k8s集群监控组件容器化部署prometheus+grafana+node-exporter
环境准备
单节点k8s集群
| 节点 | IP地址 | 版本信息 |
|---|---|---|
| master | 192.168.1.4 | k8s=v1.17.1、docker=v19.03 |
| node | 192.168.1.5 | k8s=v1.17.1、docker=v19.03 |
镜像文件准备
prom/prometheus:v2.19.1
grafana/grafana:7.0.5
prom/node-exporter:v2.0.0
镜像tar包百度网盘分享:
链接:https://pan.baidu.com/s/1xZs-jbBUdG1EJ4rBqHwI_Q
提取码:2hoq
部署node-exporter
部署前创建monitoring名称空间
kubectl create namespace monitoring
node-exporter组件采用ds方式部署
node-exporter-ds.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitoring
labels:
app: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
containers:
- image: prom/node-exporter:v2.0.0
name: node-exporter
ports:
- containerPort: 9100
hostNetwork: true
tolerations:
- operator: Exists
node-exporter-svc.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: node-exporter
name: node-exporter
namespace: monitoring
spec:
clusterIP: None
ports:
- name: metrics
port: 9100
protocol: TCP
targetPort: 9100
type: ClusterIP
selector:
app: node-exporter
创建ds和svc
kubectl create -f node-exporter-ds.yaml
kubectl create -f node-exporter-svc.yaml
部署prometheus组件
我这里创建了个/tsdb目录本地存储prometheus和grafana数据
mkdir /tsdb
prometheus-clusterrole.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
prometheus-sa.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitoring
prometheus-clusterrolebinding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitoring
kubectl create -f prometheus-clusterrole.yaml
kubectl create -f prometheus-sa.yaml
kubectl create -f prometheus-clusterrolebinding.yaml
采用configmap方式管理prometheus组件的配置文件
confimap可以配置想要采集的数据
global:
#全局配置
scrape_interval: 30s
#默认抓取周期,可用单位ms、smhdwy 默认值为1m
scrape_timeout: 30s
#默认抓取超时 默认值为10s
evaluation_interval: 1m
#估算规则的默认周期默认为1m
scrape_configs:
#抓取配置列表,及定义收集规则
- job_name: 'prometheus'
static_configs: #静态配置参数
- targets: {'localhost:9090'} #指定抓取对象IP+端口 未配置metrics_path访问路径都默认为/metrics
#prometheus会定期的从targets中拉取时序数据存储到本地的时序数据库TSDB中
- job_name: "kubernetes-pods"
kubernetes_sd_configs:
- role: pod
#kubernetes_sd_configs是以角色(role)来定义收集的,可配置node、pod、endpoints、ingress等
# api_server:
# basic_auth: XXX
# tls_config: XXX
relabel_configs:
#允许在抓取之前对任何目标及其标签进行修改 标签修改规则
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_namespace]
#pod所在的namespaces
action: replace #更换__meta_kubernetes_namespace为kubernetes_namespace显示
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
#资源标签pod名称
action: replace #更换pod名称__meta_kubernetes_pod_name为kubernetes_pod_name显示
target_label: kubernetes_pod_name
- job_name: 'kube-controller-manager'
scrape_interval: 1m
scrape_timeout: 1m
metrics_path: "/metrics"
static_configs:
- targets: ['192.168.1.4:10252']
- job_name: 'kube-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_test_io_must_be_scraped]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_test_io_metrics_path]
action: replace
target_label: __metrics_path
regex: (.+)
- source_labels: [__meta_kubernetes_service_annotation_test_io_scrape_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespaces
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- source_labels: [__meta_kubernetes_pod_host_ip]
action: replace
target_label: host_ip
- job_name: 'kube-etcd'
scheme: https
tls_config:
ca_file: /etc/kubernetes/pki/etcd/ca.crt
cert_file: /etc/kubernetes/pki/etcd/peer.crt
key_file: /etc/kubernetes/pki/etcd/peer.key
static_configs:
- targets: ['192.168.1.4:2379']
prometheus采用deployment方式部署
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
app: prometheus
name: prometheus
namespace: monitoring
spec:
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
hostNetwork: true
nodeSelector:
monitoring: prometheus
tolerations:
- operator: Exists
containers:
- image: prom/prometheus:v2.19.1
name: prometheus
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--storage.tsdb.retention=24h"
ports:
- containerPort: 9090
hostPort: 9090
protocol: TCP
volumeMounts:
- mountPath: "/prometheus"
name: prometheus-data
- mountPath: "/etc/prometheus"
name: prometheus-config-volume
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 500m
memory: 2500Mi
serviceAccountName: prometheus
volumes:
- hostPath:
path: /tsdb/prometheus
type: DirectoryOrCreate
name: prometheus-data
- configMap:
defaultMode: 420
name: prometheus-server-conf
name: prometheus-config-volume
