正态性与异常值
如欲转载本文,请先与作者联系并获得授权。
3 正态性与异常值
学习前提:懂得偏度、峰度与正态分布(normal distribution)的含义,具备基础的SPSS操作能力。
许多参数估计方法均要求数据分布为正态(normality),且期望不存在异常值(outlier)。
3.1 简介
3.1.1 概念
(1)正态分布
正态分布(或称“常态分布”,normal distribution)是一种分布频次从中间往两边递减的形态。由于其形状酷似一口倒挂的钟,也常被人们称为“钟形曲线”。假如某个连续变量符合正态分布,我们就可以通过个案的标准差来判断个案在总体中的大致位置。

图3.1-1 正态分布
除了单个变量的正态分布,多个变量同时符合正态分布被称为“多元正态(multivariate normality)”。
(2)异常值
关于异常值的定义较多,Aguinis等人(2013)收集整理了14种与异常值有关的定义,除去某些与特定分析方法相关的异常值定义(例如元分析中的异常值),其余定义主要可分为3类。
其一,认为异常值是一种错误值。例如,认为异常值是由观测误差、记录误差或者计算误差产生的值。
其二,认为异常值是一种“有趣”的值。该观点认为,异常值与其他数据点较远,提供了丰富的信息,并非错误的数据,值得我们进一步探索其形成原因。
其三,认为异常值就是对模型拟合或者参数估计具有影响力的数据。该观点认为,有一部分数据即使个数很少也能影响分析结果,我们需要进一步查看其影响力的大小。
此外,从前两种观点视角出发,异常值一般与数据分布有关,而正态分布是所有数据分布中应用最广泛的一种形式,所以异常值往往与正态分布挂钩。比如,有的研究者会将超过3个标准差的数据判断为异常值(正态分布中,正负3个标准差能包含约99.7%的数据)。
3.1.2 数据分布非正态的原因与处理
(1)原因
数据非正态分布的原因有很多,但我们首先需要明白的是:正态分布并不是数据分布的唯一形式;数据往往不是正态与否的二元判断,而是“在多大程度上不那么正态”。一方面,数据也可以有其它的分布,比如,统计上常见的χ2分布、t分布和F分布;又或者,掷色子时获得每种点数的概率都是相同的,属于均匀分布。在许多领域,甚至非正态的数据分布才是常态,比如生存领域,多为指数分布。另一方面,完美的正态分布在现实中几乎是不可能的,每一批数据多多少少都会“有点”偏离正态分布。
其次,数据可能存在某些异常值。比如,篮球明星姚明小时候在学校,身高就远远超过同龄人,这种偶然的极端数据可能会导致样本数据并非正态分布。在数据采集过程中,我们总是希望自己刚好能采集到足够好的数据,但我们也不要忘记,即使是统计上经常采用的显著性水平“α=0.05”也暗含着每20次事件中就会包含1次小概率事件,数据中的异常点可能是我们无法避免的。样本数过少的时候,发生小概率事件的可能越大。
再者,抽样方式也会影响收集到的数据分布,这在问卷调查中并不少见。比如,某情绪量表(分数在20至100分之间,分数越高,则情绪越差)主要应用于普通人施测,对于普通人而言,平均分为60分。然而,我们使用该量表对一批抑郁症患者进行施测,可想而知,结果是普遍高分。对于普通人进行施测,数据呈正态分布,但是对于抑郁症患者进行施测,则遭遇天花板效应(ceiling effect),导致数据分布不如意。这是经验不足的研究者容易遇到的问题。

图3.1-2 不同人群的分数分布
此外,假如我们将图3.1-2中的两个分布合并到一起,可能会产生双峰分布(图3.1-3)。在实际研究中,部分研究者拥有较多资源,能够针对不同人群进行取样,但不同人群的分数分布并不一定很接近,当两个群体差异较大时,合并数据就可能产生意外结果。
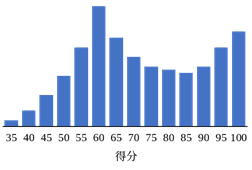
图3.1-3 两个群体数据合并后的双峰分布
数据没有呈现出正态分布的原因还有很多,读者在实际研究中需要多方考虑,也勿理所当然的认为所有数据都必须是正态分布。
(2)处理
面对非正态数据的时候,有许多应对的方法。
其一,部分研究者会不做处理,直接进行分析,这对应两种理由。第一,样本量足够大。并非说样本量足够大数据就能满足正态分布,而是因为样本量足够大之后,非正态性的影响就小了很多。统计领域存在一些谣传:“当样本量超过30的时候数据就近似于正态分布,不需要做正态检验”。其实正态分布与样本量无关,但是样本量足够大的时候,根据中心极限定理(Central
Limit Theorem),样本均值(不是样本)会服从正态分布。第二,许多检验对非正态性数据的抵抗力并没有想象中的差。基于这些原因,当我们翻阅文献时,会发现问卷调查领域的文献有许多都未进行正态检验。
其二,一部分研究者会考虑更换统计方法以应对数据的非正态。比如,在数据符合正态分布时使用独立样本t检验,但是数据不符合正态分布时可更换成Mann-Whitney U检验,本书后续部分将会讲述此内容。在许多分析中,我们也不一定会更换分析的直接方法,而是进行分析的优化,比如将Bootstrap与普通分析方法进行结合。由于Bootstrap对非正态数据的估计具有良好的稳健性(Efron & Tibshirani, 1994),加上计算机性能的普遍提高,近年来已经广泛应用。
