Flink:动态表上的连续查询
用SQL分析数据流
越来越多的公司在采用流处理技术,并将现有的批处理应用程序迁移到流处理或者为新的应用设计流处理方案。其中许多应用程序专注于分析流数据。分析的数据流来源广泛,如数据库交易,点击,传感器测量或物联网设备。
Apache Flink非常适合流式分析,因为它提供了事件时间语义支持,恰一次的处理,并同时实现了高吞吐和低延迟。由于这些特性,Flink能够近乎实时地从大量输入流计算确切的和确定性的结果,同时在出现故障时提供恰一次处理的语义。
Flink的流处理核心API,DataStream API,非常具有表现力,并为许多常见操作提供原语。除了其他功能之外,它还提供高度可定制的窗口逻辑,具有不同性能特性的不同状态原语,用于注册和响应定时器的钩子,以及用于向外部系统提供高效异步请求的工具。另一方面,许多流分析应用程序遵循类似的模式,并且不需要DataStream API提供的表达级别。他们可以使用特定领域语言以更自然和简洁的方式表达。众所周知,SQL是数据分析的事实标准。对于流式分析,SQL可以让更多的人在更短的时间内在数据流上开发应用程序。但是,还没有开源流处理器提供全面良好的SQL支持。
为什么Streams上的SQL是一个大问题?
由于许多原因,SQL是数据分析中使用最广泛的语言:
• SQL是声明式的:你指定你想要的,但不知道如何计算它。
• SQL可以得到有效优化:优化器会生成一个良好的执行计划来计算结果。
• 可以高效地评估SQL:处理引擎确切地知道要计算什么以及如何有效地执行此操作。
• 最后,大家都知道,许多工具都会讲SQL。
因此,能够使用SQL处理和分析数据流,使流处理技术可供更多用户使用。此外,由于SQL的声明性和自动优化的潜力,它大大减少了开发高效流分析应用程序的时间和精力。
但是,SQL(以及关系数据模型和代数)设计的时候并没有考虑到流式数据。关系是(多)集合,而不是无限的元组序列。在执行SQL查询时,传统的数据库系统和查询引擎将读取并处理完整可用的数据集,并生成固定大小的结果。相反,数据流不断提供新的记录,使得数据随着时间的推移而到达。因此,流式查询必须持续处理到达的数据,而不是“完整的数据”。
这就是说,用SQL处理流并不是不可能的。一些关系数据库系统具有物化视图的急切维护功能,这类似于评估数据流上的SQL查询。物化视图与常规(虚拟)视图一样被定义为SQL查询。但是,物化视图查询的结果实际上是存储(或物化)在内存或磁盘上的,这样查询不需要在查询时即时计算。为了防止物化视图变旧,数据库系统需要在其基本关系(定义查询中引用的表)被修改时更新视图。如果将视图基础关系的修改视为修改流(或者视为变更日志流),很明显就是在流上的物化视图为何和sql在某种程度上是相关的。
FlinkAPI:表API和SQL
自2016年8月发布1.1.0版本以来,Flink具有两种语义等效的关系API,嵌入语言(language-embedded)的Table API(用于Java和Scala)和标准SQL。这两个API都被设计为实时处理和离线批处理的统一API。这意味着,
无论其输入是静态批量数据还是流式数据,查询都会产生完全相同的结果。
出于多种原因,流和批处理的统一API非常重要。首先,用户只需要学习一个API来处理静态和流式数据。此外,可以使用相同的查询来分析批量和流式数据,从而可以在同一查询中共同时分析历史数据和实时数据。在目前的状态下,我们尚未实现批量和流式语义的完全统一,但社区在实现这一目标方面正取得很好的进展。
以下代码片段显示了两个等效的Table API和SQL查询,这些查询计算温度传感器测量流上简单的窗口集合。SQL查询的语法基于Apache Calcite的分组窗口函数的语法,并将在Flink的1.3.0版中得到支持。
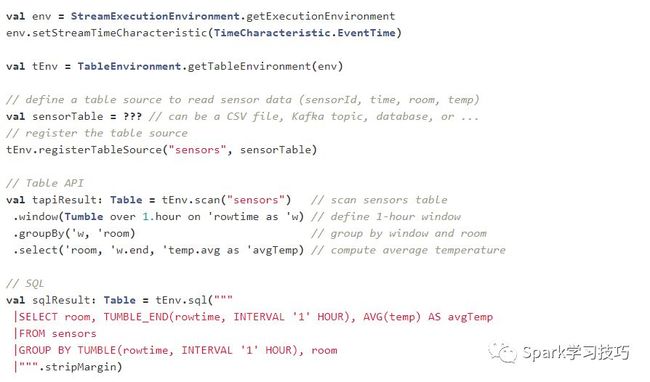
正如您所看到的,这两个API都彼此紧密集成,并与Flink的主要DataStream和DataSet API 紧密集成。一个Table可以生成于一个DataSet或DataStream,也可以转换成一个DataSet或DataStream。因此,可以轻松扫描外部表源(如数据库或Parquet文件),使用Table API查询执行一些预处理,将结果转换为DataSet并在其上运行Gelly图算法。以上示例中定义的查询也可以用于通过更改执行环境来处理批处理数据。
在内部,两个API都被翻译成相同的逻辑表示,并由Apache Calcite进行优化,并编译到DataStream或DataSet程序中。实际上,优化和编译过程并不知道查询是使用Table API还是SQL来定义的。由于Table API和SQL在语义方面是等价的,而且只有语法不同,所以当我们在这篇文章中讨论SQL时,我们总是引用这两个API。
在当前状态(版本1.2.0)中,Flink的关系API支持数据流上有限的一组关系运算符,包括projections,过滤器和窗口聚合(projections, filters, and windowed aggregates)。所有支持的操算子都有共同之处:他们从不更新已经发布的结果记录。对于projection and filter等一次性记录操作算子来说,这显然不是问题。但是,它会影响收集和处理多个记录的操作算子,例如窗口聚合。由于发布的结果无法更新,因此在Flink 1.2.0中必须丢弃在结果发布后到达的输入记录。
对于向存储系统发送数据的应用程序(如Kafka主题,消息队列或仅支持追加操作且不更新或删除的文件),当前版本的限制是可接受的。遵循此模式的常见用例是例如连续ETL和流归档应用程序,这些应用程序将流保存到归档或为进一步联机(流式)分析或后续离线分析准备数据。由于无法更新之前发布的结果,因此这些类型的应用程序必须确保发布的结果是正确的,并且将来不需要进行更正。下图说明了这些应用程序。
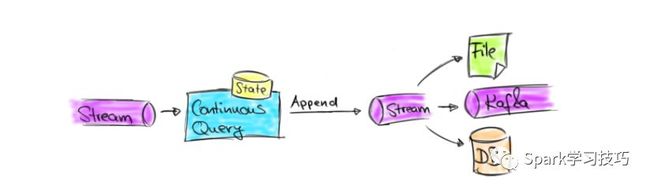
