前端必会面试题
1.类的创建和继承
(1)原型链的继承
function Animal(){
this.name="猫";
this.sex="雌性";
}
Animal.prototype.say="您好";
function Cat(){
this.a="123";
this.b="456";
}
Cat.prototype.k="k";
Cat.prototype=new Animal();
Cat.prototype.c="789";
var d=new Cat();
console.log(d.a)//123
console.log(d.name);//猫
console.log(d.c);//789
console.log(d.k);//undefined
console.log(d.sex);//雌性
console.log(d.say);//您好
console.log(d instanceof Cat);//true
console.log(d instanceof Animal);//true
优点:
实例即能够是子类的实例也能够是父类的实例,父类上的原型属性和方法都能够访问到。
缺点:1.虽然原型链继承很强大, 但是存在一个问题, 最主要的问题是包含引用类型值的原型, 因为包含引用类型值的原型属性会被所有的实例共享, 而在通过原型来实现继承的时候, 原型实际变成了另外一个函数的实例(这里边就有可能存在引用类型),无法实现多继承。
function Parent() {
this.newArr = ["heyushuo", "kebi"];
}
function Child() {
this.name = "kebi";
}
Child.prototype = new Parent();
var Person1 = new Child();
Person1.newArr.push("kuli");
console.log(Person1.newArr); // ["heyushuo","kebi","kuli"]
var Person2 = new Child();
console.log(Person2.newArr); // ["heyushuo","kebi","kuli"]
2.无法向父类构造函数传参。
(2)构造函数的继承
function Animal(method){
this.name="猫";
this.sex="雌性";
this.method=method;
this.eat=function(){
console.log("eat");
}
}
Animal.prototype.say="您好";
function Cat(method,level){
Animal.call(this,method)
this.a="123";
this.b="456";
this.level=level;
}
var c=new Cat("学习","优秀")
var e=new Cat("学习2","良好")
console.log(c.name)//猫
console.log(c.sex)//雌性
console.log(c.a)//123
console.log(c.b)//456
console.log(c.say)//undefined
console.log(c.method==e.method)//false
console.log(c.method)//学习
console.log(e.method)//学习2
console.log(c.say)//undefiend
console.log(e.say)//undefined
优点:1.实现了多继承
2.能够向父类构造函数传参数
缺点:只能继承父类构造函数的属性和方法,但是无法继承其原型上的属性和方法
(2)组合继承
function Animal(method){
this.name="猫";
this.sex="雌性";
this.method=method;
this.eat=function(){
console.log("eat");
}
}
Animal.prototype.say="您好";
function Cat(method,level){
Animal.call(this,method)
this.a="123";
this.b="456";
this.level=level;
}
Cat.prototype=new Animal();
var c=new Cat("学习","优秀")
var e=new Cat("学习2","良好")
console.log(c.name)//猫
console.log(c.sex)//雌性
console.log(c.a)//123
console.log(c.b)//456
console.log(c.method==e.method)//false
console.log(c.method)//学习
console.log(e.method)//学习2
console.log(c.say)//您好
console.log(e.say)//您好
console.log(c instanceof Cat)//true
console.log(c instanceof Animal)//true
优点:实例能够是子类的实例的也是父类的实例,实现多继承,也可以向父类进行传参数。
缺点:调用了两次父类构造函数,生成了两份实例。
(3)寄生式组合继承
unction Animal(method){
this.name="猫";
this.sex="雌性";
this.method=method;
this.eat=function(){
console.log("eat");
}
}
Animal.prototype.say="您好";
function Cat(method,level){
Animal.call(this,method)
this.a="123";
this.b="456";
this.level=level;
}
(function () {
var Super=function(){}
Super.prototype=Animal.prototype;
Cat.prototype=new Super();
})();
var c=new Cat("学习","优秀");
var e=new Cat("学习2","良好");
console.log(c.name)//猫
console.log(c.sex)//雌性
console.log(c.a)//123
console.log(c.b)//456
console.log(c.method==e.method)//false
console.log(c.method)//学习
console.log(e.method)//学习2
console.log(c.say)//您好
console.log(e.say)//您好
console.log(c instanceof Cat)//true
console.log(c instanceof Animal)//true
2.取消默认事件
function cancel(event){
var event=event||window.event;
if(event.preventDefault) event.preventDefault();
if(event.returnValue) event.returnValue=false;
}
3.图片的懒加载和预加载
4.函数的节流与防抖
防抖:
function debounce(func,delay){
delay=delay||300;
var timer=null;
return function(){
var _self=this;
var args=arguments;
clearTimeout=(timer);
timer=setTimeout(function(){
func.apply(_self,args)
},delay)
}
}
节流:
function throttle(func,delay){
var delay=delay||300;
var lastTime=0;
return function(){
var _self=this;
var arg=arguments;
var nowTime=new Date().getTime();
if(nowTime-lastTime>delay)
func.apply(_self,arguments);
lastTime=nowTime;
}
}
5.拷贝
深拷贝
1.var deepClone=function(obj){
if(typeof obj !="object") return;
var newObj=obj instanceof Array?[]:{};
for(var key in obj){
if(obj.hasOwnProperty(key)){
newObj[key]=typeof obj[key]==='object'?deepClone(obj[key]):obj[key];
}
}
return newObj;
}
缺点:这里只是针对Object引用类型的值的循环迭代,而对于Array,Date,RegExp,Error,Function引用类型
无法正确拷贝
浅拷贝
var shallowClone=function(obj){
if(typeof obj!="object") return;
var newObj=obj instanceof Array?[]:{};
for(var key in obj){
if(obj.hasOwnProperty(key)){
newObj[key]=obj[key];
}
}
return newObj;
}
深拷贝:
2.JSON.parse(JSON.stringify())
缺点:
1.拷贝的对象的值中如果有函数,undefined则经过JSON.stringify()序列化后的
JSON字符串中这个键值对会消失。
```javascript
var obj={
a:1,
b:"str",
c:function(){console.log("abc")},
d:undefined
}
console.log(JSON.parse(JSON.stringify(obj)))

2.拷贝Date引用类型会变成字符串
3.对象中含有NaN、Infinity和-Infinity,则序列化的结果会变成null
var obj={
a:1,
b:"str",
c:function(){console.log("abc")},
d:undefined,
e:NaN,
f:Infinity,
g:-Infinity
}
console.log(JSON.parse(JSON.stringify(obj)))

4.拷贝RegExp引用类型会变成空对象
var obj={
a:1,
b:"str",
c:function(){console.log("abc")},
d:undefined,
e:NaN,
f:Infinity,
g:-Infinity,
h:new RegExp(/\d/g)
}
console.log(JSON.parse(JSON.stringify(obj)))
 6.传入函数参数只执行一次
6.传入函数参数只执行一次
function ones(func){
var tag=true;
return function(){
if(tag==true){
func.aplly(null,arguments);
tag=false;
}
else
return undefined;
}
}
7.将原生的ajax封装成promise
var myAjax=function(url){
return new Promise(resolve,reject){
var xhr=new XMLHttpRequest();
xhr.open('get',url);
xhr.send();
xhr.onreadystatechange=function(){
if(xhr.status==200&&xhr.readyState==4){
var json=JSON.parse(xhr.responseText);
resolve(json);
}
else if(xhr.status!=200&&xhr.readyState==4){
reject("error")
}
}
}
}
8.requestAnimationFrame
requestAnimationFrame是不需要设置时间间隔的,大多数电脑显示器的刷新频率为60hz,每秒钟刷新60次,最佳的时间间隔是1000/60=16.6ms
特点:
(1).requestAnimationFrame会把每一帧中所有DOM操作集中起来,在一次重绘或回流中就完成,并且重绘或回流时间隔紧紧跟随浏览器的刷新速率。
(2).在隐藏或不可见的元素中,requestAnimalFrame将不会进行重绘或回流,这当然就意味着更少的CPU,GPU和内存使用量。
9.js判断类型
判断方法:typeof(),instanceof,Object.prototype.toString.call()等
运算符 结果
undefined “undefined”
null “object”
布尔值 “boolean”
数字 “number”
函数 “function”
其他都是object
typeof(nan)//number
typeof(nan==undefined)//boolean
Object.prototype.toString.call(dd)//[object Function]
Object.prototype.toString.call(Array)//[object Function]
Object.prototype.toString.call(new Array)//[object Array]
Object.prototype.toString.call(new Object)//[object Object]
Object.prototype.toString.call(new Date)//[object Date]
Object.prototype.toString.call(undefined)//[object Undefind]
Object.prototype.toString.call(null)//[object Null]
Object.prototype.toString.call(“123”)//[object String]
Object.prototype.toString.call(123)//[object Number]
9.实现add(1)(2)(3)(4)
function add(num){
var sum=num;
var fn=function(v){
sum+=v;
return fn;
}
fn.toString=function(){
return sum;
}
return fn;
}
console.log(add(1)(2)(3))
10.实现add(1)(1,2,3)(4)
function add(){
var args=[...arguments];
var fn=function(){args.push(...arguments);return fn}
fn.toString=function(){return args.reduce(function(arr,cur){return arr+cur;},0)}
return fn
}
console.log(add(1)(1,2,3)(2))
11.JS的全排列
var permute=function (nums){
result=[];
arr=[];
for(let j=0;j<nums.length;j++){
arr.push(nums[j]);
}
find(arr,[])
return result
}
function find(arr,templateList){
if(arr.length==0){
// var t=templateList.join("");//这个是转换为字符
//result.push(t);
result.push(templateList.slice());//返回的是数组
}
for(let i=0;i<arr.length;i++){
templateList.push(arr[i]);
let copy=arr.slice();
copy.splice(i,1);
find(copy,templateList);
templateList.pop();
}
}
console.log(permute("abc"));
12.比较判断
1.如果一个运算符是Boolean值,在检查相等之前,把转换为数字值,false为0,true为1.
2.如果一个运算数是字符串,另一个数字,则把字符串转换为数字
3.如果一个是对象,另一个数字,则把对象转换为数字 valueOf()
4.如果一个是对象,另一个字符串,则把对象转换为字符串toString()
5.如果两个都是对象,则比较它们的引用值,指向同一个对象为true,否则为false
“NaN"NaN//false
5NaN//false
NaNNaN//false
NaN!=NaN//true
[]0//true
[]false//true
[]undefined//false
[]=null//false
[]’’//true
[]" "//false
0undefined//false
0null//false
0” “//true
false==” “//true
false==”"//true
[]==false//true
[0]==false//true
[00]false//true
[0,0]false//false
console.log(“10”*“20”)//200输出的类型都是number
console.log(“10”-“2”)//8
console.log(“10”-2)//8
console.log([] == ![]) // true
console.log([] == []) // false
console.log([] == {}) // false
console.log(new String(‘a’) == new String(‘a’)) // false
console.log(isNaN(NaN)) // true
console.log(isNaN(‘32131dsafdas’)) // true
console.log(NaN === NaN) // false
console.log(NaN === undefined) // false
console.log(undefined === undefined) // true
console.log(typeof NaN) // number
console.log([][])//false
console.log([]{})//false
console.log([]!=[])//false
console.log({} + []) // 0
console.log([] + {}) // “[object Object]”
console.log({} + {}) // “[object Object][object Object]”
console.log([]+ []) // “”
console.log({} + 1) // 1
console.log([] + 1) // “1”
类型转换的总结
1.Boolean()函数
以下值转换为false:
false,Null,undefined,NaN,0,""
其余都是true
逻辑与(&&)操作符,如果一个操作值不是布尔值时,遵循以下规则进行转换:
如果第一个操作数经Boolean()转换后为true,则返回第二个操作值,否则返回第一个值(不是Boolean()转换后的值
如果有一个操作值为null,返回null
如果有一个操作值为NaN,返回NaN
如果有一个操作值为undefined,返回undefined
console.log(null&&undefined)//null
console.log(undefined&&null)//undefined
console.log(NaN&&undefined)//NaN
console.log(undefined&&NaN)//undefined
逻辑或(||)操作符,如果一个操作值不是布尔值,遵循以下规则:
如果第一个操作值经Boolean()转换后为false,则返回第二个操作值,否则返回第一个操作值(不是Boolean()转换后的值
对于undefined、null和NaN的处理规则与逻辑与(&&)相同
console.log(NaN||null)//null
console.log(null||NaN)//NaN
console.log(null||undefined)//undefined
console.log(undefined||null)//null
2.关系操作符(<, >, <=, >=)
如果两个操作值都是数值,则进行数值比较
如果两个操作值都是字符串,则比较字符串对应的字符编码值
如果只有一个操作值是数值,则将另一个操作值转换为数值,进行数值比较
如果一个操作数是对象,则调用valueOf()方法(如果对象没有valueOf()方法则调用toString()方法),得到的结果按照前面的规则执行比较
如果一个操作值是布尔值,则将其转换为数值,再进行比较
注:NaN是非常特殊的值,它不和任何类型的值相等,包括它自己,同时它与任何类型的值比较大小时都返回false
3.Number(mix)函数
(1)如果是布尔值,true和false分别被转换为1和0
(2)如果是数字值,返回本身。
(3)如果是null,返回0.
(4)如果是undefined,返回NaN。
(5)如果是字符串,遵循以下规则:
1、如果字符串中只包含数字,则将其转换为十进制(忽略前导0)
2、如果字符串中包含有效的浮点格式,将其转换为浮点数值(忽略前导0)
3、如果是空字符串(""," “),将其转换为0
4、如果字符串中包含非以上格式,则将其转换为NaN
(6)如果是对象,则调用对象的valueOf()方法,然后依据前面的规则转换返回的值。如果转换的结果是NaN,则调用对象的toString()方法,再次依照前面的规则(5)转换返回的字符串值。
4.parseInt(string,radix)函数//最后的输出都是10进制,radix表示目前这个数是几进制//parseInt(“033”,8),parseInt(“0x33”,16)
将字符串转换为整数类型的数值。它有一定的规则:
(1)忽略字符串前面的空格,直至找到第一个非空字符
(2)如果第一个字符不是数字符号或者负号,返回NaN
(3)如果第一个字符是数字,则继续解析直至字符串解析完毕或者遇到一个非数字符号为止
(4)如果上步解析的结果以0开头,则将其当作八进制来解析;如果以x开头,则将其当作十六进制来解析
(5)如果指定radix参数,则以radix为基数进行解析
5.parseFloat(string)函数
parseFloat(“10”)//10
parseFloat(“10.00”)//10
parseFloat(“10.33”)//10.33
parseFloat(“34 45 66”)//34
parseFloat(” 60 ")//60
parseFloat(“40 years”)//40
parseFloat(“He was 40”)//NaN
6.toString(radix)方法。
除undefined和null之外的所有类型的值都具有toString()方法,其作用是返回对象的字符串表示。
Array 将 Array 的元素转换为字符串。结果字符串由逗号分隔,且连接起来。
Boolean 如果 Boolean 值是 true,则返回 “true”。否则,返回 “false”。
Date 返回日期的文字表示法。
Error 返回一个包含相关错误信息的字符串。
Function 返回如下格式的字符串,其中 functionname 是被调用 toString 方法函数的名称:function functionname( ) { [native code] }
Number 返回数字的文字表示。
String 返回 String 对象的值。
默认返回 “[object objectname]”,其中 objectname 是对象类型的名称。
7.String(mix)函数。
将任何类型的值转换为字符串,其规则为:
(1)如果有toString()方法,则调用该方法(不传递radix参数)并返回结果
(2)如果是null,返回”null”
(3)如果是undefined,返回”undefined”
8. 如果是Infinity+(-Infinity)=NaN
+0+(+0)结果为+0
(-0)+(-0)结果为-0
(+0)+(-0)结果为+0
13.按需加载
当用户触发了动作时才加载对应的功能。触发的动作,是要看具体的业务场景而言,包括但不限于以下几种情况:鼠标点击,输入文字,拉动滚动条,鼠标移动,窗口大小更改等。加载的文件,可以是JS、图片、css、HTML等。
13.什么是虚拟dom
用js对象结构表示dom树的结构;然后用这个树构建一个真正的dom树,插到文档当中,当状态变更时,重新构造一棵新的对象树,然后用新的树和旧的树进行比较,记录两棵树的差异应用到所构建的真正的dom树上,视图就更新了。虚拟dom本质上就是在js和dom之间做了一个缓存。
14.实现一个bind函数
Function.prototype.bind=function(obj,arg){
var arg=Array.prototype.slice.call(arguments,1)
var content=this;
return function(newArg){
arg=arg.concat(Array.prototype.slice.call(newArg));
return context.apply(obj,arg);
}
}
15.一些主流浏览器对http1.1和http1.0的最大并发连接数目
浏览器 http1.1 http1.0
IE11 6 6
IE10 6 6
IE9 10 10
IE8 6 6
火狐 6 6
chrome 6 6
safari 4 4
16.head方式响应信息
1.content-length:http 的消息体传输长度
2.content-encoding:数据使用的编码类型
3.content-type:媒体资源类型
4.age:该响应在缓存机制存放多久
5.expires:过期时间
6.last-modified:修改时间
7.set-cookie:设置cookie
8.status:状态码
17.http 常用请求头
1.Accpet-encoding:所能接受的编码方式(compress,gzip)
2.cache-control:是否使用缓存机制
3.connection:连接类型
4.cookie
5.if-modified-since
6.if-none-match
7.referer:表示浏览器所访问的前一个页面
8.upgrade:服务器升级到一个高版本协议
18.http 请求方法
1.put:向指定资源位置上传其最新内容。
2.delete:请求服务器删除request-uri所标识的资源
3.trace:回显服务器收到的请求,主要用于测试或诊断。
4.connect:预留能够将连接改为管道方式的代理服务器,将服务器作为代理,让服务器代替用户访问其他网页,之后将数据返回给用户。()
19.浏览器的内核有哪些?
1.IE:trident内核
2.火狐:gecko内核
3.safari:webkit内核
4.Opera:blink 内核
5.谷歌:blink 内核
20.介绍一下你对浏览器内核理解?
1.渲染引擎:负责取得网页的内容,整理讯息,计算网页的显示方式,然后输出至显示器。
2.js引擎:解析和执行js实现逻辑和控制dom进行交互。
21.常见的http的头部
可以将http首部分为通用首部,请求首部,响应首部,实体首部
通用首部表示一些通用信息,比如date表示报文创建时间
请求首部就是请求报文中独有的,如cookie,和缓存相关的如if-modified-since
响应首部就是响应报文中独有的,如set-cookie和last-modified
实体首部用来描述实体部分,如content-type描述主题类型,content-encoding描述主题类型,content-encoding描述主体的编码方式。
22.有继承性的属性
1.字体系列属性(font-size,font-weight,font-family)
2.文体类型属性(text-indent,text-align,line-height,color)
所有元素可以继承的属性
元素可见性:visilility
光标属性:cursor
23.js动画和css3动画的差异性
1.功能涵盖面,js比css大。
2.实现难度不一样,css比js更加简单。
3.对帧速表现不好的低版本浏览器,css3可以做到自然降级(css3优雅降级,从高版本降低到低版本,css3的渐进增强,从低版本提升到高版本)
24.css的伪类和伪元素
伪类:用于已有元素处于某种状态时为其添加对应的样式,这个状态是根据用户行为而动态变化的。
伪元素:用于创建一些不在dom树中的元素,并为其添加样式。
伪类:
1.:link选择未访问的链接
2.:visited选择已访问的链接
3.:hover选择鼠标指针浮动在其上元素
4.:active选择活动的链接
5.:focus获取焦点的输入字段
伪元素:
:after
:before

 25.line-height和height
25.line-height和height
line-height是指布局里面一段文字上下行之间的高度,是针对字体的设置,height一般是指容器的整体高度
注意:
1.如果标签没有定义height属性,那么其最终的表现的高度为line-height定。
2.line-height指下一行的基线到上一行的基线距离。
3.父元素的行高为1.5,子元素的字体为18px,子元素的行高为1.5*18px;
26.多行元素的文本省略号
display:-webkit-box
-webkit-box-orient:vertical//框的子元素应该被水平或垂直排列
-webkit-line-clamp:3
overflow:hidden
27.单行文本溢出
text-overflow:ellipsis
overflow:hidden
white-wrap:nowrap//如何处理空白,不换行
28.已知父元素宽高,子元素宽高
1.
.container{
width:200px;
height:200px;
border:2px solid red;
position:relative;
}
.son{
width:100px;
height:100px;
border:2px solid blue;
position:absolute;
top:0px;
left:0px;
bottom:0px;
right:0px;
margin:auto auto;
}
.container{
width:200px;
height:200px;
border:2px solid red;
display:flex;
justify-content:center;
align-items:center;
}
.son{
width:100px;
height:100px;
border:2px solid blue;
}
.container{
width:200px;
height:200px;
border:2px solid red;
position:relative;
}
.son{
width:100px;
height:100px;
border:2px solid blue;
position:absolute;
left:50%;
top:50%;
margin-left:-50px;
margin-top:-50px;
}
.container{
width:200px;
height:200px;
border:2px solid red;
position:relative;
}
.son{
width:100px;
height:100px;
border:2px solid blue;
position:absolute;
left:50%;
top:50%;
transform:translate(-50%,-50%);
}
29.未知父元素宽高,子元素宽高
1.
<div class="son">
</div>
.son{
width:100px;
height:100px;
border:2px solid blue;
position:absolute;
left:0px;
right:0px;
bottom:0px;
top:0px;
margin:auto auto;
}
<div class="son">
</div>
.son{
width:100px;
height:100px;
border:2px solid blue;
position:absolute;
left:50%;
top:50%;
margin-left:-50px;
margin-top:-50px;
}
<div class="son">
</div>
.son{
width:100px;
height:100px;
border:2px solid blue;
position:absolute;
left:50%;
top:50%;
transform:translate(-50%,-50%);
}
//如果以浏览器为父级元素
<div class="center">
</div>
.center{
margin: 50vh auto;
transform: translateY(-50%);
}
.center{
width:20%;
height:20%;
border:2px solid red;
position:absolute;
left:50%;
top:50%;
transform:translate(-50%,-50%);
}
30.已知父元素宽高,子元素宽高未知(跟子元素知道宽高一样)
1.
.container{
width:200px;
height:200px;
border:2px solid red;
display:flex;
justify-content:center;
align-items:center;
}
.son{
width:20%;
height:20%;
border:2px solid blue;
}
31.三栏布局
1.
*{
margin:0;
padding:0;
}
.container{
display:flex;
}
.left{
width:100px;
height:100px;
background-color:red;
}
.center{
flex-grow:1;
height:100px;
background-color:blue;
}
.right{
width:100px;
height:100px;
background-color:yellow;
}
*{
margin:0;
padding:0;
}
.ex-center{
width:100%;
height:100px;
background-color:red;
float:left;
}
.left{
width:100px;
height:100px;
background-color:blue;
float:left;
margin-left:-100%;
}
.right{
width:100px;
height:100px;
background-color:yellow;
float:left;
margin-left:-100px;
}
.center{
height:100px;
margin:0px 100px;
background-color:green;
}
*{
margin:0;
padding:0;
}
.left{
position:absolute;
left:0px;
top:0px;
background-color:red;
width:100px;
height:100px;
}
.right{
position:absolute;
right:0px;
top:0px;
background-color:yellow;
width:100px;
height:100px;
}
.center{
position:absolute;
left:100px;
right:100px;
top:0px;
height:100px;
background-color:green;
}
4.父元素是浏览器
.container{
display:flex;
}
.A{
width:100px;
background:red;
height:100%;
}
.B{
flex-grow:1;
background:yellow;
height:100%;
}
.C{
width:100px;
background:black;
height:100%:
}
//第二种
.container{
}
.A{
position:absolute;
top:0px;
left:0px;
width:200px;
height:100%;
background:red;
}
.B{
position:absolute;
top:0px;
left:100px;
height:100%;
right:100px;
background:yellow;
}
.C{
position:absolute;
top:0px;
right:0px;
width:100px;
height:100%;
background:blue;
}
//第三种
.container{
}
.A{
width:100%;
height:100%;
background:red;
float:left;
}
.B{
width:100px;
height:100%;
background:blue;
float:left;
margin-left:-100%;
}
.C{
width:100px;
height:100%;
background:yellow;
float:left;
margin-left:-100px;
}
.D{
height:100%;
margin:0 100px;
background:pink;
}
两列自适应
*{
margin:0;
padding:0;
}
.container{
display:flex;
}
.left{
flex-grow:1;
height:100px;
background-color:red;
}
.right{
flex-grow:1;
height:100px;
background-color:blue;
}
2.
.container{
position:relative;
}
.left{
position:absolute;
width:50%;
height:100px;
background-color:red;
}
.right{
position:absolute;
left:50%;
top:0px;
height:100px;
width:50%;
background-color:green;
}
3.
left{
width:50%;
height:100px;
float:left;
background-color:red;
}
.right{
width:50%;
height:100px;
float:left;
background-color:green;
}
//父元素的高度随子元素的高度发生变化,左边固定,右边占据剩余宽度,高度不定
<div class="A">
<div class="B">B
</div>
<div class="C">C
</div>
</div>
.A{
width:100%;
overflow:hidden;
border:2px solid red;
}
.B{
width:100px;
height:100px;
border:2px solid blue;
float:left;
}
.C{
width:100%;
margin-left:100px;
border:2px solid yellow;
}
注意:如果子元素包含在父元素里面,而且子元素没有设置宽高,那么子元素的宽度会跟随父元素,而高度跟随子元素里面的内容,如果子元素进行浮动或者脱离文档流后在宽度和高度跟随自身。
32.事件代理
var father=document.getElementById("father");
father.addEventListener("click",function(event){
var event=event||window.event;
var target=event.target||event.srcElement;
switch (target.id){
case "one":
alert("1");
break;
case "two":
alert("2");
break;
case "three":
alert("3");
break;
case "four":
alert("4");
break;
}
});
事件先冒泡后捕获
var father=document.getElementById("father");
father.addEventListener("click",function(){setTimeout(function(){alert("2")},2000)},true);
father.addEventListener("click",function(){alert("1")},false);
33.图片的懒加载和预加载
图片的预加载:
<img src="" alt="" id="pic01"/>
<img src="" alt="" id="pic02"/>
<script type="text/javascript">
var arr=["first.jpg","second.jpg"];
var imgs=[];
preLoadImg(arr);
function preLoadImg(pars){
for(let i=0;i<pars.length;i++){
imgs[i]=new Image();
imgs[i].src=pars[i];
}
}
setTimeout(function(){
var pic01=document.getElementById("pic01");
var pic02=document.getElementById("pic02");
pic01.src="first.jpg";
pic01.style.width=200+'px';
pic01.style.height=200+"px";
pic02.src="second.jpg";
pic02.style.width=200+'px';
pic02.style.height=200+"px";
},1000)
图片的懒加载:
34.自己实现一个bind函数
Function.prototype.bind=function(obj,arg){
var args=Array.prototype.slice.call(arguments,1);
var content=this;
return function(newarg){
args=args.concat(Array.prototype.slice.call(newarg));
return content.apply(obj,arg);
}
}
35.sleep函数
function sleep(ms){
return new Promise(funtion(resolve,reject){
setTimeout(function(){
resolve("111");
},ms)
})
}
sleep(5000).then(function(value){
console.log(value);
})
35.取消默认事件
function cancelthing(event){
var ev=event||window.event;
if(ev.preventDefault) ev.preventDefault();
if(ev.returnValue) ev.returnValue=false;
return false;
}
36.观察者模式:观察者模式(Observer mode)指的是函数自动观察数据对象,一旦对象有变化,函数就会自动执行。而js中最常见的观察者模式就是事件触发机制。
发布-订阅的顺序探讨
我们通常所看到的都是先订阅再发布,但是必须要遵守这种顺序吗?答案是不一定的。如果发布者先发布一条消息,但是此时还没有订阅者订阅此消息,我们可以不让此消息消失于宇宙之中。就如同QQ离线消息一样,离线的消息被保存在服务器中,接收人下次登录之后,才会收到此消息。同样的,我们可以建立一个存放离线事件的堆栈,当事件发布的时候,如果此时还没有订阅者订阅这个事件,我们暂时把发布事件的动作包裹在一个函数里,这些包装函数会被存入堆栈中,等到有对象来订阅事件的时候,我们将遍历堆栈并依次执行这些包装函数,即重发里面的事件,不过离线事件的生命周期只有一次,就像qq未读消息只会提示你一次一样。
1.实现简单的Event模块的emit和on方法
function Events(){
this.on=function(eventName,callBack){
if(!this.handles){
this.handles={};
}
if(!this.handles[eventName]){
this.handles[eventName]=[];
}
this.handles[eventName].push(callback);
}
this.emit=function(eventName,obj){
if(this.handles[eventName]){
for(var i=0;i<this.handles[eventName].length;i++){
this.handles[eventName][i](obj);
}
}
}
return this;
}
//这样我们就定义了Events,现在我们可以开始来调用:
var events=new Events();
events.on('say',function(name){
console.log("hello",name);
})
events.emit("say","Jony yu");
//每个对象是独立的
var event1=new Events();
var event2=new Events();
event1.on("say",function(){
console.log("json01")
})
event2.on("say",function(){
console.log("json02")
})
event1.emit("say");
event2.emit("say");
//工厂模式
function createPerson(name,age,job){
var obj = new Object();
obj.name = name;
obj.age = age;
obj.job = job;
obj.speak = function(){
console.log(this.name);
};
return obj
}
var person1 = createPerson('panrui',20,'前端工程师')
优点:能够大批量生产包含这些属性的
缺点:不能够区分狗,人,猫。
//构造函数模式
function Person(name,age,job){
this.name = name;
this.age = age;
this.job = job;
this.speak = function(){
console.log(this.name);
};
}
var person2 = new Person('panrui',20,'前端工程师')
这个就区分了狗,猫,人
person2 instanceof Person;
37.for…in和forEach和for…of
var obj={
"name":"张三",
"sex":"男",
"age":30
}
for(let key in obj){
console.log(key,obj[key])
}
var arr=[3,4,5,6]
for(let key in arr){
console.log(arr[key])
}
var arr02=[4,5,6,7]
arr02.forEach(function(item){return console.log(item)})
for(let key of arr02){console.log(key);}
var str="abcdef"
for(let key of str){
console.log(key)//'a','b','c'......
}
38.Set和Map
Set的遍历操作
let set=new Set(["red","green","blue"]);
for(let key of set.keys()){
console.log(key);
}
for(let key of set.values()){
console.log(key);
}
for(let key of set.entries()){
console.log(key);
}
set.forEach(function(item){
console.log(item)
})
结果:
> "red"
> "green"
> "blue"
> "red"
> "green"
> "blue"
> Array ["red", "red"]
> Array ["green", "green"]
> Array ["blue", "blue"]
> "red"
> "green"
> "blue"
Map操作
JavaScript的对象(Object),本质上是键值对的集合(Hash结构),但是传统上只能用字符串当作键。这给它的使用带来了很大的限制。所以Map就诞生了,ES6提供了Map数据结构。它类似于对象,也是键值对的集合,但是“键”的范围不限于字符串,各种类型的值(包括对象)都可以当作键。
var m=new Map();
var o={"p":"hello world"};
m.set(o,"content");
m.get(o)//"content"
m.has(o)//true
m.delete(o)//true
m.has(o)//false
作为构造函数,Map也可以接受一个数组作为参数。该数组的成员是一个个表示键值对的数组。
var map = new Map([
['name', '张三'],
['title', 'Author']
]);
map.size // map.has('name') // true
map.get('name') // "张三"
map.has('title') // true
map.get('title') // "Author"
var items = [
['name', '张三'],
['title', 'Author']
];
var map = new Map();
items.forEach(([key, value]) => map.set(key, value));
注意,只有对同一个对象的引用,Map结构才将其视为同一个键
var map=new Map();
map.set(['a'],555);
map.get(['a'])//undefined
上面代码的set和get方法,表面是针对同一个键,但实际上这是两个值,内存地址是不一样的,因此get方法无法读取该键,返回undefined。
如果改成这样就可以了
var map=new Map();
var a=['a'];
map.set(a,555);
console.log(map.get(a))//555
**以下的NaN和-0和+0注意一下**
let map = new Map();
map.set(NaN, 123);
map.get(NaN) // 123
map.set(-0, 123);
map.get(+0) // 123
**Map结构的实例有以下属性和操作方法**
1.size属性
let map = new Map();
map.set('foo', true);
map.set('bar', false);
map.size // 2
2.set(key,value)
var m = new Map();
m.set("edition", 6) // 键是字符串
m.set(262, "standard") // 键是数值
m.set(undefined, "nah") // 键是undefined,get可以访问到
3.get(key)
4.has(key)
5.delete(key)
6.clear()
let map = new Map([
['F', 'no'],
['T', 'yes'],
]);
for (let key of map.keys()) {
console.log(key);
}
// "F"
// "T"
for (let value of map.values()) {
console.log(value);
}
// "no"
// "yes"
for (let item of map.entries()) {
console.log(item[0], item[1]);
}
// "F" "no"
// "T" "yes"
// 或者
for (let [key, value] of map.entries()) {
console.log(key, value);
}
// 等同于使用map.entries()
for (let [key, value] of map) {
console.log(key, value);
}
Map结构的遍历方法
let map=new Map([["F","no"],["T","yes"]]);
for(let key of map.keys()){
console.log(key)//"F","T"
}
for(let value of map.values()){
console.log(value)//"no" "yes"
}
for(let item of map.entries()){
console.log(item[0],item[1]);
}//"F""no" //"T""yes"
或者是
for(let [key,value] of map.entries()){
console.log(key,value)
}
Map结构转为数组结构,比较快速的方法是结合使用扩展运算符(...)
let map = new Map([
[1, 'one'],
[2, 'two'],
[3, 'three'],
]);
[...map.keys()]
// [1, 2, 3]
[...map.values()]
// ['one', 'two', 'three']
[...map.entries()]
// [[1,'one'], [2, 'two'], [3, 'three']]
[...map]
// [[1,'one'], [2, 'two'], [3, 'three']]
Map结构本身就没有map和filter方法
let map0=new Map()
map0.set(1,'a')
map0.set(2,'b')
map0.set(3,'c')
let map1=new Map([...map0].filter(function([key,value]){return key<3}));
console.log([...map1])//[[1,"a"],[2,"b"]]
let map1=new Map([...map0].map(function([key,value]){return [key*2,"_"+value]}));
console.log([...map1])
Map还有一个forEach方法,与数组的forEach方法类似,也可以实现遍历
map.forEach(function(value,key,map){
console.log(key,value)
})
Map转换为对象
```javascript
function strMapToObj(strMap){
let obj=Object.create(null);
for(let [k,v] of strMap){
obj[k]=v;
}
return obj;
}
对象转换为Map
function objToStrMap(obj){
let strMap=new Map();
for(let k of Object.keys(obj)){
strMap.set(k,obj[k]);
}
return strMap;
}
Map转为JSON
Map转为JSON要区分两种情况。一种情况是,Map的键名都是字符串
function strMapToJSON(strMap){
return JSON.stringify(strMapToObj(strMap))
}
Map的键名有非字符串,这时可以选择转为数组JSON
function mapToArrayJson(map){
return JSON.stringify([...map])
}
JSON转为Map
正常情况下,所有键名都是字符串
function jsonToStrMap(jsonStr){
return objToStrMap(JSON.parse(jsonStr))
}
但是,有一种特殊情况,整个JSON就是一个数组,且每个数组成员本身,又是一个有两个成员的数组。这时,它可以一一对应地转为Map。这往往是数组转为JSON的逆操作。
function jsonToMap(jsonStr) {
return new Map(JSON.parse(jsonStr));
}
39.跨域
1.jsonp跨域原理
jsonp的封装函数
function jsonp(url,data,callback){
let scriptTag=document.createElement("script");
let params="";
for(key in data){
params+=key+"="+data[key]+"&"
}
params.length===0?scriptTag.src=url+"?"+'fn='+callback:
scriptTag.src=url+"?"+params+'fn='+callback
document.querySelector("head").appendChild(scriptTag);
}
function myCallback(){alert("success")}
jsonp("123",{name:"lhy"},"myCallback")
前端页面:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<title>index.html</title>
</head>
<body>
<script>
function jsonpCallback(data) { // 相对后端接口所需要的处理函数
alert('用JSONP跨域,获得数据:' + data.x);
}
</script>
<script src="http://127.0.0.1:3000?callback=jsonpCallback"></script> // 发送请求
</body>
</html>
后端页面:
const url = require('url');
require('http').createServer((req, res) => {
const data = {
x: 10
}
const callback = url.parse(req.url, true).query.callback //
res.writeHead(200)
res.end(`${callback}(${JSON.stringify(data)})`) // 服务器收到请求后,解析参数,
// 将callback(data)以字符串的形式返还数据,前端页面会将callback(data)作为js执行
// 调用jsonpCallback(data)函数。
}).listen(3000, '127.0.0.1');
console.log('启动服务,监听 127.0.0.1:3000');
JSON的缺点:
1.它支持get请求而不支持post等其它类行的http 请求。
2.它只支持跨域http请求这种情况,不能解决不同域的两个页面或iframe之间进行数据通信的问题。
2.CORS原理
CORS 全称是跨域资源共享(Cross-Origin Resource Sharing),是一种 ajax 跨域请求资源的方式,支持现代浏览器,IE支持10以上。 实现方式很简单,当你使用 XMLHttpRequest 发送请求时,浏览器发现该请求不符合同源策略,会给该请求加一个请求头:Origin,后台进行一系列处理,如果确定接受请求则在返回结果中加入一个响应头:Access-Control-Allow-Origin; 浏览器判断该响应头中是否包含 Origin 的值,如果有则浏览器会处理响应,我们就可以拿到响应数据,如果不包含浏览器直接驳回,这时我们无法拿到响应数据。所以 CORS 的表象是让你觉得它与同源的 ajax 请求没啥区别,代码完全一样。
CORS又分简单请求和非简单请求
简单请求:
比如发送了一个origin的头部
Origin : http: //www.nczonline.net
如果服务器认为这个请求可以接受,就在Access-Control-Allow-Origin头部回发相同的源信息
Access-Control-Allow-Origin : http: //www.nczonline.net
比如发送了一个origin的头部
Origin : http: //www.nczonline.net
如果服务器认为这个请求可以接受,就在Access-Control-Allow-Origin头部回发相同的源信息
Access-Control-Allow-Origin : http: //www.nczonline.net
1.Access-Control-Allow-Origin:该字段是必须的,* 表示接受任意域名的请求,还可以指定域名
2.Access-Control-Allow-Credentials:该字段可选,是个布尔值,表示是否可以携带cookie,(注意:如果Access-Control-Allow-Origin字段设置*,此字段设为true无效)
3.Access-Control-Allow-Headers:该字段可选,里面可以获取Cache-Control、Content-Type、Expires等,如果想要拿到其他字段,就可以在这个字段中指定。比如图中指定的GUAZISSO
非简单请求:
非简单请求是那种对服务器有特殊要求的请求,比如请求方法是PUT或DELETE,或者Content-Type字段的类型是application/json。
非简单请求的CORS请求,会在正式通信之前,增加一次HTTP查询请求,称为“预检”请求(preflight)。
浏览器先询问服务器,当前网页所在的域名是否在服务器的许可名单之中,以及可以使用哪些HTTP动词和头信息字段。只有得到肯定答复,浏览器才会发出正式的XMLHttpRequest请求,否则就报错。
简单请求:
只要同时满足以下两大条件,就属于简单请求
1.请求的方式是POST,GET,HEAD
2.HTTP的头信息不超过以下几种字段
Accept
Accept-Language
Content-Language
Last-Event-ID
Content-Type:只限于三个值application/x-www-form-urlencoded、multipart/form-data、text/plain
除了以上的都是非简单请求
前端代码
<!doctype>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>index.html</title>
</head>
<body>
<script>
const xhr = new XMLHttpRequest();
xhr.open('GET', 'http://127.0.0.1:3000', true);
xhr.onreadystatechange = function() {
if(xhr.readyState === 4 && xhr.status === 200) {
alert(xhr.responseText);
}
}
xhr.send(null);
</script>
</body>
</html>
后端代码
const url = require('url')
require('http').createServer((req, res) => {
**res.writeHead(200, {
'Access-Control-Allow-Origin': 'http://localhost:8080'
})
res.end('用CORS跨域成功')**
}).listen(3000, '127.0.0.1')
console.log('启动服务,监听 127.0.0.1:3000')
CORS的优缺点:
1.使用简单方便,更为安全
2.支持POST请求方式
3.CORS是一种新型的跨域问题的解决方案,存在兼容问题,仅支持IE10以上
3.使用window.name+iframe来进行跨域
window的name属性特征:name 值在不同的页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的 name 值(2MB),即在一个窗口(window)的生命周期内,窗口载入的所有的页面都是共享一个window.name的,每个页面window.name都有读写的权限。
比如:有一个example.com/a.html页面,需要通过a.html页面里的js来获取另一个位于不同域上的页面cnblogs.com/data.html里的数据。
1)创建cnblogs.com/data.html代码:
<script>
window.name = "我是data.html的数据,所有可以转化为字符串来传递的数据都可以在这里使用,比如这里可以传递Json数据";
</script>
2)创建example.com/a.html的代码:
想要即使a.html页面不跳转也能得到data.html里的数据。在a.html页面中使用一个隐藏的iframe来充当一个中间人角色,由iframe去获取data.html的数据,然后a.html再去得到iframe获取到的数据。
<script>
function getData(){
//iframe载入data.html页面会执行此函数
var ifr = document.getElementById("iframe");
ifr.onload = function(){
//这个时候iframe和a.html已经处于同一源,可以互相访问
var data = ifr.contentWindow.name;
//获取iframe中的window.name,也就是data.html中给它设置的数据
alert(data);
}
ifr.src = 'b.html';//这里的b.html为随便一个页面,只要与a.html同源就行,目的是让a.html能够访问到iframe中的东西,否则访问不到
}
</script>
<iframe id = "iframe" src = "cnblogs.com/data.html" style = "display:none" onload = "getData()"></iframe>
40.var,let,const变量提升问题
var a,b;
(function(){
alert(a);
alert(b);
var a=b=3;//b=3,var a=b;b=3说明是全局变量
alert(a);
alert(b);
}();
alert(a);
alert(b);
//undefined,undefined,3,3,undefined,3
let a=3;
let b;
(function(){
console.log(a);
console.log(b);
let a=b=3;//b=3;let a=b;
console.log(a);
console.log(b);
})();
console.log(a);
console.log(b);
//报错,undefined,3,3,3,3
foo();
function foo() {
console.log('foo');
}
var foo = 2;
//上面代码变量提升转换后如下:
function foo() {
console.log('foo');
}
var foo;
foo();
foo = 2;
// 执行结果为: foo
//下面代码输出什么
var a=10;
(function(){
console.log(a)
a=5
console.log(window.a)
var a=20;
console.log(a)
})()//依次输出:undefined->10->20
解析:
在立即执行函数中,var a = 20; 语句定义了一个局部变量 a,由于js的变量声明提升机制,局部变量a的声明会被提升至立即执行函数的函数体最上方,且由于这样的提升并不包括赋值,因此第一条打印语句会打印undefined,最后一条语句会打印20。
**由于全局的var 会挂载到window对象下,并且立即执行函数里面有变量提示。 ‘a = 5;’这条语句执行时,局部的变量a已经声明,因此它产生的效果是对局部的变量a赋值,此时window.a 依旧是最开始赋值的10**
41.正则表达式
1.单词首字母大写 每单词首字大写,其他小写。如blue idea转换为Blue Idea,BLUE IDEA也转换为Blue Idea。
function firstCharUpper(str) {
str = str.toLowerCase();
let reg = /\b(\w)/g;
return str.replace(reg, m => m.toUpperCase());
}
42.dom遍历
var obj={
a:"123",
b:"456",
c:"789",
d:{
e:"abc",
f:"def"
},
children:[
{
tag:"li"
},
{
ta:"div"
}
]
}
//
function acquire(obj)
{
for(let key in obj){
if(typeof obj[key]=="object")
{
console.log(key);
acquire(obj[key]);
}
else
{
console.log(key,obj[key]);
}
}
}
acquire(obj)
43.虚拟dom和diff 算法
用javascript对象结构表示dom树的结构。然后用这个树构建一个真正的dom树,插到文档当中;当状态变更的时候,
重新构造一棵新的对象树。然后用新的树和旧的树进行比较,记录两颗树差异,把所记录的差异应用到所构建的真正的dom
树上,视图就更新了。虚拟dom本质上就是js和dom之间做一个缓存。
diff算法:
真实的dom算法会对同一层级的元素进行比对。
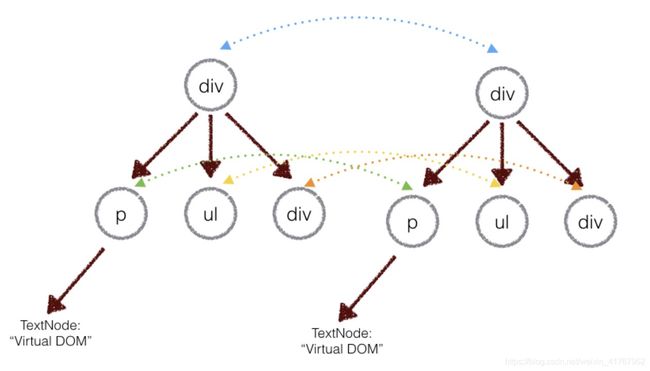
上图中,div只会和同一层级的div的对比,第二层级的只会和第二层级对比。这样算法复杂度可以达到O(n).
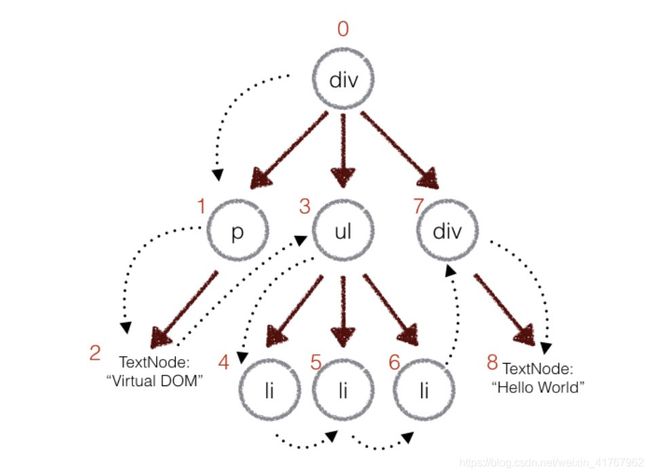
上面的这个遍历过程就是深度优先,即深度完全完成之后,再转移位置。在深度优先遍历的时候,每遍历到一个节点就把该节点和新的树进行对比,如果有差异的话就记录到一个对象里面。最后返回这个对象用来应用到实际的dom tree 更新。
44.Null和undefiend的区别
1.console.log(typeof undefined)//“undefined”
console.log(typeof null)//“object”
2.null作为原型链的终点
3.定义了形参,没有传实参,显示undefined
4.对象属性名不存在
5.函数没有写返回值,拿到的是undefined
6.写了return,但是没有赋值,拿到的是undefined
7.null和undefined转化为number类型
null默认为0,undefined默认为NaN
45.token与session的区别
session:
随着交互式Web应用的兴起,比如,购物等需要登录的网站。引出了一个新的问题,那就是要记录哪些用户登录了系统进行了哪些操作,即要管理会话(什么是会话?简单的讲如果用户需要登录,那么就可以简单的理解为会话,如果不需要登录,那么就是简单的连接。),比如,不同用户将不同商品加入到购物车中, 也就是说必须把每个用户区分开。因为HTTP请求是无状态的,所以想出了一个办法,那就是给每个用户配发一个会话标识(Session id),简单的讲就是一个既不会重复,又不容易被找到规律以仿造的随机字符串,使得每个用户的收到的会话标识都不一样, 每次用户从客户端向服务端发起HTTP请求的时候,把这个字符串给一并发送过来, 这样服务端就能区分开谁是谁了,至于客户端(浏览器)如何保存这个“身份标识”,一般默认采用 Cookie 的方式,这个会话标识(Session id)会存在客户端的Cookie中。
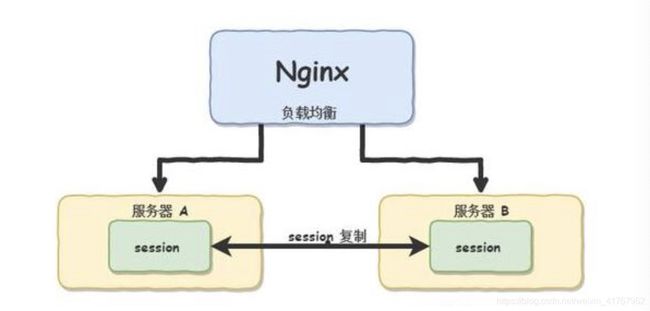
虽然这样解决了区分用户的问题,但又引发了一个新的问题,那就是每个用户(客户端)只需要保存自己的会话标识(Session id),而服务端则要保存所有用户的会话标识(Session id)。 如果访问服务端的用户逐渐变多, 就需要保存成千上万,甚至几千万个,这对服务器说是一个难以接受的开销 。 再比如,服务端是由2台服务器组成的一个集群, 小明通过服务器A登录了系统, 那session id会保存在服务器A上, 假设小明的下一次请求被转发到服务器B怎么办? 服务器B可没有小明 的 session id。
可能会有人讲,如果使小明登录时,始终在服务器A上进行登录(sticky session),岂不解决了这个问题?那如果服务器A挂掉怎么办呢? 还是会将小明的请求转发到服务器B上。
如此一来,那只能做集群间的 session 复制共享了, 就是把 session id 在两个机器之间进行复制,如下图,但这对服务器的性能和内存提出了巨大的挑战。
因此,又想到如果将所有用户的Session集中存储呢,也就想到了缓存服务Memcached——由于 Memcached 是分布式的内存对象缓存系统,因此可以用来实现 Session 同步。把session id 集中存储到一台服务器上, 所有的服务器都来访问这个地方的数据, 如此就避免了复制的方式, 但是这种“集万千宠爱于一身”使得又出现了单点故障的可能, 就是说这个负责存储 session 的服务器挂了, 所有用户都得重新登录一遍, 这是用户难以接受的。
token:
例如, 小明已经登录了系统,服务端给他发一个令牌(Token), 里边包含了小明的 user id, 后续小明再次通过 Http 请求访问服务器的时候, 把这个 Token 通过 Http header 带过来不就可以了。
服务端需要验证 Token是自己生成的,而非伪造的。假如不验证任何人都可以伪造,那么这个令牌(token)和 session id没有本质区别,如何让别人伪造不了?那就对数据做一个签名(Sign)吧, 比如说服务端用 HMAC-SHA256 加密算法,再加上一个只有服务端才知道的密钥, 对数据做一个签名, 把这个签名和数据一起作为 Token 发给客户端, 客户端收到 Token 以后可以把它存储起来,比如存储在 Cookie 里或者 Local Storage 中,由于密钥除了服务端任何其他用户都不知道, 就无法伪造令牌(Token)。
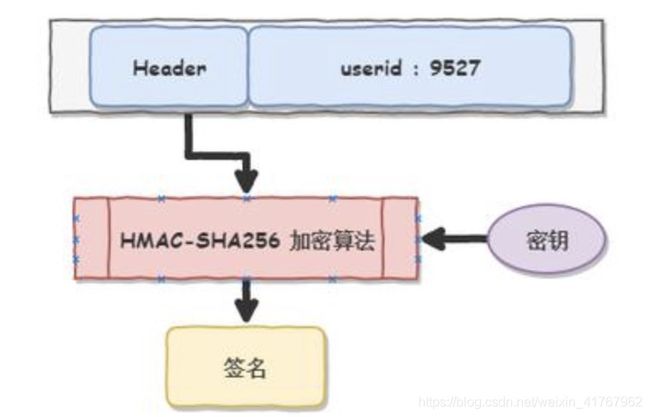
如此一来,服务端就不需要保存 Token 了, 当小明把这个Token发给服务端时,服务端使用相同的HMAC-SHA256 算法和相同的密钥,对数据再计算一次签名, 和 Token 中的签名做个对比, 如果相同,说明小明已经登录过了, 即验证成功。若不相同, 那么说明这个请求是伪造的。

这样一来, 服务端只需要生成 Token,而不需要保存Token, 只是验证Token就好了 ,也就实现了时间换取空间(CPU计算时间换取session 存储空间)。没了session id 的限制, 当用户访问量增大, 直接加机器就可以轻松地做水平扩展,也极大的提高了可扩展性。
46.cookie
var cookieParser = require('cookie-parser');
router.post("/setCookie",function(req,res, next){
var addr = req.body.a;
//设置cookie,配置signed: true的话可以配置签名cookie
res.cookie("addr", addr, {maxAge: 1000*60*60*24*30,httpOnly: true}); //, signed: true
next();
});
//获取cookie
var a=req.cookies.addr;
console.log(a);
//删除cookie
res.clearCookie("username");
//直接在html页面中通过js获取cookie
var arrStr=document.cookie.split(";");
for(var i=0;i<arrStr.length;i++){
var temp=arrStr[i].split("=");
if(temp[0]==objName){
decodeURIComponent(temp[1])//解码
}
}
cookie的同类请求指的是资源路径相同:URL:资源路径+资源名称
cookie的禁用(客户端不在接收cookie,对服务端是没有任何的影响的)
cookie属性
max-age
过期时间有多长
默认在浏览器关闭时失效
expires
到哪个时间点过期
secure
表示这个cookie只会在https的时候才会发送
HttpOnly
设置后无法通过在js中使用document.cookie访问
保障安全,防止攻击者盗用用户cookie
domain
表示该cookie对于哪个域是有效的。
47.session
session,即会话,是web开发中的一种会话状态跟踪技术。当然,前面所讲述的cookie也是会话跟踪技术。不同的是cookie是将会话状态保存在了客户端,而session则是将会话状态保存在了服务器端。
那么到底什么是“会话”?当用户打开浏览器,从发出第一请求开始,一直到最终关闭浏览器,就表示一次会话的完成。
session的工作原理
在服务器中系统会为每个会话维护一个session不同的会话,对应不同的session。那么,在系统是如何识别各个session对象的?即是如何做到在同一个会话过程中,一直使用的是同一个session对象呢?
(1)写入session列表
服务器对当前应用中的session是以Map的形式进行管理的,这个Map称为session列表。该Map的key为一个32位长度的随机串,这个随机串称为JSsessionID,value则为Session对象的引用。
当用户第一次提交请求时,服务端中执行到request.getSession()方法时,会自动生成一个Map.Entry对象,key为一个根据某种算法新生成的JSsessionID,value则为新创建的HttpSession对象。

(2)服务器生成并发送cookie
在将session信息写入session列表后,系统还会自动将“JSESSIONID”作为name,这个32位长度的随机串作为value,以cookie的形式存放到响应报头中,并随着响应,将该cookie发送到客户端。
(3)客户端接收并发送cookie
客户端接收到这个cookie后会将其存放到浏览器的缓存中。即,只要客户端浏览器不关闭,浏览器缓存中的cookie就不会消失。
当用户提交第二次请求时,会将缓存中的这个cookie,伴随着请求的头部信息,一块发送到服务端。
(4)从session列表中查找
服务端从请求中读取到客户端发送来的cookie,并根据cookie的sessionid的值,从map中查找相应key所对应的value,即session对象。然后,对该session对象的域属性进行读写操作。
session的失效时间
session的默认超时时间为30分钟, 需要再次强调的是,这个时间并不是从session被创建开始计时的生命周期时长,而是从最后一次被访问开始计时,在指定时长内一直未被访问的时长。
cookie禁用后使用session进行会话跟踪
从前面session的工作原理可知,服务器之所以可以针对不同的会话找到不同的session,是因为cookie完成了会话的跟踪。但是,若客户 端浏览器将cookie禁用后,那么服务器还怎样保证同一个会话使用的是同一个session呢?
若客户端浏览器禁用了cookie,会发现向服务器所提交的每一次请求,服务器在给出的响应中都会包含名称为JSESSIONID的cookie,只不过这个cookie的值每一次都不同。也就是说,只要客户端浏览器所提交的请求中没有包含JSESSIONID,服务器就会认为这是一次新的会话的开始,就会为其生成一个Map.Entry对象,key为新的32位长度的随机串,value为新创建的session会话引用。这样就无法实现会话的跟踪。
cookie禁用以后,session还是能够可以进行访问的,通过url+jsessionid=32位长度的随机串。
48.referer
Referer是HTTP请求Header的一部分,当浏览器向Web服务器发送请求的时候,请求头信息一般需要包含Referer。该Referer会告诉服务器我是从哪个页面链接过来的,服务器基此可以获得一些信息用于处理。
referer作用是什么?
(1).防盗链
比如办事通服务器只允许网站访问自己的静态资源,那服务器每次都需要判断Referer的值是否是zwfw.yn.gov.cn,如果是就继续访问,不是就拦截。
(2).防止恶意请求
比如静态请求是.html结尾的,动态请求是.shtml,那么所有的*.shtml请求,必须 Referer为我自己的网站才可以访问,这就是Referer的作用。
(3).空referer怎么回事?
空Referer是指Referer头部的内容为空,或者,一个HTTP 请求头中根本不包含Referer,那么什么时候HTTP请求会不包含Referer字段呢?
根据Referer的定义,它的作用是指示一个请求是从哪里链接过来,那么当一个请求并不是由链接触发产生的,那么自然也就不需要指定这个请求的链接来源。
比如,直接在浏览器的地址栏中输入一个资源的URL地址,那么这种请求是不会包含Referer字段的,因为这是一个“凭空产生”的HTTP请求,并不是从一个地方链接过去的。
比如说:你在百度中访问一张图片,你通过在URL地址中直接输入该地址图片能够访问的到,但是你通过标签就无法访问到,是因为referer在作怪。
49.实现一个简单的promise
function Promise(executor){
let self=this;
self.status="pending";//等待态
self.value=undefined;//成功的返回值
self.reason=undefined;//失败的原因
function resolve(value){
if(self.status=="pending"){
self.status="resolved";
self.value=value;
}
}
function reject(reason){
if(self.status=="pending"){
self.status="reject";
self.reason=reason;
}
}
try{
executor(resolve,reject);
}catch(e){
reject(e);
}
}
//onFufilled 成功的回调
//onRejected 失败的回调
Promise.prototype.then=function(onFufilled,onRejected){
let self=this;
if(self.status==="resolved"){
onFufilled(self.value);
}
if(self.status==="rejected"){
onRejected(self.reason);
}
}
module.exports=Promise;
50.BFC
1.BFC直译为“块级格式化上下文”。它是一个独立的渲染区域。
2.BFC作用:
(1).利用BFC避免外边距折叠
(2).清楚内部浮动
(3).避免文字环绕
//避免文字环绕
<div style="height: 100px;width: 100px;float: left;background: #ff5555"></div>
<div style="width: 200px; height: 200px;background: #eee">我是一个没有设置浮动,
也没有触发 BFC 元素,我是一个没有设置浮动,
也没有触发 BFC 元素,</div>

这时候其实第二个元素有部分被浮动元素所覆盖,(但是文本信息不会被浮动元素所覆盖) 如果想避免元素被覆盖,可触第二个元素的 BFC 特性,在第二个元素中加入 overflow: hidden,就会变成:

3.如何生成BFC
(1).根元素,即html元素
(2).float的值不为none
(3).position:absolute,fixed
(4).overflow不为visible
(5).display:inline-block
4.BFC布局规则
(1).内部的box会在垂直方向,一个接一个地放置
(2).属于同一个BFC的两个相邻的Box的margin会发生重叠
解决方案如下:
<!--html-->
<div class="container">
<div class="box">
</div>
<div class="box02">
</div>
</div>
<!--css-->
.container{
width:200px;
height:200px;
border:2px solid red;
overflow:hidden;
}
.box{
width:50px;
height:50px;
background-color:blue;
margin-bottom:20px;
float:left;
}
.box02{
width:50px;
height:50px;
background-color:yellow;
margin-top:90px;
}
(3).BFC的区域不会与float box重叠(文字环绕)
(4).计算BFC的高度时,浮动元素也要计算进去(清除浮动)
51.IFC
内联格式化上下文
1.生成IFC的条件
(1).块级元素中仅包含内联级别元素。
2.IFC布局规则
(1).子元素水平方向横向排列,且垂直方向起点为元素顶部。
(2).子元素只会计算横向样式空间【padding、border、margin】,垂直方向样式空间不会被计算【padding、border、margin】
<!--html-->
<div class="warp
<span class="text">文本一</span>
<span class="text">文本二</span>
</div>
<!--css-->
.warp { border: 1px solid red; display: inline-block; }
.text { margin: 20px; background: green; }

(3).当一个"inline box"超过父元素的宽度时,它会被分割成多个boxes,这些boxes分布在多个"line box"。如果子元素未设置强制换行的情况下,"inline box"将不可被分割,将会溢出父元素。
<!--html-->
<div class="warp">
<span class="text">dsdsdsdsdsdsdsdsdsdsdsdsdsdsdsdsddsdsdssddsdsdsdddsdsd发送到大大的三大但是的但是的大多数</span>
</div>
<!--css-->
.warp{
border:1px solid red;
width:200px;
}
.text{
background:green;
word-wrap:break-word;//超过边界换行
}
 (4).当inline-level boxes的总宽度少于包含它们的line box时,其水平渲染规则由text-align属性值来决定
(4).当inline-level boxes的总宽度少于包含它们的line box时,其水平渲染规则由text-align属性值来决定
<!--css-->
.warp{border:1px solid red;width:200px;text-align:center;}
.text{background:green;}
<!--html-->
<div class="wrap">
<span class="text">文本一</span>
<span class="text">文本二</span>
</div>

52.你对line-height是如何理解的?
