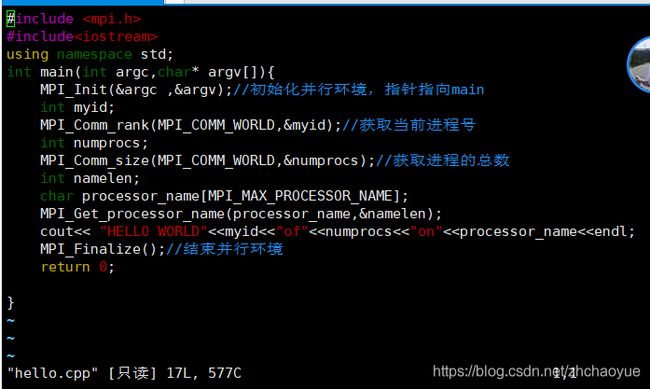
MPI并行编程函数加c++语言例子,并行输出helloworld和矩阵
MPI编程首先要创建文件,touch helloworld.cpp 用cpp当后缀就可以用c++语言编写程序
sudo vim helloworld.cpp来编写文件,或者将文件可编写权限变成其他用户可编写,就用vim hellpworld.cpp进行编写
首先MPI并行编程要引入头文件,也就是函数库
#include "mpi.h"
先讲解几个简单的函数,然后再用这几个函数写一下并行输出hellowrld
MPI_Init(&argc,&argv);这个函数的作用就是作为初始化函数,让服务器知道要做好mpi的相关初始化。传入的argc和argv指向main函数的命令行参数argc,argv的指针,这里可以看到main函数是int main (int argc,char *argv);如果没有命令行参数也可以输入NULL
知道个概念MPI_COMM_WORLD:通讯子,“一组可以互发消息的进程集合”
MPI_Comm_rank(MPI_COMM_WORLD,&procnum);第一个参数是输入参数--通信子,第二个参数是输出参数--进程号。
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);第一个参数是输入参数--通信子,第二个参数是输出参数--通信子中总进程数
MPI_Get_processor_name(pro_name,&namelen);得到当前进程的名字
MPI_Finalize();结束mpi编程,释放MPI的一些资源
mpic++ helloworld.cpp -o helloworld将cpp文件编译链接成可执行文件。
mpirun -np 5 ./helloworld 就是5线程执行文件
下面讲一下MPI最基本的两个函数,发送和接受函数
MPI_Send(void *buf,int count,MPI_Datatype,datatype,int dest,int tag,MPI_COMM_WORLD)
buf:发送缓冲区的起始地址(可选类型)
count将发送的数据个数(非负整数)
datatype发送数据的数据类型(句柄)
dest目的的进程标识号(整型)
tag消息标志(整型)
MPI_COMM_WORLD(句柄)
MPI_Recv(void *buf,int count ,MPI_Datatype,int source int tag,MPI_COMM_WORLD,MPI_Status *status)
buf 接受缓冲区的起始地址(可选类型)
count最多可接收的数据个数(非负整数)
datatype接收数据的数据类型(句柄)
source接收数据的来源进程标识号(整型)
tag消息标识与相应的发送操作的表示相匹配(整型)
MPI_COMM_WORLD本进程与发送进程所在的通信域(句柄)
*status 返回状态(状态类型)
用这两个函数写的矩阵代码
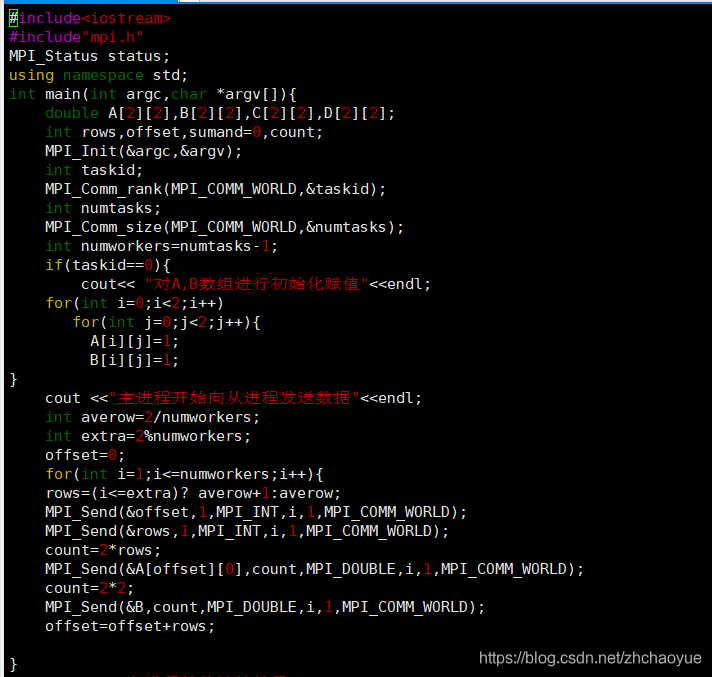
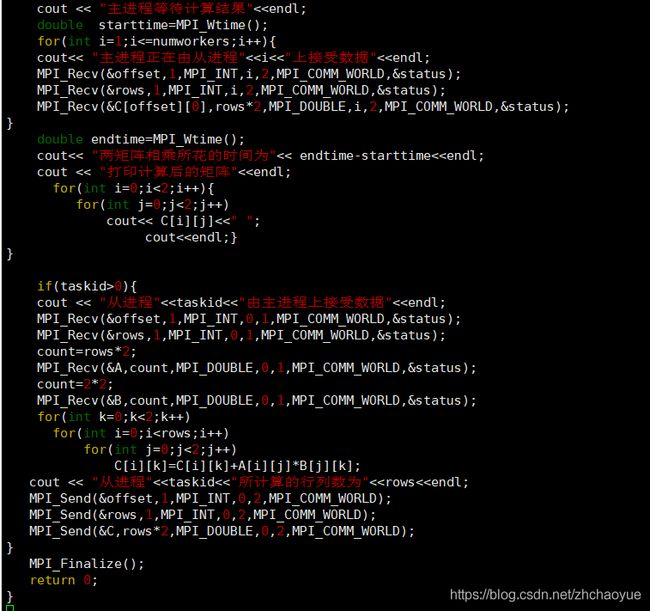
这是并行输出的矩阵点乘运算
列举几个函数
1.广播函数
int array[5];先定义数组
MPI_Bcast(&array,5,MPI_INT,source,MPI_COMM_WORLD)
缓冲区的起始地址
缓冲区中的数据个数
缓冲区的数据类型
发送信息的进程id,广播就是主进程0广播的
通信子
简介:每个从进程都会收到5组数据,就是完整的一个矩阵,收到的都是相同的。
2.MPI_Wtich()打印精度
3.MPI_Barrier(MPI_COMM_WORLD)阻止调用直到communicator中所有进程已经完成调用,就是说任意一次进程的调用只能在所有communicator中的成员已经开始调用之后进行。在计算运行时间的信息之前调用MPI_Barrier函数完成同步
4.MPI_Address(void *location,MPI_Aint *address)地址函数
void *location调用者的内存位置
MPI_Aint address1,address2;
int a=1,b=2;
MPI_Address(&a,&address1);
MPI_Address(&b,&address2);
address2-address1就是地址偏移量因为是int类型的所以是4
5.MPI的规约:我们需要对于数据做同一种操作,并将结果返回到指定的进程中,这个过程称为集合通信。例如,将数据分散到各个进程中,先在各个进程内进行求和,再在全局完成求和到平均这个过程,这个过程是一个规约的过程。
一般来说,集合通信包括通信,同步,计算三个功能。
double local_num=3.0;
double global_num;
MPI_Reduce(&local_num,&global_num,1,MPI_DOUBLE,MPI_SUM,0,MPI_COMM_WORLD)
每个进程处理的数据放在local_num中
global_num存放输出消息的内存块的地址
缓冲区中的数据个数
数据项的类型
操作子,例如加减
要接受消息的进程的进程号
通信器
MPI_MAX 最大值 MPI_SUM求和 MPI_LAND逻辑与 MPI_LOR逻辑或 MPI_LXOR逻辑异或 MPI_MAXLOC 最大值及位置 MPI_MIN最小值 MPI_PROD 求内积 MPI_BAND按位与 MPI_BOR 按位或 MPI_BXOR按位异或 MPI_MINLOC最小值及位置
如果是矩阵
int a[6][6]
int b[6][6]
MPI_Reduce(&a,&b,36,MPI_INT,MPI_SUM,0,MPI_COMM_WORLD);
这样计算的时候会每个从进程矩阵对应的位置执行相加操作,比如a矩阵全部赋值为1,5线程输出那么b矩阵就会返回6行6列全部为4的值
