李宏毅 机器学习2020 作业5 hw5-explainAI
本次作业做的是解释机器学习是如何识别一张图片的。用到了上一次CNN作业训练好的模型。
先导入需要用得到的库,其中lime需要提前安装。
我在安装的时候,conda install命令不能使用,但是使用pip命令就可以安装了。
import os
from torch.utils.data import DataLoader
import sys
import argparse
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import Adam
from torch.utils.data import Dataset
import torchvision.transforms as transforms
from skimage.segmentation import slic
from lime import lime_image
from pdb import set_trace
如果要用torch.model()来导入模型是需要这个类的定义的。
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# torch.nn.MaxPool2d(kernel_size, stride, padding)
# input 維度 [3, 128, 128]
self.cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), # [64, 128, 128]
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [64, 64, 64]
nn.Conv2d(64, 128, 3, 1, 1), # [128, 64, 64]
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [128, 32, 32]
nn.Conv2d(128, 256, 3, 1, 1), # [256, 32, 32]
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [256, 16, 16]
nn.Conv2d(256, 512, 3, 1, 1), # [512, 16, 16]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 8, 8]
nn.Conv2d(512, 512, 3, 1, 1), # [512, 8, 8]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 4, 4]
)
self.fc = nn.Sequential(
nn.Linear(512*4*4, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 11)
)
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1)
return self.fc(out)
class FoodDataset(Dataset):
def __init__(self, paths, labels, mode):
# mode: 'train' or 'eval'
#mode是train就用train的transform
#paths是每一个图片的名字
#labels是每一个图片对应的label
self.paths = paths
self.labels = labels
trainTransform = transforms.Compose([
transforms.Resize(size=(128, 128)),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15),
transforms.ToTensor(),
])
evalTransform = transforms.Compose([
transforms.Resize(size=(128, 128)),
transforms.ToTensor(),
])
self.transform = trainTransform if mode == 'train' else evalTransform
def __len__(self):
return len(self.paths)
def __getitem__(self, index):
X = Image.open(self.paths[index])
X = self.transform(X)
Y = self.labels[index]
return X, Y
#这个函数是为了方便的取出指定index的图片
def getbatch(self, indices):
images = []
labels = []
for index in indices:
image, label = self.__getitem__(index)
images.append(image)
labels.append(label)
return torch.stack(images), torch.tensor(labels)
# 给一个文件夹的名字,可以返回他下面图片的名字和labels的名字
def get_paths_labels(path):
imgnames = os.listdir(path)
imgnames.sort()
imgpaths = []
labels = []
for name in imgnames:
imgpaths.append(os.path.join(path, name))
labels.append(int(name.split('_')[0]))
return imgpaths, labels
train_paths, train_labels = get_paths_labels('./food-11/training')
train_set = FoodDataset(train_paths, train_labels, mode='train')
val_paths, val_labels = get_paths_labels('./food-11/validation')
val_set = FoodDataset(val_paths, val_labels, mode='eval')
batch_size = 128
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False)
这个是训练这个model的函数,为了完整放上来,如果你用自己的model 可以直接跳过看下面。
#暂不运行
model = Classifier()
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
num_epoch = 5
loss_all=[]
val_loss_all=[]
acc_all=[]
val_acc_all=[]
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
model.train() # 確保 model 是在 train model (開啟 Dropout 等...)
