利用动态渲染页面对京东笔记本电脑信息爬取
写在前面
之前写过一个爬取京东商品的Scrapy爬虫项目,但是里面价格及评论数是通过逆向工程法获得的,在不使用代理ip的情况下,在爬取一定数量的商品后会被持续要求输入验证码。所以这里写出利用动态页面渲染对京东商品价格及评论数爬取的方法。
在之前的项目中,构造特殊请求获得的数据有:
- 价格
- 评论数
- 好评度
但由于好评度需要进入单个商品的页面才能获取,而利用动态渲染页面爬取数据其实是模拟真实浏览器对网页访问,加载所有网页内容后实现“可见即可得”,所以速度比requests.get()等要慢很多很多,在要批量爬取大量商品信息时效率极低。所以这里就舍弃了好评度这项数据,保留了 价格 和 评论数 这两项在商品浏览页面就可以获取的数据。

利用Selenium对价格、评论数提取
注:这里使用谷歌浏览器
首先利用Selenium打开Chrome并访问商品页面(由于要批量爬取商品信息,所以这里使用headless模式隐藏浏览器界面):
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
page = 1
url = "https://list.jd.com/list.html?cat=670,671,672&page=" + str(page) + "&sort=sort_totalsales15_desc&trans=1&JL=6_0_0#J_main"
browser.get(url)
html = browser.page_source
这样就获取了页面所有信息,然后在Chrom的开发者工具中对页面进行分析:
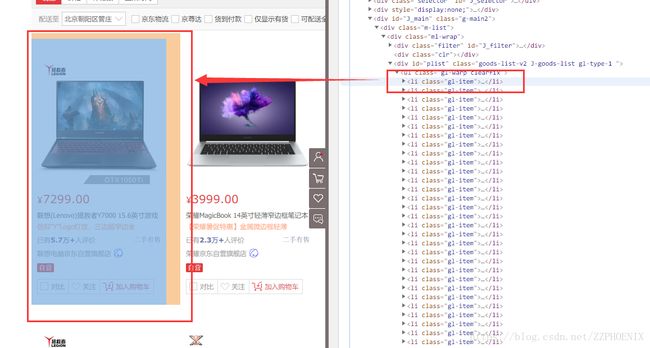
可见每一个

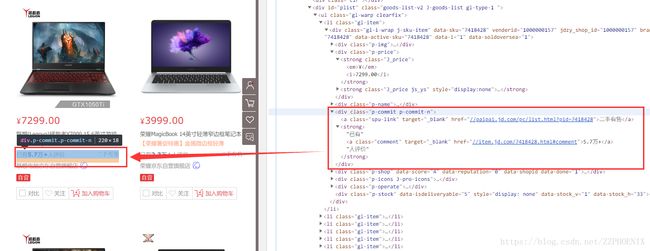
然后利用pyquery库对价格和评论数进行提取:
from pyquery import PyQuery as pq
doc = pq(html)
首先提取所有的
info = doc('.gl-item').items()
然后遍历并提取价格和评论数:
for item in info:
price = item.find('.J_price.js_ys').text()
comment = item.find('.p-commit').text()
多观察几个商品后会发现有的商品评论数后有“二手有售”,而有的没有
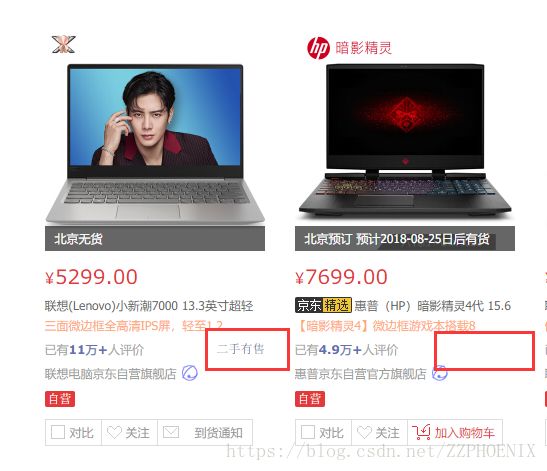
而“二手有售”将会出现在提取的comment中,所以进行处理:
import re
comment = re.compile(r'已有\n(.*?)\n人评价').findall(comment)[0]
这样提取出来的评论为“2.3万+”这样的格式,为了后期在数据库中对数据的比较操作,这里再进行处理:
if '万' in comment:
comment = comment.replace('万+', '')
comment = int(float(comment) * 10000)
elif '+' in comment:
comment = int(comment.replace('+', ''))
同样的,对价格进行处理:
price = float(price.replace('¥\n', ''))
最后将两个数据分别存储到对应的列表中:
prices = []
comments = []
prices.append(price)
comments.append(comment)
这样商品的价格和评论数就提取完成了。
后期操作和之前写的项目 Scrapy框架爬虫项目:京东商城笔记本电脑信息爬取 基本相同
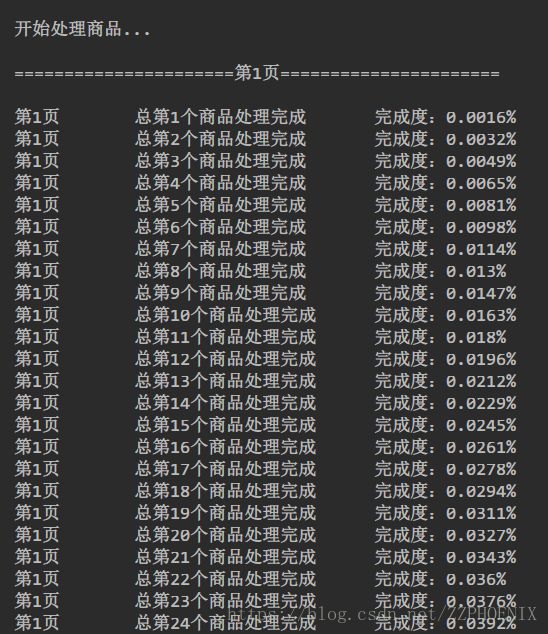
运行图片:
代码如下:
更新:
1. 增加功能:商品爬取失败后单独存储商品链接并在后期重新爬取
2. 解决了“全球购”商品的信息存储格式与普通商品不同导致爬取失败的问题
from selenium import webdriver
from pyquery import PyQuery as pq
import pymysql
import re
import urllib.request
import time
import socket
import threading
connection = pymysql.connect(user='root', password='Zwp0816...', host='127.0.0.1', db='JD_Goods')
cursor = connection.cursor()
cursor.execute('drop table if exists new_Goods;')
cursor.execute(
'create table new_Goods(名称 varchar(100), 价格 float, 评论 int, 内存 varchar(100), CPU类型 varchar(100), CPU型号 varchar(100), CPU速度 varchar(100), CPU核心 varchar(100), 硬盘容量 varchar(100), 固态硬盘 varchar(100), 显卡类型 varchar(100), 显示芯片 varchar(100), 显存容量 varchar(100), 尺寸 varchar(100), 重量 varchar(100), 链接 varchar(100));')
# cursor.execute('create table Goods(名称 varchar(100), 价格 varchar(100), 好评数 int, 差评数 int, 好评度 varchar(10), 内存 varchar(100), CPU类型 varchar(100), CPU型号 varchar(100), CPU速度 varchar(100), CPU核心 varchar(100), 硬盘容量 varchar(100), 固态硬盘 varchar(100), 显卡类型 varchar(100), 显示芯片 varchar(100), 显存容量 varchar(100), 尺寸 varchar(100), 重量 varchar(100), 链接 varchar(100));')
connection.commit()
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
# browser2 = webdriver.Chrome(chrome_options=chrome_options)
'''
browser = webdriver.Firefox()
'''
# TOTAL为总页数
url = 'https://list.jd.com/list.html?cat=670,671,672&page=1'
TOTAL = int(re.findall('共(.*?)', urllib.request.urlopen(url).read().decode('utf-8', 'ignore'))[0])
