Java十大算法(2):普利姆算法(Prim)、克鲁斯卡尔算法(Kruskal)、迪杰斯特拉算法(Dijkstra)、弗洛伊德算法(Floyd)、马踏棋盘算法
6、普利姆算法(Prim)
最小生成树:
修路问题本质就是就是最小生成树问题, 先介绍一下 最小生成树 (Minimum Cost Spanning Tree),简称MST。
- 给定一个带权的无向连通图,如何选取一棵生成树,使树上所有边上权的总和为最小,这叫最小生成树
- N个顶点,一定有N-1条边
- 包含全部顶点
- N-1条边都在图中
- 举例说明(如图)

- 求最小生成树的算法主要是普里姆 算法和克鲁斯卡尔算法
普里姆算法介绍:
- 普利姆(Prim)算法求最小生成树,也就是在包含n个顶点的连通图中,找出只有(n-1)条边包含所有n个顶点的连通子图,也就是所谓的极小连通子图。
- 普利姆的算法如下:
(1)设G=(V,E)是连通网,T=(U,D)是最小生成树,V,U是顶点集合,E,D是边的集合。
(2)若从顶点u开始构造最小生成树,则从集合V中取出顶点u放入集合U中,标记顶点v的visited[u]=1。
(3)若集合U中顶点ui与集合V-U中的顶点vj之间存在边,则寻找这些边中权值最小的边,但不能构成回路,将顶点vj加入集合U中,将边(ui,vj)加入集合D中,标记visited[vj]=1。
(4)重复步骤②,直到U与V相等,即所有顶点都被标记为访问过,此时D中有n-1条边。
普里姆算法最佳实践(修路问题):

有胜利乡有7个村庄(A, B, C, D, E, F, G) ,现在需要修路把7个村庄连通,各个村庄的距离用边线表示(权) ,比如 A – B 距离 5公里,问:如何修路保证各个村庄都能连通,并且总的修建公路总里程最短?
图解:

代码:
public class PrimAlgorithm {
public static void main(String[] args) {
char[] data=new char[] {'A','B','C','D','E','F','G'};
int vertexs = data.length;
//用二维数组来表示邻接矩阵
int[][] weight = new int[][] {//用10000这个较大的数表示不连通
{10000,5,7,10000,10000,10000,2},
{5,10000,10000,9,10000,10000,3},
{7,10000,10000,10000,8,10000,10000},
{10000,9,10000,10000,10000,4,10000},
{10000,10000,8,10000,10000,5,4},
{10000,10000,10000,4,5,10000,6},
{2,3,10000,10000,4,6,10000},
};
//创建图对象
MGraph graph = new MGraph(vertexs);
//创建最小生成树对象
MinTree minTree = new MinTree();
minTree.createGraph(graph, vertexs, data, weight);
//输出最小生成树
minTree.showGraph(graph);
//测试算法
minTree.prim(graph, 1);
}
}
// 创建最小生成树
class MinTree {
// 创建图的邻接矩阵
/**
*
* @param graph
* 图对象
* @param vertexs
* 图对应的顶点个数
* @param data
* 图对应的各个顶点的值
* @param weight
* 图的邻接矩阵
*/
public void createGraph(MGraph graph, int vertexs, char[] data, int[][] weight) {
for (int i = 0; i < vertexs; i++) {
graph.data[i] = data[i];
for (int j = 0; j < vertexs; j++) {
graph.weight[i][j] = weight[i][j];
}
}
}
// 显示图的邻接矩阵
public void showGraph(MGraph graph) {
for(int i=0;i<graph.vertexs;i++) {
for(int j=0;j<graph.vertexs;j++) {
System.out.printf("%6d",graph.weight[i][j]);
}
System.out.println();
}
}
//编写Prim算法得到最小生成树
/**
*
* @param graph 图
* @param v 表示从图的第几个顶点开始生成'A'->0, 'B'->1 ...