创建prometheus-svc.yaml
kind: Service
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus
namespace: monitoring
spec:
type: ClusterIP
ports:
- port: 9090
protocol: TCP
targetPort: 9090
selector:
app: prometheus
部署keepalived+haproxy采用vip代理后端两个prometheus服务实现高可用
yum install -y keepalived
yum install -y haproxy
keepalived配置文件解析
master主机配置 vi /etc/keepalived/keepalived.conf
----------------
global_defs{ #全局配置
lvs_id haproxy_DH
}
vrrp_script check_haproxy { #定义用于实例执行的脚本内容 可以设置优先级来强制切换
script "killall -0 haproxy"#向haproxy发送0查看返回值来判断haproxy进程是否存在 返回0表示存在否则表示不存在
interval 2 # 脚本执行间隔
weight 2 # 脚本结果导致的优先级变更
}
#上面类似定义了一个方法在下面的main函数中引用
vrrp_instance VI_01{ #定义一个实例 类似一个路由器
state MASTER #初始状态 可以是master和backup
interface ens33 #使用那个接口进行
virtual_router_id 51 # 虚拟路由ID,同一组虚拟路由就定义一个ID 取值范围0-255
priority 101 #优先级设置 如果为master就要高于其他的
virtual_ipaddress{#设置虚拟vip地址
192.168.1.232/24
}
track_script {#执行上面定义的脚本
check_haproxy
}
}
node节点keepalived配置
global_defs {
lvs_id haproxy_DH
}
vrrp_script check_haproxy {
script "killall -0 haproxy"
interval 2
weight 2
}
vrrp_instance VI_01 {
state MASTER
interface ens33
virtual_router_id 51
priority 101
virtual_ipaddress {
192.168.1.232/24
}
track_script {
check_haproxy
}
}
修改完成后重启keepalived服务
systemctl restart keepalived
重启后查看服务状态
systemctl status keepalived
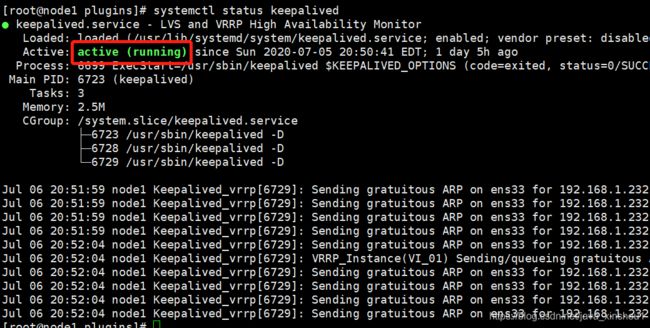
haproxy配置解析
global
log 127.0.0.1 local2 #定义全局的syslog服务器,最多可定义两个
chroot /var/lib/haproxy #修改haproxy的工作目录至指定的目录并在放弃权限之前执行chroot()操作
pidfile /var/run/haproxy.pid
maxconn 4000 #设定每个haproxy进程所接受的最大并发连接数
user haproxy #以指定用户运行haproxy进程
group haproxy #同上指定组名
daemon #让haproxy以守护进程的方式工作于后台
stats socket /var/lib/haproxy/stats #用户访问统计数据的接口
defaults #为所有其它配置段提供默认参数,这配置默认配置参数可由下一个“defaults”所重新设定。
mode http
#设定实例的运行模式或协议。当实现内容交换时,前端和后端必须工作于同一种模式(默认是HTTP模式),否则将无法启动实例
log global
#设置当前实例的日志系统参数同”global”段中的定义
option httplog
#启用记录HTTP请求、会话状态和计时器的功能。
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8#向每个发往服务器的请求添加此首部 以客户端ip为value
option redispatch
retries 3
timeout http-request 10s #在客户端建立连接但不请求数据,关闭客户端连接
timeout queue 1m #等待最大时长
timeout connect 10s #定义haproxy将客户端请求转发到后端服务所等待的超时时长