# print(TOTAL)
#TOTAL = 1
global count, links, prices, comments, retry_index, retry_products, fail_links
count = 0
links = []
prices = []
comments = []
retry_index = []
retry_products = []
fail_links = []
def get_url_price_and_comment(index):
try:
url = "https://list.jd.com/list.html?cat=670,671,672&page=" + str(
index) + "&sort=sort_totalsales15_desc&trans=1&JL=6_0_0#J_main"
page = urllib.request.urlopen(url).read().decode('gbk', 'ignore')
global links, prices, comments
results = re.compile('').findall(page)
for i in range(0, len(results)):
results[i] = 'https:' + results[i]
links += results
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get(url)
html = browser.page_source
doc = pq(html)
browser.close()
info = doc('.gl-item').items()
for item in info:
price = item.find('.J_price.js_ys').text()
try:
price = float(price.replace('¥\n', ''))
except:
price = "NULL"
prices.append(price)
comment = item.find('.p-commit').text()
comment = re.compile(r'已有\n(.*?)\n人评价').findall(comment)[0]
if '万' in comment:
comment = comment.replace('万+', '')
comment = int(float(comment) * 10000)
elif '+' in comment:
comment = int(comment.replace('+', ''))
comments.append(comment)
print("\n======================第" + str(index) + "页======================\n")
except Exception as e:
print(e)
global retry_index
retry_index.append(index)
def get_product(page):
global links, prices, comments
link = links.pop(0)
price = prices.pop(0)
comment = comments.pop(0)
try:
html = urllib.request.urlopen(link, timeout=5).read().decode('gbk', 'ignore')
name = re.compile('![]() , re.S).findall(html)[0]
name = name.strip()
result1 = re.compile('
, re.S).findall(html)[0]
name = name.strip()
result1 = re.compile('内存容量 .*?(.*?)<' , re.S).findall(html)
result2 = re.compile('内存类型 .*?(.*?)<' , re.S).findall(html)
result1 = result1[0] if result1 != [] else ''
result2 = result2[0] if result2 != [] else ''
internalStorage = result1 + result2
# print(internalStorage)
result = re.compile('CPU类型 .*?(.*?)<' , re.S).findall(html)
cpu_type = result[0] if result != [] else ''
# print(cpu_type)
result = re.compile('CPU型号 .*?(.*?)<' , re.S).findall(html)
cpu_Mode = result[0] if result != [] else ''
# print(cpu_Mode)
result = re.compile('CPU速度 .*?(.*?)<' , re.S).findall(html)
cpu_speed = result[0] if result != [] else ''
result = re.compile('核心 .*?(.*?)<' , re.S).findall(html)
cpu_core = result[0] if result != [] else ''
result = re.compile('硬盘容量 .*?(.*?)<' , re.S).findall(html)
diskCapacity = result[0] if result != [] else ''
result = re.compile('固态硬盘 .*?(.*?)<' , re.S).findall(html)
SSD = result[0] if result != [] else ''
result = re.compile('类型 .*?(.*?)<' , re.S).findall(html)
GCtype = result[0] if result != [] else ''
result = re.compile('显示芯片 .*?(.*?)<' , re.S).findall(html)
GCcore = result[0] if result != [] else ''
result = re.compile('显存容量 .*?(.*?)<' , re.S).findall(html)
GCcapacity = result[0] if result != [] else ''
result = re.compile('尺寸 .*?(.*?)<' , re.S).findall(html)
size = result[0] if result != [] else ''