6.有时候我们希望在一个进程中从所有进程获取信息,例如将所有进程中的一个数组都收集到根进程做进一步的处理,这样的通信集合叫做收集
int *rbuf
rbuf=(int*)malloc(numprocs*5*sizeof(int))
MPI_Gather(&array,5,MPI_INT,rbuf,5,MPI_INT,0,MPI_COMM_WORLD)
array发送缓冲区的起始地址
发送缓冲区的数据个数
发送缓冲区的数据类型
接收缓冲区的起始地址
待接收的元素个数
接收的数据类型
接收进程id
通信子
这个函数会让根进程从所有进程接收一个数组,并在根进程中打印出来。
7.根进程向所有进程发送缓冲区的数据,称为散发
散发操作和广播操作的区别在于发送到各个进程的信息可以是不同的
MPI_Scatter(sbuf,5,MPI_INT,rbuf,5,MPI_INT,source,MPI_COMM_WORLD)
发送缓冲区的起始地址
发送的数据个数
发送缓冲区的数据类型
接收缓冲区的起始地址
待接收的元素个数
接收的数据类型
发送进程id
通信子
类似与根进程通过MPI_Send发送一条消息,这条消息被分为n等份,第i份发送给组中的第i个处理器,然后每个处理器就会收到消息
8.
打包函数先打包发送过去,然后再解包
int i,j,position;
int k[2];
int buf[1000];
int i=1,j=2;
position=0;
MPI_Pack(&i,1,MPI_INT,&buf,1000,&position,MPI_COMM_WORLD)
输入缓冲区地址
输入数据项数目
数据项的类型
输出缓冲区的地址
输出缓冲区的大小
缓冲区当前位置
通信子
MPI_Pack(&j,1,MPI_INT,&buf,1000,&position,MPI_COMM_WORLD)
MPI_Send(&buf,position,MPI_PACKED,1,99,MPI_COMM_WORLD)
发送到第一个线程,数据个数为position
MPI_Recv(&k,2,MPI_INT,0,99,MPI_COMM_WORLD,&status);
MPI_Unpack(&k,2,&position,&i,1,MPI_INT,MPI_COMM_WORLD);
MPI_Unpack(&k,2,&position,&j,1,MPI_INT,MPI_COMM_WORLD);
k表示的是输入缓冲区,输出缓冲区可以是MPI_Recv()允许的任何通信缓冲区(整型)
输入缓冲区大小(整型)
缓冲区当前位置(整型)
输出缓冲区地址
输出缓冲区大小(整型)
每个输入数据的类型
通信域
MPI_Recv()和MPI_Unpcak()的区别,在MPI_Recv()中count参数指明的是可以接收的最大项数,实际接收的项数是由接收的消息的长度来决定的。在MPI_Unpack()中count参数指明实际打包的项数;相应消息的"size"是position的增加值,这种改动的原因是“输入消息的大小”直到用户决定如何解包之前是不能预先确定的;从解包的项数来确定‘消息大小’也是很困难的