(1).line-height 指一行字的高度,包含了字间距,实际上是下一行基线到上一行基线距离
(2).如果一个标签没有定义 height 属性,那么其最终表现的高度是由 line-height 决定的
(3). 一个容器没有设置高度,那么撑开容器高度的是 line-height 而不是容器内的文字内容
(4).把 line-height 值设置为 height 一样大小的值可以实现单行文字的垂直居中
line-height三种赋值方式有何区别?
(1).px是固定值,如果设置为em时,首先看下自己有没有设置font-size,如果设置了以自己为准,如果没有设置,去父元素寻找。
(2).会把比例传递给后代。例如,父级行高为1.5,子元素字体为18px,则子元素行高为1.5*18px。
(3).百分比:将计算后的值传递给后代,line-height的百分比是按照字体大小来的。因为line-height具有继承性,所以可以写在父元素上面照样是可以继承的。
53.css换行几种方式
1.强制不换行
div{white-space:nowrap;}
2.自动换行
div{
word-wrap:break-word;
}
3.强制英文单词断行
div{
word-break:break-all;
}
54.CSS单位
1.em相对单位。不同的属性有不同的参照值。
(1).对于字体大小属性来说,em的计算方式是相对于父元素的字体大小
(2).border,width,height,padding,margin,line-height这些属性中,使用em单位的计算方式是参照该元素的font-size,1em等于该元素设置的字体大小。同理如果该元素没有设置,则一直向父级元素查找,直到找到,如果都没有设置大小,则使用浏览器默认的字体大小。
2.vw,vh,vmin,vmax相对单位,是基于视窗大小(浏览器用来显示内容的区域大小)来计算的。
vw:基于视窗的宽度计算,1vw等于视窗宽度的百分之一
vh:基于视窗的高度计算,1vh等于视窗高度的百分之一
vmin:基于vw和vh中的最小值来计算,1vmin等于最小值的百分之一
vmax:基于vw和vh中的最大值来计算,1vmax等于最大值的百分之一
transform中的skew(倾斜转换)
skewX(10deg)//逆时针方向倾斜
skewX(-10deg)//顺时针方向倾斜
skewY(10deg)//顺时针方向倾斜
skewY(-10deg)//逆时针方向倾斜
55.如何水平居中一个元素?
1.如果需要居中的元素为inline-block,为父元素设置text-align:center;
2.如果要居中的元素为一个块级元素的话,一般使用margin:0 auto;进行居中。
56.display:inline-block什么时候会显示间隙?
1.相邻的inline-block元素之间有换行或空格分隔的情况下会产生间隙
2.可以在父级加font-size:0;在子元素里设置需要的字体大小,消除垂直间隙
57.移动端项目需要注意的4个问题
1.meta中设置viewport
阻止用户手滑放大或缩小页面,需要在index.html中添加meta元素,设置viewport
<meta name="viewport" content="width=device-width,initial-scale=1.0,minimum-scale=1.0,maximum-scale=1.0,user-scalable=no">
2.css样式统一问题
我们需要重置页面样式,因为在不同的手机浏览器上,默认的css样式不是统一的。 解决方法:使用reset.css重置所有元素的默认样式
3.300毫秒点击延迟问题
在移动端开发中,某些机型上使用click事件会延迟300ms才执行,这样影响了用户体验。 解决方法: 引入fastclick.js。
58.DOM和html的关系
程序员用html语言,写html文件,其中包含了很多标签,如等。浏览器在解析html文件时,会在它内部,按照标签构建一个树状逻辑组织,这就是DOM。构建DOM后,浏览器按顺序解析每个标签,完成解析后,用户就看到了网页的结构。
itemprop=“image”
59.var、let 及 const 区别?
1.全局申明的var变量会挂载在window上,而let和const不会
2.var声明变量存在变量提升,let和const不会
3.let、const 的作用范围是块级作用域,而var的作用范围是函数作用域
function test(){
for(var i=0;i<10;i++){
console.log(i)
}
console.log(i)
}//正常输出
function test(){
for(let i=0;i<10;i++){
console.log(i);
}
console.log(i);
}//报错,说没有定义i
4.同一作用域下let和const不能声明同名变量,而var可以
5.const
一旦声明必须赋值,不能使用null占位
声明后不能再修改
如果声明的是复合类型数据,可以修改其属性
60.filter和reduce
filter 的作用也是生成一个新数组,在遍历数组的时候将返回值为 true 的元素放入新数组,我们可以利用这个函数删除一些不需要的元素
filter 的回调函数接受三个参数,分别是当前索引元素,索引,原数组
var arr=[1,2,3,4]
console.log(arr.filter(function(item){
if(item>1){
return item
}
}))
console.log(arr)//原数组不会受到影响
reduce首先初始值为 0,该值会在执行第一次回调函数时作为第一个参数传入回调函数接受四个参数,分别为累计值、当前元素、当前索引、原数组,后三者想必大家都可以明白作用,这里着重分析第一个参数。
var arr=[1,2,3,4]
console.log(arr.reduce(function(acc,cur){
return acc=acc+cur;
},0))//10
61.Es6中箭头函数与普通函数的区别?
1.普通function的声明在变量提升中是最高的,箭头函数没有函数提升
2.箭头函数没有属于自己的this,arguments
3.箭头函数不能作为构造函数,不能被new,没有property
62.async和await
一个函数如果加上async,那么该函数就会返回一个Promise
async function test(){
return "1"
}
test().then(function(value){console.log(value)})
63.BOM与DOM的关系
1.javacsript 是通过访问 BOM 对象来访问、 控制、 修改浏览器
2.BOM 的 window 包含了 document, 因此通过 window 对象的 document 属性就可以访问、 检索、 修改文档内容与结构。
3.document 对象又是 DOM 模型的根节点。
4.因此, BOM 包含了 DOM, 浏览器提供出来给予访问的是 BOM 对象, 从 BOM 对象再访问到 DOM 对象, 从而 js 可以操作浏览器以及浏览器读取到的文档
64.BOM 对象包含哪些内容?
Window JavaScript 层级中的顶层对象, 表示浏览器窗口。
Navigator 包含客户端浏览器的信息。
History 包含了浏览器窗口访问过的 URL。
Location 包含了当前 URL 的信息。
Screen 包含客户端显示屏的信息。
65.offsetWidth/offsetHeight,clientWidth/clientHeight 与 scrollWidth/scrollHeight 的区别
1.offsetWidth/offsetHeight 返回值包含 content + padding + border,效果与 e.getBoundingClientRect()相同
2.clientWidth/clientHeight 返回值只包含 content + padding,如果有滚动条,也不包含滚动条
3.scrollWidth/scrollHeight 返回值包含 content + padding + 溢出内容的尺寸
document.documentElement.clientWidth
IE:document.body.clientWidth
66.DOM事件级别
DOM0
onXXX类型的定义事件
element.onclick = function(e) { … }
DOM2
addEventListener方式
element.addEventListener(‘click’, function (e) { … })
btn.removeEventListener(‘click’, func, false)
btn.attachEvent(“onclick”, func);
btn.detachEvent(“onclick”, func);
DOM3
增加了很多事件类型
element.addEventListener(‘keyup’, function (e) { … })
eventUtil 是自定义对象,textInput 是 DOM3 级事件
67.DOM事件模型

window—>document—>body–>目标元素
68.JS获取dom的CSS样式
function getStyle(obj, attr){
if(obj.currentStyle){
return obj.currentStyle[attr];
} else {
return window.getComputedStyle(obj, false)[attr];
}
}
//getComputedStyle
69.documen.write 和 innerHTML 的区别
1.document.write 只能重绘整个页面
2.innerHTML 可以重绘页面的一部分
70.window对象与document对象
window
1.Window 对象表示当前浏览器的窗口,是 JavaScript 的顶级对象。
2.我们创建的所有对象、函数、变量都是 Window 对象的成员。
3.Window 对象的方法和属性是在全局范围内有效的。
document
1.Document 对象是 HTML 文档的根节点与所有其他节点(元素节点,文本节点,属性节点, 注释节点)

2.Document 对象使我们可以通过脚本对 HTML 页面中的所有元素进行访问
document.getElementById()
document.getElementsByTagName()
document.getElementsByName()
3.Document 对象是 Window 对象的一部分,即 window.document
71.区分什么是“客户区坐标”、“页面坐标”、“屏幕坐标”
1.客户区坐标(可视窗口)
鼠标指针在可视区中的水平坐标(clientX)和垂直坐标(clientY)
let obj=document.getElementsByTagName("html")[0];
obj.addEventListener("click",function(event){
alert(event.clientX);
})
2.页面坐标
鼠标指针在页面布局中的水平坐标(pageX)和垂直坐标
let obj=document.getElementsByTagName("html")[0];
obj.addEventListener("click",function(event){
alert(event.pageX);
})
3.屏幕坐标
设备物理屏幕的水平坐标(screenX)和垂直坐标(screenY)
let obj=document.getElementsByTagName("html")[0];
obj.addEventListener("click",function(event){
alert(event.screenX);
})
72.多进程和多线程
以Chrome浏览器中为例,当你打开一个 Tab 页时,其实就是创建了一个进程,一个进程中可以有多个线程(下文会详细介绍),比如渲染线程、JS 引擎线程、HTTP 请求线程等等。当你发起一个请求时,其实就是创建了一个线程,当请求结束后,该线程可能就会被销毁。
73.浏览器内核
1.渲染线程
(1).主要负责页面的渲染,解析html、css、构建dom树,布局和绘制等。
(2).当界面需要重绘或者由于某种操作引发回流时,将执行该线程。
(3).该线程与JS引擎线程互斥,当执行JS引擎线程时,GUI渲染会被挂起,当任务队列空闲时,主线程才会去执行GUI渲染
2.js引擎线程
(1).该线程当然是主要负责处理js脚本,执行代码。
(2).也是主要负责执行准备好待执行的事件,即定时器计数结束,或者异步请求成功并正确返回时,将依次进入任务队列,等待js引擎线程的执行。
3.定时器触发线程
(1).负责执行异步定时器一类的函数的线程,如: setTimeout,setInterval。
(2).主线程依次执行代码时,遇到定时器,会将定时器交给该线程处理,当计数完毕后,事件触发线程会将计数完毕后的事件加入到任务队列的尾部,等待JS引擎线程执行。
4.事件触发线程
(1).主要负责将准备好的事件交给 JS引擎线程执行。
比如 setTimeout定时器计数结束, ajax等异步请求成功并触发回调函数,或者用户触发点击事件时,该线程会将整装待发的事件依次加入到任务队列的队尾,等待 JS引擎线程的执行。
5.异步http 请求线程
(1).负责执行异步请求一类的函数的线程,如: Promise,axios,ajax等。
(2).主线程依次执行代码时,遇到异步请求,会将函数交给该线程处理,当监听到状态码变更,如果有回调函数,事件触发线程会将回调函数加入到任务队列的尾部,等待JS引擎线程执行。
74.浏览器端事件循环中异步队列
常见的 macro-task 比如:setTimeout、setInterval、script(整体代码)、I/O 操作、UI 渲染等。
常见的 micro-task 比如: new Promise().then(回调)、MutationObserver(html5新特性) 等。
74.Node中的Event Loop
(1).V8引擎解析js脚本
(2).解析后的代码,调用Node API
(3).libuv库负责Node API的执行。它将不同的任务分配给不同的线程,形成一个Event Loop(事件循环),以异步的方式将任务的执行结果返回给V8引擎。
(4).V8引擎再将结果返回给用户
2.Node事件循环分为6个阶段:
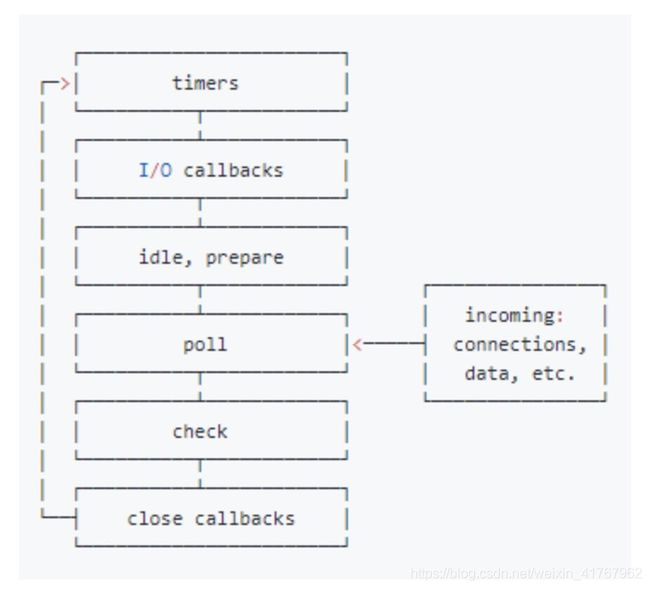
从上图中,大致看出node中的事件循环的顺序:
外部输入数据—>轮询阶段(poll)—>检查阶段(check)—>关闭事件回调阶段(close callback)—>定时器检测阶段(timers)—>I/O事件回调阶段(I/O callbacks)—>闲置阶段(idle,prepare)—>轮询阶段(按照该顺序反复运行)
(1).timers阶段:这个阶段执行timers(setTimeout,setInterval)的回调
(2).I/Ocallbacks阶段:处理一些上一轮循环中的少数未执行的I/O回调
(3).idle,prepare阶段:仅node内部使用
(4).poll阶段:获取新的I/O事件, 适当的条件下node将阻塞在这里
(5).check 阶段:执行 setImmediate() 的回调
(6).close callbacks 阶段:执行 socket 的 close 事件回调
timers 阶段会执行 setTimeout 和 setInterval 回调,并且是由 poll 阶段控制的。同样,在 Node 中定时器指定的时间也不是准确时间,只能是尽快执行。
poll 是一个至关重要的阶段,这一阶段中,系统会做两件事情
(1).回到 timer 阶段执行回调
(2).执行 I/O 回调
并且在进入该阶段时如果没有设定了 timer 的话,会发生以下两件事情
如果 poll 队列不为空,会遍历回调队列并同步执行,直到队列为空或者达到系统限制
如果 poll 队列为空时,会有两件事发生:
(1)如果有 setImmediate 回调需要执行,poll 阶段会停止并且进入到 check 阶段执行回调
(2).如果没有 setImmediate 回调需要执行,会等待回调被加入到队列中并立即执行回调,这里同样会有个超时时间设置防止一直等待下去
当然设定了 timer 的话且 poll 队列为空,则会判断是否有 timer 超时,如果有的话会回到 timer 阶段执行回调。
check:setImmediate()的回调被加入check队列中,从event loop的阶段图可以知道,check阶段的执行顺序在poll阶段之后。
3.Micro-Task与Macro-Task
Node端事件循环中的异步队列也是这两种:macro(宏任务)队列和 micro(微任务)队列。
(1).常见的 macro-task 比如:setTimeout、setInterval、 setImmediate、script(整体代码)、 I/O 操作等。(setImmediate比setTimeout厉害点,即当两者在异步I/o callback内部调用时,总是先执行setImmediate,再执行setTimeout)
(2).常见的 micro-task 比如: process.nextTick、new Promise().then(回调)等。
process.nextTick
这个函数其实是独立于 Event Loop 之外的,它有一个自己的队列,当每个阶段完成后,如果存在 nextTick 队列,就会清空队列中的所有回调函数,并且优先于其他 microtask 执行。
4.Node与浏览器的Event Loop差异
Node端,microtask在事件循环的各个阶段之间执行
浏览器端,microtask在事件循环的macrotask执行完之后执行
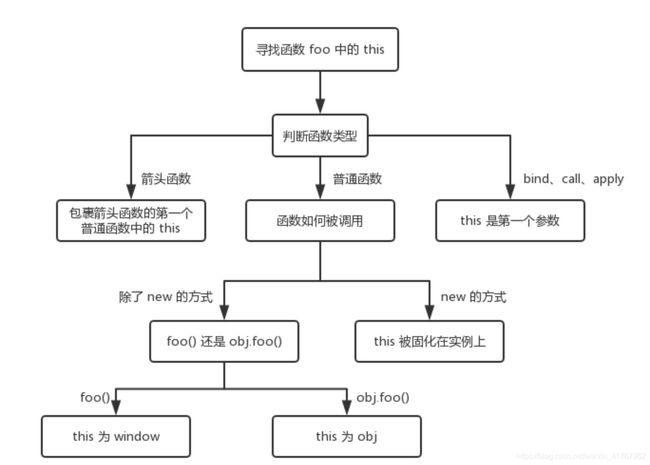
75.this的指向有哪几种情况?
1.作为函数直接调用,非严格模式下,this指向window,严格模式下,this指向undefined;
2.作为某对象的方法调用,this通常指向调用的对象。
3.使用apply、call、bind 可以绑定this的指向。
4.在构造函数中,this指向新创建的对象
5.箭头函数没有单独的this值,this在箭头函数创建时确定,它与声明所在的上下文相同。
76.宏任务和微任务
1.宏任务:可以理解每次执行栈执行的代码就是一个宏任务
宏任务主要包含script,setTimeout、setInterval、setImmediate(nodejs环境)
2.微任务
在当前任务task执行结束后立即执行的任务。也就是说,在当前task任务后,下一个task之前,在渲染之前。
微任务主要包含promise.then、process.nextTick(nodejs环境)
77.await
从字面意思上看await就是等待,await 等待的是一个表达式,这个表达式的返回值可以是一个promise对象也可以是其他值。
很多人以为await会一直等待之后的表达式执行完之后才会继续执行后面的代码,实际上await是一个让出线程的标志。await后面的表达式会先执行一遍,将await后面的代码加入到microtask中,然后就会跳出整个async函数来执行后面的代码。
78.为什么JavaScript是单线程?
JavaScript语言的一大特点就是单线程,也就是说,同一个时间只能做一件事。那么,为什么JavaScript不能有多个线程呢?这样能提高效率啊。
JavaScript的单线程,与它的用途有关。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
所以,为了避免复杂性,从一诞生,JavaScript就是单线程,这已经成了这门语言的核心特征,将来也不会改变。
79.作用域相关问题,使之分别打印10和20
var b=10;
(function b(){
b=20;
console.log(b);
})()
//输出结果是:
//function b(){
//b=20;
//console.log(b);
//}
讲解一下立即执行函数

立即执行函数的好处:
1.不必为函数命名,避免了污染全局变量
2.立即执行函数内部形成了一个单独的作用域,可以封装一些外部无法读取的私有变量
var liList = ul.getElementsByTagName('li')
for(var i=0; i<6; i++){
liList[i].onclick = function(){
alert(i) // 为什么 alert 出来的总是 6,而不是 0、1、2、3、4、5
}
}
原因是用户一定是在for运行完了之后,才点击的,此时i为6
var liList = ul.getElementsByTagName('li')
for(var i=0; i<6; i++){
!function(ii){
liList[ii].onclick = function(){
alert(ii) // 0、1、2、3、4、5
}
}(i)
}
//原因是用立即执行函数给每个li创造一个独立作用域即可(当然还有其他办法)
//立即执行函数中this的指向问题
for(var i=0;i<6;i++){
(function(){
console.log(this)//this指向的是window
})()
}
打印10:
var b=10;
(function b(b){
window.b=20;
console.log(b);
})(b)//10
打印20:
var b=10;
(function(b){
b=20;
console.log(b)
})(b)
80.求一个字符串的字节长度
假设:一个英文字符占用一个字节,一个中文字符占用两个字节
function GetBytes(str){
var len = str.length;
var bytes = len;
for(var i=0; i<len; i++){
if (str.charCodeAt(i) > 255) bytes++;//确定是不是中文--charCodeAt返回字符串的Unicode编码 str.charCodeAt()
}
return bytes;
}
alert(GetBytes("你好,as"));
81.数组扁平化
数组扁平化是指将一个多维数组变为一维数组
递归法:
1.function test(str){
return str.join(",").split(",").map(function(item){ return parseInt(item)});
}
console.log(test(arr))
2.function flatten(arr){
return arr.reduce(function(prev, cur){
return prev.concat(Array.isArray(cur) ? flatten(cur) : cur)
},[])
}
82.手写原生ajax
xhr.open("POST", url, true);
xhr.setRequestHeader("Content-Type": "application/x-www-form-urlencoded");
xhr.send("key1=value1&key2=value2");
83.http
1.http协议的特点
无连接
限制每次连接只处理一个请求
无状态
协议对于事务处理没有记忆能力。
简单快速
客户向服务器请求服务时,只需传送请求方法和路径。
灵活
HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
2.请求报文
1.请求行(请求类型,要访问的资源,http协议版本号)
![]()
2.请求头
用来说明服务器要使用的附加信息(一些键值对)
例如:User-Agent、 Accept、Content-Type、Connection

cookie :发送请求的携带cookie信息
accept:告诉WEB服务器自己接受什么介质类型,/ 表示任何类型,type/* 表示该类型下的所有子类型,type/sub-type空行
Host:访问的服务器域名
User-Agent:浏览器信息
Accept-Language:浏览器申明自己可以接收的语言
Accpet-Encoding:浏览器申明自己接收的编码类型,通常指定的是压缩方法,是否支持压缩
3.请求体
可以添加任意的其他数据
3.响应报文
1.状态行(状态码,状态信息,http协议版本号)
![]()
2.消息报头
说明客户端要使用的一些附加信息
如:Content-Type、charset、响应的时间

content-type:表示文档属于什么MIME类型
set-cookie:设置cookie信息
cache-control:请求和响应遵循的缓存机制
ETag:标识
Last-Modifie:最后修改的时间
3.响应正文
返回给客户端的文本信息
4.HTTP2
二进制传输:之前的版本采用的是文本的方式进行传输,现在采用二进制格式编码
多路复用:http2中同域名下所有通信都在单个连接上完成,消除了因多个TCP连接而带来的延时和内存消耗。
Header压缩
服务端推送:服务端可以在客户端某个请求后,主动推送其他资源。
5.https的密码学基础
1.明文: 明文指的是未被加密过的原始数据。
2.密文:明文被某种加密算法加密之后,会变成密文,从而确保原始数据的安全。密文也可以被解密,得到原始的明文。
3.密钥:密钥是一种参数,它是在明文转换为密文或将密文转换为明文的算法中输入的参数。密钥分为对称密钥与非对称密钥,分别应用在对称加密和非对称加密上。
对称加密
对称加密又叫做私钥加密,即信息的发送方和接收方使用同一个密钥去加密和解密数据。对称加密的特点是算法公开、加密和解密速度快,适合于对大数据量进行加密,常见的对称加密算法有DES、3DES、TDEA、Blowfish、RC5和IDEA。
其加密过程如下:明文 + 加密算法 + 私钥 => 密文
解密过程如下:密文 + 解密算法 + 私钥 => 明文
对称加密中用到的密钥叫做私钥,私钥表示个人私有的密钥,即该密钥不能被泄露。
其加密过程中的私钥与解密过程中用到的私钥是同一个密钥,这也是称加密之所以称之为“对称”的原因。由于对称加密的算法是公开的,所以一旦私钥被泄露,那么密文就很容易被破解,所以对称加密的缺点是密钥安全管理困难。
非对称加密
非对称加密也叫做公钥加密。非对称加密与对称加密相比,其安全性更好。对称加密的通信双方使用相同的密钥,如果一方的密钥遭泄露,那么整个通信就会被破解。而非对称加密使用一对密钥,即公钥和私钥,且二者成对出现。私钥被自己保存,不能对外泄露。公钥指的是公共的密钥,任何人都可以获得该密钥。用公钥或私钥中的任何一个进行加密,用另一个进行解密。
被公钥加密过的密文只能被私钥解密,过程如下:
明文 + 加密算法 + 公钥 => 密文, 密文 + 解密算法 + 私钥 => 明文
被私钥加密过的密文只能被公钥解密,过程如下:
明文 + 加密算法 + 私钥 => 密文, 密文 + 解密算法 + 公钥 => 明文
由于加密和解密使用了两个不同的密钥,这就是非对称加密“非对称”的原因。 非对称加密的缺点是加密和解密花费时间长、速度慢,只适合对少量数据进行加密。 在非对称加密中使用的主要算法有:RSA、Elgamal、Rabin、D-H、ECC(椭圆曲线加密算法)等。
HTTPS为了兼顾安全与效率,同时使用了对称加密和非对称加密。数据是被对称加密传输的,对称加密过程需要客户端的一个密钥,为了确保能把该密钥安全传输到服务器端,采用非对称加密对该密钥进行加密传输,总的来说,对数据进行对称加密,对称加密所要使用的密钥通过非对称加密传输。
6.CDN
CDN(Content Delivery Network,内容分发网络)是构建在现有互联网基础之上的一层智能虚拟网络,通过在网络各处部署节点服务器,实现将源站内容分发至所有CDN节点,使用户可以就近获得所需的内容。CDN服务缩短了用户查看内容的访问延迟,提高了用户访问网站的响应速度与网站的可用性,解决了网络带宽小、用户访问量大、网点分布不均等问题。
加速原理
当用户访问使用CDN服务的网站时,本地DNS服务器通过CNAME方式将最终域名请求重定向到CDN服务。CDN通过一组预先定义好的策略(如内容类型、地理区域、网络负载状况等),将当时能够最快响应用户的CDN节点IP地址提供给用户,使用户可以以最快的速度获得网站内容。使用CDN后的HTTP请求处理流程如下:
CDN节点有缓存场景
1.用户在浏览器输入要访问的网站域名,向本地DNS发起域名解析请求。
2.域名解析的请求被发往网站授权DNS服务器。
3.网站DNS服务器解析发现域名已经CNAME到了www.example.com.c.cdnhwc1.com。
4.请求被指向CDN服务。
5.CDN对域名进行智能解析,将响应速度最快的CDN节点IP地址返回给本地DNS。
6.用户获取响应速度最快的CDN节点IP地址。
7.浏览器在得到速度最快节点的IP地址以后,向CDN节点发出访问请求。
8.CDN节点将用户所需资源返回给用户。
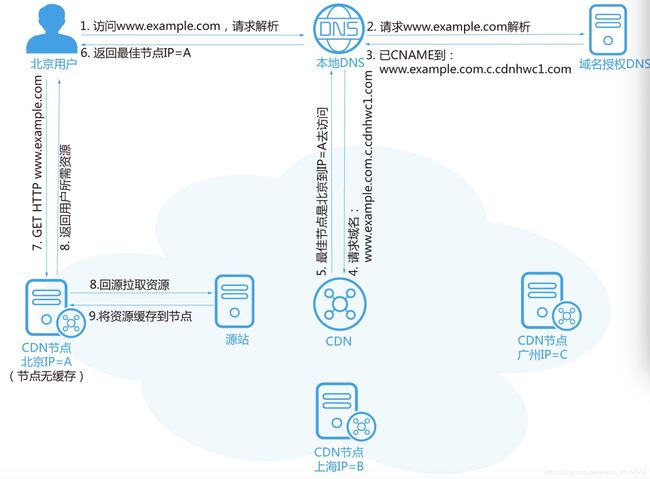
 CDN节点无缓存场景
CDN节点无缓存场景
1.用户在浏览器输入要访问的网站域名,向本地DNS发起域名解析请求。
2.域名解析的请求被发往网站授权DNS服务器。
3.网站DNS服务器解析发现域名已经CNAME到了www.example.com.c.cdnhwc1.com。
4.请求被指向CDN服务。
5.CDN对域名进行智能解析,将响应速度最快的CDN节点IP地址返回给本地DNS。
6.用户获取响应速度最快的CDN节点IP地址。
7.浏览器在得到速度最快节点的IP地址以后,向CDN节点发出访问请求。
8.CDN节点回源站拉取用户所需资源。
9.将回源拉取的资源缓存至节点。
10.将用户所需资源返回给用户。
6.CSRF防御
1.Get 请求不对数据进行修改
2.不让第三方网站访问到用户 Cookie
3.阻止第三方网站请求接口
4.请求时附带验证信息,比如验证码或者 Token
SameSite
可以对 Cookie 设置 SameSite 属性。该属性表示 Cookie 不随着跨域请求发送,可以很大程度减少 CSRF 的攻击,但是该属性目前并不是所有浏览器都兼容。
Token验证
cookie是发送时自动带上的,而不会主动带上Token,所以在每次发送时主动发送Token
Referer验证
对于需要防范 CSRF 的请求,我们可以通过验证 Referer 来判断该请求是否为第三方网站发起的。
隐藏令牌
主动在HTTP头部中添加令牌信息
攻击危害:
盗取用户资金
冒充用户发帖背锅
损坏网站名誉
基于promise实现jsonp 单行和多行css省率号 大数相加递归和非递归 二叉树的第k小的节点
7.XSS攻击
XSS ( Cross Site Scripting ) 是指恶意攻击者利用网站没有对用户提交数据进行转义处理或者过滤不足的缺点,进而添加一些代码,嵌入到web页面中去。使别的用户访问都会执行相应的嵌入代码。
从而盗取用户资料、利用用户身份进行某种动作或者对访问者进行病毒侵害的一种攻击方式。
XSS攻击的危害包括:
获取页面数据
获取cookie
劫持前端逻辑
发送请求
偷取网站任意数据
偷取用户资料
偷取用户密码和登陆态
欺骗用户
xss攻击分类
反射型
通过url参数直接注入。
发出请求时,XSS代码出现在URL中,作为输入提交到服务器端,服务端解析后返回,XSS代码随响应内容一起传回给浏览器,最后浏览器执行XSS代码。这个过程像一次反射,故叫做反射型XSS。
一个链接,里面的query字段中包含一个script标签,这个标签的src就是恶意代码,用户点击了这个链接后会先向服务器发送请求,服务器返回时也携带了这个XSS代码,然后浏览器将查询的结果写入Html,这时恶意代码就被执行了。
并不是在url中没有包含script标签的网址都是安全的,可以使用短网址来让网址变得很短。
存储型
存储型XSS会被保存到数据库,在其他用户访问(前端)到这条数据时,这个代码会在访问用户的浏览器端执行。
举个例子
比如攻击者在一篇文章的评论中写入了script标签,这个评论被保存数据库,当其他用户看到这篇文章时就会执行这个脚本。
8.SQL注入
所谓SQL注入,就是通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,后台执行SQL语句时直接把前端传入的字段拿来做SQL查询。
防御
1.永远不要信任用户的输入。
2.永远不要使用动态拼装sql。
3.不要把机密信息直接存放。
基于promise实现jsonp 单行和多行css省率号 大数相加递归和非递归 二叉树的第k小的节点‘
84.判断手机是竖屏还是横屏
window.onorientationchange=function(){
if(window.orientation==90||window.orientation==-90){
window.location.reload()
}
else{
window.location.reload()
}
}
//css判断横屏还是竖屏
@media screen and (orientation:portrait){}//竖屏
@media screen and (orientation:landscape){}//横屏
85.作用域和作用域链
1.作用域
定义了一个变量以后,此变量可以使用的范围
2.作用域链
(1).查找当前作用域,如果当前作用域声明了这个变量,可以直接访问
(2).查找当前作用域的上级作用域,也就是当前函数的上级函数,看看上级函数有没有声明,有就返回变量,没有继续下一步
(3).再往上查,直到全局作用域为止,有则返回,无则继续
(4).如果全局作用域中也没有,我们就认为这个变量未声明
86.promise.all
function promiseAll(promises){
return new Promise(function(resolve,reject){
if(!Array.isArray(promises)) return reject(new Error("must be array"))
var len=promises.length;
var result=[];
var count=0;
for(let i=0;i<len;i++){
Promise.resolve(promises[i]).then(function(value){
result.push(value);
count++;
if(count==len){
return resolve(result);
}
}).catch(function(reson){
return reject(reson);
})
}
})
}
87.自封装bind,call,apply
//bind
Function.prototype.mybind=function(that,...argu){
var self=that;
console.log(argu)//[1,2,3,4]
return function(){
var args=argu.concat(...arguments);
self.apply(self,args);
}
}
test.mybind(that,1,2,3,4)()
//call
var obj={
name:"aaa",
age:18,
say:function(a,b,c){console.log(this.name,a,b,c)}
}
var obj2={name:"bbb"};
Function.prototype.myCall=function(that,...argu){
that=that||window;
var fn=this;//指向say函数
console.log(this.name);//say;
var fnName=new Date()*1;
that[fnName]=fn;//在that对象上添加一个函数
that[fnName](...argu);//执行函数
delete that[fnName];//用完删除
}
obj.say.myCall(obj2,1,2,3);
//apply方法
var obj = {
name:'aaa',
age:18,
say:function(a, b, c) {
console.log(this.name, a, b, c);
}
}
var obj2 = {
name:'bbb',
}
Function.prototype.myApply(that, argu) {
that = that || window; //如果没有传默认window
var fn = this; //say函数
var fnName = this.name + new Date() * 1; //保证say函数的唯一性
console.log(...argu);//1,2,3
that[fnName] = fn; //在that对象上添加一个函数
that[fnName](...argu); //执行函数
delete that[fnName]; //用完就删除
}
obj.say.myApply(obj2, [1, 2, 3]);
88.防抖函数的应用
function debounce(handler, delay){
delay = delay || 300;
var timer = null;
return function(){
var _self = this,
_args = arguments;
console.log(this);//指向了obj,因为bind的缘故改变了this的指向,如果没有bind,this指向的是window
clearTimeout(timer);
timer = setTimeout(function(){
handler.apply(_self, _args);
}, delay);
}
}
function add(name) {
console.log(name+ ": " + this.index ++);
}
let obj={
index:0
}
let db_add=debounce(add,10).bind(obj);
//每隔500ms频繁调用3次自增函数,但因为防抖的存在,这3次只调用了一次
setInterval(function(){
db_add("1");
db_add("2");
db_add("3");
},500)
//
89.name值是多少
function A(name) {
this.name = name || 'Tom'
this.msg = "use 'this.' set in function"
}
function B() {};
B.prototype = A;
var b = new B();
console.log(b.name);//A
console.log(b.msg);//undefiend
//分析:
//b.name返回 A,是因为b上面没有name属性,他就会沿着原型链向上查找,然而 b.__proto__ 为函数A,每一个函数都有一个属性为name,其值是函数的名字。
//改进:B.prototype=new A();
90.用reduce实现map的功能
Array.prototype.map = function (callback) {
const array = this;
return array.reduce((acc, cur, index) => {
acc.push(callback(cur, index, array))
return acc
}, [])
}
91.this指向
function Foo() {
getName = function() {
console.log(1);
};
return this;
}
Foo.getName = function() {
console.log(2);
};
Foo.prototype.getName = function() {
console.log(3);
};
var getName = function() {
console.log(4);
};
function getName() {
console.log(5);
}
Foo.getName();//2
getName();//4,函数的提升
Foo().getName();//1
getName();//1
new Foo.getName()//2 Foo后面不带括号而直接".",那么点的优先级会比new的高
new Foo().getName();//3
92.实现一个类型判断函数
//var obj={"a":1}
obj["b"]=2;
console.log(obj)//obj={"a":1,"b":2}
function getType(target) {
//先处理最特殊的Null
if(target === null) {
return 'null';
}
//判断是不是基础类型
const typeOfT = typeof target
if(typeOfT !== 'object') {
return typeOfT;
}
//肯定是引用类型了
const template = {
"[object Object]": "object",
"[object Array]" : "array",
"[object Function]": "function",
// 一些包装类型
"[object String]": "string",
"[object Number]": "number",
"[object Boolean]": "boolean"
};
const typeStr = Object.prototype.toString.call(target);
return template[typeStr];
}
93.节流函数
function throttle(fn,delay){
delay=delay||300;
let timer=null;
booleanVal=true;
return function(){
let _self=this;
let argus=arguments;
if(!booleanVal) return
booleanVal=false;
timer=setTimeout(function(){
fn.apply(_self,argus);
booleanVal=true;
},delay)
}
}
94:缓存机制
1.Cache-Control的属性:
max-age:指定一个时间长度,在这个时间段内缓存是有效的,单位是s。例如设置 Cache-Control:max-age=31536000,也就是说缓存有效期为(31536000 / 24 / 60 * 60)天,第一次访问这个资源的时候,服务器端也返回了 Expires 字段,并且过期时间是一年后。
s-maxage:同 max-age,覆盖 max-age、Expires,但仅适用于共享缓存,在私有缓存中被忽略。
public:表明响应可以被任何对象(发送请求的客户端、代理服务器等等)缓存。
private:表明响应只能被单个用户(可能是操作系统用户、浏览器用户)缓存,是非共享的,不能被代理服务器缓存。
no-cache: 强制所有缓存了该响应的用户,在使用已缓存的数据前,发送带验证器的请求到服务器。不是字面意思上的不缓存。(即使用缓存前发送验证信息)
no-store 禁止缓存,每次请求都要向服务器重新获取数据。
协商缓存:
浏览器第一次请求一个资源的时候,服务器返回的header中会加上Last-Modify,Last-modify是一个时间标识该资源的最后修改时间,例如Last-Modify: Thu,31 Dec 2037 23:59:59 GMT。

ETag扩展说明
我们对ETag寄予厚望,希望它对于每一个url生成唯一的值,资源变化时ETag也发生变化。神秘的Etag是如何生成的呢?以Apache为例,ETag生成靠以下几种因子
文件的i-node编号,此i-node非彼iNode。是Linux/Unix用来识别文件的编号。是的,识别文件用的不是文件名。使用命令’ls –I’可以看到。
文件最后修改时间
文件大小
生成Etag的时候,可以使用其中一种或几种因子,使用抗碰撞散列函数来生成。所以,理论上ETag也是会重复的,只是概率小到可以忽略。
既生Last-Modified何生Etag?
你可能会觉得使用Last-Modified已经足以让浏览器知道本地的缓存副本是否足够新,为什么还需要Etag(实体标识)呢?HTTP1.1中Etag的出现主要是为了解决几个Last-Modified比较难解决的问题:
- Last-Modified标注的最后修改只能精确到秒级,如果某些文件在1秒钟以内,被修改多次的话,它将不能准确标注文件的修改时间
- 如果某些文件会被定期生成,当有时内容并没有任何变化,但Last-Modified却改变了,导致文件没法使用缓存
3.有可能存在服务器没有准确获取文件修改时间,或者与代理服务器时间不一致等情形
Etag是服务器自动生成或者由开发者生成的对应资源在服务器端的唯一标识符,能够更加准确的控制缓存。Last-Modified与ETag是可以一起使用的,服务器会优先验证ETag,一致的情况下,才会继续比对Last-Modified,最后才决定是否返回304。
Expires的缺点
该字段会返回一个时间,比如Expires:Thu,31 Dec 2037 23:59:59 GMT。这个时间代表着这个资源的失效时间,也就是说在2037年12月31日23点59分59秒之前都是有效的,即命中缓存。这种方式有一个明显的缺点,由于失效时间是一个绝对时间,所以当客户端本地时间被修改以后,服务器与客户端时间偏差变大以后,就会导致缓存混乱。于是发展出了Cache-Control。
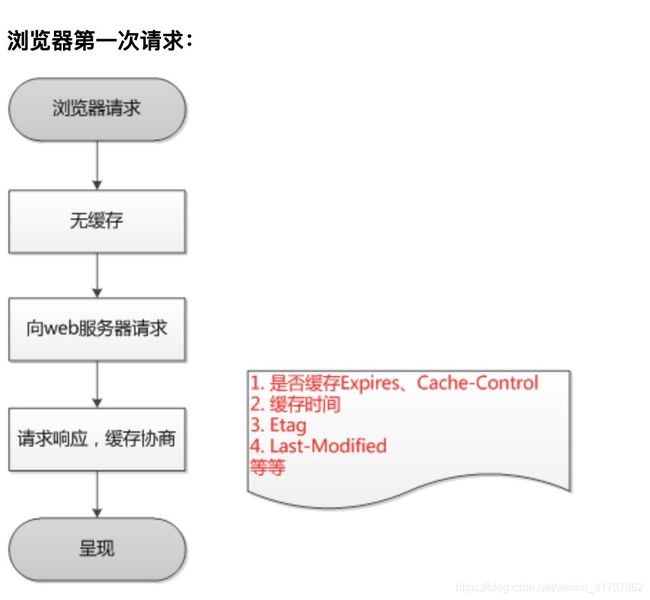
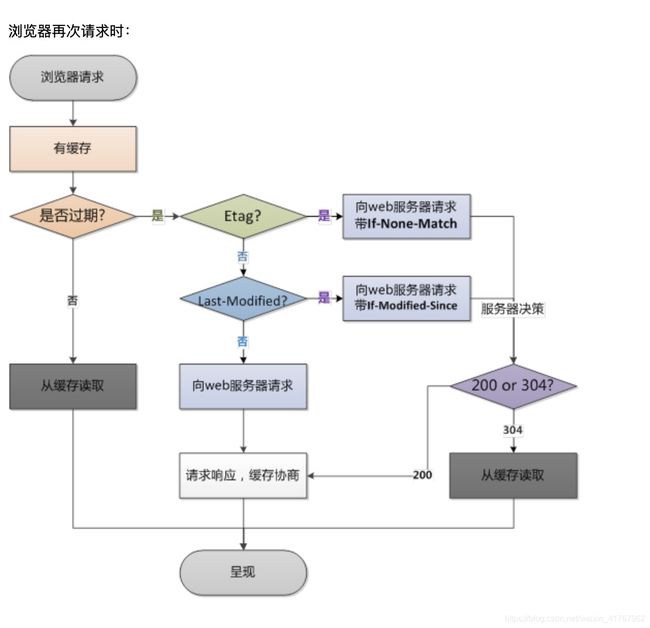
当使用 response.setHeader() 设置响应头时,则与传给 response.writeHead() 的任何响应头合并,且 response.writeHead() 的优先。
const body ="hello world";
response.writeHead(200, {
"Content-Length": Buffer.byteLength(body),
'Content-Type': 'text/plain' });
// 返回 content-type = text/plain
const server = http.createServer((req, res) => {
res.setHeader('Content-Type', 'text/html');
res.setHeader('X-Foo', 'bar');
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('ok');
});
95.大数相加(递归和不递归)
function bigSum(a, b) {
// 已 12345 和 678 为例
// 我们需要先把他们转换为位数相同,不够补零,记住要统一加一位,为了两个最大的位数相加后可能需要进位
// 12345 => 012345 678 => 000678
// 然后让各自的个位个位相加,十位与十位相加 5 + 8 = 3 (1为进位) 4 + 7 + 1 = 2 (1) .....
a = '0' + a
b = '0' + b
let aArr = a.split('')
let bArr = b.split('')
let carry = 0
let res = []
let length = Math.max(aArr.length,bArr.length)
let distance = aArr.length - bArr.length
if (distance > 0) {
for(let i = 0; i < distance; i++){
bArr.unshift('0');
}
} else{
for(let i = 0; i < Math.abs(distance); i++){
aArr.unshift('0');
}
}
for(let i = length - 1; i >= 0; i--) {
let sum = Number(aArr[i]) + Number(bArr[i]) + Number(carry)
carry = sum > 10 ? 1 : 0
sum = sum > 10 ? parseInt(sum / 10) : sum
res.unshift(sum)
}
return res.join('').replace(/^0/,'')
}
//js实现大数相加递归
96.判断空对象
1.Object.keys(obj).length=0//返回的是数组
2.JSON.stringify(data)"{}"
97.Object
ES5比较两个值是否相等,只有两个运算符:相等运算符()和严格相等运算符(=)。它们都有缺点,前者会自动转换数据类型,后者的NaN不等于自身,以及+0等于-0。JavaScript缺乏一种运算,在所有环境中,只要两个值是一样的,它们就应该相等。
ES6提出“Same-value equality”(同值相等)算法,用来解决这个问题。Object.is就是部署这个算法的新方法。它用来比较两个值是否严格相等,与严格比较运算符(=)的行为基本一致。
1.+0=0//true
2.-0=0//true
3.+0===-0//true
NaN===NaN//false
Object.is(+0,-0)//false
Object.is(NaN,NaN)//true
Object.defineProperty(Object,"is",{
value:function(x,y){
if(x===y){
//针对+0不等于-0的情况
return x!==0||1/x===1/y;
}
//针对NaN的情况
return x!==x && y!==y;
},
configurable:true,
enumerable:false,
writeable:true
})
Object.create()
1.语法:
Object.create(proto,[propertiesObject])
//方法创建一个新对象,使用现有的对象来提供新创建的对象的proto。
2.参数:
proto : 必须。表示新建对象的原型对象,即该参数会被赋值到目标对象(即新对象,或说是最后返回的对象)的原型上。该参数可以是null, 对象, 函数的prototype属性 (创建空的对象时需传null , 否则会抛出TypeError异常)。propertiesObject : 可选。 添加到新创建对象的可枚举属性(即其自身的属性,而不是原型链上的枚举属性)对象的属性描述符以及相应的属性名称。这些属性对应Object.defineProperties()的第二个参数。
3 返回值:
在指定原型对象上添加新属性后的对象
new Object()通过构造函数来创建对象,添加的属性是在自身实例下
Object.create()es6创建对象的另一种方式,可以理解为继承一个对象,添加的属性是在原型下。
// new Object() 方式创建
var a = { rep : 'apple' }
var b = new Object(a)
console.log(b) // {rep: "apple"}
console.log(b.__proto__) // {}
console.log(b.rep) //"apple"
// Object.create() 方式创建
var a = { rep: 'apple' }
var b = Object.create(a)
console.log(b) // {}
console.log(b.__proto__) // {rep: "apple"}
console.log(b.rep) // {rep: "apple"}
Object.assign()
基本用法
Object.assin方法用于对象的合并,将源对象(source)的所有可枚举属性,复制到目标对象(target)
var target={a:1};
var source1={b:2};
var source2={c:3};
Object.assign(target,source1,source2);
target//{a:1,b:2,c:3}
Object.assign(target,source1,source2);
//如果只有一个参数,Object.assign会直接返回该参数
var obj={a:1};
Object.assign(obj)===obj//true
//如果该参数不是对象,则会先转成对象,然后返回
typeof Object.assign(2)//"Object"
console.log(Object.assign(2))//2
Object.assign(undefined)//报错
Object.assign(null)//报错
let obj={a:1}
Object.assign(obj,undefined)===obj//ture
Object.assign(obj,null)===obj//true
注意:如果非对象参数出现在源位置,会转成对象,如果无法转成对象就跳过
var v1="abc";
var v2=true;
var v3=10;
var obj=Object.assign({},v1,v2,v3);
console.log(obj);//{0:"a",1:"b",2:"c"}
Object(true) // {[[PrimitiveValue]]: true}
Object(10) // {[[PrimitiveValue]]: 10}
Object('abc') // {0: "a", 1: "b", 2: "c", length: 3, [[PrimitiveValue]]: "abc"}
解释:上面代码中,布尔值、数值、字符串分别转成对应的包装对象,可以看到它们的原始值都在包装对象的内部属性[[PrimitiveValue]]上面,这个属性是不会被Object.assign拷贝的。只有字符串的包装对象,会产生可枚举的实义属性,那些属性则会被拷贝。
Object.assign拷贝的属性是有限制的,只拷贝源对象的自身属性(不拷贝继承属性),也不拷贝不可枚举的属性(enumerable: false)。
var a={age:1}
var b=Object.assign({},a);
a.age=2;
console.log(b.age)//1
var a=[1,2,3,4,5]
var b=Object.assign({},a)
console.log(b)//{0:1,1:2,2:3,3:4,4:5}
function son(){
this.name="zhang"
this.sex="男"
}
son.prototype.age=23;
var a=new son();
var b=Object.assign({},a)
console.log(b.age)//undefined
Object.assign方法实行的是浅拷贝,而不是深拷贝。也就是说,如果源对象某个属性的值是对象,那么目标对象拷贝得到的是这个对象的引用。
var obj1={a:{b:1}}
var obj2=Object.assign({},obj1);
obj1.a.b=2;
console.log(obj1)
console.log(obj2)
//克隆对象,包括克隆继承
function clone(origin){
let originProto=Object.getPrototypeOf(origin);
//Object.create()方法接受两个参数,第一个参数是一个对象,应该是新创建的对象的原型;第二个参数可选,该参数对象是一组属性与值。
return Object.assign(Object.create(originProto),origin);
}
遍历对象的属性
1.for…in
for…in循环遍历对象自身的和继承的可枚举属性(不含Symbol属性)。
2.Object.keys(obj),Object.values()
Object.keys返回一个数组,包括对象自身的(不含继承的)所有可枚举属性(不含Symbol属性)。
3.Object.getOwnPropertyNames(obj)
Object.getOwnPropertyNames返回一个数组,包含对象自身的所有属性(不含Symbol属性,但是包括不可枚举属性)。
var obj={a:2,b:3,c:4,d:5,1:6}
console.log(Object.keys(obj))// Array ["1", "a", "b", "c", "d"]
var obj={a:2,b:3,c:4,d:5,1:6}
console.log(Object.getOwnPropertyNames(obj))//Array ["1", "a", "b", "c", "d"]
Object.getOwnPropertyNames(obj).forEach(function(key){
console.log(key,obj[key])
})
//遍历顺序
首先遍历所有属性名为数值的属性,按照数字排序。
其次遍历所有属性名为字符串的属性,按照生成时间排序。
最后遍历所有属性名为Symbol值的属性,按照生成时间排序。
Object.setPrototypeOf()
Object.setPrototypeOf方法的作用与__proto__相同,用来设置一个对象的prototype对象,返回参数对象本身。它是 ES6 正式推荐的设置原型对象的方法。
let proto={};
let obj={x:10};
Object.setPrototypeOf(obj,proto);
proto.y=20;
proto.z=40;
obj.x//10
obj.y//20
obj.z//40
Object.setPrototypeOf(1, {}) === 1 // true
Object.setPrototypeOf('foo', {}) === 'foo' // true
Object.setPrototypeOf(true, {}) === true // true
由于undefiend和null无法转为对象,所以如果第一个对象是undfiend或者是null时,会报错
Object.getPrototypeOf()
function Rectangle() {
// ...
}
var rec = new Rectangle();
Object.getPrototypeOf(rec) === Rectangle.prototype
// true
Object.setPrototypeOf(rec, Object.prototype);
Object.getPrototypeOf(rec) === Rectangle.prototype
// false
//会先转换为对象
Object.getPrototypeOf(1) === Number.prototype // true
Object.getPrototypeOf('foo') === String.prototype // true
Object.getPrototypeOf(true) === Boolean.prototype // true
Object.values()
Object.values方法返回一个数组,成员是参数对象自身的(不含继承的)所有可遍历(enumerable)属性的键值。
var obj=Object.create({},{p:{
value:42,
enumerable:true//如果这个值是false,那么就不会遍历到p,该单词的意思是可枚举
}
})
Object.values(obj)//[42]
Object.values("foo")//['f','o','o']
Object.values(42)//[]
Object.values(true)//[]
Object.entries()
Object.entries方法返回一个数组,成员是参数对象自身的(不含继承的)所有可遍历(enumerable)属性的键值对数组。
var obj = { foo: 'bar', baz: 42 };
Object.entries(obj)
// [ ["foo", "bar"], ["baz", 42] ]
let obj={"one":1,"two":2};
for(let [key,value] of Object.entries(obj)){
console.log(key,value)
}
对象的扩展运算符
const [a,...b]=[1,2,3]
a//1
b//[2,3]
let {x,y,...z}={x:1,y:2,a:3,b:4}
x//1
y//2
z//{a:3,b:4}
//解构赋值要求等号右边是一个对象
let {x,y,...z}=null//运行时错误
let {x,y,...z}=undefined//运行时错误
//解构赋值的拷贝是浅拷贝
let obj={a:{b:1}}
let {...x}=obj;
obj.a.b=2;
x.a.b//2
//解构函数不会拷贝继承自原型对象的属性
let o1={a:1};
let o2={b:2};
o2.__proto__=o1;
let o3={...o2};
o3//{b:2}
var o=Object.create({x:1,y:2})
o.z=3;
let {x,...{y,z}}=o;
x//1
y//undefined
z//3
上面代码中,变量x是单纯的解构赋值,所以可以读取继承的属性;解构赋值产生的变量y和z,只能读取对象自身的属性,所以只有变量z可以赋值成功。
let a={
age:1
}
let b={...a};
a.age=2;
console.log(b.age)//1
Proxy
1.Proxy可以理解成,在目标对象之前架设一层“拦截”,外界对该对象的访问,都必须先通过这层拦截,因此提供了一种机制,可以对外界的访问进行过滤和改写。Proxy 这个词的原意是代理,用在这里表示由它来“代理”某些操作,可以译为“代理器”。通俗地讲就是在访问目标对象之前先进行一个拦截,哈哈哈哈!
var obj = new Proxy({}, {
get: function (target, key, receiver) {
console.log(`getting ${key}!`);
return Reflect.get(target, key, receiver);
},
set: function (target, key, value, receiver) {
console.log(`setting ${key}!`);
return Reflect.set(target, key, value, receiver);
}
});
obj.count = 1
// setting count!
++obj.count
// getting count!
// setting count!
// 2
2.ES6 原生提供 Proxy 构造函数,用来生成 Proxy 实例。
var proxy = new Proxy(target, handler);
var proxy = new Proxy({}, {
get: function(target, property) {
return 35;
}
});
proxy.time // 35
proxy.name // 35
proxy.title // 35
注意:target在这里就是{},property:time和title
3.如果handler没有设置任何拦截,那就等同于直接通向原对象。
var target = {};
var handler = {};
var proxy = new Proxy(target, handler);
proxy.a = 'b';
target.a // "b"
4.一个技巧是将Proxy对象,设置到object.proxy属性,从而可以在object对象上调用。
var object={proxy:new Proxy(target,handler)}
//Proxy实例也可以作为其他对象的原型对象。
var proxy=new Proxy({},{
get:function(target,property){return 35;}
});
let obj=Object.create(proxy);
obj.time//35
上面代码中,proxy对象是obj对象的原型,obj对象本身并没有time属性,所以根据原型链,会在proxy对象上读取该属性,导致被拦截。
**proxy支持的拦截操作一览**
1.get(target,propKey,receiver)//receiver可选参数
2.set(target,propKey,value,receiver)
3.has(target,propKey)//拦截propKey in proxy的操作,返回一个布尔值。
4.deleteProperty(target,propKey)//拦截delete proxy[propKey]的操作,返回一个布尔值。
5.ownKeys(target)
拦截Object.getOwnPropertyNames(proxy)、Object.getOwnPropertySymbols(proxy)、Object.keys(proxy),返回一个数组。该方法返回目标对象所有自身的属性的属性名,而Object.keys()的返回结果仅包括目标对象自身的可遍历属性。
Proxy实例的方法
1.get()
get方法用于拦截某个属性的读取操作
var person = {
name: "张三"
};
var proxy = new Proxy(person, {
get: function(target, property) {
if (property in target) {
return target[property];
} else {
throw new ReferenceError("Property \"" + property + "\" does not exist.");
}
}
});
proxy.name // "张三"
proxy.age // 抛出一个错误
2.set()
set方法用来拦截某个属性的赋值操作。
假定Person对象有一个age属性,该属性应该是一个不大于200的整数,那么可以使用Proxy保证age的属性值符合要求。
let validator = {
set: function(obj, prop, value) {
if (prop === 'age') {
if (!Number.isInteger(value)) {
throw new TypeError('The age is not an integer');
}
if (value > 200) {
throw new RangeError('The age seems invalid');
}
}
// 对于age以外的属性,直接保存
obj[prop] = value;
}
};
let person = new Proxy({}, validator);
person.age = 100;
person.age // 100
person.age = 'young' // 报错
person.age = 300 // 报错
3.has()
//has方法用来拦截HasProperty操作,即判断对象是否具有某个属性时,这个方法会生效。典型的操作就是in运算符。
//下面的例子使用has方法隐藏某些属性,不被in运算符发现。
var handler = {
has (target, key) {
if (key[0] === '_') {
return false;
}
return key in target;
}
};
var target = { _prop: 'foo', prop: 'foo' };
var proxy = new Proxy(target, handler);
'_prop' in proxy // false
4.deleteProperty()
deleteProperty方法用于拦截delete操作,如果这个方法抛出错误或者返回false,当前属性就无法被delete命令删除。
var handler = {
deleteProperty (target, key) {
invariant(key, 'delete');
return true;
}
};
function invariant (key, action) {
if (key[0] === '_') {
throw new Error(`Invalid attempt to ${action} private "${key}" property`);
}
}
var target = { _prop: 'foo' };
var proxy = new Proxy(target, handler);
delete proxy._prop
// Error: Invalid attempt to delete private "_prop" property
上面代码中,deleteProperty方法拦截了delete操作符,删除第一个字符为下划线的属性会报错。
98.js中的sort()方法
sort()方法用于对数组的元素进行排序
如果调用该方法时没有使用参数,将按字母顺序对数组中的元素进行排序,说得更精确点,是按照字符编码(字典排序)的顺序进行排序。要实现这一点,首先应把数组的元素都转换成字符串(如有必要),以便进行比较。
如果想按照其他标准进行排序,就需要提供比较函数,该函数要比较两个值,然后返回一个用于说明这两个值的相对顺序的数字。比较函数应该具有两个参数 a 和 b,其返回值如下:
若 a 小于 b,在排序后的数组中 a 应该出现在 b 之前,则返回一个小于 0 的值。
若 a 等于 b,则返回 0。
若 a 大于 b,则返回一个大于 0 的值。
99.js中的进制转换
1.parseInt(字符串,进制数)
2.Number.parseInt(string,radix)//这个是把字符串(只能由字母和数字组成),这个只能是由低进制转高进制,如二进制转八进制,但是八进制不能转二进制,radix表示进制,取值2~36。Number.parseInt(“010”,8);//将二进制转换为8进制
3.Number.toString(radix);//这个函数只能将十进制数字转换为任意进制的字符串形式,同样,radix表示进制,取值2~36。
(10).toString(2);//"1010"转2进制
(10).toString(16);//"a"转16进制
(1000).toString(36);//"rs"转36进制
100闭包的理解
1.如何产生闭包?
当一个嵌套的内部(子)函数引用了嵌套的外部(父)函数的变量(函数)时,就产生了闭包。
2.常见的闭包?
