前言
Solr 是一种可供企业使用的、基于 Lucene 的搜索服务器,它支持层面搜索、命中醒目显示和多种输出格式。在这篇文章中,我将介绍 Solr 的部署和使用的基本操作,希望能让初次使用的朋友们少踩一些坑。
下载地址:https://lucene.apache.org/solr/downloads.html
本文中使用的 Solr 版本:7.7.2,因为我是用的是 Windows 系统,所以主要介绍的是 Windows 下的部署方法。
安装
Solr 内置了 Jetty,所以不需要任何安装任何 Web 容器即可运行。直接通过命令行就可以启动。
启动 Solr:
.\solr.cmd start停止 Solr:
.\solr.cmd stop -all创建 Core
首先在 server\solr 文件夹中创建一个新的目录,然后将 server\solr\configsets\_default 下的 conf 目录复制到刚刚创建的文件夹。
在浏览器中打开 http://localhost:8983/solr/ 点击左侧的 Core Admin 添加 Core。
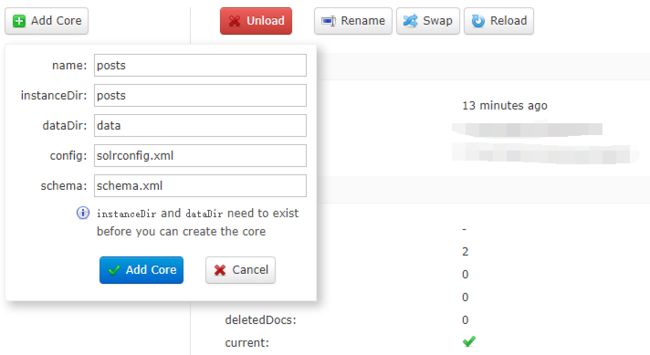
name 和 instanceDir 都改成刚刚创建的目录名称。
创建好之后即可在左侧的 Core Selector 中找到这个 Core。
现在一个 Core 就创建好了,在 Core 的面板里可以对其进行一些基本操作。
Solr 的 Api 是支持通过调用接口添加数据的,但是在实际使用中我们都是从数据库中同步数据,所以我们需要为 Solr 配置数据源。
在 solrconfig.xml 文件中找到如下内容:
添加一个 requestHandler 节点:
data-config.xml
data-config.xml 文件的大致结构如下:

稍后会对 data-config.xml 文件进行详细介绍。
配置数据源
使用 SQL Server 数据源
从微软官网下载 SQL Server 的 Microsoft SQL Server JDBC 驱动程序 4.1 驱动,复制到 server\solr-webapp\webapp\WEB-INF\lib 目录下。
这里需要注意的是把在下载的文件重命名为 sqljdbc4.jar,我之前没有改名死活加载不上。
使用 com.microsoft.sqlserver.jdbc.SQLServerDriver 驱动配置数据源:
使用 MySQL 数据源
下载:mysql-connector-java-6.0.6.jar 复制到 server\solr-webapp\webapp\WEB-INF\lib 目录下。
从 dist 目录复制 solr-dataimporthandler-7.7.2.jar 到 server/solr-webapp/webapp/WEB-INF/lib 中。
配置 data-config.xml:
entity 中的一些常用属性:
- query:查询只对第一次全量导入有作用,对增量同步不起作用。
- deltaQuery:的意思是,查询出所有经过修改的记录的 Id 可能是修改操作,添加操作,删除操作产生的(此查询只对增量导入起作用,而且只能返回 Id 值)
- deletedPkQuery:此操作值查询那些数据库里伪删除的数据的 Id、solr 通过它来删除索引里面对应的数据(此查询只对增量导入起作用,而且只能返回 Id 值)。
- deltaImportQuery:是获取以上两步的 Id,然后把其全部数据获取,根据获取的数据对索引库进行更新操作,可能是删除,添加,修改(此查询只对增量导入起作用,可以返回多个字段的值,一般情况下,都是返回所有字段的列)。
- parentDeltaQuery:从本 entity 中的 deltaquery 中取得参数。
dataSource 中 batchSize 属性的作用是可以在批量导入的时候限制连接数量。
配置完成后重新加载一下 Core。
中文分词
将 contrib\analysis-extras\lucene-libs 目录中的 lucene-analyzers-smartcn-7.7.2.jar 复制到 server\solr-webapp\webapp\WEB-INF\lib 目录下,否则会报错。
在 managed-shchema 中添加如下代码:
把需要使用中文分词的字段类型设置成 text_cn:
主从部署
Solr 复制模式,是一种在分布式环境下用于同步主从服务器的一种实现方式,因之前提到的基于 rsync 的 SOLR 不同方式部署成本过高,被 Solr 1.4 版本所替换,取而代之的就是基于 HTTP 协议的索引文件传输机制,该方式部署简单,只需配置一个文件即可。Solr 索引同步的是 Core 对 Core,以 Core 为基本同步单元。
主服务器 solrconfig.xml 配置:
commit
startup
schema.xml,stopwords.txt
00:05:00
从服务器 solrconfig.xml 配置:
http://192.168.1.135/solr/posts
00:00:60
internal
50000
500000
Solr 主从同步是通过 Slave 周期性轮询来检查 Master 的版本,如果 Master 有新版本的索引文件,Slave 就开始同步复制。
- 1、Slave 发出一个 filelist 命令来收集文件列表。这个命令将返回一系列元数据(size、lastmodified、alias 等信息)。
- 2、Slave 查看它本地是否有这些文件,然后它会开始下载缺失的文件(使用命令 filecontent)。如果与 Master 连接失败,就会重新连接,如果重试 5 次还是没有成功,就会 Slave 停止同步。
- 3、文件被同步到了一个临时目录(
index.时间戳格式的文件夹名称,例如:index.20190614133600008)。旧的索引文件还存放在原来的文件夹中,同步过程中出错不会影响到 Slave,如果同步过程中有请求访问,Slave 会使用旧的索引。 - 4、当同步结束后,Slave 就会删除旧的索引文件使用最新的索引。