timeout client 1m #客户端非活动状态的超时时长
timeout server 1m #客户端与服务端建立连接 等待服务端的超时时长
timeout http-keep-alive 10s #定义保持连接的超时时长
timeout check 10s #健康检测的超时时长 过短可能误判 过长可能造成资源消耗
maxconn 3000 #设定每个haproxy进程所接受的最大并发连接数
frontend main *:5000 #"frontend"段用于定义一系列监听套接字 这些套接字可接受客户端请求并与之建立连接
acl url_static path_beg -i /static /images /javascript /stylesheets
acl url_static path_end -i .jpg .gif .png .css .js
use_backend static if url_static
default_backend app #没有被规则匹配到的请求将由 backend app 后端接收
backend static
balance roundrobin
server static 127.0.0.1:4331 check
backend app
balance roundrobin
server app1 127.0.0.1:5001 check
#为后端声明一个server,app1为服务器指定的内部名称 127.0.0.1表示此服务器的IPV4地址 :5001指定将连接请求所发往的此服务器的目标端口,未设定将使用客户端请求的同端口,check表示启动对此server的健康检查。
server app2 127.0.0.1:5002 check
server app3 127.0.0.1:5003 check
server app4 127.0.0.1:5004 check
listen prometheus_server
bind 0.0.0.0:30003 #监听当前系统的所有IPV4地址:30003
balance roundrobin #定义负载均衡算法 roundrobin表示基于权重进行伦叫,在服务器的处理时间保持均匀分布时,这是最平衡的算法。
mode tcp #设定实例运行于TCP模式
option tcp-check
server pr-1 192.168.1.4:9090 check port 9090 inter 2000 fall 3 rise 3 on-marked-down shutdown-sessions
server pr-2 192.168.1.5:9090 check port 9090 inter 2000 fall 3 rise 3 on-marked-down shutdown-sessions
# inter 2000 设定健康检查的时间间隔默认为2000ms fall 3表示健康检查三次失败后将其标记为不可用状态,rise 3 表示离线server从离线状态转换为正常状态需要成功检查的次数
node节点配置和master节点相同即可
kind: Service
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus
namespace: monitoring
spec:
type: ClusterIP
ports:
- port: 9090
protocol: TCP
targetPort: 9090
selector:
app: prometheus
[root@master prometheus]# cd /etc/keepalived/
[root@master keepalived]# ls
keepalived.conf
[root@master keepalived]# cat /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
frontend main *:5000
acl url_static path_beg -i /static /images /javascript /stylesheets
acl url_static path_end -i .jpg .gif .png .css .js
use_backend static if url_static
default_backend app
backend static
balance roundrobin
server static 127.0.0.1:4331 check
backend app
balance roundrobin
server app1 127.0.0.1:5001 check
server app2 127.0.0.1:5002 check
server app3 127.0.0.1:5003 check
server app4 127.0.0.1:5004 check