将函数作为另一个函数的返回值
function fn1(){
var a=2;
function fn2(){
a++;
console.log(a)
}
return fn2
}
var f=fn1()//调用几次外部函数就创建几次闭包
f()//3
f()//4
将函数作为实参传递给另一个函数调用
function showDelay(msg,time)
{
setTimeout(function(){alert(msg)},time)
}
showDelay("atguigu",200)
3.闭包的作用
1.使用函数内部的变量在函数执行完后,仍然存活在内存中(延长局部变量的生命周期),如果不用闭包函数执行完后,内部变量就会被销毁。
2.让函数外部可以操作(读写)到函数内部的数据(变量/函数),因为函数内部的变量是局部变量,如果不用闭包是无法访问到局部变量的。
4.闭包的生命周期
1.产生:在嵌套的内部函数定义执行完时就产生了(不是在调用)
2.死亡:在嵌套的内部函数成为垃圾对象时
function fn1(){
//此时闭包就已经产生了(函数提升,内部函数对象已经创建了)
var a=2;
function fn2(){
a++;
console.log(a);
}
return fn2
}
var f=fn1()
f()//3
f()//4
f=null//闭包死亡(包含闭包的函数对象成为垃圾对象)
5.闭包的内存溢出与内存泄露
1.缺点
函数执行完后,该函数后面不会在用了,函数内的局部变量没有释放,占用内存时间会变长,导致容易造成内存泄漏。
2.解决
能不用闭包就不用
及时释放
function fn1(){
var arr=new Array[100000]
function fn2(){
console.log(arr.length)
}
return fn2
}
var f=fn1();
f()
如果后面你不用了,就要进行释放,以免造成内存泄漏
f=null;
<!--
1.内存溢出
一种程序运行出现的错误,当程序运行需要的内存超过了剩余的内存时,就会抛出内存溢出的错误
2.内存泄露
闭包,占用的内存没有及时释放
内存泄露积累多了就容易导致内存溢出
常见的内存泄露:
意外的全局变量
没有及时清理的计时器或回调函数
闭包
-->
//意外的全局变量
function fn()
{
a=3;
console.log(a);
}
fn();//本来想写成var a=3的,然后函数执行完就销毁了,忘记写var了,意外的全局变量,导致a没有被销毁
setInterval(function(){
console.log("-----")
},1000)//启动定时器后,后面不用了忘记把它清除了
//闭包
上面有例子了
101垃圾回收
就像人生活的时间长了会产生垃圾一样,程序运行过程中也会产生垃圾
这些垃圾积攒过多以后,会导致程序运行的速度过慢
所以我们需要一个垃圾回收机制,来处理程序运行过程中产生垃圾
当一个对象没有任何的变量或属性对它进行引用,此时我们将永远无法操作对象,此时这种对象就是一个垃圾,这种对象过多会占用大量的内存空间,导致程序运行很慢,所以这些垃圾必须清除。
var obj=new Object();
obj=null
在浏览器中拥有自动的垃圾回收机制,会自动将这些垃圾对象从内存中销毁,我们不需要也不能进行垃圾回收的操作
我们需要做的只是要将不再使用的对象设置null即可
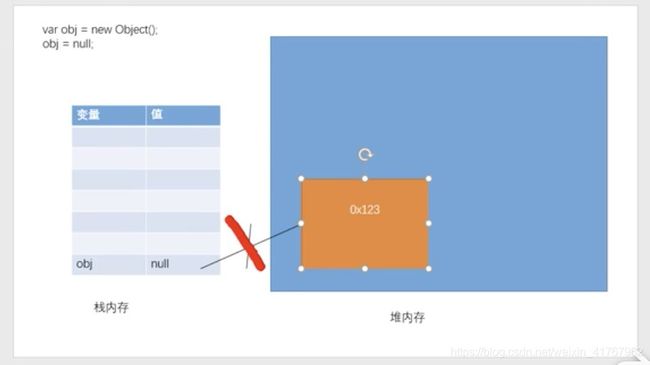
102数组对象常用方法
影响自身
Array.prototype.pop()
删除数组的最后一个元素,并返回这个元素,并且影响到自身。
Array.prototype.push()
在数组的末尾增加一个或多个元素,并返回数组的新长度,并且影响到自身。
Array.prototype.shift()
删除数组的第一个元素,并返回这个元素,并且影响到自身。
Array.prototype.unshift()
在数组的开头增加一个或多个元素,并返回数组的新长度,并且影响到自身。
Array.prototype.splice(index,删除几个,添加到数组的新元素)
//返回的是删除元素,并且影响到自身
var a=[1,2,3,4,5,6,7]
console.log(a.splice(2,0,9,9))//[]
console.log(a)//[1,2,9,9,3,4,5,6,7]
在任意的位置给数组添加或删除任意个元素。
Array.prototype.reverse()
颠倒数组中元素的排列顺序,即原先的第一个变为最后一个,原先的最后一个变为第一个。
Array.prototype.sort()
对数组元素进行排序,并返回当前数组,并且影响到自身。
不影响自身
Array.prototype.join()
连接所有数组元素组成一个字符串。
Array.prototype.slice()
抽取当前数组中的一段元素组合成一个新数组。
Array.prototype.concat()
返回一个由当前数组和其它若干个数组或者若干个非数组值组合而成的新数组。
Array.prototype.indexOf()
返回数组中第一个与指定值相等的元素的索引,如果找不到这样的元素,则返回 -1。
方法
Array.prototype.forEach()
为数组中的每个元素执行一次回调函数,没有返回值。
Array.prototype.map()
返回一个由回调函数的返回值组成的新数组,不会影响自身。
Array.prototype.reduce()
从左到右为每个数组元素执行一次回调函数,并把上次回调函数的返回值放在一个暂存器中传给下次回调函数,并返回最后一次回调函数的返回值。
Array.prototype.filter()
将所有在过滤函数中返回 true 的数组元素放进一个新数组中并返回,不会影响自身。
var a=[1,2,3,4,5,7,6]
console.log(a.filter(function(item){if(item>3){return item }}))
console.log(a)
Array.prototype.find()
找到第一个满足测试函数的元素并返回那个元素的值,如果找不到,则返回 undefined,不会影响自身;
103字符串方法
String.prototype.split()
通过分离字符串成字串,将字符串对象分割成字符串数组,不会影响到自身。
String.prototype.slice(start, end)
摘取一个字符串区域,返回一个新的字符串,不会影响到自身。
String.prototype.substr(start, len)
通过指定字符数返回在指定位置开始的字符串中的字符,不会影响到自身。
String.prototype.substring()
返回在字符串中指定两个下标之间的字符,不会影响到自身。
String.prototype.trim()
从字符串的开始和结尾去除空格,不会影响到自身
String.prototype.concat()
连接两个字符串文本,并返回一个新的字符串,不会影响到自身。
100.animation动画效果
<div class="container">
<div class="son">
</div>
</div>
.container{
width:100px;
height:100px;
border:2px solid red;
position:relative;
}
.son{
width:20px;
height:20px;
border:2px solid blue;
border-radius:50%;
position:absolute;
background-color:blue;
animation:remove 2s ease-in-out 1s;
animation-fill-mode:forwards;
animation-direction:alternate;
animation-iteration-count:3;
animation-play-state:running;
}
@keyframes remove{
0%{
transform:translate(0px,0px);
}
100%{
transform:translate(78px,78px);
}
}//斜对角线来回滚动3次
101.transition动画效果
.container{
width:100px;
height:100px;
border:2px solid red;
position:relative;
}
.son{
width:20px;
height:20px;
border:2px solid blue;
border-radius:50%;
position:absolute;
background-color:blue;
transform:translate(0px,0px);
transition:transform 2s ease 2s;
}
.son:hover{
transform:translate(78px,78px);
}//斜对角线来回滚动三次
102.transform动画效果
.container{
width:100px;
height:100px;
border:2px solid red;
}
.son{
width:20px;
height:20px;
border:2px solid blue;
background-color:blue;
}
.son:hover{
transform:scaleX(5);/*自身的宽度进行拉升,百分比,px,em,rem没用*/
transform:scaleY(5);/*之前的scaleX无效,没有用了*/
transform:scale3d(5,5);/*x轴方向失效*/
transform:scale(5,5);/*x,y有效*/
/*transform:rotate(20deg);/*顺时针旋转20deg*/
/*transform:rotate(-20deg);/*逆时针旋转20deg*/
/*transform:rotateX(40deg);/*3D沿着x轴逆时针40deg*/
/*transform:rotateY(40deg);/*3D沿着y轴逆时针40deg*/
/*transform:rotateZ(20deg);/*3D沿着Z轴顺时针20deg*/
/*transform:skewX(10deg);/*2D沿着x轴逆时针倾斜20deg*/
/*transform:skewY(10deg);/*2D沿着y轴顺时针倾斜10deg*/
}
103.css的性能优化
1.发布前压缩css代码
2.合并属性,如margine-left:5px;margine-top:10px 这个就可以合并成一条的。
3.css 雪碧图
4.利用CSS继承减少代码量
104.DOM简介
什么是DOM
文档对象模型(document object mode,简称DOM),是W3C组织推荐的处理可扩展标记语言的标准编程接口。//通俗地来将就是编程的接口。
W3C已经定义了一系列的DOM接口,通过这些DOM接口可以改变网页的内容、结构和样式。
文档:一个页面就是一个文档,DOM中使用document表示。
元素:页面中的所有标签都是元素,DOM中使用element表示。
节点:网页中的所有内容都是节点(标签、属性、文本、注释等),DOM中使用node表示。
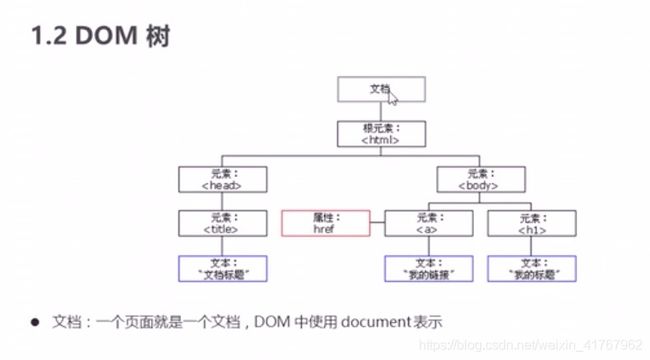
105:重绘和回流
1.添加、删除可见的dom
2.元素的位置改变
3.元素的尺寸改变(外边距、内边距、边框厚度、宽高、等几何属性)
4.页面渲染初始化
5.浏览器窗口尺寸改变
6.获取某些属性。当获取一些属性时,浏览器为取得正确的值也会触发重排,它会导致队列刷新,这些属性包括:offsetTop、offsetLeft、 offsetWidth、offsetHeight、scrollTop、scrollLeft、scrollWidth、scrollHeight、clientTop、clientLeft、clientWidth、clientHeight、getComputedStyle() (currentStyle in IE)。所以,在多次使用这些值时应进行缓存。
7.引发回流:
改变节点内部文字结构也会触发重布局
text-align overflow-y font-weight overflow
font-family line-height vertival-align white-space
font-size。
8.触发重绘的属性:
color border-style border-radius visibility
text-decoration background background-image background-position
background-repeat background-size outline-color outline
outline-style outline-width box-shadow
优化:
(1)不要一条一条地修改 DOM 的样式。可以先定义好 css 的 class,然后修改 DOM 的 className。
(2)把 DOM 离线后修改,比如:先把 DOM 给 display:none (有一次 Reflow),然后你修改100次,然后再把它显示出来
(3)为动画的 HTML 元件使用 fixed 或 absoult 的 position,那么修改他们的 CSS 是不会 reflow 的。
106:对象数组
let arr = [{
key: '01',
value: '乐乐'
},{
key: '02',
value: '博博'
},{
key: '03',
value: '淘淘'
},{
key: '04',
value: '哈哈'
},{
key: '01',
value: '乐乐'
}];
var obj={};
var result=[];
for(var i=0;i<arr.length;i++)
{
if(!obj[arr[i].key])
{
result.push(arr[i])
obj[arr[i].key]=true;
}
}
console.log(result)
107:js实现对象树
var data = [
{ id: 1, name: "办公管理", pid: 0 },
{ id: 2, name: "请假申请", pid: 1 },
{ id: 3, name: "出差申请", pid: 1 },
{ id: 4, name: "请假记录", pid: 2 },
{ id: 5, name: "系统设置", pid: 0 },
{ id: 6, name: "权限管理", pid: 5 },
{ id: 7, name: "用户角色", pid: 6 },
{ id: 8, name: "菜单设置", pid: 6 },
];
//程序
function toTree(data) {
// 将数据存储为 以 id 为 KEY 的 map 索引数据列
var map = {};
data.forEach(function (item) {
map[item.id] = item;
});
// console.log(map);
var val = [];
data.forEach(function (item) {
// 以当前遍历项的pid,去map对象中找到索引的id
var parent = map[item.pid];
// 好绕啊,如果找到索引,那么说明此项不在顶级当中,那么需要把此项添加到,他对应的父级中
if (parent) {
(parent.children || ( parent.children = [] )).push(item);
} else {
//如果没有在map中找到对应的索引ID,那么直接把 当前的item添加到 val结果集中,作为顶级
val.push(item);
}
});
return val;
}
console.log(toTree(data))
108:实现简单的promise
function PromiseM(){
this.status='pending';
this.msg='';
var process=arguments[0];
var that=this;
process(function(){
that.status='resolve';
that.msg=arguments[0];
},function(){
that.status='reject';
that.msg=arguments[0];
});
return this;
}
PromiseM.prototype.then=function(){
if(this.status=='resolve'){
arguments[0](this.msg);
}
if(this.status=='reject'){
arguments[1](this.msg);
}
}
var mm=new PromiseM(function(resolve,reject){
resolve('123');//123其实就是第二个arguments[0]
});//上面的第一个arguments[0]
mm.then(function(success){
console.log(success);//该success其实就是上面的this.msg
console.log("ok!");
},function(error){
console.log(error);
});
111:二叉树的遍历
前序
function DLR(tree){
console.log(tree.value);
if(tree.left){
DLR(tree.left);
}
if(tree.right){
DLR(tree.right);
}
}
//非递归
let dfs = function (nodes) {
let result = [];
let stack = [];
stack.push(nodes);
while(stack.length) { // 等同于 while(stack.length !== 0) 直到栈中的数据为空
let node = stack.pop(); // 取的是栈中最后一个j
result.push(node.value);
if(node.right) stack.push(node.right); // 先压入右子树
if(node.left) stack.push(node.left); // 后压入左子树
}
return result;
}
dfs(tree);
中序:
function LDR(tree){
if(tree.left){
LDR(tree.left);
}
console.log(tree.value);
if(tree.right){
LDR(tree.right);
}
}
//非递归
function dfs(node) {
let result = [];
let stack = [];
while(stack.length || node) { // 是 || 不是 &&
if(node) {
stack.push(node);
node = node.left;
} else {
node = stack.pop();
result.push(node.value);
//node.right && stack.push(node.right);
node = node.right; // 如果没有右子树 会再次向栈中取一个结点即双亲结点
}
}
return result;
}
dfs(tree);
// ["a", "+", "b", "*", "c", "-", "d", "/", "e"]
后序:
function LRD(tree){
if(tree.left){
LRD(tree.left);
}
if(tree.right){
LRD(tree.right);
}
console.log(tree.value);
}
112:广度遍历递归和非递归
广度遍历递归:
let result = [];
let stack = [tree]; // 先将要遍历的树压入栈
let count = 0; // 用来记录执行到第一层
let bfs = function () {
let node = stack[count];
if(node) {
result.push(node.value);
if(node.left) stack.push(node.left);
if(node.right) stack.push(node.right);
count++;
bfs();
}
}
dfc();
console.log(result);
// ["-", "+", "/", "a", "*", "d", "e", "b", "c"]
非递归
function bfs(node) {
let result = [];
let queue = [];
queue.push(node);
let pointer = 0;
while(pointer < queue.length) {
let node = queue[pointer++]; // // 这里不使用 shift 方法(复杂度高),用一个指针代替
result.push(node.value);
node.left && queue.push(node.left);
node.right && queue.push(node.right);
}
return result;
}
bfs(tree);
// ["-", "+", "/", "a", "*", "d", "e", "b", "c"]
深度遍历递归
let result = [];
let dfs = function (node) {
if(node) {
result.push(node.value);
dfs(node.left);
dfs(node.right);
}
}
dfs(tree);
console.log(result);
// ["-", "+", "a", "*", "b", "c", "/", "d", "e"]
深度遍历非递归
let dfs = function (nodes) {
let result = [];
let stack = [];
stack.push(nodes);
while(stack.length) { // 等同于 while(stack.length !== 0) 直到栈中的数据为空
let node = stack.pop(); // 取的是栈中最后一个j
result.push(node.value);
if(node.right) stack.push(node.right); // 先压入右子树
if(node.left) stack.push(node.left); // 后压入左子树
}
return result;
}
dfs(tree);
113:vue的继承性
//继承是使用extends,有一个功能完善的公用组件,当需要对组件进行扩展时,会用到 extend,而不需要重新写一个组件。
import Vue from 'vue'
const component = {
props: {
active: Boolean,
propOne: String
},
template: `
{{propOne}}
`,
data () {
return {
text: 0
}
},
mounted () {
console.log('comp mounted')
}
}
const component2 = {
extends: component, // 指定继承组件
data () {
return {
text: 1
}
},
mounted () {
console.log('comp2 mounted')
}
}
new Vue({
el: '#root',
components: {
Comp: component2
},
template: `114:计算属性和监听属性
watch是观察某一个属性的变化,重新计算属性值。computed是通过所依赖的属性的变化重新计算属性值。
大部分情况下watch和computed几乎没有差别。但如果要在数据变化的同时进行异步操作或者是比较大的开销,那么watch为最佳选择。
``
**117.vue-router原理(前端路由)**
hash 模式:
这种 #。后面 hash 值的变化,并不会导致浏览器向服务器发出请求,浏览器不发出请求,也就不会刷新页面。另外每次 hash 值的变化,还会触发hashchange 这个事件,通过这个事件我们就可以知道 hash 值发生了哪些变化。然后我们便可以监听hashchange来实现更新页面部分内容。
history 模式:
14年后,因为HTML5标准发布。多了两个 API,pushState 和 replaceState,通过这两个 API 可以改变 url 地址且不会发送请求。同时还有popstate 事件。通过这些就能用另一种方式来实现前端路由了,但原理都是跟 hash 实现相同的。用了 HTML5 的实现,单页路由的 url 就不会多出一个#,变得更加美观。但因为没有 # 号,所以当用户刷新页面之类的操作时,浏览器还是会给服务器发送请求。为了避免出现这种情况,所以这个实现需要服务器的支持,需要把所有路由都重定向到根页面。
**118.图片用base64与url的区别?**
119.原生js继承和es6继承
**120.怎么是实现双向绑定 怎么实现劫持?**
数据更新视图的重点是如何知道数据变了,只要知道数据变了,那么接下去的事都好处理。如何知道数据变了,其实上文我们已经给出答案了,就是通过Object.defineProperty( )对属性设置一个set函数,当数据改变了就会来触发这个函数,所以我们只要将一些需要更新的方法放在这里面就可以实现data更新view了。
```javascript
Object.defineProperty(Book, 'name', {
set: function (value) {
name = value;
console.log('你取了一个书名叫做' + value);
},
get: function () {
return '《' + name + '》'
}
})
123.JS的DOM操作知识点,appendChild()如果出现在循环中,如循环十次会产生十个新的节点还是就产生一个,为什么
127.高阶函数了解过吗
128.class的用处
130.判断是对象上的方法还是原型上的方法
obj.hasOwnProperty(‘属性名’)
131.vue响应式原理说一下
Vue 的响应式原理是核心是通过 ES5 的保护对象的 Object.defindeProperty 中的访问器属性中的 get 和 set 方法,data 中声明的属性都被添加了访问器属性,当读取 data 中的数据时自动调用 get 方法,当修改 data 中的数据时,自动调用 set 方法,检测到数据的变化,会通知观察者 Wacher,观察者 Wacher自动触发重新render 当前组件(子组件不会重新渲染),生成新的虚拟 DOM 树,Vue 框架会遍历并对比新虚拟 DOM 树和旧虚拟 DOM 树中每个节点的差别,并记录下来,最后,加载操作,将所有记录的不同点,局部修改到真实 DOM 树上。
132.Object.defineProperty来实现响应式有什么缺陷?
缺点:
Object.defineProperty只能劫持对象的属性,从而需要对每个对象,每个属性进行遍历,如果,属性值是对象,还需要深度遍历。
134.Proxy和Object.defineProperty各有什么优劣?
1.Object.defineProperty()
Object.defineProperty()方法会直接在一个对象上定义一个新属性,或者修改一个对象的现有属性,并返回这个对象。
Object.defineProperty(Book, 'name', {
set: function (value) {
name = value;
console.log('你取了一个书名叫做' + value);
},
get: function () {
return '《' + name + '》'
}
})
var Book={};
Book.name="jack";
console.log(Book.name)
Object.defineProperty()的问题主要有3个:
不能监听数组的变化
必须遍历对象的每个属性,如果属性里面还是一个对象,则会进行深层遍历
(1).数组的这些方法是无法触发set的:push, pop, shift, unshift,splice, sort, reverse.
Object.keys(obj).forEach(key => {
Object.defineProperty(obj, key, {
// ...