虽然仅支持追加的查询对于某些类型的应用程序和特定类型的存储系统很有用,但有很多流分析用例需要更新结果。这包括流式处理应用程序,这些应用程序不能丢弃迟到的记录,需要(长时间运行的)窗口化聚合的早期结果,或需要非窗口聚合。在每种情况下,以前发出的结果记录都需要更新。结果更新查询通常会将其结果实现为外部数据库或键值存储,以便外部应用程序可以访问并进行查询。实现这种模式的应用程序是仪表板,报告应用程序或其他应用程序,这需要及时获得不断更新的结果。下图说明了这些类型的应用程序。
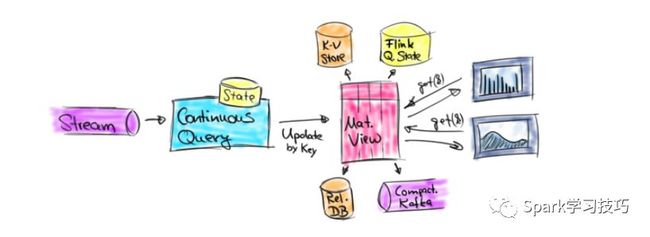
动态表上的连续查询
支持更新先前发布结果的查询是Flink关系API的下一个重要步骤。此功能非常重要,因为它大大增加了API的范围和支持的用例范围。
因此,当添加对结果更新查询的支持时,我们当然必须保留流和批输入的统一语义。我们通过动态表的概念来实现这一点。动态表是一个不断更新的表,可以像常规的静态表一样查询。但是,与作为结果终止并返回静态表的批处理表相比,对动态表的查询连续运行,并生成一个根据输入表上的修改不断更新的表。因此,结果表也是一个动态表。这个概念与我们之前讨论的物化视图维护非常相似。
假设我们可以在产生新动态表的动态表上运行查询,下一个问题是,流和动态表如何相互关联?答案是可以将流转换为动态表,并将动态表转换为流。下图显示了在流上处理关系查询的概念模型。

首先,将流转换为动态表。使用连续查询来查询动态表,从而生成新的动态表。最后,结果表转换回流。需要注意的是,这只是逻辑模型,并不意味着查询是如何实际执行的。实际上,连续查询在内部翻译成传统的DataStream程序。
在下面,我们描述这个模型的不同步骤:
1. 在一个流上定义一个动态表,
2. 查询动态表
3. 发出动态表格。
在流上定义动态表
评估动态表上的SQL查询的第一步是在流上定义一个动态表。这意味着我们必须指定流的记录如何修改动态表。流携带的记录必须有一个schema,该schema可以映射到表的关系schema。有两种模式可以在流上定义动态表:追加模式和更新模式。
在追加模式下,每个流记录都是对动态表的插入修改。因此,流的所有记录都会追加到动态表中,使其不断增长并且大小无限。下图说明了追加模式。
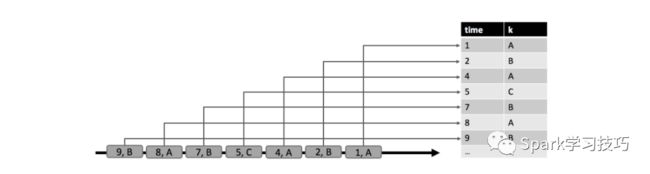
在更新模式下,流记录可以表示对动态表的插入,更新或删除修改(追加模式实际上是更新模式的特例)。当通过更新模式在流上定义动态表时,我们可以在表上指定唯一的键属性。在这种情况下,更新和删除操作是针对key属性执行的。更新模式在下图中显示。

查询动态表
一旦我们定义了一个动态表,我们就可以在其上运行查询。由于动态表随时间而改变,因此我们必须定义查询动态表的含义。让我们想象一下,我们在特定的时间点拍摄动态表格的快照。此快照可以视为常规静态批处理表。我们将动态表A在点t处的快照表示为A [t]。快照可以用任何SQL查询来查询。查询生成一个常规的静态表作为结果。我们将在时间t的动态表A上的查询q的结果表示为q(A [t])。如果我们重复计算查询动态表快照的结果以获得进展时间点,我们将获得许多随时间变化的静态结果表,并有效地构成一个动态表。我们在动态表中定义一个查询的语义如下。
