Soft Actor-Critic 论文笔记
无模型深度强化学习算法(Model-free DRL)有两个主要缺点:
1.非常高的样本复杂性(需要与环境进行大量交互产生大量样本)
2.脆弱的收敛性(它的收敛性受超参数影响严重:学习率,探索常量等等)
这两个缺点限制了其应用于复杂的真实世界任务。
有些同策略算法(On-policy)样本效率低。比如TRPO,A3C,PPO等是同策略,他们每一步梯度计算都需要新的样本收集。而异策略算法(Off-policy),可以重复使用过去的经验。重复使用过去经验(经验回放Experiences Replay )并不能直接使用于传统策略梯度框架,但其在基于Q学习的方法上有直接使用。此外异策略学习,高维空间,与神经网络的结合会带来稳定性和收敛性的挑战。这两个挑战对于连续状态动作任务(连续任务中Q-Learning的最大化动作通过actor直接选择)更加明显,DDPG就是一个代表。但是DDPG虽然实现在Off-policy leraning中重复利用样本,但是其对超参敏感,并且收敛性脆弱。
为了设计稳定高效的无模型DRL,本文,提出来一种异策略(Off-policy)深度AC算法,Soft Actor-Critic(SAC),SAC基于最大熵强化学习框架。在这个框架中,演员的目标是最大化期望的奖励,同时也最大化熵。**这样做的目的是在完成任务同时行动尽量随机化。**注意是虽然实验环境是连续任务,不同于DDPG将异策略AC与确定性actor(确定性策略)结合,SAC是将异策略AC方法和随机Actor(随机策略)
最大化熵的设置的优点:改变强化学习的目标,可以实际性提升探索性和鲁棒性
实验上,SAC在连续任务上实现了state-of-the-art,而且相比于其他异策略算法更加稳定,在不同随机种子种表现相似。
SAC
首先当然是强化学习中的MDP,通过元组 ( S , A , p , r ) (S,A,p,r) (S,A,p,r)定义, A , S A,S A,S分别是状态和动作空间, p p p是转移概率: S × S × A → [ 0 , ∞ ) S\times S\times A \rightarrow [0, \infty) S×S×A→[0,∞). 环境给出的奖赏是有界的 r : S × A → [ r m i n , r m a x ] r:S\times A\rightarrow[r_{min},r_{max}] r:S×A→[rmin,rmax]. 策略 π ( a t ∣ s t ) \pi(a_t|s_t) π(at∣st)引起的轨迹分布的状态和状态 - 动作边缘分布分别表示 ρ π ( s t ) \rho_\pi(s_t) ρπ(st)和 ρ π ( s t ∣ a t ) \rho_\pi(s_t|a_t) ρπ(st∣at).
通常强化学习方法的目标是最大化累积奖赏: ∑ t E ( s t , a t ) ∼ ρ π [ r ( s t , a t ) ] \sum_t \mathbb{E}_{(s_t,a_t)\sim \rho_\pi}[r(s_t,a_t)] t∑E(st,at)∼ρπ[r(st,at)]而SAC的目标是带熵的累积奖赏: J ( π ) = ∑ t = 0 T E ( s t , a t ) ∼ ρ π [ r ( s t , a t ) + α H ( π ( ⋅ ∣ s t ) ) ] ( 1 ) J(\pi)=\sum_{t=0}^T\mathbb{E}_{(s_t,a_t)\sim\rho_\pi}[r(s_t,a_t)+\alpha H(\pi(\cdot|s_t))] \quad(1) J(π)=t=0∑TE(st,at)∼ρπ[r(st,at)+αH(π(⋅∣st))](1)
其中参数 α \alpha α控制最优策略的随机程度,以及上策略熵相对于奖赏的重要程度。对于无限的情况我们可以加上折扣因子.
