Scrapy实战:爬取知乎用户信息
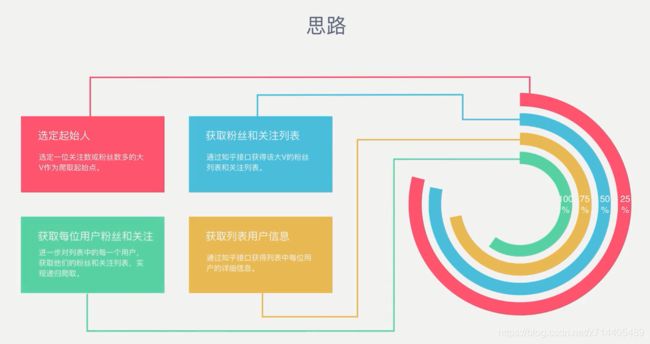
思路:从一个用户(本例为“张佳玮”)出发,来爬取其粉丝,进而爬取其粉丝的粉丝…
先来观察网页结构:

审查元素:

可以看到用户“关注的人”等信息在网页中用json格式保存在data中。
当把鼠标移到列表中的某个名字上时,可以看到浏览器产生了一个Ajax请求:
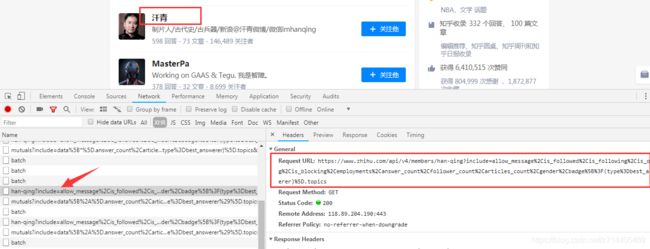
请求的url后面加上了很长的一串查询字符串。
并且json中也请求了许多详细的信息。

这与该用户的主页基本是对应的:
实战
我们先在命令行中新建一个项目:
scrapy startproject zhihuuser
然后直接在pycharm中打开,接着在settings里面找到OBOTSTXT_OBEY = True把它修改为false:
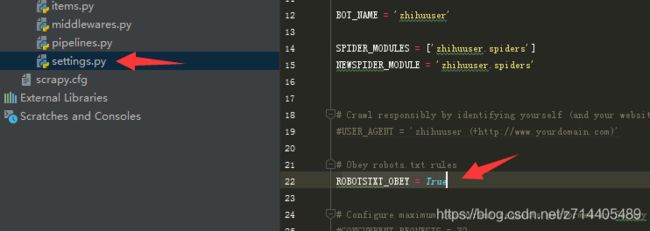
这样做的目的是我们不遵循tobots协议,以免在访问某些网址时失效。
接下来创建一个zhihu的spider:
scrapy genspider zhihu www.zhihu.com
然后直接运行,发现状态码为400:

这是因为知乎加了user-agent识别,如果请求不是从浏览器发出那么就会返回非正常的状态码。
我们在settings中将DEFAULT_REQUEST_HEADERS解除注释并加上user-agent:
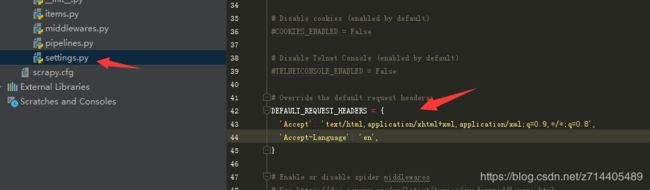

这是再运行爬虫返回的就是200状态码了。
接下来修改爬虫代码,完成“初始请求”的实现。
初始请求
先试验一下根据两个接口是否能返回正确的信息,一个是个人信息的接口,一个是关注列表
我们把某个用户的个人信息的url贴过来:
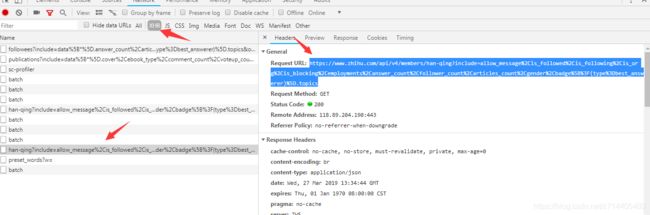
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Spider,Request
class ZhihuSpider(scrapy.Spider):
name = 'zhihu'
allowed_domains = ['www.zhihu.com']
start_urls = ['http://www.zhihu.com/']
def start_requests(self):
url = 'https://www.zhihu.com/api/v4/members/han-qing?include=allow_message%2Cis_followed%2Cis_following%2Cis_org%2Cis_blocking%2Cemployments%2Canswer_count%2Cfollower_count%2Carticles_count%2Cgender%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics'
yield Request(url, callback=self.parse)
def parse(self, response):
print(response.text)
运行,可以看到打印出来的是一个列表。
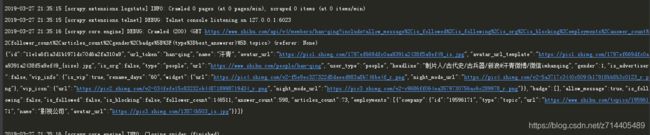
我们再把url换成该用户的关注列表:

用这个url替换上面的那个再次试验:
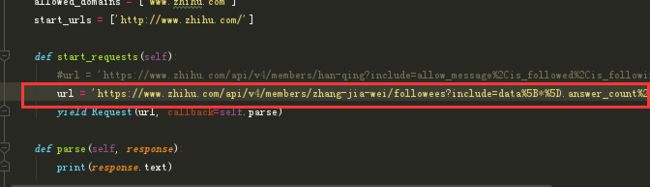

这回打印的是json格式。这说明以上两个接口(用户详细信息,用户关注信息)都能被爬虫正常请求。
持续请求
接下来进行完善,我们需要对url进行改写,

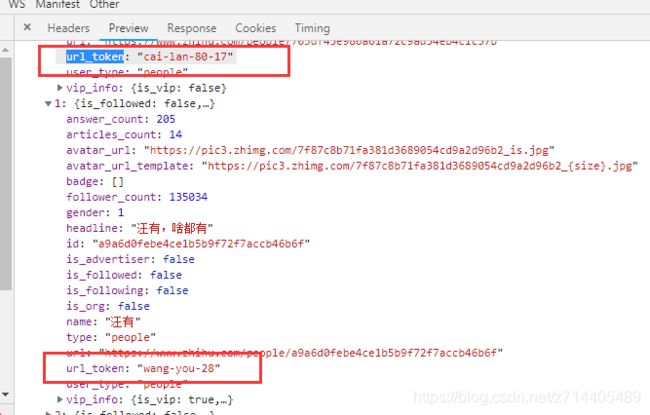
如图,url的limit表示返回的信息数量为20个,offset表示偏移值(,若limit为20,60就是第4页,通过这两个变量可以完成分页的操作),现在我们要做的是动态构造url,把其中的变量替换一下就好了。

在每个用户信息页面有一个url_token,我们可以将这个设为变量,在关注列表里面获取这个token然后组成新的url,形成一个递归的关系:
现在我们改写user_url:
user_url = 'https://www.zhihu.com/api/v4/members/{user}?include={include}'
将url_token作为变量“user”,查询语句作为变量“incluede”,也就是下面的user_query,可以到审查中复制:

user_query = 'allow_message,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics'

然后是关注列表的url,类似,只是后面加上了offset和limit参数:
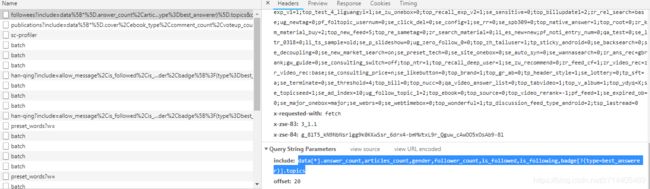
follows_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}'
follows_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics'
接下来编写start_requests方法使其构造两个初始访问的url:
def start_requests(self):
yield Request(self.user_url.format(user=self.start_user,include=self.user_query) ,callback=self.parse_user)
yield Request(self.follows_url.format(user=self.start_user,include=self.follows_query, offset=0, limit=20),callback=self.parse_follows)
再定义两个解析方法以使回调函数调用:
#解析用户信息
def parse_user(self, response):
print(response.text)
#解析关注列表
def parse_follows(self, response):
print(response.text)
定义一个起始token:start_user = 'zhang-jia-wei'
运行爬虫,可以看到打印出了许多json信息,说明以上两个url可以正常请求。
下面,在items.py中定义我们需要从页面中存储的信息。
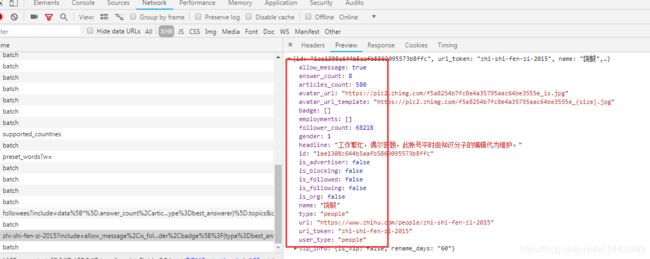
从用户信息界面可以看到有许多的属性,我们把它们复制下来并添加到items中:
from scrapy import Item ,Field
class UserItem(Item):
id = Field()
name = Field()
allow_message = Field()
answer_count = Field()
articles_count = Field()
avatar_url = Field()
avatar_url_template = Field()
badge = Field()
employments = Field()
follower_count = Field()
gender = Field()
headline = Field()
type = Field()
url = Field()
url_token = Field()
user_type = Field()
然后修改parse_user方法,用来生成用户信息的item
#解析用户信息
def parse_user(self, response):
result = json.loads(response.text)#生成一个json对象
item = UserItem()
for field in item.fields:
if field in result.keys():#如果field是键名的其中之一
item[field] = result.get(field)
yield item
接下来考虑关注列表

