对于爬虫的这几点,你没认真整理了解过

首先,爬虫不是我的本职工作,我爬虫是为了工作而准备的,但爬虫内容真的很多:静态页面、动态页面、JS 加密、App 加密、逆向工程等等,对于这么一篇文章来说,我希望对你学习爬虫有一些帮助。
1. 准备工作
在具体分享之前,我也要教你如何安装 Postman。
1.1 下载 Postman
Postman 一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如 Jmeter、soapUI 等。不过,对于开发过程中去调试接口,Postman 确实足够的简单方便,而且功能强大。
官方网站:https://www.postman.com/

下载也很简单,如果这一步不会的话,也可以加小编好友拉你进交流群!微信号:AndersonHjb,添加小编好友的时候记得来者目的,24h 内通过。
对于安装包,官网下载较慢,小伙伴还可以从蓝奏云下载,也是最新版本(2020),公众号后台回复:postman,即可。
1.2 安装
-
Postman 最早是作用 chrome 浏览器插件存在的,所以,你可以到 chrome 商店搜索下载安装,因为重所周知的原因,所以,大家都会找别人共享的 postman 插件文件来安装。由于 2018 年初 Chrome 停止对Chrome应用程序的支持。
-
Postman 提供了独立的安装包,不再依赖于 Chrome 浏览器了。同时支持 MAC、Windows 和 Linux,推荐你使用这种方式安装。
一般我的爬虫流程是这样的:
-
浏览器访问待爬网页,并提前打开开发者工具(
F12),选中Nework选项卡,这样就可以看到网络交互信息;或者,右键查看网页源代码,查找目标信息。 -
在网络交互信息流中筛选出自己需要的,然后在
postman中模拟请求,看是否仍然可以获取到想要的信息;Postman 除了可以进行请求测试外,还有一个优势就是,代码可以直接生成,这样就可以方便得进行最终的整合了。 -
数据解析,从请求的响应中解析出我们的目标数据,至于得到数据后如何处理,那就是你的事情了。
下面就以大家耳熟能详的豆瓣电影 TOP250 为例。
2. 实例分析
2.1 请求梳理
首先,我们要访问待爬取的网页:https://movie.douban.com/top250。
一般情况下,我都是直接按下 F12 调出 DevTools,点击 Network 选项卡:
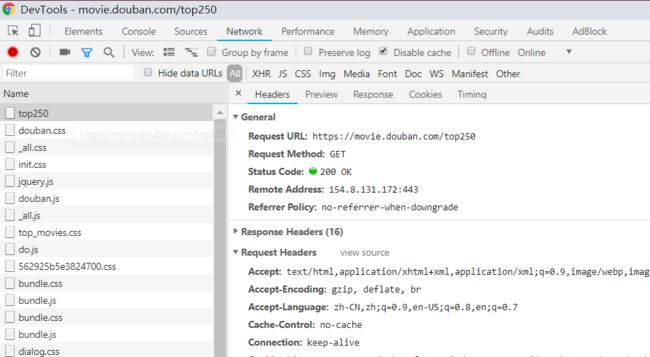
有时请求已经加载完成了,可以把数据全部 clear 掉,然后重新刷新网页,这时候请求流会重新加载。
这里有几个点需要注意,主要是下图圈红的几个:

我一般是把上面的几点勾选起来。
-
有些网页请求会有自动跳转,这是请求流会重新加载,这是勾选了
Preserve log的话,数据就会持续打印,不会被冲掉;(也就是,你有可能在等待加载的时候,结果正式要去分析的时候却消失了) -
勾选
Disable cache可以禁用缓存; -
请求流的筛选:
XHR是 XMLHttpRequest 的意思,大多数情况下只要点击 XHR 就行了,但是若此时发现没有想要的请求数据,那么就要点击All展示所有请求流。
比如豆瓣的这个,XHR 中是没有我们的目标请求的。

2.2 请求模拟
通过上面的步骤,我们能够确定通过哪些请求能够得到我们的目标数据,然后把这些请求放到 postman 中进行模拟。
比如,我们在 postman 中访问豆瓣的网站:

这里的请求比较简单,直接 get url 就能获取到目标数据。
其实大部分情况下,都是需要添加一些访问参数的,这是我们可以在 Headers 里添加。
另外,postman 还支持其他请求,如 post、delete 等等:

- 生成代码
点击右侧的 code 按钮,就可以获取到对应的代码:
支持生成多种语言的代码,操作动图如下:
比如,我们这里选择 Python Requests,就可以得到如下代码:
url = "https://www.aiyc.top/"
import requests
url = "https://www.aiyc.top/"
payload = {}
headers = {
'Cookie': 'e21622aacc25df990a6b262591f2c098latest_time_id=91'
}
response = requests.request("GET", url, headers=headers, data = payload)
print(response.text.encode('utf8'))
url = "https://movie.douban.com/top250"
import requests
url = "https://movie.douban.com/top250"
headers = {
'cache-control': "no-cache",
'postman-token': "d2e1def2-7a3c-7bcc-50d0-eb6baf18560c"
}
response = requests.request("GET", url, headers=headers)
print(response.text)
这样我们只要把这些代码合并到我们的业务逻辑里就行了,当然其中的 postman 相关的参数是不需要的。
2.3 数据解析
下面要做的就是从响应中解析目标数据。
有些响应是返回 HTML,有些是返回 json 数据,有的还是返回 XML,当然也有其他的,这就需要不同的解析逻辑。
具体如何解析,这里我们不再赘述,之前的爬虫文章中都有涉及,有兴趣的可以翻一翻。
3. 总结
本来打算写 postman 的使用的,但是写来写去,成了我的一般爬虫流程梳理。
本文涉及的爬虫都是比较初级的,至于 ip 代理、验证码解析等高端功能,后面有会慢慢出来还会手把手教学搭建代理池(包括代理评分等等)如果,本文 在看 超过 20 我就写出来。
不知道你的一般流程是什么样的,不妨留言分享下。(点击阅读原文,在我的博客下留言噢!期待和你的交流)