软策略迭代(Soft policy Iteration)
Soft policy evaluation:
策略评估阶段,根据最大熵目标(1)式计算策略对应的值函数。对于一个固定的策略其软Q值(Soft Q-value)通过改正的贝尔曼操作 τ π \tau^\pi τπ:
τ π Q ( s t , a t ) = r ( s t , a t ) + γ E s t + 1 ∼ p [ V ( s t + 1 ) ] ( 2 ) \tau ^\pi Q(s_t,a_t)=r(s_t,a_t)+\gamma\mathbb{E}_{s_{t+1}\sim p}[V(s_{t+1})]\quad (2) τπQ(st,at)=r(st,at)+γEst+1∼p[V(st+1)](2)其中
V ( s t ) = E a t ∼ π [ Q ( s t , a t ) − l o g π ( a t ∣ s t ) ] ( 3 ) V(s_t)=\mathbb{E}_{a_t\sim \pi}[Q(s_t,a_t)-log\pi(a_t|s_t)]\quad (3) V(st)=Eat∼π[Q(st,at)−logπ(at∣st)](3)是软状态值函数(Soft state value function).那么软策略评估可以通过 Q k + 1 = τ π Q k Q^{k+1}=\tau^\pi Q^k Qk+1=τπQk迭代,若通过无限次迭代,这样最终Q会收敛到策略 π \pi π的软 Q Q Q值函数.
定义带熵的奖赏: r π ( s t , a t ) = r ( s t , a t ) + E s t + 1 ∼ p [ H ( π ( ⋅ ∣ s t + 1 ) ) ] r_\pi(s_t,a_t)=r(s_t,a_t)+\mathbb{E}_{s_{t+1}\sim p}[H(\pi(\cdot|s_{t+1}))] rπ(st,at)=r(st,at)+Est+1∼p[H(π(⋅∣st+1))]则更新规则为: Q ( s t , a t ) ← r π ( s t , a t ) + γ E s t + 1 ∼ p , a t + 1 ∼ π [ Q ( s t + 1 , a t + 1 ) ] Q(s_t,a_t)\leftarrow r_\pi(s_t,a_t)+\gamma\mathbb{E}_{s_{t+1}\sim p,a_{t+1}\sim \pi}[Q(s_{t+1},a_{t+1})] Q(st,at)←rπ(st,at)+γEst+1∼p,at+1∼π[Q(st+1,at+1)]
(解释:
Q k + 1 ( s , a ) = r ( s , a ) + γ E s ′ ∼ p [ V ( s ′ ) ] Q^{k+1}(s,a)=r(s,a)+\gamma\mathbb{E}_{{s}'\sim p}[V({s}')]\quad Qk+1(s,a)=r(s,a)+γEs′∼p[V(s′)]其中 V ( s ′ ) = E a ′ ∼ π [ Q k ( s ′ , a ′ ) − α l o g ( π ( a ′ ∣ s ′ ) ) ] V({s}')=E_{{a}'\sim \pi}[Q^k({s}',{a}')-\alpha log(\pi({a}'|{s}'))]\quad V(s′)=Ea′∼π[Qk(s′,a′)−αlog(π(a′∣s′))](式子中没有出现alpha但是代码中是用了),两个式子合并得到
Q k + 1 ( s , a ) = r ( s , a ) + γ E s ′ ∼ p E a ′ ∼ π [ Q k ( s ′ , a ′ ) − l o g ( π ( a ′ ∣ s ′ ) ) ] = r ( s , a ) + γ E s ′ ∼ p E a ′ ∼ π [ Q k ( s ′ , a ′ ) ] + γ E s ′ ∼ p E a ′ ∼ π [ − l o g ( π ( a ′ ∣ s ′ ) ) ] Q^{k+1}(s,a)=r(s,a)+\gamma \mathbb{E}_{{s}'\sim p}\mathbb{ E}_{{a}'\sim \pi}[Q^k({s}',{a}')-log(\pi({a}'|{s}'))]=r(s,a)+\gamma\mathbb{E}_{{s}'\sim p}\mathbb{ E}_{{a}'\sim \pi}[Q^k({s}',{a}')]+\gamma \mathbb{E}_{{s}'\sim p} \mathbb{E}_{{a}'\sim \pi}[-log(\pi({a}'|{s}'))] Qk+1(s,a)=r(s,a)+γEs′∼pEa′∼π[Qk(s′,a′)−log(π(a′∣s′))]=r(s,a)+γEs′∼pEa′∼π[Qk(s′,a′)]+γEs′∼pEa′∼π[−log(π(a′∣s′))] = r ( s , a ) + γ E s ′ ∼ p E a ′ ∼ π [ Q k ( s ′ , a ′ ) ] + E s ′ ∼ p [ H ( π ( ⋅ ∣ s ′ ) ) ] = r(s,a)+\gamma \mathbb{E}_{{s}'\sim p}\mathbb{ E}_{{a}'\sim \pi}[Q^k({s}',{a}')]+\mathbb{E}_{{s}'\sim p}[H(\pi(\cdot|{s}'))] =r(s,a)+γEs′∼pEa′∼π[Qk(s′,a′)]+Es′∼p[H(π(⋅∣s′))] = r π ( s , a ) + γ E s ′ ∼ p E a ′ ∼ π [ Q k ( s ′ , a ′ ) ] =r_\pi(s,a)+\gamma \mathbb{E}_{{s}'\sim p}\mathbb{ E}_{{a}'\sim \pi}[Q^k({s}',{a}')] =rπ(s,a)+γEs′∼pEa′∼π[Qk(s′,a′)]也就是实际上(2)(3)式的定义等价于更新规则
)
Soft Policy Improvement:
策略更新: π n e w = a r g m i n D K L ( π ( ⋅ ∣ s t ) ∣ ∣ e x p ( Q π o l d ( s t , ⋅ ) ) Z π o l d ( s t ) ) ( 4 ) \pi_{new}=arg min D_{KL}(\pi(\cdot|s_t)||\frac{exp(Q^{\pi_{old}}(s_t,\cdot))}{Z^{\pi_{old}}(s_t)})\quad (4) πnew=argminDKL(π(⋅∣st)∣∣Zπold(st)exp(Qπold(st,⋅)))(4)这里是把 Q Q Q值函数转换为概率分布来表示策略,然后求策略和Q值策略的KL散度最小时的策略. 其中 π o l d ∈ ∏ \pi_{old}\in\prod πold∈∏, π n e w \pi_{new} πnew是最优化上式的策略也同样在策略空间 ∏ \prod ∏中,满足 Q π n e w ( s t , a t ) ≥ Q π o l d ( s t , a t ) Q^{\pi_{new}}(s_t,a_t)\geq Q^{\pi_{old}}(s_t,a_t) Qπnew(st,at)≥Qπold(st,at) for all ( s t , a t ) ∈ S × A (s_t,a_t)\in S\times A (st,at)∈S×A. 这样保证每次更新策略至少优于旧策略.
Final
软策略迭代过程(Soft policy Iteration):就是策略评估和策略改进两个过程不断迭代,最终策略会收敛到 π ∗ \pi^* π∗,满足 Q ∗ ( s t , a t ) ≥ Q π ( s t , a t ) Q^*(s_t,a_t)\geq Q^\pi(s_t,a_t) Q∗(st,at)≥Qπ(st,at) for all π ∈ ∏ a n d ( s t , a t ) ∈ S × A \pi\in\prod and (s_t,a_t)\in S\times A π∈∏and(st,at)∈S×A. 证明过程类似Sutton, Intriduction RL Chapter 4.
Soft Actor-Critic
上面的软策略迭代过程是基于tabular(表格式环境)来推导的,对于连续情况,就需要引入函数逼近。首先定义软状态值函数 V ψ ( s t ) V_\psi(s_t) Vψ(st),软 Q Q Q值函数 Q θ ( s t , a t ) Q_\theta(s_t,a_t) Qθ(st,at),策略函数 π ϕ ( a t ∣ s t ) \pi_{\phi}(a_t|s_t) πϕ(at∣st)(注意是个随机策略)。对应的参数分别是 ψ , θ , ϕ \psi,\theta,\phi ψ,θ,ϕ.
软状态值函数的目标函数是:
![]()
梯度:
![]()
软 Q Q Q值函数的目标函数是:
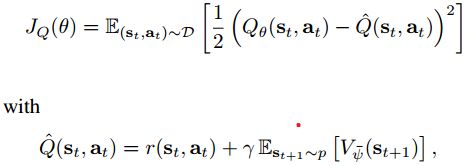
梯度:
![]()
注意这里的target网络只使用了一个 V ψ ˉ V_{\bar{\psi}} Vψˉ.
策略更新的目标函数:
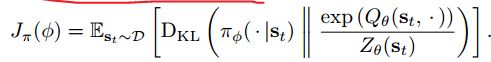
这里策略表示为带噪声的神经网络:
![]()
其中 ε \varepsilon ε是输入的噪声向量。那么策略的目标函数可以重新写成(这个式子是原目标函数省略了 Z θ ( s t ) Z_\theta(s_t) Zθ(st),因为它是与 ϕ \phi ϕ无关的量,求导为0,对梯度无影响所以省略了。KL散度计算):
![]()
对上式求导(把期望去掉,因为期望通过多次批量抽样实现)得梯度:
算法:
