视频内容理解核心技术解密:Partial re-ID 在成片体检中的技术实践


作者 | 阿里文娱高级算法工程师 朔衣
责编 | 李雪敬
头图 | CSDN下载自视觉中国

引言
人物重拾(Person Re-identification,简称为re-ID)是一项在现实世界非常具有挑战性的任务,它旨在利用视觉算法模型匹配出不同视角的不同摄像头下的相同人物。无处不在的遮挡,复杂的背景,光照的变化等都使得这个问题困难重重。而目前大部分的开源数据集,如 Market1501,DukeMTMC 等都是在监控视频下采集的行人数据,这些数据集的人物形象大多是直立全身的固定姿态,目前的一些主流的算法模型对于这些数据集都有很好的性能优化和提升。然而,基于内容视频数据进行的人物 re-ID 的研究工作却是屈指可数。区别于传统的监控视频,内容视频中有大量的人工剪辑和镜头切换,大量多角度和多机位的镜头拍摄,这些都使得内容视频中的人物形象存在不同程度的遮挡,人体区域的丢失,角度,姿态以及大小的变化。
我们可以通过如图1的一个具体的示例看下。在图1(a)中,A 和 B 是用来描述同一场景的不同角度和机位的镜头。而镜头 A 中和镜头 B 中的人物匹配问题可以看做是一个针对全身人体和半身人体的匹配问题。在图1(b)中,镜头 A 中的人物形象具有可识别的正脸,此时,如果我们能够匹配出镜头 B 中的同一人物,那么我们最终就能识别出那些在某些镜头中仅仅只是背面或者侧面的人物角色信息。这有助于我们提高视频内容分析指标的准确性和有效性。

(a) (b)
图1 内容视频中的人物匹配
综上我们可以看出,内容视频中的 re-ID 算法要解决的一个主要问题就是遮挡或者部分人物形象的匹配,学术界通常称为 partial re-ID 或者 occluded re-ID。目前行业内对于这类问题的主要解决思路一种是通过将局部区域特征重建为全局特征来实现隐式的对齐操作,另一种则是利用人体空间区域划分,来实现相同区域特征的显式对齐操作。但是现有这些方法的问题一方面是训练数据集跟内容视频的数据差异较大,另一方面是粗粒度的空间区域划分并不能适应内容视频中复杂的人体姿态。因此,我们考虑从数据集和算法模型两个方面进行内容视频中的 re-ID 算法优化。

数据集构建
图2是开源数据集和剧集视频数据的一个对比,从图中我们发现,剧集视频中的人物姿态更加多变,分辨率较高,并且伴随着大量的遮挡或人体部分丢失,而开源数据集中的人物姿态较为固定,较多是直立全身的图像。因此,在目前的开源数据集上训练的算法模型很难直接应用于内容视频之中。基于此,我们直接构建了一个剧集场景下的大型 re-ID 数据集。

图2 数据集对比
整个数据集的构建流程主要分为以下几步:
1. 筛选剧集:根据时间和热度选取大约500部剧集,每部选择10-20集。
2. 抽帧检测:对每集视频抽帧检测,利用人体检测模型获取人体框图片。
3. 数据分组:对检测好的人体框图片,按照 show 进行分组,以减少标注工作量。
4. 数据标注:对分组的数据集进行人物ID的标注,每个 ID 大约标注30张左右。
最终得到我们剧集场景下的 Drama-ReID 数据集,整个数据集大约有1W的 ID 数,包含38W左右的图片数量。是目前行业内最大的剧集场景的 re-ID 数据集。

算法模型
我们的整体算法模型框架如图3所示。基础网络部分使用预训练的 resnet50,为了获得更大的特征图,我们会将 backbone 的最后一个卷积层的 stride 设置为1。在 backbone 之后有三个主要的模块:人体语义分割,信息熵度量模块,语义对齐匹配。整个网络结构是 end-to-end 训练。

图3 网络结构
1. 人体语义分割
不同于现有的一些算法那样对人体区域进行一个空间区域上的划分,我们利用人体语义分割进行人体语义区域的划分,如图4所示:

图4 人体语义分割
一方面,我们可以利用人体语义区域划分来实现语义级别的特征对齐,另一方面,我们可以去掉背景区域特征,防止部分复杂背景的图像对人物匹配造成影响。同时,我们也并没有像现有一些算法中那样利用一个单独的语义分割模型来提取人体语义区域,而是使用一个多任务学习的人体语义分割,它的好处一是可以减少模型的复杂度和计算量,另一个则是通过增加语义分割的监督 loss,可以有效提高基础特征的空间表征能力
2. 信息熵度量模块
多任务的人体语义分割可以帮助我们提取人体语义区域,但同时我们也需要考虑语义分割错误的情况。错误的语义分割会带来错误的特征对齐,从而导致人物匹配错误。考虑到如果某个区域的分割概率越高,这个区域被分割正确的可能性就越高,我们通过计算分割概率的信息熵来度量这种分割的不确定性。计算公式如下:
![]()
如果越小,表示模型对于这部分区域分割正确的把握就越高。通过这种方式,我们可以计算出特征图上每个点的信息熵,然后通过设定一个合适的信息熵阈值,我们将整个人体区域划分为了高熵和低熵区域。
整个的信息熵度量模块如图5所示:
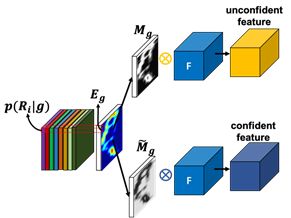
图5 信息熵度量
高熵区域是语义分割不确定性高的部分,它们可能无法被正确的划分到某个的语义区域上,我们直接提取它们的全局特征。而往往,同一个人物的高熵部分具有某种独特性(例如某个人物的特殊的帽子),这种独特少有的元素很难被分割正确,但它却是我们进行人物匹配的一个重要依据,而我们的高熵区域的全局特征就是在表征这类人物所独有的元素。
低熵区域是语义分割不确定性低的部分,它们往往是能够轻易分割正确的部分,往往跟人体的区域结构具有强关联性。我们通过一个 entropy attention map 来增强语义分割中确定性高的表征,而抑制语义分割中确定性低的表征。一方面增强了稳定的语义部件的表达,另一方面减少了错误对齐的可能。
同时,在模型训练过程中,整体的信息熵会随着分割 loss 的降低而降低。在训练的初始阶段,模型不能很好进行语义分割,导致信息熵都偏高,大部分的区域都会被划分到高熵区域,此时人物比对的特征以全局特征为主。随着训练的进行,模型的语义分割能力会提高,信息熵会降低,大部分的区域都会被划分到低熵区域,此时人物比对的特征以语义特征为主。这像是模型在特征选择上的一种自我对抗学习,在训练的过程中动态的选择高熵的全局特征和低熵的局部特征。
3. 语义对齐匹配
在获得了高熵的全局特征和低熵的语义特征之后,我们会首先根据下面的公式计算其各自的重要性分数,对于高熵区域来说,如果它所包含的人体区域特征越多,它的重要性分数会越高。而对于低熵区域来说,如果某个人体语义区域不可见,被遮挡或者不显著,则它的重要性分数会低。而语义对齐匹配的如下图所示:

图6 语义对齐匹配
根据各自的重要性分数和其对应的特征比对距离,可以计算最终人物匹配的整体距离。

此时,我们就实现了人体区域的动态对齐匹配。

结果分析
我们在开源数据集上进行了我们的模型一些 SOTA 模型的效果对比,结果如下:

图7 Holistic 数据集对比

图8 Partial 数据集对比
图7是全身数据集上的对比结果,图8是 Partial 数据集的对比结果。
同时我们也在构建的 Drama-ReID数 据集上进行了测试对比,结果如下:
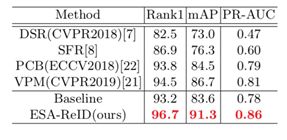
图9 Drama数据集对比

成片体检应用案例
通过加入 Partial re-ID 特征我们可以获取更加准全的视频人物数据,这些数据目前主要应用于成片体检中各项指标的计算,例如人物出镜,人物交互,故事线等, 同时我们可以根据以上这些指标对视频内容进行量化的剪辑优化或者内容评估。以下是《冰糖炖雪梨》的一些 case 应用。

图10 角色出镜率

图11 故事线分布
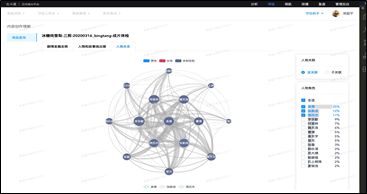
图12 角色社交网络关系


更多精彩推荐
☞去世这天是她的生日,全球首位女性图灵奖得主 Frances Allen 的传奇人生
☞华为云 GaussDB 数据库,会是新的国产之光吗?
☞小米十年,雷军的一往无前
☞用Bi-GRU语义解析,实现中文人物关系分析
☞CPU:别再拿我当搬砖工!
☞DeFi升空助推器:收益耕作者「Yield Farming」
点分享点点赞点在看