listen prometheus_server
bind 0.0.0.0:30003
balance roundrobin
mode tcp
option tcp-check
server pr-1 192.168.1.4:9090 check port 9090 inter 2000 fall 3 rise 3 on-marked-down shutdown-sessions
server pr-2 192.168.1.5:9090 check port 9090 inter 2000 fall 3 rise 3 on-marked-down shutdown-sessions
配置修改后重启haproxy服务
systemctl restart haproxy
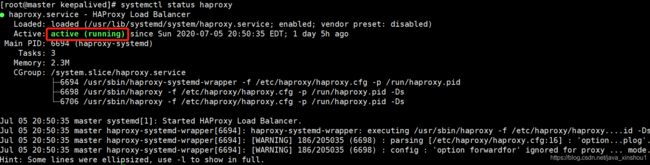
查看haproxy服务状态
systemctl status haproxy
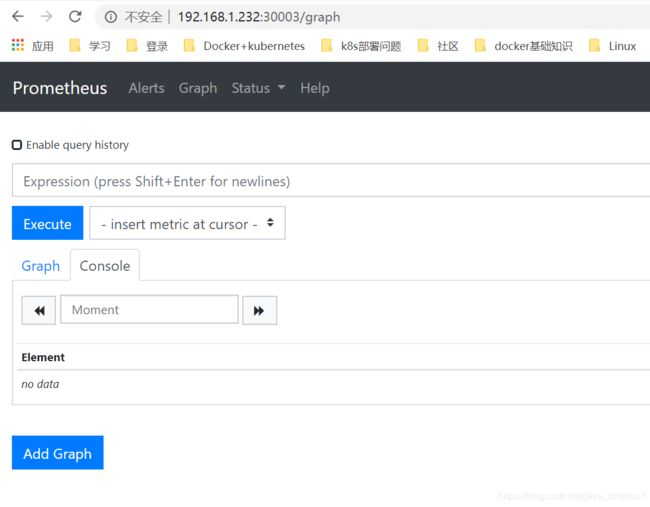
这里可以测试使用vip+端口访问prometheus
部署grafana展示prometheus数据
grafana-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana-core
namespace: monitoring
labels:
app: grafana
spec:
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
nodeSelector:
app: grafana
hostNetwork: true
containers:
- image: grafana/grafana:7.0.5
name: grafana
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
env:
- name: GF_AUTH_BASIC_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "false"
readinessProbe:
httpGet:
path: /login
port: 3000
volumeMounts:
- name: grafana-data
mountPath: /var/lib/grafana
- name: localtime
mountPath: /etc/localtime
volumes:
- hostPath:
path: /tsdb/grafana
type: DirectoryOrCreate
name: grafana-data
- hostPath:
path: /etc/localtime
type: ""
name: localtime
kubectl create -f grafana-deploy.yaml
这里部署在node节点,通过label来选择
kubectl label no app=grafana
配置haproxy将grafana服务代理出去
master和node节点均修改haproxy配置
vi /etc/haproxy/haproxy.cfg
在末尾加 加完重启下haproxy服务
listen grafana
bind 0.0.0.0:30004
balance roundrobin
mode tcp
option tcp-check
server pr-1 192.168.1.5:3000 check port 3000 inter 2000 fall 3 rise 3 on-marked-down shutdown-sessions
测试用VIP访问grafana服务
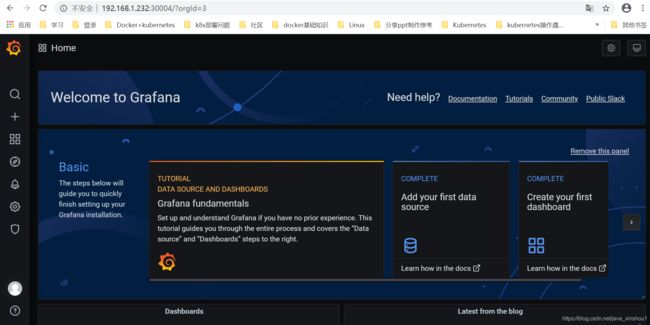
grafana初始用户名密码均为:admin
接下来就可以配置展示面板了
首先添加数据源

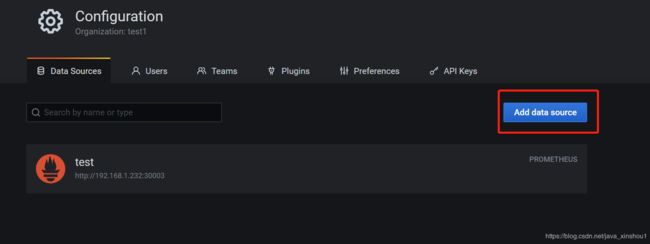
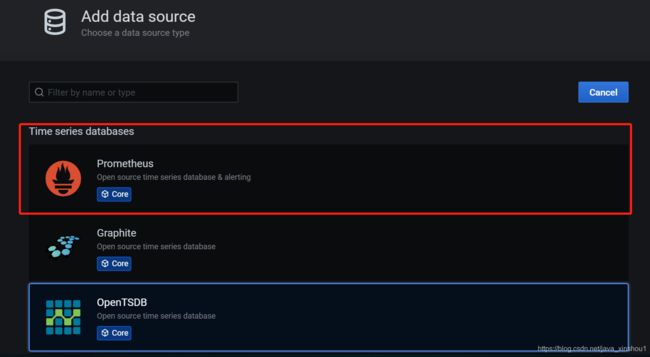
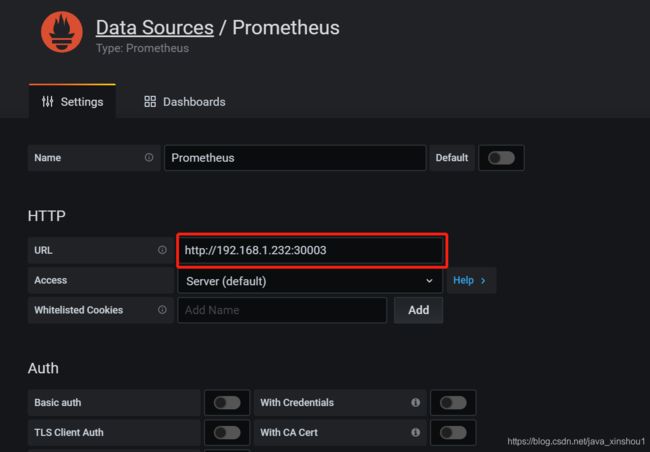
下拉选择save&test即可
简单配置一个面板
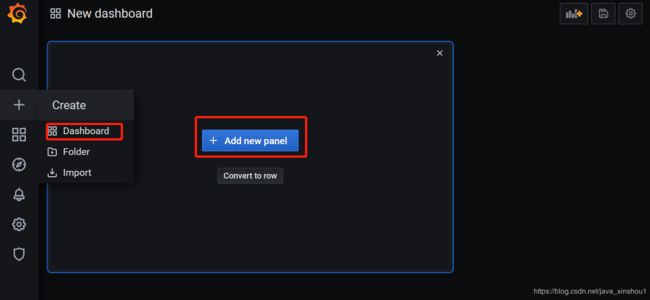
选择刚刚配置的数据源
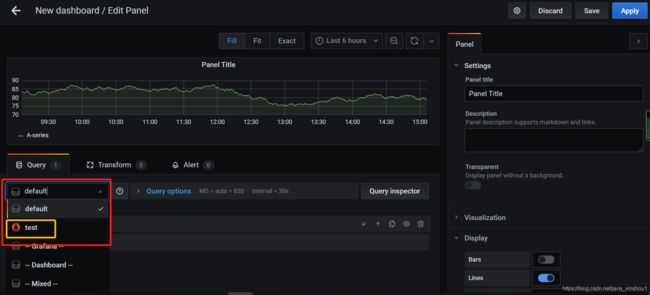
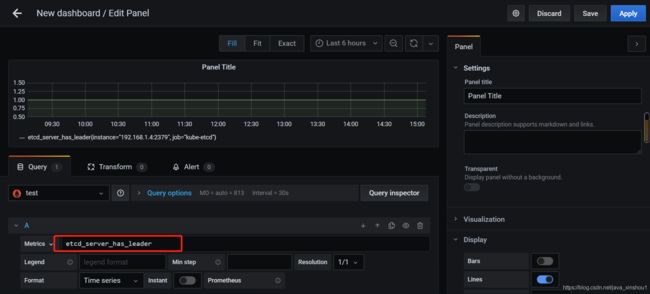
metrics写prometheus查询语句
选择合适的面板来展示数据
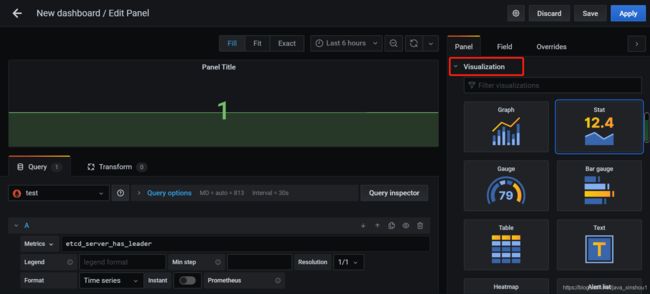
百度网盘分享中有几个面板插件 可以下载解压到主机的grafana目录的plugins目录下,重启grafana即可
![]()