其三,许多领域会对数据进行转换,使其符合正态分布,再进行相应的分析。但不是每一类数据都适合进行转换,有的数据转换后也依然非正态,而且难以解释。该部分内容见本书数据转换章节。
其四,如果是由于小样本而导致的数据非正态分布(小样本具有随机性),在条件允许的情况下可适当增加样本量。
3.1.3 数据存在异常值的原因与处理
(1)原因
当数据中心存在异常值时,可能会扭曲统计分析的结果,而这是每个数据分析工作者都将面对的问题。以笔者经验而言,最常见的异常值产生原因有5种。
其一,输入错误。假如我们在问卷中询问学生身高,结果出现了1150cm的回答,则很明显属于输入错误。输入问题不仅在回答问题时会发生,在录入数据时也经常出现,为此,部分研究者可能会使用诸如EpiData软件进行双录入,避免该错误发生。
其二,抽样错误。统计分析总是立足于某些特定群体而得到结论,假如调查目标为小学三年级学生,但是有一名高中生填写了问卷,则该数据可能会体现为异常值(仅仅是可能)。
其三,异常因素的影响。假如我们对某个群体进行视力测量,但其中某人提前对视力表进行背诵,在测量中就会显示出异常的分数。在一些生物和地理科学中,自然因素造成的异常值并不少见(比如台风与降水)。
其四,数据本身的特性。某些数据由于自身特点,必定会包含“异常值”。比如,对某个小公司的工资数据进行采集,则公司高层的薪水必然远远大于员工,但这个“异常值”属于数据的内在特点。
其五,正常概率下的异常值。正态分布告诉我们,正负3个标准差能包含约99.7%的数据,从宏观角度而言,这意味着每收集大约333个数据必然会遭遇1个异常数据。当然,在每一次抽样中遭遇这类异常值的概率并不相同,即使是十几个数据的小样本也可能存在这类异常值,我们需要明白这是数据分布的正常结果。
(2)处理
由于异常值的判断标准与原因界定往往是多样化的,同一批数据在不同研究者手上可能得出不同结论,因此本书不准备提供与Aguinis等人(2013)一样的流程,而是从几种主要的处理方式出发,给出建议。
其一,不做任何处理,正常分析。异常值的比例往往较小,对于一个大样本来说,即使存在异常值,对分析结果的影响也是极小的,这种时候,我们可能无需删除异常值,也不用做任何处理。该视角下的异常值往往是自然概率下产生的异常值。
其二,删除异常值。当我们判断某些值属于异常值,并且是错误的异常值时,在情况允许下对其进行校正,否则应该进行删除处理(Kutner,2004)。为了避免这类异常值的发生,我们需要在调查的全流程中做好记录,才能在问题发生后进行回溯式的复查,寻找异常值产生的原因。当我们存在许多数据,异常值的影响并不大的时候,也可以对异常值进行剔除。
其三,不删除异常值,更换统计方法。假如我们的数据中存在大量异常值(比例较高),则我们没有理由进行删除,这或许是该数据的真实分布;对于某些研究来说,即使是微小的变化也非常重要,则我们也不应该删除异常值。面对这类情况时,我们可以同面对非正态数据时一般,选择更为稳健的分析方法(例如非参数的方法、Bootstrap方法等)。这些方法往往对数据分布不苛刻,对于异常值具有很好的抵抗力。
其四,对数据进行转换后再分析。例如经济领域经常会对数据作缩尾(winsorize)处理。由于异常值经常与正态分布挂钩,部分研究者会对数据采取正态转换以减少异常值的影响。
此外,还有许多异常值处理方法。部分学者会同时报告完整数据与删除异常值后的数据结果,通过对比两个结果,来阐明异常值的影响力大小;当存在大量异常值时,对异常值进行另外的分析,对比异常值与“正常值”的子样本结果,进一步挖掘数据信息;使用平均值替换异常值进行分析;或者将异常值视为缺失值,采用缺失值的分析方法进行处理。
不同的处理方法可能并没有绝对的对错之分,更多的是合适与不合适的问题。读者在使用某些统计方法判断出异常值后,仍需探究其形成原因,并进一步检查异常值带来的影响,才能决定如何更好的处理异常值问题。
参考文献
Aguinis, H., Gottfredson, R. K., & Joo, H. (2013). Best-practice recommendations for defining, identifying, and handling outliers. Organizational Research Methods, 16(2), 270-301.
Efron, B., & Tibshirani, R. J. (1994). An introduction to the bootstrap. CRC
press.
Kutner, M. H., Nachtsheim, C. J., Neter, J., & Li, W. (2004). Applied linear
statistical models (5th ed.). Boston:McGraw-Hill/Irwin.