paging这个列表里是一些用来分页的信息,其中is_end用来标识是否为最后一页(如上图例子所示),此外,next属性中的值即为下一页的url,但是无法直接用来请求,对比上面提到的follows_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}',这个next中的url少了api/v4/,所以我们提取出来后还要进行拼接处理,这样的url才能正常发起request。
那么可以编写解析关注列表的方法,这个方法完成了两件事,第一是从列表中拿到每个关注人的url_token,进而可以解析这些用户的个人信息;第二是获取下一页的关注列表,进而继续解析,直到访问了“张佳玮”的所有关注人。
这部分的代码如下:
#解析关注列表
def parse_follows(self, response):
results = json.loads(response.text)
# 解析follows列表,重点是拿到url_token
if 'data'in results.keys():
for result in results.get('data'):
yield Request(self.user_url.format(user=result.get('url_token'), include=self.user_query),callback=self.parse_user)
# 请求下一页
if 'paging' in results.keys() and results.get('paging').get('is_end') == False:
next_page = results.get('paging').get('next')
next_page='https://www.zhihu.com/api/v4%s' % (next_page[21:]) #拼接,形成有效的url
yield Request(next_page, self.parse_follows)
运行爬虫,就可以把“张佳玮”的所有关注者的信息爬取到了。
接下来继续修改parse_user,当请求到某用户的信息时,继续请求该用户的关注列表,这样才能实现一个层层递归的效果。
def parse_user(self, response):
result = json.loads(response.text)#生成一个json对象
item = UserItem()
for field in item.fields:
if field in result.keys():#如果field是键名的其中之一
item[field] = result.get(field)
yield item
yield Request(self.follows_url.format(user=result.get('url_token'),include=self.follows_query,limit=20,offset=0),callback=self.parse_follows)
这样一来就可以从一个用户出发,到其关注列表,再从这个列表其中的用户,再请求该用户的关注列表,这样往复递归,从而爬取大量的用户信息。
此外,在关注列表之外,我们再加上爬取粉丝列表的功能。

与上面类似,定义一个followers_url和一个followers_query(followers_url只是改变了一个字母):
followers_url = 'https://www.zhihu.com/api/v4/members/{user}/followers?include={include}&offset={offset}&limit={limit}'
followers_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics'
然后修改parse_user,在最后添加:
yield Request(self.followers_url.format(user=result.get('url_token'),include=self.followers_query,limit=20,offset=0),callback=self.parse_followers)
既然回调函数用到了parse_followers,我们就需要定义这样一个方法,可以直接复制之前的parse_follows,然后把所有“follows”改为“followers”即可。
最后在start_requests方法中添加一个起始的对粉丝列表的请求:
yield Request(self.followers_url.format(user=self.start_user,include=self.followers_query, offset=0, limit=20),callback=self.parse_followers)
那么现在运行爬虫,就会从“张佳玮”出发,爬取他的关注和关注他的列表,再从这两个列表中的用户出发爬取各自的两个列表,这样不断递归,然后在理论上把所有用户爬取到(除了0粉丝0关注的大虾…)。
存储
现在要把爬取的数据存储到mongodb。那么需要在pipeline中定义MongoPipeline:
import pymongo
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
# 去重:查找到则进行更新,没查找到则进行插入操作
self.db['user'].update({'url_token':item['url_token']},{'$set':item},True)
return item
然后在settings中注册:
ITEM_PIPELINES = {
'zhihuuser.pipelines.MongoPipeline': 300,
}
运行爬虫,大功告成:
