异常检测/离群点检测算法汇总
不存在普遍意义上的最优模型,不过有些模型的表现一直不错,建议优先考虑。对于大数据量和高纬度的数据集,Isolation Forest算法的表现比较好。小数据集上,简单算法KNN和MCD的表现不错。
模型效果和效率往往是对立的,PCA和MCD的理论类似(都是基于协方差),但是前者是后者的“简洁版”,前者速度更快,但是后者效果更好。
HBOS的计算速度快,但效果不稳定,在特征独立的情况下,可能有奇效。
参考:https://www.zhihu.com/question/280696035
本文基于outlier detection离群点检测 python库对各种离群点检测算法(异常检测)进行汇总,并基于这个开源库的代码,对代码内容,如参数做一个讲解。该库对应的算法讲解和链接。

1.基于线性模型的算法:PCA,MCD,OCSVM
2.基于相似性的算法:LOF, CBLOF, LOCI, HBOS, kNN
3.基于概率的算法:ABOD,FastABOD,SOS
4.基于集群的算法(集成): Iforest, Feature Bagging, LSCP, XGBOD
5.基于神经网络的算法:AutoEncoder,SO_GAAL,MO_GAAL
•异常种类
1.数据点异常:离群点,异常数据的特征值与正常数据的特征值距离较远。如车在某个时间点的速度、加速度、扭矩、发动机转速、转角加速度等离群距离和超过阈值,则为异常点。
2.上下文异常:时间序列里的异常,该数据本身是正常数据,但在对应的上下文里出现时则是异常数据。如开车门信号在车速为30km/h情况下是异常信号。
•异常点检测的难点
1.数据没有标签,不知道哪些是异常数据哪些是正常数据;或者缺乏异常数据。
2.难以划分异常和正常的边界,正常数据在某些特定场景下也可能是异常数据。
3.数据本身可能存在噪声,导致噪声和异常难以区分。
•异常点检测算法种类
1.无监督算法:数据无标签且正常信号和异常信号混合在一起,适用于异常点是低密度的离群点情况。不属于高密度区域的点被认为是异常点。
2.半监督算法:数据只含有正常信号,离训练数据距离超过一定阈值的点被认为是异常点,即使这些异常点能形成一个高密度区域。
3.监督算法:适用于有正常信号和异常信号,且数据有标签的情况。
1. 基于线性模型的方法
1.1 PCA
PCA主成分分析
PCA用于异常检测
PCA是最常见的一种降维方法,它本质上将方差最大的方向(或基于最小投影距离,即样本点投影超平面的距离足够近)作为主要特征,并在各个正交方向上将数据“离相关”。
如下图,PCA也可以类比成神经网络AutoEncoder模型的形式(来自李宏毅PPT),与神经网络不同的是,PCA都是线性变换,即没有激活函数。

异常检测两种思路:
1. 将数据映射到低维特征空间,然后在特征空间不同维度上查看每个数据点跟其它数据的偏差。

2. 将数据映射到低维特征空间,然后由低维特征空间重新映射回原空间,尝试用低维特征重构原始数据,看重构误差的大小。如果一个样本不容易被重构出来,表示这个样本的特征跟整体数据样本的特征不一致,即是异常样本。
参数
这里的PCA基于sklearn的PCA进行了封装,保留了所有的原始参数,并添加了些新参数。
n_components:PCA保留的主成分(特征)数量
n_selected_components(新): 在保留下来的主成分中被选用计算score的主成分的数量,取值None时=n_components。
contamination(新):(0,0.5)中的一个float,default=0.1,数据集中离群点的比例,训练时候使用
copy:True/False,True时在复制的副本上进行计算,不会影响原数据;False时,训练过程中训练数据会被降维修改。
whiten:对数据白化与否
svd_solver:指定奇异值分解SVD的方法。
weighted:default=True,在score计算上使用特征值
PCA对象属性
1.2 OCSVM
OCSVM一类支持向量机
OCSVM和SVDD的比较

 目标函数
目标函数
OCSVM使用于只有正常数据的场景。找到一个参数为w和ρ的超平面分割数据点和原点,超平面离原点距离越大越好,原点在这里被认作是唯一的异常点。
SVDD的思路和OCSVM类似,找到一个“球面”,将所有数据点包含在里面,寻找使“球体”体积最小的中心点a和球体积R^2。

2. 基于距离的方法
2.1 LOF(Local Outlier Factor)
异常点/离群点检测算法——LOF
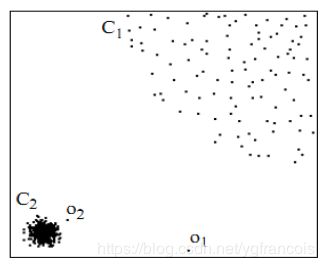
LOF思想:
通过比较每个点p和其邻域点的密度来判断该点是否为异常点,如果点p的密度越低,越可能被认定是异常点。
密度通过点之间的距离来计算的,点之间距离越远,密度越低,距离越近,密度越高。

2.2 CBLOF(Cluster-Based Local Outlier Factor基于聚类+距离)
2.3 KNN


K近邻距离有多种设置:
1.距离第k近的点的距离
2.距离最近的k个点的平均距离
3.距离最近的k个点中的中间距离
基于集成的方法:Isolation Forest孤立森林

 思路:很快被划分到叶子节点的大概率是异常
思路:很快被划分到叶子节点的大概率是异常
算法步骤:
1. 从训练数据中随机选择Ψ个点样本点作为subsample,放入树的根节点。
2. 随机指定一个维度(attribute),在当前节点数据中随机产生一个切割点p——切割点产生于当前节点数据中指定维度的最大值和最小值之间。
3. 以此切割点生成了一个超平面,然后将当前节点数据空间划分为2个子空间:把指定维度里小于p的数据放在当前节点的左孩子,把大于等于p的数据放在当前节点的右孩子。
4. 在孩子节点中递归步骤2和3,不断构造新的孩子节点,直到 孩子节点中只有一个数据(无法再继续切割) 或 孩子节点已到达限定高度 。
预测:
对于一个数据样本x,我们将其传入所有的树中,计算x所处的叶子节点的高度平均值,设置一个阈值,高度不够的视为异常。
特点:
•适用于特征值是连续值的任务
•Non-parametric和unsupervised的算法
•由于每次切割是随机的,所以需要用Ensemble的方法来获得收敛值,即需要用多棵二叉树
基于神经网络的算法(准确来说是基于自编码器或生成对抗网络的算法)
基于autoencoder和GAN网络的算法思路和PCA类比的方法一样,先用encoder对数据编码(也相当于一个降维),再使用decoder解码,比较和原始数据的差距。模型训练的方向是越近似原始数据越好。对于异常数据,生成出的结果一般和原始数据差距较大。设置一个合适的阈值即可。
Fully connected AutoEncoder
 Outlier Score: Reconstruction Error
Outlier Score: Reconstruction Error
SO_GAAL,MO_GAAL 论文:https://arxiv.org/pdf/1809.10816.pdf
原因:有限的异常数据难以提供足够的信息用于划分异常边界。
思路:使用GAN的思想,用Generator生成潜在离群点(异常数据),将噪声和真实数据合在一起,让Discriminator分辨出噪声和真实数据,最后使用Discriminator作为异常检测分类器


SO_GAAL的ROC在iteration=400左右时急速下降,原因是G和D达到了纳什平衡,再往下训练,G会出现mode collapse问题,即生成出的噪声多样性不够,总是生成某种mode的异常点,对于D来说,虽然仍然能够区分real和fake,但是fake提供的信息有限,所以在测试时,D用作outlier detector的性能就会下降。

为了解决一个G可能只能模拟一个mode的问题,
MO_GAAL中创建了k个Generator,将Real data根据D(x)的结果分成k份subsets,G的target设置D(G(x))获得的分数的中位数(每个subset不同),generator_loss为这k个loss的平均数。

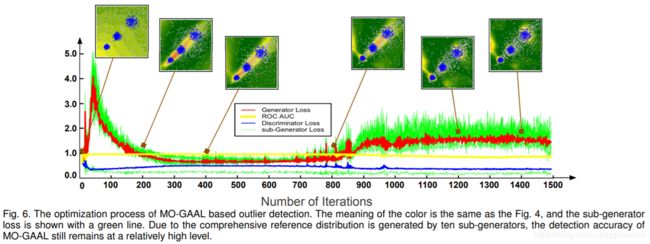
虽然整个模型还是会达到nash平衡,但是ROC不再下降,因为多个generator估计了多个不同的mode分布
总结
1.LOF类的算法适用于局部区域空间问题,对于完整区域空间,KNN和Iforest更好。
2.KNN每次运行需要遍历所有数据,所以效率比较低,如果效率要求比较高,用聚类方法更好。
3.传统机器学习算法中Iforest、KNN和OCSVM表现较好,基于深度学习的算法准确率在论文中更好!
4.对于不同种类的数据,没有哪一种算法是最好的,HBOS算法在某些数据集上的表现非常好,且运算速度很快。
5.当数据特征数很多时,如400个特征,只有KNN表现还不错,Iforest表现也不好,因为特征选取的随机性,可能无法覆盖足够多的特征(不绝对)。
6.ABOD综合效果最差,尽量不要用。