我们项目中 6.7G 的索引文件(279 万条记录),大概只用了 12 分钟左右就同步完成了,平均每秒的同步速度大约在 10M 左右。
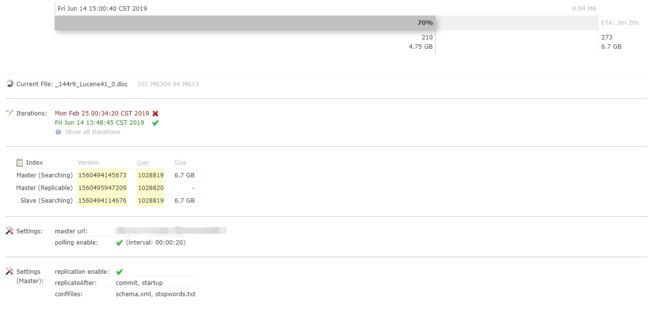

注意事项: 如果主从的数据源配置的不一致,很可能导致从服务器无法同步索引数据。
在项目中使用 Solr
在 Java 项目中使用 Solr
SolrJ 是 Solr 的官方客户端,文档地址:https://lucene.apache.org/solr/7_7_2/solr-solrj/。
使用 maven 添加:
org.apache.solr
solr-solrj
7.7.2
查询索引文档:
String keyword = "苹果";
Map queryParamMap = new HashMap();
queryParamMap.put("q", "*:*");
queryParamMap.put("fq", keyword);
MapSolrParams queryParams = new MapSolrParams(queryParamMap);
QueryResponse queryResponse = client.query("posts", queryParams);
SolrDocumentList results = queryResponse.getResults(); 添加和更新索引文档:
// 通过 属性 添加到索引中
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", "10000");
doc.addField("post_title", "test-title");
doc.addField("post_name", "test-name");
doc.addField("post_excerpt", "test-excerpt");
doc.addField("post_content", "test-content");
doc.addField("post_date", "2019-06-18 14:56:55");
client.add("posts", doc);
// 通过 Bean 添加到索引中
Post post = new Post();
post.setId(10001);
post.setPost_title("test-title-10001");
post.setPost_name("test-name");
post.setPost_excerpt("test-excerpt");
post.setPost_content("test-content");
post.setPost_date(new Date());
client.addBean("posts", post);
client.commit("posts");具体代码可以参考我 GitHub 中的示例,这里就不详细列出了。
在 DotNet 项目中使用 Solr
SolrNet:https://github.com/mausch/SolrNet
通过 Nuget 添加 SolrNet:
Install-Package SolrNet首先定义一个索引对象 PostDoc:
///
/// 文章 doc。
///
[Serializable]
public class PostDoc
{
[SolrUniqueKey("id")]
public int Id { get; set; }
[SolrField("post_title")]
public string Title { get; set; }
[SolrField("post_name")]
public string Name { get; set; }
[SolrField("post_excerpt")]
public string Excerpt { get; set; }
[SolrField("post_content")]
public string Content { get; set; }
[SolrField("post_date")]
public DateTime PostDate { get; set; }
}在项目的 Startup 类中初始化 SolrNet:
SolrNet.Startup.Init("http://localhost:8983/solr/posts"); 添加或更新文档操作:
// 同步添加文档
solr.Add(
new PostDoc()
{
Id = 30001,
Name = "This SolrNet Name",
Title = "This SolrNet Title",
Excerpt = "This SolrNet Excerpt",
Content = "This SolrNet Content 30001",
PostDate = DateTime.Now
}
);
// 异步添加文档(更新)
await solr.AddAsync(
new PostDoc()
{
Id = 30001,
Name = "This SolrNet Name",
Title = "This SolrNet Title",
Excerpt = "This SolrNet Excerpt",
Content = "This SolrNet Content Updated 30001",
PostDate = DateTime.Now
}
);
// 提交
ResponseHeader responseHeader = await solr.CommitAsync();删除文档操作:
// 使用文档 Id 删除
await solr.DeleteAsync("300001");
// 直接删除文档
await solr.DeleteAsync(new PostDoc()
{
Id = 30002,
Name = "This SolrNet Name",
Title = "This SolrNet Title",
Excerpt = "This SolrNet Excerpt",
Content = "This SolrNet Content 30002",
PostDate = DateTime.Now
});
// 提交
ResponseHeader responseHeader = await solr.CommitAsync();搜索并对结果进行排序,在不传入分页参数的情况下 SolrNet 会返回所有满足条件的结果。
// 排序
ICollection sortOrders = new List() {
new SortOrder("id", Order.DESC)
};
// 使用查询条件并排序
SolrQueryResults docs = await solr.QueryAsync("post_title:索尼", sortOrders); 使用字段筛选的另一种方式:
// 使用条件查询
SolrQueryResults posts = solr.Query(new SolrQueryByField("id", "30000")); 分页查询并对高亮关键字:
SolrQuery solrQuery = new SolrQuery("苹果");
QueryOptions queryOptions = new QueryOptions
{
// 高亮关键字
Highlight = new HighlightingParameters
{
Fields = new List { "post_title" },
BeforeTerm = "",
AfterTerm = ""
},
// 分页
StartOrCursor = new StartOrCursor.Start(pageIndex * pageSize),
Rows = pageSize
};
SolrQueryResults docs = await solr.QueryAsync(solrQuery, queryOptions);
var highlights = docs.Highlights; 高亮关键字需要在返回结果中单独获取,docs.Highlights 是一个 IDictionary 对象,每个 key 对应文档的 id,HighlightedSnippets 中也是一个 Dictionary,存储高亮处理后的字段和内容。
在 Python 项目中使用 Solr
PySolr:https://github.com/django-haystack/pysolr
使用 pip 安装 pysolr:
pip install pysolr简单的操作:
# -*- coding: utf-8 -*-
import pysolr
SOLR_URL = 'http://localhost:8983/solr/posts'
def add():
"""
添加
"""
result = solr.add([
{
'id': '20000',
'post_title': 'test-title-20000',
'post_name': 'test-name-20000',
'post_excerpt': 'test-excerpt-20000',
'post_content': 'test-content-20000',
'post_date': '2019-06-18 14:56:55',
},
{
'id': '20001',
'post_title': 'test-title-20001',
'post_name': 'test-name-20001',
'post_excerpt': 'test-excerpt-20001',
'post_content': 'test-content-20001',
'post_date': '2019-06-18 14:56:55',
}
])
solr.commit()
results = solr.search(q='id: 20001')
print(results.docs)
def delete():
"""
删除
"""
solr.delete(q='id: 20001')
solr.commit()
results = solr.search(q='id: 20001')
print(results.docs)
def update():
"""
更新
"""
solr.add([
{
'id': '20000',
'post_title': 'test-title-updated',
'post_name': 'test-name-updated',
'post_excerpt': 'test-excerpt-updated',
'post_content': 'test-content-updated',
'post_date': '2019-06-18 15:00:00',
}
])
solr.commit()
results = solr.search(q='id: 20000')
print(results.docs)
def query():
"""
查询
"""
results = solr.search('苹果')
print(results.docs)
if __name__ == "__main__":
solr = pysolr.Solr(SOLR_URL)
add()
delete()
update()
query()需要注意的是在使用 solr.add() 和 solr.delete 方法以后需要执行一下 solr.commit() 方法,否则文档的变更不会提交。
如果想获取添加或更新是否成功可以通过判断 solr.commit() 方法返回结果,solr.commit() 方法的返回结果是一个 xml 字符串:
0
44
status 的值如果是 0 就表示提交成功了。
总结
通过简单使用和测试,就会发现搜索结果并不是很精准,比如搜索“微软”这个关键字,搜索出来的数据中有完全不包含这个关键字的内容,所以要想让搜索结果更加准确就必须对 Sorl 进行调优,Solr 中还有很多高级的用法,例如设置字段的权重、自定义中文分词词库等等,有机会我会专门写一篇这样的文章来介绍这些功能。
我在 sql 目录里提供了数据库脚本,方便大家创建测试数据,数据是以前做的一个小站从网上抓取过来的科技新闻。
项目地址:https://github.com/weisenzcharles/SolrExample