result = re.compile('净重 .*?(.*?)<' , re.S).findall(html)
weight = result[0] if result != [] else ''
if price != 'NULL':
sql = 'insert into new_Goods values(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)'
cursor.execute(sql, (
name, price, comment, internalStorage, cpu_type, cpu_Mode, cpu_speed, cpu_core, diskCapacity, SSD,
GCtype,
GCcore, GCcapacity, size, weight, link))
connection.commit()
global count
count += 1
print("第" + str(page) + "页\t\t总第" + str(count) + "个商品处理完成\t\t完成度:" + str(
int((count / (TOTAL * 60)) * 1000000) / 10000) + "%")
else:
global retry_products
info = {'link': link, 'comment': comment}
retry_products.append(info)
print('! ! ! ! ! !错误: 价格为空\t稍后重试')
except Exception as e:
print('! ! ! ! ! !错误: ', e, '\t稍后重试')
info = {'link': link, 'comment': comment}
retry_products.append(info)
def retry_product(page):
global retry_products
info = retry_products.pop(0)
link = info['link']
comment = info['comment']
try:
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get(link)
doc = pq(browser.page_source)
price = doc.find('.summary-price .price').text()
price = float(price)
html = urllib.request.urlopen(link, timeout=None).read().decode('gbk', 'ignore')
name = re.compile('![]() , re.S).findall(html)[0]
name = name.strip()
result1 = re.compile('
, re.S).findall(html)[0]
name = name.strip()
result1 = re.compile('内存容量 .*?(.*?)<' , re.S).findall(html)
result2 = re.compile('内存类型 .*?(.*?)<' , re.S).findall(html)
result1 = result1[0] if result1 != [] else ''
result2 = result2[0] if result2 != [] else ''
internalStorage = result1 + result2
# print(internalStorage)
result = re.compile('CPU类型 .*?(.*?)<' , re.S).findall(html)
cpu_type = result[0] if result != [] else ''
# print(cpu_type)
result = re.compile('CPU型号 .*?(.*?)<' , re.S).findall(html)
cpu_Mode = result[0] if result != [] else ''
# print(cpu_Mode)
result = re.compile('CPU速度 .*?(.*?)<' , re.S).findall(html)
cpu_speed = result[0] if result != [] else ''
result = re.compile('核心 .*?(.*?)<' , re.S).findall(html)
cpu_core = result[0] if result != [] else ''
result = re.compile('硬盘容量 .*?(.*?)<' , re.S).findall(html)
diskCapacity = result[0] if result != [] else ''
result = re.compile('固态硬盘 .*?(.*?)<' , re.S).findall(html)
SSD = result[0] if result != [] else ''
result = re.compile('类型 .*?(.*?)<' , re.S).findall(html)
GCtype = result[0] if result != [] else ''
result = re.compile('显示芯片 .*?(.*?)<' , re.S).findall(html)
GCcore = result[0] if result != [] else ''
result = re.compile('显存容量 .*?(.*?)<' , re.S).findall(html)
GCcapacity = result[0] if result != [] else ''
result = re.compile('尺寸 .*?(.*?)<' , re.S).findall(html)
size = result[0] if result != [] else ''
result = re.compile('净重 .*?(.*?)<' , re.S).findall(html)
weight = result[0] if result != [] else ''
sql = 'insert into new_Goods values(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)'
cursor.execute(sql, (
name, price, comment, internalStorage, cpu_type, cpu_Mode, cpu_speed, cpu_core, diskCapacity, SSD,
GCtype,
GCcore, GCcapacity, size, weight, link))
connection.commit()
global count
count += 1