for i, data in enumerate(train_loader):
optimizer.zero_grad() # 用 optimizer 將 model 參數的 gradient 歸零
train_pred = model(data[0]) # 利用 model 得到預測的機率分佈 這邊實際上就是去呼叫 model 的 forward 函數
batch_loss = loss(train_pred, data[1]) # 計算 loss (注意 prediction 跟 label 必須同時在 CPU 或是 GPU 上)
batch_loss.backward() # 利用 back propagation 算出每個參數的 gradient
optimizer.step() # 以 optimizer 用 gradient 更新參數值
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()
model.eval()
#一个数据集训练结束
loss_all.append(train_loss/train_set.__len__())
acc_all.append(train_acc/train_set.__len__())
with torch.no_grad():
for i, data in enumerate(val_loader):
val_pred = model(data[0])
batch_loss = loss(val_pred, data[1])
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
val_loss += batch_loss.item()
#將結果 print 出來
val_loss_all.append(val_loss/val_set.__len__())
val_acc_all.append(val_acc/val_set.__len__())
print('epoch:',epoch+1, ', train acc:', '{:.2f}'.format(train_acc/train_set.__len__()),', val acc:','{:.2f}'.format(val_acc/val_set.__len__()))
加载训练好的model
model=torch.load('ckpt2.model')
可以测试一下 看看model可以用吗
model.eval()
for i, data in enumerate(train_loader):
pred = model(data[0])
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
print(val_acc/train_set.__len__())
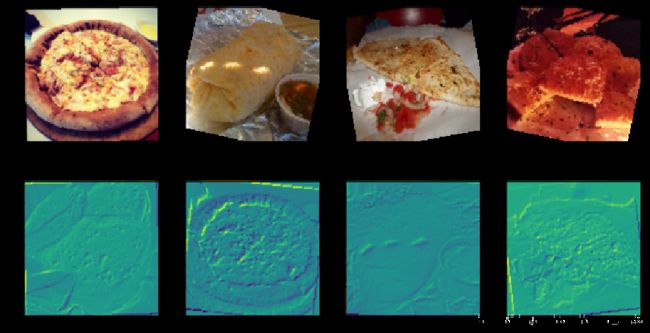
开始计算laliencies map
就是计算输出对一张image的梯度,如果一个像素的梯度高,说明他会对结果产生比较大的影响。
normalize函数可以防止产生一张黑乎乎的图片,什么也看不清
def normalize(image):
return (image - image.min()) / (image.max() - image.min())
model.eval()
img_indices=[1,2,3,4]
x, y= train_set.getbatch(img_indices)
x.requires_grad_()
y_pred=model(x)
loss_func = torch.nn.CrossEntropyLoss()
loss=loss_func(y_pred,y)
loss.backward()
saliencies = x.grad.abs().detach().cpu()
saliencies = torch.stack([normalize(item) for item in saliencies])
x=x.detach()
fig, axs = plt.subplots(2, len(img_indices), figsize=(15, 8))
for row, target in enumerate([x, saliencies]):
for column, img in enumerate(target):
axs[row][column].imshow(img.permute(1, 2, 0).numpy())
#matplolib 的最后一维是图片的三个通道,但是pytorch中我们的X数据第一维是,所以转换一下维度才能打印正常
plt.show()
plt.close()
这个model我训练的不是特别好
换一个训练的稍微好一点的model

可以看到披萨的范围更圆形了,更贴合披萨的形状。之前很方
画出来某一层的某filter卷积出来的图片
第一层
model=torch.load('ckpt_best.model')
model.eval()
cnnid=0
filterid=0
img_indices=[0,1,2,3]
x, y=train_set.getbatch(img_indices)
model.eval()
def hook(model,input,output):
global layer_activations
layer_activations=output
hook_handle = model.cnn[cnnid].register_forward_hook(hook)
model(x)
x=x.detach()
filter_activations=layer_activations[:, filterid, :, :].detach()
hook_handle.remove()
fig, axs = plt.subplots(2, len(img_indices), figsize=(15, 8))
for i, img in enumerate(images):
axs[0][i].imshow(img.permute(1, 2, 0))
for i, img in enumerate(filter_activations):
axs[1][i].imshow(normalize(img))
plt.show()
plt.close()
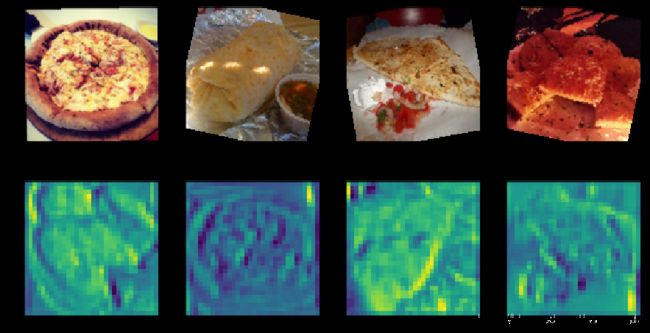
第一个卷积层的第一个filter画出来的图像
layer_activations.size()
torch.Size([4, 64, 128, 128])
一共取了4个图片,有64个filter,输出的图片是128*128的
画一池化以后的输出
model=torch.load('ckpt_best.model')
model.eval()
cnnid=3
filterid=0
img_indices=[0,1,2,3]
x, y=train_set.getbatch(img_indices)
model.eval()
