python-web框架Flask-(11)requests
requests模块是用来发送http请求的,返回响应结果,需要安装:
创建虚拟环境我用的是pipenv,所以使用pipenv来安装:
(1)进入虚拟环境:pipenv shell
(2)安装requests:pipenv install requests
(3)导入requests模块:import requests
Requests.get( ) 请求
import requests
url = 'https://api.github.com/events'
r = requests.get(url)
print(r) # 返回的是一个Response对象 上边调用get方法,返回的是一个Response对象,我们可以从这个对象中获取所有我们想要的信息。
Requests.post( ) 请求
import requests
url_1 = 'https://httpbin.org/post'
r = requests.post(url_1,data={'key':'value'})
print(r) # 返回的是一个Respons对象 ( 一 )发送表单(dict)形式的数据
上边调用post方法,与get一样,但参数二可以接受参数data,值是一个字典。(可联想到表单post提交数据)数据字典在发出请求时,会自动编码为表单形式。。。
( 二 )发送字符串形式的数据
很多时候,发送的数据并非是表单形式的数据,如果是字符串形式的数据string而非dict,name数据会被直接发布出去:
import requests,json
url = 'https://api.github.com/some/endpoint'
dict_data = {"name":"lxc"}
r = requests.post(url,data=json.dumps(dict_data))上边代码,使用json.dumps( ) 把数据解析为json格式的字符串,发送出去。
( 三 )直接使用json参数发送数据
也可以直接使用json参数,它可以把数据直接解析成json格式的字符串。
import requests,json
url = 'https://api.github.com/some/endpoint'
dict_data = {"name":"lxc"}
r = requests.post(url,json=dict_data)
URL参数传递
如果你想传递 参数,Response允许你使用params关键字参数,值是字典类型。
如:传递 key1 = value1,key2 = value2 参数到 https://httpbin.org/get ,你可以这样做:
import requests
url_1 = 'https://httpbin.org/get'
payload = {"key":'value','key1':'value1'}
r = requests.get(url_1,params=payload)
print(r.url) # https://httpbin.org/get?key=value&key1=value1
上边代码,Response对象上边有一个 url方法,可输出完整的url 路径。。。
还可以将值为列表的字典传入:
import requests
url_1 = 'https://httpbin.org/get'
payload = {"key":'value','key1':['1','2']}
r = requests.get(url_1,params=payload)
print(r.url) # https://httpbin.org/get?key=value&key1=1&key1=2Request.text 方法
text方法,是返回值 Response对象中的一个方法,可以返回请求页面的内容(http的响应内容 - 字符串类型);当我们调用Response.text时,Requests会基于HTTP头部对响应的编码做出推测,Requests会使用推测出来的文本编码,解码来自服务器的内容。大多数的unicode字符集都能被无缝解码!!!
import requests
url = 'http://www.baidu.com/'
r = requests.get(url)
print(r.text)
# 打印结果
#
#
#
#
#
#
# ç¾åº¦ä¸ä¸ï¼ä½ å°±ç¥é
# ··· ···上边代码,我们使用text方法输出的标签的内容是乱码!!!现在可以改变下载得到的页面的编码,就可以正常打印出"友好的"文本了。
先来查看下 Requests推测出来的文本编码(也就是Requests使用的什么编码):
import requests
url = 'http://www.baidu.com/'
r = requests.get(url)
print(r.encoding) # ISO-8859-1现在我们使用 r.encoding 来改变编码格式,可以看到打印结果正常了:
import requests
url = 'http://www.baidu.com/'
r = requests.get(url)
r.encoding = "utf-8" # 修改编码格式
print(r.encoding) # utf-8 Requests都将使用修改后的编码进行解码
print(r.text)
# 打印结果
#
#
#
#
#
# 百度一下,你就知道
# ··· ···官方文档:如果你改变了编码,每当你访问 r.text , Requests 都会使用 r.encoding 的新值。。。
补充下:
现在一般网站在response headers的Content-Type中会指定编码类型:(如:下边csdn网页响应头中,添加了指定编码)
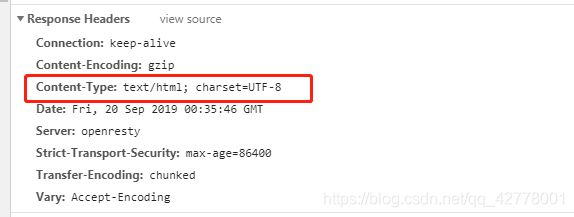
在找一个没有指定编码类型的网站:(电影天堂)
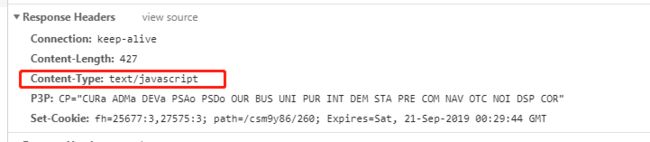
import requests
url = 'http://www.dytt8.net/index.htm'
r = requests.get(url)
print(r.encoding) # ISO-8859-1
print(r.text[200:300]) # 截取电影天堂title标签里的内容
# 输出结果
# -Type content="text/html; charset=gb2312">
# µçÓ°ÌìÌÃ_Ãâ·ÑµçÓ°_ѸÀ×µçÓ°ÏÂÔØ
#
上边代码,我们截取了电影天堂title标签的内容,由于网页不规范,没有指定编码格式,英文可以正常解码,但是解码中文就会出现乱码!!!