print("第" + str(page) + "页\t\t总第" + str(count) + "个商品处理完成\t\t完成度:" + str(
int((count / (TOTAL * 60)) * 10000) / 100) + "%")
except:
try:
# 处理“全球购”商品
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get(link)
doc = pq(browser.page_source)
price = doc.find('.p-price .price').html()
price = float(price)
html = urllib.request.urlopen(link, timeout=None).read().decode('gbk', 'ignore')
name = doc.find('.sku-name').text()
name = name.replace('"', '')
name = name.strip()
result1 = re.compile('最大支持容量.*? (.*?)<', re.S).findall(html)
result2 = re.compile(' 内存类型.*? (.*?)<', re.S).findall(html)
result1 = "最大支持容量" + result1[0] if result1 != [] else ''
result2 = result2[0] if result2 != [] else ''
internalStorage = result2 + ' ' + result1
# print(internalStorage)
result = re.compile(' CPU类型 .*?(.*?)<', re.S).findall(html)
cpu_type = result[0] if result != [] else ''
# print(cpu_type)
result = re.compile('CPU型号 .*?(.*?)<', re.S).findall(html)
cpu_Mode = result[0] if result != [] else ''
# print(cpu_Mode)
result = re.compile('CPU速度 .*?(.*?)<', re.S).findall(html)
cpu_speed = result[0] if result != [] else ''
result = re.compile(' 核心 .*?(.*?)<', re.S).findall(html)
cpu_core = result[0] if result != [] else ''
result = re.compile(' 硬盘容量 .*?(.*?)<', re.S).findall(html)
diskCapacity = result[0] if result != [] else ''
result = re.compile(' 固态硬盘 .*?(.*?)<', re.S).findall(html)
SSD = result[0] if result != [] else ''
result = re.compile(' 类型 .*?(.*?)<', re.S).findall(html)
GCtype = result[0] if result != [] else ''
result = re.compile(' 显示芯片 .*?(.*?)<', re.S).findall(html)
GCcore = result[0] if result != [] else ''
result = re.compile(' 显存容量 .*?(.*?)<', re.S).findall(html)
GCcapacity = result[0] if result != [] else ''
result = re.compile(' 屏幕尺寸 .*?(.*?)<', re.S).findall(html)
size = result[0] if result != [] else ''
result = re.compile(' 净重 .*?(.*?)<', re.S).findall(html)
weight = result[0] if result != [] else ''
sql = 'insert into new_Goods values(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)'
cursor.execute(sql, (
name, price, comment, internalStorage, cpu_type, cpu_Mode, cpu_speed, cpu_core, diskCapacity, SSD,
GCtype,
GCcore, GCcapacity, size, weight, link))
connection.commit()
count += 1
print("第" + str(page) + "页\t\t总第" + str(count) + "个商品处理完成\t\t完成度:" + str(
int((count / (TOTAL * 60)) * 10000) / 100) + "%")
except:
print("* * * * * 商品信息无法处理,链接:", link)
global fail_links
fail_links.append(link)
def main():
print("\n开始处理商品...")
start = 1
end = start + TOTAL
for i in range(start, end):
get_url_price_and_comment(i)
while links != []:
get_product(i)
if retry_products != []:
print("\t--------正在重新处理错误商品--------")
while retry_products != []:
retry_product(i)
print("\n第" + str(i) + "页处理完成")
while retry_index != []:
index = retry_index.pop(0)
get_url_price_and_comment(index)
if retry_products != []:
print("\t--------正在重新处理错误商品--------")
while retry_products != []:
retry_product(i)
print("\n第" + str(index) + "页处理完成")
print("**************所有商品链接处理完成**************")
if __name__ == '__main__':
main()
你可能感兴趣的:(爬虫,编程语言)