})
})
2.Proxy:
Proxy 对象用于定义基本操作的自定义行为(如属性查找,赋值,枚举,函数调用等)。
(1).针对对象:针对整个对象,而不是对象的某个属性。
(2).支持数组:不需要对数组的方法进行重载,省去了众多 hack。
(3).嵌套支持: get 里面递归调用 Proxy 并返回
针对对象:
不需要对 keys 进行遍历。这解决Object.defineProperty() 的第二个问题.Proxy 是针对整个 obj 的。所以 obj 内部包含的所有的 key ,都可以走进 set。(省了一个 Object.keys() 的遍历)
let obj = {
name: 'Eason',
age: 30
}
let handler = {
get (target, key, receiver) {
console.log('get', key)
return Reflect.get(target, key, receiver)
},
set (target, key, value, receiver) {
console.log('set', key, value)
return Reflect.set(target, key, value, receiver)
}
}
let proxy = new Proxy(obj, handler)
proxy.name = 'Zoe' // set name Zoe
proxy.age = 18 // set age 18
支持数组:
let arr = [1,2,3]
let proxy = new Proxy(arr, {
get (target, key, receiver) {
console.log('get', key)
return Reflect.get(target, key, receiver)
},
set (target, key, value, receiver) {
console.log('set', key, value)
return Reflect.set(target, key, value, receiver)
}
})
proxy.push(4)
// 能够打印出很多内容
// get push (寻找 proxy.push 方法)
// get length (获取当前的 length)
// set 3 4 (设置 proxy[3] = 4)
// set length 4 (设置 proxy.length = 4)
Reflect.get():获取对象身上某个属性的值,类似于 target[name]。
Reflect.set():将值分配给属性的函数,返回一个Boolean,如果更新成功,则返回true。
嵌套支持
Proxy 也是不支持嵌套的,这点和 Object.defineProperty() 是一样的。因此也需要通过逐层遍历来解决。Proxy 的写法是在 get 里面递归调用 Proxy 并返回
let obj = {
info: {
name: 'eason',
blogs: ['webpack', 'babel', 'cache']
}
}
let handler = {
get (target, key, receiver) {
console.log('get', key)
// 递归创建并返回
if (typeof target[key] === 'object' && target[key] !== null) {
return new Proxy(target[key], handler)
}
return Reflect.get(target, key, receiver)
},
set (target, key, value, receiver) {
console.log('set', key, value)
return Reflect.set(target, key, value, receiver)
}
}
let proxy = new Proxy(obj, handler)
// 以下两句都能够进入 set
proxy.info.name = 'Zoe'
proxy.info.blogs.push('proxy')
136.vue实例能addEventListener吗?
mounted () {
this.$nextTick(() => {
document.getElementById('id').addEventListener('your event', () => {
})
})
}
137.dns 预解析,哪些方式
141.vue mixin
142.getElementsByClassName 怎么判断获取元素的标签
(nodename)
var a=getElementsByClassName("child")[0];获取第二个名为child的标签
145. Fast-click原理
146.为什么ios会有这个300ms延迟
147.列表无限滚动加载怎么做的
148.倒计时组件怎么做的
149.图片base64有哪些优缺点
优点:
我们都知道,我们的网站采用的都是http协议,而http协议是一种无状态的连接,就是连接和传输后都会断开连接节省资源。此时解决的方法就是尽量的减少http请求,此时base64编码可以将图片添加到css中,实现请求css即可下载下来图片,减少了再次请求图片的请求。当然减少http请求次数的方法还有很多,如css sprite技术,将网页中的小图片拼在 一张大图中,下载时只需要一次完整的http请求就可以,减少了请求次数。
缺点:
CSS 文件体积的增大。
通俗而言,就是图片不会导致关键渲染路径的阻塞,而转化为 Base64 的图片大大增加了 CSS 文件的体积,CSS 文件的体积直接影响渲染,导致用户会长时间注视空白屏幕。HTML 和 CSS 会阻塞渲染,而图片不会。
用武之地:如果图片足够小且因为用处的特殊性无法被制作成雪碧图(CssSprites),在整个网站的复用性很高且基本不会被更新。比如说背景图片的使用
151.symbol和const区别
153.移动端适配
154.现在我有一个对象urls = {url1: “这里是具体url地址”, url2: …}, 我想用urls.url1(‘POST’, callback)的方式来发请求,你怎么做?
155.清除浮动的原理
156.vue的权限路由如何做?
157.diff原理
158.实际情况diff处理机制
159.![]的结果//false
160.获取页面上所有标签的类型和个数
161.有如下场景:我现在在用Promise.all,假如参数传了三个Promise对象,这三个对象有两个总是能在200ms以内resolve,可是有一个有可能会2000ms都没有响应,很慢,我想现在如果这个Promise对象200ms还没返回,我直接reject,怎么做?
162.大列表操作节流怎么做的
163.说一下base64
164.plugin生命周期
165.miniCssExtract是把css单独提取还是内嵌
css单独提取出来
166.动态链接资源怎么实现
167.parrelUglyfyJs可以删除无用代码吗
168.webpack3 4区别
169.js的设计模式
171.Dom树的渲染过程
172.{}{}? [][]? null==undefined?
[]+{} 结果是 "[object Object]"
{}+[] 结果是 0
({}+[]) 结果是 "[object Object]"
+[] 结果是 0 ,此处+为正号
+{} 结果是 NaN ,此处+为正号
[].toString() 结果是 ""
({}).toString() 结果是 "[object Object]"
{}.toString() 会出错,Uncaught SyntaxError: Unexpected token .
0+[] 结果是 "0"
0+{} 结果是 "0[object Object]"
先说 [] + {} 。一个数组加一个对象。
加法会进行隐式类型转换,规则是调用其 valueOf() 或 toString() 以取得一个非对象的值(primitive value)。如果两个值中的任何一个是字符串,则进行字符串串接,否则进行数字加法。
[] 和 {} 的 valueOf() 都返回对象自身,所以都会调用 toString(),最后的结果是字符串串接。[].toString() 返回空字符串,({}).toString() 返回“[object Object]”。最后的结果就是“[object Object]”。
然后说 {} + [] 。看上去应该和上面一样。但是 {} 除了表示一个对象之外,也可以表示一个空的 block。在 [] + {} 中,[] 被解析为数组,因此后续的 + 被解析为加法运算符,而 {} 就解析为对象。但在 {} + [] 中,{} 被解析为空的 block,随后的 + 被解析为正号运算符。即实际上成了:
{ // empty block }
+[]
即对一个空数组执行正号运算,实际上就是把数组转型为数字。首先调用 [].valueOf() 。返回数组自身,不是primitive value,因此继续调用 [].toString() ,返回空字符串。空字符串转型为数字,返回0,即最后的结果。
{}=={}?//
[]==[]?
null==undefined?
[] == ! [] -> [] == false -> [] == 0 -> '' == 0 -> 0 == 0 -> true
{} == ! {} -> {} == false -> {} == 0 -> NaN == 0 -> false
规范中提到, 要比较相等性之前,不能将 null 和 undefined 转换成其他任何值,并且规定null 和 undefined 是相等的。
null 和 undefined都代表着无效的值。
173 es6中的类
class类:
1.类的所有方法都定义在类的prototype属性上面。
2.class不存在变量提升,这一点与es5完全不同
3.this的指向
类的方法内部如果含有this,它默认指向类的实例。
4.name属性,name属性总是返回紧跟在class关键字后面的类名。
class Point {}
Point.name // "Point"
es6的类
class Point {
constructor(x,y){
this.x=x;
this.y=y;
}
toString(){
return "("+this.x+","+this.y+")"
}
}
class ColorPoint extends Point {
constructor(x,y,color){
super(x,y)
this.color=color;
}
toString(){
return this.color +" "+super.toString();
}
}
var cp=new ColorPoint("123","456","green")
console.log(cp.x)
console.log(cp.toString())
extends表示ColorPoint继承Point
上面代码中,constructor方法和toString方法之中,都出现了super关键字,它在这里表示父类的构造函数,用来新建父类的this对象。
子类必须在constructor方法中调用super方法,否则新建实例时会报错。这是因为子类没有自己的this对象,而是继承父类的this对象,然后对其进行加工。如果不调用super方法,子类就得不到this对象。
ES5的继承,实质是先创造子类的实例对象this,然后再将父类的方法添加到this上面(Parent.apply(this))。ES6的继承机制完全不同,实质是先创造父类的实例对象this(所以必须先调用super方法),然后再用子类的构造函数修改this。
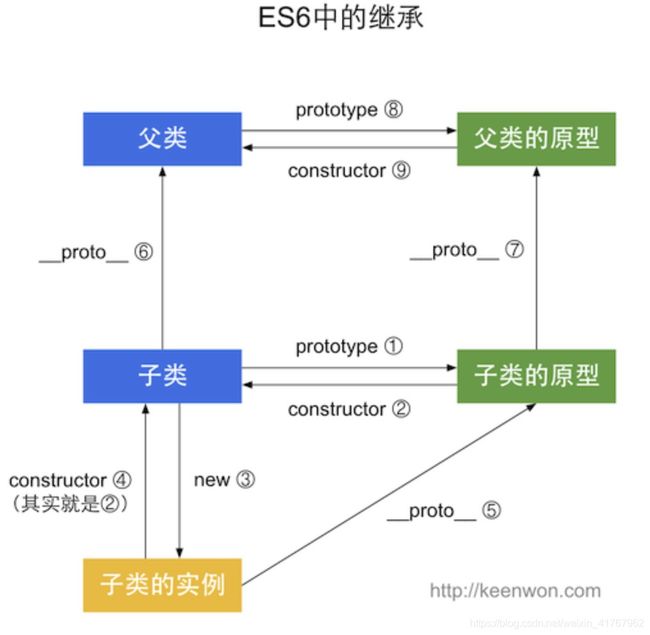
class A {
}
class B extends A {
}
B.__proto__ === A // true
Object.setPrototypeOf(B, A);
B.prototype.__proto__ === A.prototype // true
Object.setPrototypeOf(B.prototype, A.prototype);
class A {
}
A.__proto__ === Function.prototype // true
A.prototype.__proto__ === Object.prototype // true
Object.getPrototypeOf(ColorPoint) === Point
// true
因此,可以使用这个方法判断,一个类是否继承了另一个类。
**super 关键字**
第一种情况,super作为函数调用时,代表父类的构造函数。es6要求,子类的构造函数必须执行一次super函数
class A {}
class B extends A {
constructor() {
super();
}
}
第二种情况,super作为对象时,在普通方法中,指向父类的原型对象;在静态方法中,指向父类。
在普通方法中,指向父类的原型对象,所以定义在父类实例上的方法或属性,是无法通过super调用的。
class A {
constructor() {
this.x = 1;
}
}
class B extends A {
constructor() {
super();
this.x = 2;
super.x = 3;
console.log(super.x); // undefined
console.log(this.x); // 3
}
}
let b = new B();
super.x赋值为3,这时等同于对this.x赋值为3。因为super绑定的是子类的this;而当读取super.x的时候,读的是A.prototype.x,所以返回undefined。
如果super作为对象,用在静态方法之中,这时super将指向父类,而不是父类的原型对象。
class Parent {
static myMethod(msg) {
console.log('static', msg);
}
myMethod(msg) {
console.log('instance', msg);
}
}
class Child extends Parent {
static myMethod(msg) {
super.myMethod(msg);
}
myMethod(msg) {
super.myMethod(msg);
}
}
Child.myMethod(1); // static 1
var child = new Child();
child.myMethod(2); // instance 2
上面代码中,super在静态方法之中指向父类,在普通方法之中指向父类的原型对象。
174 移动端适配
1.viewport
viewport就是设备上用来显示网页的那一块区域,但viewport又不局限于浏览器可视区域的大小,它可能比浏览器的可视区域要大,也可能比浏览器的可视区域要小。
在默认情况下,一般来讲,移动设备上的viewport都是要大于浏览器可视区域的,这是因为考虑到移动设备的分辨率相对于桌面电脑来说都比较小,所以为了能在移动设备上正常显示那些传统的为桌面浏览器设计的网站,移动设备上的浏览器都会把自己默认的viewport设为980px或1024px(也可能是其它值,这个是由设备自己决定的),但带来的后果就是浏览器会出现横向滚动条,因为浏览器可视区域的宽度是比这个默认的viewport的宽度要小的。
1. visual viewport 可见视口,指屏幕宽度
2. layout viewport 布局视口,指DOM宽度
3. ideal viewport 理想适口,使布局视口就是可见视口即为理想视口
获取屏幕宽度(visual viewport)的尺寸:window. innerWidth/Height
获取DOM宽度(layout viewport)的尺寸:document. documentElement. clientWidth/Height
设置理想视口ideal viewport:
<meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
该meta标签的作用是让layout viewport的宽度等于visual viewport的宽度,同时不允许用户手动缩放,从而达到理想视口。
meta[name=“viewport”]里各参数的含义为:
width: 设置layout viewport 的宽度,为一个正整数,或字符串”width-device”。
initial-scale: 设置页面的初始缩放值,为一个数字,可以带小数。
minimum-scale: 允许用户的最小缩放值,为一个数字,可以带小数。
maximum-scale: 允许用户的最大缩放值,为一个数字,可以带小数。
height: 设置layout viewport 的高度,这个属性对我们并不重要,很少使用。
user-scalable: 是否允许用户进行缩放,值为“no”或“yes”。
2.rem
rem是相对于根元素的字体大小的单位,也就是html的font-size大小,浏览器默认的字体大小是16px,所以默认的1rem=16px,我们可以根据设备宽度动态设置根元素的font-size,使得以rem为单位的元素在不同终端上以相对一致的视觉效果呈现。
不同的移动端设备进行相同的平等分,来达到自适应的效果
事实上 rem是把屏幕等分成 指定的份数,以20份为例,每份为 1rem , 1rem 对应的大小就是 rem基准值 ,rem做的就是把 rem基准值 给的 font-size ,所以如果设备的 物理像素 宽为 640px ,分成20份,那么 1rem=640px/20=32px , 的 font-size为32px 。
3.vw,vh进行适配
vw:viewport width(可视窗口宽度)
vh:viewport height(可视窗口高度)
1vw等于1%的设备宽度(设计稿宽度),1vh等于1%的设备高度(设计稿高度),这样看来vw,vh其它是最方便的,但是目前兼容性不是特别好。
vw单位在绝大部分高版本浏览器内的支持性很好,但是opera浏览器整体不支持vw单位,如果需要兼容opera浏览器的布局,不推荐使用vw
175 http2.0
二进制分帧:HTTP 2.0 会将所有传输的信息分割为更小的消息和帧,并对它们采用二进制格式的编码 ,其中HTTP1.x的首部信息会被封装到Headers帧,而我们的request body则封装到Data帧里面。
多路复用:
HTTP 2.0 通信都在一个连接上完成,这个连接可以承载任意数量的双向数据流。相应地,每个数据流以消息的形式发送,而消息由一或多个帧组成,这些帧可以乱序发送,然后再根据每个帧首部的流标识符重新组装。
首部压缩
报文头压缩同样比较容易理解,减小HTTP报文中头部字段的开销,提供通信效率。采用报文头压缩主要是两个原因:
(1)对于单个HTTP报文而言,当携带较少的通信数据时,报文头部大小将远远大于有效的通信数据,导致带宽利用率较低。
(2)在持久化连接下,传送的多个HTTP报文之间,经常存在重复报文头字段在传输。
基于静态静态字典压缩
在HTTP协议中的客户端以及服务端之间,共同维护了一份静态字典。该静态字典中存储了大量常见的HTTP报文头字段。比如下述,静态字典:
在静态字典的基础上,可以利用静态字典中的索引号代替HTTP中的报文头,一般来说一个字节就足以覆盖静态字典中的所有索引号了。如下图所示,利用一个字节格式,来代替HTTP报文头,index是静态字典中的索引号。
基于动态字典压缩
静态字典并不能够涵盖HTTP头部键值对所有的组合情况,为此在静态字典压缩的基础上补充了动态字典压缩。
动态字典压缩过程比较简单。如果遇见在静态字典中不存在的HTTP头部字段,那么此处采用非压缩传输,接着把该头部字段添加到动态字段中。当下次传送同样的头部字段时,则可以依据动态字典的内容对该头部字段进行压缩了。
当通信过程越长导致动态字典积累的内容将越多,因此HTTP头部压缩的效果越佳
动态字典的内容会在连接新建立的时候重置。
服务器推送
HTTP 2.0 新增的一个强大的新功能,就是服务器可以对一个客户端请求发送多个响应。换句话说,除了对最初请求的响应外,服务器还可以额外向客户端推送资源,而无需客户端明确地请求。
174 清楚浮动的原理
1.clear:both,清除左右两侧浮动,独占一行,撑起了父元素的高度。
176 页面卡,你怎么检测
177 首页白屏
1.网络延迟,JS加载延迟 ,会阻塞页面
解决办法:
1.减少http的请求
css的图片使用雪碧图的方式
css的图片进行图片的懒加载模式
使用缓存机制
2.对css和js文件进行相应的压缩
3.cdn
4.js的异步加载
178.前端衡量性能指标
1.浏览器开始渲染的时间,从用户角度出发则可以定义为用户在页面上看到的第一个内容的时间。
2.页面解析完成的时间
3.window.onload事件触发的时间。window.onload事件要等到所有资源加载完成后才会触发
4.页面可交互的时间
179.cdn怎么找到最近的站点
180.如何实现渲染后台传来的html片段
181.getelementbyid.innerhtml和innertext区别
innerText:拿到的是文本,如果文本里面有<>尖括号,不会把<>尖括号当成html元素解析
innerHTML:拿到的是文本,如果文本里面有<>尖括号,会把<>尖括号当成html元素解析
其实innerHTML和innerText获取到的都是文本,唯一的区别就是如果文本中有<>尖括号,innerText不会把<>尖括号当成html元素解析,而innerHTML会把<>尖括号当成html元素解析
182.vue3.0新增了什么
176 实现一个快排+优化(不用递归)
177.浏览器一个tab页卡住了,为什么其他tab没事
178.requestAnimationFrame
手写loadsh的_.get方法,要求能针对错误输入处理
179.算法中时间复杂度和空间复杂度,分别对应计算机什么硬件资源的使用?
180.计算机如何存储小数?0.1+0.2 ?= 0.3
181.深拷贝是什么?实现 deepCopy 接收任意类型的值。
182.面向对象的特征
抽象,封装,继承,多态
183.基于对象和面向对象的区别,以及JS是面向对象还是基于对象
面向对象和基于对象的区别是多态,和继承无关。
184.观察者模式
class PubSub {
constructor() {
this.handles = {};
}
// 订阅事件
on(eventType, handle) {
if (!this.handles.hasOwnProperty(eventType)) {
this.handles[eventType] = [];
}
if (typeof handle == 'function') {
this.handles[eventType].push(handle);
} else {
throw new Error('缺少回调函数');
}
return this;
}
// 发布事件
emit(eventType, ...args) {
if (this.handles.hasOwnProperty(eventType)) {
this.handles[eventType].forEach((item, key, arr) => {
item.apply(null, args);
})
} else {
throw new Error(`"${eventType}"事件未注册`);
}
return this;
}
// 删除事件
off(eventType, handle) {
if (!this.handles.hasOwnProperty(eventType)) {
throw new Error(`"${eventType}"事件未注册`);
} else if (typeof handle != 'function') {
throw new Error('缺少回调函数');
} else {
this.handles[eventType].forEach((item, key, arr) => {
if (item == handle) {
arr.splice(key, 1);
}
})
}
return this; // 实现链式操作
}
}
// 下面做一些骚操作
let callback = function () {
console.log('you are so nice');
}
let pubsub = new PubSub();
pubsub.on('completed', (...args) => {
console.log(args.join(' '));
}).on('completed', callback);
pubsub.emit('completed', 'what', 'a', 'fucking day');
pubsub.off('completed', callback);
pubsub.emit('completed', 'fucking', 'again');
185.promise.race
const race = function (iterable) {
return new Promise(function (resolve, reject) {
for (const i in iterable) {
const v = iterable[i]
if (typeof v === 'object' && typeof v.then === 'function') {
v.then(resolve, reject)
} else {
resolve(v)
}
}
})
}
const p1 = new Promise(function (resolve) { setTimeout(resolve, 200, 1) })
const p2 = new Promise(function (resolve) { setTimeout(resolve, 100, 2) })
race([p1, p2]).then(function (res) { console.log(res) }) // 2
实现一个快排+优化(不用递归)