*/
public void prim(MGraph graph, int v) {
//visited数组表示顶点是否被访问过
int[] visited = new int[graph.vertexs];//默认就为0
//把当前节点标记为已经访问
visited[v]=1;
//h1和h2记录两个顶点的下标
int h1=-1;
int h2=-1;
int minWeight=10000;//将其设置为一个比较大的数,在后面的遍历过程中会被替换
for(int k=1;k<graph.vertexs;k++) {//因为有vertexs个顶点,则经过prim算法过后一定有vertexs-1条边
//确定每一次生成的子图,和哪个结点距离最近
for(int i=0;i<graph.vertexs;i++) {//i表示被访问过的点
for(int j=0;j<graph.vertexs;j++) {//j表示与i结点相连且未被访问过的点
if(visited[i]==1&&visited[j]==0&&graph.weight[i][j]<minWeight) {
//替换minWeight,由此来寻找满足条件两边中权值最小的
minWeight=graph.weight[i][j];
h1=i;
h2=j;
}
}
}
//此时已经找到了一条最小的边,则将这个边输出
System.out.println("在边 <"+graph.data[h1]+"-"+graph.data[h2]+">修路 权值为:"+minWeight);
//将当前这个新点标记为已访问过
visited[h2]=1;
//重置minWeight
minWeight=10000;
}
}
}
class MGraph {
int vertexs;// 表示节点数
char[] data;// 存放节点数据
int[][] weight;// 存放边
public MGraph(int vertexs) {
this.vertexs = vertexs;
data = new char[vertexs];
weight = new int[vertexs][vertexs];
}
}
结果:
10000 5 7 10000 10000 10000 2
5 10000 10000 9 10000 10000 3
7 10000 10000 10000 8 10000 10000
10000 9 10000 10000 10000 4 10000
10000 10000 8 10000 10000 5 4
10000 10000 10000 4 5 10000 6
2 3 10000 10000 4 6 10000
在边 <B-G>修路 权值为:3
在边 <G-A>修路 权值为:2
在边 <G-E>修路 权值为:4
在边 <E-F>修路 权值为:5
在边 <F-D>修路 权值为:4
在边 <A-C>修路 权值为:7
7、克鲁斯卡尔算法(Kruskal)
克鲁斯卡尔算法介绍:
- 克鲁斯卡尔(Kruskal)算法,是用来求加权连通图的最小生成树的算法。
- 基本思想:按照权值从小到大的顺序选择n-1条边,并保证这n-1条边不构成回路。
- 具体做法:首先构造一个只含n个顶点的森林,然后依权值从小到大从连通网中选择边加入到森林中,并使森林中不产生回路,直至森林变成一棵树为止。
克鲁斯卡尔最佳实践-公交站问题:

有北京有新增7个站点(A, B, C, D, E, F, G) ,现在需要修路把7个站点连通,各个站点的距离用边线表示(权) ,比如 A – B 距离 12公里,问:如何修路保证各个站点都能连通,并且总的修建公路总里程最短?
图解:

代码:
import java.util.Arrays;
public class KruskalCase {
private int edgeNum;//记录有多少条边
private char[] vertexs;//记录顶点
private int[][] matrix;//邻接矩阵
//使用INF表示两个顶点不能连通
private static final int INF = Integer.MAX_VALUE;
public static void main(String[] args) {
char[] vertexs = {'A','B','C','D','E','F','G'};
//邻接矩阵
int[][] matrix= {
/*A*//*B*//*C*//*D*//*E*//*F*//*G*/
/*A*/ { 0, 12, INF, INF, INF, 16, 14},
/*B*/ { 12, 0, 10, INF, INF, 7, INF},
/*C*/ { INF, 10, 0, 3, 5, 6, INF},
/*D*/ { INF, INF, 3, 0, 4, INF, INF},
/*E*/ { INF, INF, 5, 4, 0, 2, 8},
/*F*/ { 16, 7, 6, INF, 2, 0, 9},
/*G*/ { 14, INF, INF, INF, 8, 9, 0}
};
//创建KruskalCase对象实例
KruskalCase kruskalCase = new KruskalCase(vertexs, matrix);
//输出图
kruskalCase.print();
kruskalCase.kruskal();
}
//构造器
public KruskalCase(char[] vertexs ,int[][] matrix) {
//初始化顶点个数,和边的个数
int vlen = vertexs.length;
//初始化顶点
this.vertexs=vertexs.clone();
//初始化边
this.matrix=matrix.clone();
//统计边的个数
for(int i=0;i<vlen;i++) {
for(int j=i+1;j<vlen;j++){
if(this.matrix[i][j]!=INF) {
edgeNum++;
}
}
}
}
public void kruskal() {
int index=0;//表示最后结果数组的索引
int[] ends = new int[vertexs.length];//用于保存“已有最小生成树”中的每个顶点在最小生成树中的终点
//创建结果数组,用于保存最后的最小生成树
EData[] res = new EData[vertexs.length-1];
//获取图中所有的边的集合(12条边)
EData[] edges = getEdges();
//按边的权值大小排序(从小到大)
sortEdges(edges);
//遍历edges数组,添加边入最小生成树。判断准备加入的边是否形成了回路,如果没形成则加入最小生成树中,否则继续遍历
for(int i=0;i<edgeNum;i++) {
//获取第i条边的第一个顶点
int p1 = getPosition(edges[i].start);
//获取第i条边的第二个顶点
int p2 = getPosition(edges[i].end);
//获取p1顶点在已有最小生成树中的终点
int m = getEnd(ends, p1);
//获取p2顶点在已有最小生成树中的终点
int n = getEnd(ends, p2);
//判断是否构成回路
if(m!=n) {//没有构成回路
ends[m]=n;
res[index++]=edges[i];
}
}
//打印最小生成树
System.out.println("最小生成树:");
for(int i=0;i<res.length;i++) {
System.out.println(res[i]);
}
System.out.println(Arrays.toString(ends));
}
//打印邻接矩阵
public void print() {
System.out.println("邻接矩阵为:");
for(int i=0;i<vertexs.length;i++) {
for(int j=0;j<vertexs.length;j++) {
System.out.printf("%12d",matrix[i][j]);
}
System.out.println();
}
}
//对边进行排序处理(冒泡)
private void sortEdges(EData[] edges) {
for(int i=0;i<edges.length-1;i++) {
for(int j=0;j<edges.length-1-i;j++) {
if(edges[j].weight>edges[j+1].weight) {
EData temp = edges[j];
edges[j]=edges[j+1];
edges[j+1]=temp;
}
}
}
}
//返回传入顶点对应的下标
private int getPosition(char ch) {
for(int i=0;i<vertexs.length;i++) {
if(vertexs[i]==ch) {
return i;
}
}
return -1;
}
//获取图中的所有边,放入EData数组中,通过邻接矩阵来获取
private EData[] getEdges() {
int index=0;
EData[] edges = new EData[edgeNum];
for(int i=0;i<vertexs.length;i++) {
for(int j=i+1;j<vertexs.length;j++) {
if(matrix[i][j]!=INF) {
edges[index++]=new EData(vertexs[i],vertexs[j],matrix[i][j]);
}
}
}
return edges;
}
//获取下标为i的顶点的终点的下标
//ends数组用来记录各个顶点的终点是哪个,它是在遍历过程中逐步生成的
private int getEnd(int[] ends,int i) {
while(ends[i]!=0) {
i=ends[i];
}
return i;
}
}
//创建一个类,其对象实例表示一条边
class EData{
char start;//边的一个点
char end;//边的另一个点
int weight;//边的权值
//构造器
public EData(char start, char end, int weight) {
super();
this.start = start;
this.end = end;
this.weight = weight;
}
//输出边的信息
@Override
public String toString() {
return "EData [<" + start + ", " + end + "> =" + weight + "]";
}
}
结果:
邻接矩阵为:
0 12 2147483647 2147483647 2147483647 16 14
12 0 10 2147483647 2147483647 7 2147483647
2147483647 10 0 3 5 6 2147483647
2147483647 2147483647 3 0 4 2147483647 2147483647
2147483647 2147483647 5 4 0 2 8
16 7 6 2147483647 2 0 9
14 2147483647 2147483647 2147483647 8 9 0
最小生成树:
EData [<E, F> =2]
EData [<C, D> =3]
EData [<D, E> =4]
EData [<B, F> =7]
EData [<E, G> =8]
EData [<A, B> =12]
8、迪杰斯特拉算法(Dijkstra)
迪杰斯特拉(Dijkstra)算法介绍:
迪杰斯特拉(Dijkstra)算法是典型最短路径算法,用于计算一个结点到其他结点的最短路径。 它的主要特点是以起始点为中心向外层层扩展(广度优先搜索思想),直到扩展到终点为止。
迪杰斯特拉(Dijkstra)算法过程:
设置出发顶点为v,顶点集合V{v1,v2,vi…},v到V中各顶点的距离构成距离集合Dis,Dis{d1,d2,di…},Dis集合记录着v到图中各顶点的距离(到自身可以看作0,v到vi距离对应为di)
- 从Dis中选择值最小的di并移出Dis集合,同时移出V集合中对应的顶点vi,此时的v到vi即为最短路径。
- 更新Dis集合,更新规则为:比较v到V集合中顶点的距离值,与v通过vi到V集合中顶点的距离值,保留值较小的一个(同时也应该更新顶点的前驱节点为vi,表明是通过vi到达的)。
- 重复执行两步骤,直到最短路径顶点为目标顶点即可结束。
迪杰斯特拉(Dijkstra)算法最佳应用-最短路径:
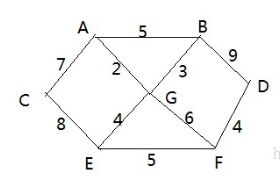
战争时期,胜利乡有7个村庄(A, B, C, D, E, F, G) ,现在有六个邮差,从G点出发,需要分别把邮件分别送到 A, B, C , D, E, F 六个村庄,各个村庄的距离用边线表示(权) ,比如 A – B 距离 5公里,问:如何计算出G村庄到 其它各个村庄的最短距离?
图解:

代码:
import java.util.Arrays;
public class DijkstraAlgorithm {
public static void main(String[] args) {
char[] vertex = { 'A', 'B', 'C', 'D', 'E', 'F', 'G' };
// 邻接矩阵
int[][] matrix = new int[vertex.length][vertex.length];
final int N = 65535;// 表示不可连接
matrix[0] = new int[] { N, 5, 7, N, N, N, 2 };
matrix[1] = new int[] { 5, N, N, 9, N, N, 3 };
matrix[2] = new int[] { 7, N, N, N, 8, N, N };
matrix[3] = new int[] { N, 9, N, N, N, 4, N };
matrix[4] = new int[] { N, N, 8, N, N, 5, 4 };
matrix[5] = new int[] { N, N, N, 4, 5, N, 6 };
matrix[6] = new int[] { 2, 3, N, N, 4, 6, N };
// 创建Graph对象
Graph graph = new Graph(vertex, matrix);
graph.showGraph();
graph.dijkstra(6);
graph.showDijkstra();
}
}
class Graph {
private char[] vertex;// 存放各个顶点
private int[][] matrix;// 邻接矩阵
private VisitedVertex visitedVertex;// 已经访问的定点的集合
// 构造器
public Graph(char[] vertexs, int[][] matrix) {
this.vertex = vertexs;
this.matrix = matrix;
}
// 显示最后结果
public void showDijkstra() {
visitedVertex.show();
}
// 显示图
public void showGraph() {
for (int[] link : matrix) {
System.out.println(Arrays.toString(link));
}
}
// 地杰斯特拉算法实现,index表示出发顶点的下标
public void dijkstra(int index) {
visitedVertex = new VisitedVertex(vertex.length, index);
update(index);// 更新距离和前驱顶点
for (int i = 1; i < vertex.length; i++) {
index = visitedVertex.updateArr();// 选择并访问新的访问顶点
update(index);
}
}
// 同时更新index下标顶点到周围相连顶点的距离,和周围相连顶点的前驱顶点
public void update(int index) {
int len = 0;
// 遍历邻接矩阵的index行
for (int i = 0; i < matrix[index].length; i++) {
// len表示出发顶点到index顶点的距离 + index顶点到i顶点的距离
len = visitedVertex.getDis(index) + matrix[index][i];
// 如果i顶点未被访问过,并且len小于出发顶点到i顶点的距离,就要更新
if (!visitedVertex.in(i) && len < visitedVertex.getDis(i)) {
visitedVertex.updatePre(i, index);// 更新i顶点的前驱顶点为index顶点
visitedVertex.updateDis(i, len);// 更新出发顶点到i顶点的距离为len
}
}
}
}
// 已访问顶点集合
class VisitedVertex {
public int[] already_arr;// 记录各个顶点是否为访问过
public int[] pre_visited;// 记录本下标顶点所对应的前一个顶点的下标
public int[] dis;// 记录出发顶点到与其相连的所有顶点的距离,将距离最短的放入dis中
// 构造器
/**
*
* @param length
* 顶点的个数
* @param index
* 出发顶点对应的下标
*/
public VisitedVertex(int length, int index) {
this.already_arr = new int[length];//标记某个顶点是否已经被访问
this.pre_visited = new int[length];//记录每个顶点的上一个顶点是哪一个(用来确定最短路径是哪一条)
this.dis = new int[length];//起始点到每一个点的最短路径长度
// 初始化dis数组,全填为最大值(除了出发顶点)
Arrays.fill(dis, 65535);
this.already_arr[index] = 1;// 设置出发顶点已经被访问过
this.dis[index] = 0;// 设置出发顶点的访问距离为0
}
// 判断index顶点是否被访问过
public boolean in(int index) {
return already_arr[index] == 1;
}
// 更新出发顶点到index顶点的距离,更新为len
public void updateDis(int index, int len) {
dis[index] = len;
}
// 更新pre顶点的前驱顶点,更新为index
public void updatePre(int pre, int index) {
pre_visited[pre] = index;
}
// 返回出发顶点到index顶点的距离
public int getDis(int index) {
return dis[index];
}
// 继续选择并返回新的访问顶点,比如G完之后就是A作为一个新的访问顶点(并非出发顶点)
public int updateArr() {
int min = 65535, index = 0;
for (int i = 0; i < already_arr.length; i++) {
if (already_arr[i] == 0 && dis[i] < min) {
min = dis[i];
index = i;
}
}
// 更新index被访问过
already_arr[index] = 1;
return index;
}
// 显示最后的结果
public void show() {
System.out.println("==========================");
// 输出already_arr
for (int i : already_arr) {
System.out.print(i + " ");
}
System.out.println();
// 输出pre_visited
for (int i : pre_visited) {
System.out.print(i + " ");
}
System.out.println();
// 输出dis
for (int i : dis) {
System.out.print(i + " ");
}
System.out.println();
// 为了好看最后的最短距离,我们处理
char[] vertex = { 'A', 'B', 'C', 'D', 'E', 'F', 'G' };
int count = 0;
for (int i : dis) {
if (i != 65535) {
System.out.print(vertex[count] + "(" + i + ") ");
} else {
System.out.println("N ");
}
count++;
}
System.out.println();
}
}
结果:
[65535, 5, 7, 65535, 65535, 65535, 2]
[5, 65535, 65535, 9, 65535, 65535, 3]
[7, 65535, 65535, 65535, 8, 65535, 65535]
[65535, 9, 65535, 65535, 65535, 4, 65535]
[65535, 65535, 8, 65535, 65535, 5, 4]
[65535, 65535, 65535, 4, 5, 65535, 6]
[2, 3, 65535, 65535, 4, 6, 65535]
==========================
1 1 1 1 1 1 1
6 6 0 5 6 6 0
2 3 9 10 4 6 0
[65535, 5, 7, 65535, 65535, 65535, 2]
[5, 65535, 65535, 9, 65535, 65535, 3]
[7, 65535, 65535, 65535, 8, 65535, 65535]
[65535, 9, 65535, 65535, 65535, 4, 65535]
[65535, 65535, 8, 65535, 65535, 5, 4]
[65535, 65535, 65535, 4, 5, 65535, 6]
[2, 3, 65535, 65535, 4, 6, 65535]
==========================
1 1 1 1 1 1 1
6 6 0 5 6 6 0
2 3 9 10 4 6 0
A(2) B(3) C(9) D(10) E(4) F(6) G(0)
其中 A(2) B(3) C(9) D(10) E(4) F(6) G(0) 括号中的数字表示G点与括号前的点最短的距离。
9、弗洛伊德算法(Floyd)
弗洛伊德(Floyd)算法介绍:
- 和Dijkstra算法一样,弗洛伊德(Floyd)算法也是一种用于寻找给定的加权图中顶点间最短路径的算法。该算法名称以创始人之一、1978年图灵奖获得者、斯坦福大学计算机科学系教授罗伯特·弗洛伊德命名。
- 弗洛伊德算法(Floyd)计算图中各个顶点之间的最短路径。
- 迪杰斯特拉算法用于计算图中某一个顶点到其他顶点的最短路径。
- 弗洛伊德算法 VS 迪杰斯特拉算法:迪杰斯特拉算法通过选定的被访问顶点,求出从出发访问顶点到其他顶点的最短路径;弗洛伊德算法中每一个顶点都是出发访问点,所以需要将每一个顶点看做被访问顶点,求出从每一个顶点到其他顶点的最短路径。
弗洛伊德(Floyd)算法分析:
- 设置顶点vi到顶点vk的最短路径已知为Lik,顶点vk到vj的最短路径已知为Lkj,顶点vi到vj的路径为Lij,则vi到vj的最短路径为:min((Lik+Lkj),Lij),vk的取值为图中所有顶点,则可获得vi到vj的最短路径。
- 至于vi到vk的最短路径Lik或者vk到vj的最短路径Lkj,是以同样的方式获得。
弗洛伊德(Floyd)算法最佳应用-最短路径:

胜利乡有7个村庄(A, B, C, D, E, F, G),各个村庄的距离用边线表示(权) ,比如 A – B 距离 5公里,问:如何计算出各村庄到 其它各村庄的最短距离?
图解:

代码实现:
package floyd;
import java.util.Arrays;
public class FloydAlgorithm {
public static void main(String[] args) {
char[] vertex = { 'A', 'B', 'C', 'D', 'E', 'F', 'G' };
int[][] matrix = new int[vertex.length][vertex.length];
final int N = 65535;
matrix[0] = new int[] { 0, 5, 7, N, N, N, 2 };
matrix[1] = new int[] { 5, 0, N, 9, N, N, 3 };
matrix[2] = new int[] { 7, N, 0, N, 8, N, N };
matrix[3] = new int[] { N, 9, N, 0, N, 4, N };
matrix[4] = new int[] { N, N, 8, N, 0, 5, 4 };
matrix[5] = new int[] { N, N, N, 4, 5, 0, 6 };
matrix[6] = new int[] { 2, 3, N, N, 4, 6, 0 };
Graph graph = new Graph(vertex.length, matrix, vertex);
graph.floyd();
graph.show();
}
}
class Graph {
private char[] vertex;// 存放顶点
private int[][] dis;// 保存从各个顶点出发到其它顶点的距离
private int[][] pre;// 保存前驱顶点
// 构造器
/**
*
* @param length
* 大小
* @param matrix
* 邻接矩阵
* @param vertex
* 顶点数组
*/
public Graph(int length, int[][] matrix, char[] vertex) {
this.vertex = vertex;
this.dis = matrix;
this.pre = new int[length][length];
// 对pre数组初始化,存放的是顶点下标
for (int i = 0; i < length; i++) {
Arrays.fill(pre[i], i);
}
}
// 显示dis数组和pre数组
public void show() {
// 为了显示便于阅读,我们优化一下输出
char[] vertex = { 'A', 'B', 'C', 'D', 'E', 'F', 'G' };
for (int k = 0; k < dis.length; k++) {
// 先将pre数组输出的一行
for (int i = 0; i < dis.length; i++) {
System.out.print(vertex[pre[k][i]] + " ");
}
System.out.println();
}
for (int k = 0; k < dis.length; k++) {
// 输出dis数组的一行数据
for (int i = 0; i < dis.length; i++) {
System.out.print("(" + vertex[k] + "到" + vertex[i] + "的最短路径是" + dis[k][i] + ") ");
}
System.out.println();
}
}
//弗洛伊德算法
public void floyd() {
int len=0;//保存变量距离
//遍历中间顶点,k为其下标
for(int k=0;k<dis.length;k++) {
//从i顶点出发
for(int i=0;i<dis.length;i++) {
//到达j顶点
for(int j=0;j<dis.length;j++) {
len = dis[i][k]+dis[k][j];//从i顶点出发,经过中间顶点k,到达j顶点的距离
if(len<dis[i][j]) {//如果len小于i到j的直连距离,则更新len;否则就不更新
dis[i][j]=len;
pre[i][j]=pre[k][j];
}
}
}
}
}
}
结果:
A A A F G G A
B B A B G G B
C A C F C E A
G D E D F D F
G G E F E E E
G G E F F F F
G G A F G G G
(A到A的最短路径是0) (A到B的最短路径是5) (A到C的最短路径是7) (A到D的最短路径是12) (A到E的最短路径是6) (A到F的最短路径是8) (A到G的最短路径是2)
(B到A的最短路径是5) (B到B的最短路径是0) (B到C的最短路径是12) (B到D的最短路径是9) (B到E的最短路径是7) (B到F的最短路径是9) (B到G的最短路径是3)
(C到A的最短路径是7) (C到B的最短路径是12) (C到C的最短路径是0) (C到D的最短路径是17) (C到E的最短路径是8) (C到F的最短路径是13) (C到G的最短路径是9)
(D到A的最短路径是12) (D到B的最短路径是9) (D到C的最短路径是17) (D到D的最短路径是0) (D到E的最短路径是9) (D到F的最短路径是4) (D到G的最短路径是10)
(E到A的最短路径是6) (E到B的最短路径是7) (E到C的最短路径是8) (E到D的最短路径是9) (E到E的最短路径是0) (E到F的最短路径是5) (E到G的最短路径是4)
(F到A的最短路径是8) (F到B的最短路径是9) (F到C的最短路径是13) (F到D的最短路径是4) (F到E的最短路径是5) (F到F的最短路径是0) (F到G的最短路径是6)
(G到A的最短路径是2) (G到B的最短路径是3) (G到C的最短路径是9) (G到D的最短路径是10) (G到E的最短路径是4) (G到F的最短路径是6) (G到G的最短路径是0)
10、马踏棋盘算法
马踏棋盘算法介绍:
- 马踏棋盘算法也被称为骑士周游问题
- 将马随机放在国际象棋的8×8棋盘Board [0~7] [0~7] 的某个方格中,马按走棋规则(马走日字)进行移动。要求每个方格只进入一次,走遍棋盘上全部64个方格。
- 游戏演示:马踏棋盘小游戏(6x6棋盘)


马踏棋盘游戏分析:
- 马踏棋盘问题(骑士周游问题)实际上是图的深度优先搜索(DFS)的应用。
- 如果使用回溯(就是深度优先搜索)来解决,假如马儿踏了53个点,如图:走到了第53个,坐标(1,0),发现已经走到尽头,没办法,那就只能回退了,查看其他的路径,就在棋盘上不停的回溯……
- 分析这种方式,可以再使用使用贪心算法(greedyalgorithm)的思想进行优化。即每次优先走再下一步走法较少的点。
图解:

代码:
import java.awt.Point;
import java.util.ArrayList;
public class HorseChessBoard {
private static int X;// 棋盘列数
private static int Y;// 棋盘行数
// 创建一个数组标记棋盘的各个位置是否被访问过
private static boolean visited[][];
// 使用一个属性,标记棋盘的所有位置是否都被访问过
private static boolean finished;
public static void main(String[] args) {
X = 8;
Y = 8;
int row = 1;// 马初始位置的行,从1开始
int col = 1;// 马初始位置的列,从1开始
// 创建棋盘
int[][] chessBoard = new int[X][Y];
visited = new boolean[X][Y];// 初始值均为false
long star = System.currentTimeMillis();
travelChessBoard(chessBoard, row - 1, col - 1, 1);
long end = System.currentTimeMillis();
System.out.println("共耗时:" + (end - star) + " ms");
//输出棋盘最后情况
for(int[] rows:chessBoard) {
for(int cols:rows) {
System.out.print(cols+"\t");
}
System.out.println();
}
}
/**
*
* @param chessBoard
* 棋盘
* @param row
* 马当前位置的行,从0开始
* @param col
* 马当前位置的列,从0开始
* @param step
* 第几步,从1开始
*/
public static void travelChessBoard(int[][] chessBoard, int row, int col, int step) {
chessBoard[row][col] = step;
visited[row][col] = true;// 标记该位置已经被访问
// 获取当前位置可以走的下一个位置的集合
ArrayList<Point> points = next(new Point(col, row));
// 遍历points
while (!points.isEmpty()) {
Point point = points.remove(0);
// 判断该点是否已经被访问过
if (!visited[point.y][point.x]) {
travelChessBoard(chessBoard, point.y, point.x, step + 1);
}
}
// 判断马是否完成任务(用step和应走的步数进行比较)
// 如果没有达到数量,则表示未完成任务,则将整个棋盘置0
// 如果step
// 1. 棋盘到目前位置仍然没有走完
// 2. 棋盘处于一个回溯过程
if (step < X * Y && !finished) {
chessBoard[row][col] = 0;
visited[row][col] = false;
} else {
finished = true;
}
}
// 根据当前位置(Point对象),计算马还能走那些位置(Point),并放入List集合中(最多有8个位置)
public static ArrayList<Point> next(Point curPoint) {
// 创建一个集合
ArrayList<Point> points = new ArrayList<Point>();
Point p1 = new Point();
// 表示马儿可以走5这个位置
if ((p1.x = curPoint.x - 2) >= 0 && (p1.y = curPoint.y - 1) >= 0) {
points.add(new Point(p1));
}
// 判断马儿可以走6这个位置
if ((p1.x = curPoint.x - 1) >= 0 && (p1.y = curPoint.y - 2) >= 0) {
points.add(new Point(p1));
}
// 判断马儿可以走7这个位置
if ((p1.x = curPoint.x + 1) < X && (p1.y = curPoint.y - 2) >= 0) {
points.add(new Point(p1));
}
// 判断马儿可以走0这个位置
if ((p1.x = curPoint.x + 2) < X && (p1.y = curPoint.y - 1) >= 0) {
points.add(new Point(p1));
}
// 判断马儿可以走1这个位置
if ((p1.x = curPoint.x + 2) < X && (p1.y = curPoint.y + 1) < Y) {
points.add(new Point(p1));
}
// 判断马儿可以走2这个位置
if ((p1.x = curPoint.x + 1) < X && (p1.y = curPoint.y + 2) < Y) {
points.add(new Point(p1));
}
// 判断马儿可以走3这个位置
if ((p1.x = curPoint.x - 1) >= 0 && (p1.y = curPoint.y + 2) < Y) {
points.add(new Point(p1));
}
// 判断马儿可以走4这个位置
if ((p1.x = curPoint.x - 2) >= 0 && (p1.y = curPoint.y + 1) < Y) {
points.add(new Point(p1));
}
return points;
}
}
结果:
共耗时:69672 ms
1 8 11 16 3 18 13 64
10 27 2 7 12 15 4 19
53 24 9 28 17 6 63 14
26 39 52 23 62 29 20 5
43 54 25 38 51 22 33 30
40 57 42 61 32 35 48 21
55 44 59 50 37 46 31 34
58 41 56 45 60 49 36 47
可以明显看到需要较长时间,才能运行出结果。
下面我们用贪心算法的思想进行优化,优先走再下一步走法较少的点:

代码:
import java.awt.Point;
import java.util.ArrayList;
import java.util.Comparator;
public class HorseChessBoard {
private static int X;// 棋盘列数
private static int Y;// 棋盘行数
// 创建一个数组标记棋盘的各个位置是否被访问过
private static boolean visited[][];
// 使用一个属性,标记棋盘的所有位置是否都被访问过
private static boolean finished;
public static void main(String[] args) {
X = 8;
Y = 8;
int row = 1;// 马初始位置的行,从1开始
int col = 1;// 马初始位置的列,从1开始
// 创建棋盘
int[][] chessBoard = new int[X][Y];
visited = new boolean[X][Y];// 初始值均为false
long star = System.currentTimeMillis();
travelChessBoard(chessBoard, row - 1, col - 1, 1);
long end = System.currentTimeMillis();
System.out.println("共耗时:" + (end - star) + " ms");
//输出棋盘最后情况
for(int[] rows:chessBoard) {
for(int cols:rows) {
System.out.print(cols+"\t");
}
System.out.println();
}
}
/**
*
* @param chessBoard
* 棋盘
* @param row
* 马当前位置的行,从0开始
* @param col
* 马当前位置的列,从0开始
* @param step
* 第几步,从1开始
*/
public static void travelChessBoard(int[][] chessBoard, int row, int col, int step) {
chessBoard[row][col] = step;
visited[row][col] = true;// 标记该位置已经被访问
// 获取当前位置可以走的下一个位置的集合
ArrayList<Point> points = next(new Point(col, row));
//对points中元素进行排序
sort(points);
// 遍历points
while (!points.isEmpty()) {
Point point = points.remove(0);
// 判断该点是否已经被访问过
if (!visited[point.y][point.x]) {
travelChessBoard(chessBoard, point.y, point.x, step + 1);
}
}
// 判断马是否完成任务(用step和应走的步数进行比较)
// 如果没有达到数量,则表示未完成任务,则将整个棋盘置0
// 如果step
// 1. 棋盘到目前位置仍然没有走完
// 2. 棋盘处于一个回溯过程
if (step < X * Y && !finished) {
chessBoard[row][col] = 0;
visited[row][col] = false;
} else {
finished = true;
}
}
// 根据当前位置(Point对象),计算马还能走那些位置(Point),并放入List集合中(最多有8个位置)
public static ArrayList<Point> next(Point curPoint) {
// 创建一个集合
ArrayList<Point> points = new ArrayList<Point>();
Point p1 = new Point();
// 表示马儿可以走5这个位置
if ((p1.x = curPoint.x - 2) >= 0 && (p1.y = curPoint.y - 1) >= 0) {
points.add(new Point(p1));
}
// 判断马儿可以走6这个位置
if ((p1.x = curPoint.x - 1) >= 0 && (p1.y = curPoint.y - 2) >= 0) {
points.add(new Point(p1));
}
// 判断马儿可以走7这个位置
if ((p1.x = curPoint.x + 1) < X && (p1.y = curPoint.y - 2) >= 0) {
points.add(new Point(p1));
}
// 判断马儿可以走0这个位置
if ((p1.x = curPoint.x + 2) < X && (p1.y = curPoint.y - 1) >= 0) {
points.add(new Point(p1));
}
// 判断马儿可以走1这个位置
if ((p1.x = curPoint.x + 2) < X && (p1.y = curPoint.y + 1) < Y) {
points.add(new Point(p1));
}
// 判断马儿可以走2这个位置
if ((p1.x = curPoint.x + 1) < X && (p1.y = curPoint.y + 2) < Y) {
points.add(new Point(p1));
}
// 判断马儿可以走3这个位置
if ((p1.x = curPoint.x - 1) >= 0 && (p1.y = curPoint.y + 2) < Y) {
points.add(new Point(p1));
}
// 判断马儿可以走4这个位置
if ((p1.x = curPoint.x - 2) >= 0 && (p1.y = curPoint.y + 1) < Y) {
points.add(new Point(p1));
}
return points;
}
//根据当前这一步的所有下一步的选择位置,进行非递减排序(贪心算法思想优化)
public static void sort(ArrayList<Point> points) {
points.sort(new Comparator<Point>() {
@Override
public int compare(Point o1, Point o2) {
int count1=next(o1).size();
int count2=next(o2).size();
return count1-count2;
}
});
}
}
结果:
共耗时:24 ms
1 16 37 32 3 18 47 22
38 31 2 17 48 21 4 19
15 36 49 54 33 64 23 46
30 39 60 35 50 53 20 5
61 14 55 52 63 34 45 24
40 29 62 59 56 51 6 9
13 58 27 42 11 8 25 44
28 41 12 57 26 43 10 7
可以明显看出这样优化大大提高了速度(由于改变了行走的策略,会导致走法与未优化前的不同)