r.encoding 之所以 输出的编码是 ISO-8859-1 ,是因为———《HTTP权威指南》里第16章国际化里提到,如果HTTP响应中Content-Type字段没有指定charset,则默认页面是'ISO-8859-1'编码。
对于没有指定编码类型的网站,解决方案:
(1)使用 response . encoding 来指定 编码格式,调用response.text时,会根据你设定的编码格式来对网页进行解码。
r.encoding = "gb2312"
(2)使用 response . apparent_encoding 获得真实编码,程序自己会从内容中分析出编码(比较慢)
r.encoding = r.apparent_encoding

Request.content( )方法
r.content 返回的是 bytes 类型原始类型的数据:
import requests
url = 'https://movie.douban.com/'
r = requests.get(url)
print(r.content)
# ··· \xe8\xb1\x86\xe7\x93\xa3\xe7\x94\xb5\xe5\xbd\xb1\n
#
# ··· ···
想要把bytes变为str,需要使用 decode()方法
import requests
url = 'https://movie.douban.com/'
r = requests.get(url)
print(r.content.decode())
# 可以正常打印了 。。。
Request.json( )方法
request.json( ) 方法 会自动将json数据转换成python对应的数据,注意下:
使用此方法来解码数据时,有时候会报错:
报错信息:JSONDecodeError("Expecting value", s, err.value) from None json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)

这种报错信息的原因是:http请求返回的数据不是json格式的,而你却使用了json解析函数在处理,所以报错了!!!
import requests
url = 'http://www.qq.com/'
r = requests.get(url)
print(r.json()) # 报错
如果你不清楚api返回的数据是否是json格式的,不能直接使用r.json ,需要判断:
import requests,json
url = 'http://www.dytt8.net/index.htm'
r = requests.get(url)
# 判断状态码是否为200
def status_is_200(r):
if r.status_code == 200: #判断状态码
return r.text
sta = status_is_200(r)
#判断是否是json格式
def is_json(params):
try:
r = json.loads(params)
return r
except Exception as e:
print(type(Exception)) #
print(isinstance(e,Exception)) # True
print(e.__class__.__name__) # JSONDecodeError
print("不是json格式的数据") # "不是json格式的数据"
is_json(sta)
上边代码,之所以要判断状态码,是因为:有的服务器会在失败的响应中包含一个 JSON 对象(比如 HTTP 500 的错误细节)。这种 JSON 也会被解码返回,但是返回的状态码不是200。所以,开始判断状态码是否等于200 是有必要的;假设请求成功,结果会传到下边is_json( ) 函数中,在函数内,如果数据是json格式的,会直接返回解析好的python数据;如果失败,则会抛出异常,输出 "不是json格式的数据" 。
抛出的异常,会被except 捕获到,如果不知道异常类型,可使用:Exception类来代替,因为所有的异常都是类Exception的成员。所有异常都从基类Exception继承的;
捕获异常之后,如果需要访问异常类的一些属性,可以使用as关键字,e是异常类的实例(也就是Exception类的实例);上边我们输出了异常的类型。
订制请求头
先看下官方文档:
可以为HPPT请求添加头部,只要传递字典(dict)类型的参数给headers参数即可:
import requests
url = 'https://api.github.com/some/endpoint'
dict_data = {"user-agent":"app/0.0.2"}
r = requests.post(url,headers=dict_data)
关于订制请求头有以下几点注意的地方:
- 如果被重定向到别的主机,订制的 header 就会被删除。
- 所有的 header 值必须是
string、bytestring 或者 unicode。
在实际开发应用:
爬虫获取页面信息。在请求某些网页的时候,有时会禁止你爬取,需要通过反爬机制来解决这个问题:
headers是解决requests请求禁止爬取的方法之一,相当于我们进到这个网站的服务器中,假装自己本身在爬取数据!!!
对于反爬网页,可以设置一些headers信息,模拟成浏览器去访问网页。。。
import requests
url = 'https://baike.so.com/doc/24386561-25208408.html'
dict_data = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3730.400 QQBrowser/10.5.3805.400"
}
r = requests.post(url,headers=dict_data)
r.encoding = "utf-8"
print(r.text[245:337])
# 我截取了一部分数据,输出结果:
#
上边代码,爬取的是360百科的数据;设置了user-agent,结果爬取数据成功,我是截取了一部分标签数据。(不设置请求头,返回的是空值!!!可以试下)
补充下:上边之所以要设置编码格式r.encoding = "utf-8",因为360百科在响应头Response headers 中的content-type中没有设置编码格式!!!
响应状态码
通过Response对象中的status_code 可获得响应的状态码:
import requests,json
url = 'http://httpbin.org/get'
r = requests.get(url)
print(r.status_code) # 200
响应头的获取
通过Response对象中的headers可获得响应头的信息:
import requests
url = 'http://httpbin.org/get'
r = requests.get(url)
print(r.headers)
# 输出结果:
'''
{
'Access-Control-Allow-Credentials': 'true',
'Access-Control-Allow-Origin': '*',
'Content-Encoding': 'gzip',
'Content-Type': 'application/json',
'Date': 'Sun, 22 Sep 2019 02:50:51 GMT',
'Referrer-Policy': 'no-referrer-when-downgrade',
'Server': 'nginx',
'X-Content-Type-Options': 'nosniff',
'X-Frame-Options': 'DENY',
'X-XSS-Protection': '1; mode=block',
'Content-Length': '183',
'Connection': 'keep-alive'
}
上边代码,headers 输出了响应头所有内容,,注意:HTTP 头部是大小写不敏感的。
我们可以像访问字典一样去访问响应头中的信息:
print(r.headers['content-type']) # 'application/json'
print(r.headers.get('content-type')) # 'application/json'
Cookie
1、r.cookie
先来看下官方文档:
如果某响应中包含cookie,你可以快速访问他们:
import os
from flask import Flask,render_template,session
app = Flask(__name__)
app.config['SECRET_KEY'] = os.urandom(24)
@app.route("/login")
def fn():
session['name'] = 'lxc'
return render_template('http.html')
if __name__ == "__main__":
app.run(debug=True)
上边代码,我用flask搭建了一个简易服务,当访问http://127.0.0.1:5000/login 时,会设置一个session值,在flask中,会把session存到cookie中;
import requests
url = 'http://127.0.0.1:5000/login'
r = requests.get(url)
print(r.headers)
# 输出结果
'''
{
'Content-Type': 'text/html; charset=utf-8',
'Content-Length': '297',
'Vary': 'Cookie',
'Set-Cookie': 'session=eyJuYW1lIjoibHhjIn0.XYcEkA.VgHhnQN0YlGXUxXHM0Fxb0JVLow; HttpOnly; Path=/',
'Server': 'Werkzeug/0.15.6 Python/3.7.4',
'Date': 'Sun, 22 Sep 2019 05:20:16 GMT'
}
'''
print(r.cookies['session'])
# 取cookie中的值,值是加密之后
# eyJuYW1lIjoibHhjIn0.XYcEkA.VgHhnQN0YlGXUxXHM0Fxb0JVLow
我们可以用r.cookie 来取数据中的cookie值,
2、发送cookie到服务器,可以使用cookies参数
import requests
url = 'http://127.0.0.1:5000/sendcookie'
cookie_data = {'name':'lvxingchen'}
r = requests.post(url,cookies=cookie_data)
以上就是requests基础方法,以后我会不断更新,补充。。。