def hook(model,input,output):
global layer_activations
layer_activations=output
hook_handle = model.cnn[cnnid].register_forward_hook(hook)
model(x)
x=x.detach()
filter_activations=layer_activations[:, filterid, :, :].detach()
hook_handle.remove()
fig, axs = plt.subplots(2, len(img_indices), figsize=(15, 8))
for i, img in enumerate(images):
axs[0][i].imshow(img.permute(1, 2, 0))
for i, img in enumerate(filter_activations):
axs[1][i].imshow(normalize(img))
plt.show()
plt.close()
layer_activations.size() #池化以后变小了
torch.Size([4, 64, 64, 64])
画一个第二层卷积后的输出
model=torch.load('ckpt_best.model')
model.eval()
cnnid=4
filterid=0
img_indices=[0,1,2,3]
x, y=train_set.getbatch(img_indices)
model.eval()
def hook(model,input,output):
global layer_activations
layer_activations=output
hook_handle = model.cnn[cnnid].register_forward_hook(hook)
model(x)
x=x.detach()
filter_activations=layer_activations[:, filterid, :, :].detach()
hook_handle.remove()
fig, axs = plt.subplots(2, len(img_indices), figsize=(15, 8))
for i, img in enumerate(images):
axs[0][i].imshow(img.permute(1, 2, 0))
for i, img in enumerate(filter_activations):
axs[1][i].imshow(normalize(img))
plt.show()
plt.close()

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w53mRviK-1593768185002)(output_36_0.png)]
第三层
model=torch.load('ckpt_best.model')
model.eval()
cnnid=8
filterid=0
img_indices=[0,1,2,3]
x, y=train_set.getbatch(img_indices)
model.eval()
def hook(model,input,output):
global layer_activations
layer_activations=output
hook_handle = model.cnn[cnnid].register_forward_hook(hook)
model(x)
x=x.detach()
filter_activations=layer_activations[:, filterid, :, :].detach()
hook_handle.remove()
fig, axs = plt.subplots(2, len(img_indices), figsize=(15, 8))
for i, img in enumerate(images):
axs[0][i].imshow(img.permute(1, 2, 0))
for i, img in enumerate(filter_activations):
axs[1][i].imshow(normalize(img))
plt.show()
plt.close()

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z2nZX7wm-1593768185002)(output_38_0.png)]
第四层
model=torch.load('ckpt_best.model')
model.eval()
cnnid=12
filterid=0
img_indices=[0,1,2,3]
x, y=train_set.getbatch(img_indices)
model.eval()
def hook(model,input,output):
global layer_activations
layer_activations=output
hook_handle = model.cnn[cnnid].register_forward_hook(hook)
model(x)
x=x.detach()
filter_activations=layer_activations[:, filterid, :, :].detach()
hook_handle.remove()
fig, axs = plt.subplots(2, len(img_indices), figsize=(15, 8))
for i, img in enumerate(images):
axs[0][i].imshow(img.permute(1, 2, 0))
for i, img in enumerate(filter_activations):
axs[1][i].imshow(normalize(img))
plt.show()
plt.close()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bJjZKthv-1593768185003)(output_40_0.png)]
第5层
model=torch.load('ckpt_best.model')
model.eval()
cnnid=16
filterid=0
img_indices=[0,1,2,3]
x, y=train_set.getbatch(img_indices)
model.eval()
def hook(model,input,output):
global layer_activations
layer_activations=output
hook_handle = model.cnn[cnnid].register_forward_hook(hook)
model(x)
x=x.detach()
filter_activations=layer_activations[:, filterid, :, :].detach()
hook_handle.remove()
fig, axs = plt.subplots(2, len(img_indices), figsize=(15, 8))
for i, img in enumerate(images):
axs[0][i].imshow(img.permute(1, 2, 0))
for i, img in enumerate(filter_activations):
axs[1][i].imshow(normalize(img))
plt.show()
plt.close()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AiAbCVt7-1593768185005)(output_44_0.png)]
layer_activations.size(),layer_activations[:,0,].size()
现在来看看什么样的input可以最大化的激活某一个filter
model=torch.load('ckpt_best.model')
model.eval()
cnnid=0
filterid=0
img_indices=[0,1,2,3]
x, y=train_set.getbatch(img_indices)
model.eval()
def hook(model,input,output):
global layer_activations
layer_activations=output
hook_handle = model.cnn[cnnid].register_forward_hook(hook)
model(x)
x=x.detach()
filter_activations=layer_activations[:, filterid, :, :].detach()
#torch.Size([4, 128, 128]))
x.requires_grad_()
optimizer = Adam([x], lr=1)
for iter in range(100):
optimizer.zero_grad()
model(x)
objective = -layer_activations[:, filterid, :, :].sum()
objective.backward()
optimizer.step()
filter_visualization = x.detach().cpu().squeeze()[0]
#torch.Size([4, 3, 128, 128])只取第一张
hook_handle.remove()
plt.imshow(normalize(filter_visualization.permute(1, 2, 0)))
plt.show()
plt.close()
训练的好一点的model的结果:

训练的很差的model的结果

是取出layer_activations的某一个filter输出的四个图片,(我这里样本去了4个),把他们直接加起来,和就是objective 。然后反向传播计算梯度以后更新X的值。
layer_activations[:, filterid, :, :].sum()
tensor(19903.7070, grad_fn=)
最后的filter_visualization 只取X的第一张图片
LIME计算哪一个分片是重要的影响
def predict(input):
# input: numpy array, (batches, height, width, channels)
model.eval()
input = torch.FloatTensor(input).permute(0, 3, 1, 2)
# 需要先將 input 轉成 pytorch tensor,且符合 pytorch 習慣的 dimension 定義
# 也就是 (batches, channels, height, width)
output = model(input)
return output.detach().cpu().numpy()
def segmentation(input):
# 利用 skimage 提供的 segmentation 將圖片分成 100 塊
return slic(input, n_segments=100, compactness=1, sigma=1)
img_indices = [0,1,2,3]
images, labels = train_set.getbatch(img_indices)
fig, axs = plt.subplots(1, 4, figsize=(15, 8))
np.random.seed(16)
# 讓實驗 reproducible
for idx, (image, label) in enumerate(zip(images.permute(0, 2, 3, 1).numpy(), labels)):
x = image.astype(np.double)
# lime 這個套件要吃 numpy array
explainer = lime_image.LimeImageExplainer()
explaination = explainer.explain_instance(image=x, classifier_fn=predict, segmentation_fn=segmentation)
# 基本上只要提供給 lime explainer 兩個關鍵的 function,事情就結束了
# classifier_fn 定義圖片如何經過 model 得到 prediction
# segmentation_fn 定義如何把圖片做 segmentation
# doc: https://lime-ml.readthedocs.io/en/latest/lime.html?highlight=explain_instance#lime.lime_image.LimeImageExplainer.explain_instance
lime_img, mask = explaination.get_image_and_mask(
label=label.item(),
positive_only=False,
hide_rest=False,
num_features=11,
min_weight=0.05
)
# 把 explainer 解釋的結果轉成圖片
# doc: https://lime-ml.readthedocs.io/en/latest/lime.html?highlight=get_image_and_mask#lime.lime_image.ImageExplanation.get_image_and_mask
axs[idx].imshow(lime_img)
plt.show()
plt.close()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gCgvmnGQ-1593768185010)(output_53_1.png)]
```python