动态表A上的查询q产生动态表R,其在每个时间点t等于在A [t]上应用q的结果,即R [t] = q(A [t])。这一定义意味着在一个批处理表上运行在相同的查询q,并在流表产生相同的结果。在下面,我们给出两个例子来说明动态表上查询的语义。
在下图中,我们在左侧看到一个动态输入表A,它在追加模式下定义。在t = 8时,A由六行(蓝色)组成。在时间t = 9和t = 12,分别有一行被追加到A(分别以绿色和橙色显示)。我们在表A上运行一个图中心显示的简单的查询。查询按属性k分组并统计每组的记录。在右侧,我们看到在时间t = 8(蓝色),t = 9(绿色)和t = 12时查询q的结果(橙子)。在时间t的每个时间点,结果表等同于在时间t时动态表A上的批量查询。
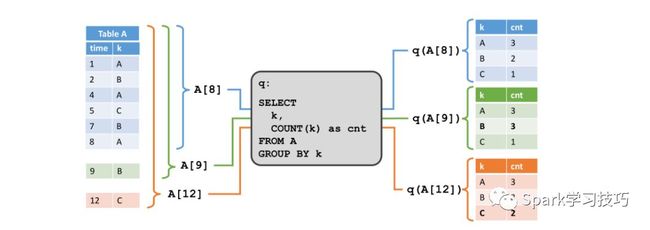
这个例子中的查询是一个简单的分组(但没有窗口)聚合查询。因此,结果表的大小取决于输入表的不同分组键的数量。此外,值得注意的是,查询不断更新它先前发出的结果行,而不是仅添加新行。
第二个例子展示了一个类似的查询,它在一个重要方面有所不同 除了在关键属性k上进行分组之外,查询还将记录分组到五秒钟的滚动窗口中,这意味着它计算每五秒每个k值的计数。再次,我们使用Calcite的组窗口函数来指定此查询。在图的左侧,我们看到输入表A以及它在追加模式下随时间变化的情况。在右侧,我们看到结果表以及它随着时间的变化。
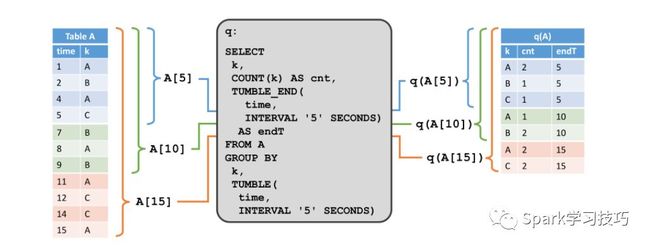
与第一个例子的结果相反,结果表相对于时间增长,即每5秒钟计算一次新的结果行(假设输入表在过去5秒内接收到更多记录)。尽管非窗口化查询(主要)更新结果表的行,但窗口化聚合查询仅将新行追加到结果表中。
尽管这篇博文主要关注动态表上的SQL查询的语义,而不是关于如何有效地处理这样的查询,但我们想指出,每当更新输入表时,不可能从头开始计算查询的完整结果。相反,查询被编译为一个流式处理程序,它根据输入的变化不断更新其结果。这意味着并非所有有效的SQL查询都受支持,但只有那些可以连续,增量和有效计算的SQL查询才受支持。我们计划在后续博客文章中讨论有关动态表上SQL查询评估的详细信息。
发出动态表格
查询动态表将生成另一个动态表,它表示查询的结果。根据查询及其输入表,结果表通过插入,更新和删除来持续修改,就像常规数据库表一样。它可能是一个带有单个行的表,它不断更新,只有插入表而没有更新修改,或者两者都有。
传统数据库系统在发生故障和复制时使用日志来重建表。有不同的日志记录技术,如UNDO,REDO和UNDO / REDO日志记录。简而言之,UNDO日志记录修改元素的先前值以恢复未完成的事务,REDO日志记录已修改元素的新值以redo丢失的已完成事务的更改,UNDO / REDO日志记录一个变更的元素旧值和新值来撤消未完成的事务和redo已完成的事务的丢失变更。根据这些日志记录技术的原理,可以将动态表格转换为两种类型的更新日志流,即REDO流和REDO + UNDO流。
通过将表中的修改转换为流消息,将动态表转换为redo+undo流。插入被发射作为带新的行的插入消息,删除修改被发射作为带有旧的行的删除消息,并且更新修改被发射作为带有旧的行的删除消息,并且与新的行的插入消息。下图说明了此行为。
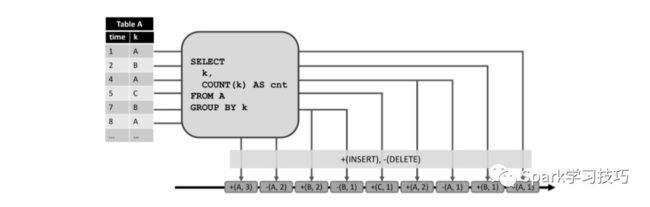
左边显示了一个动态表格,该表格以追加模式维护,并作为图中心查询的输入。查询结果转换为底部显示的redo + undo流。输入表的第一条记录(1,A)会在结果表中产生一条新记录,并因此在流中插入消息+(A,1)。具有k ='A' (4,A)的第二输入记录在结果表中产生(A,1)记录的更新,并因此产生删除消息- (A,1)和插入消息+(A ,2)。所有下游操作算子或数据接收器都需要能够正确处理这两种类型的消息。
在两种情况下,动态表可以转换为redo流:它可以是仅追加表(即仅具有插入修改),也可以具有唯一键属性。动态表上的每个插入修改都会生成一条插入消息,并将新行添加到redo流中。由于redo流的限制,只有具有唯一键的表可以进行更新和删除修改。如果从键控动态表中删除键,或者因为行被删除或因为行的键属性被修改了,则删除键中的删除键被发送到redo流。更新修改产生带有更新的更新消息,即新行。由于删除和更新修改是针对唯一key定义的,因此下游操作员需要能够通过key访问先前的值。下图,展示了相同查询的结果表是如何转化为一个redo流的。
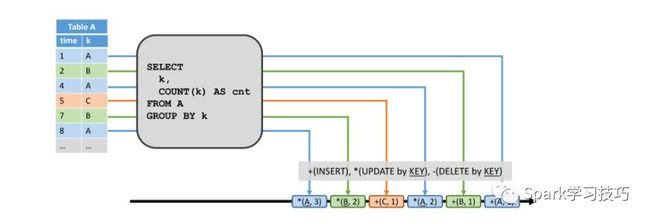
产生插入到动态表中的行(1,A)导致+(A,1)插入消息。产生更新的行(4,A)产生*(A,2)更新消息。
redo流的常见用例是将查询结果写入仅追加存储系统,如滚动文件或Kafka主题,或者写入具有key访问特性的数据存储区,如Cassandra,关系型数据库或压缩kafka话题。还可以将动态表实现为流式应用程序内部的keyed状态,以评估连续查询并使其可从外部系统进行查询。通过这种设计,Flink自身维护流中持续SQL查询的结果,并在结果表上提供key查找,例如从仪表板应用程序中进行查找。
切换到动态表格后会发生什么变化?
在版本1.2中,Flink的关系API的所有流式运算符(如过滤器,项目和组窗口聚合)仅发出新行并且无法更新以前发出的结果。相比之下,动态表格能够处理更新和删除修改。现在你可能会问自己:当前版本的处理模型与新的动态表模型有什么关系?API的语义是否会彻底改变?我们是否需要从头开始重新实现API以实现所需的语义?
所有这些问题的答案都很简单。当前的处理模型是动态表模型的一个子集。使用我们在这篇文章中介绍的术语,当前模型将流转换为追加模式下的动态表格,即无限增长的表格。由于所有运算符只接受插入更改并在其结果表上产生插入更改(即发出新行),所有受支持的查询都会生成动态追加表,这些追加表将使用redo模型转换回DataStreams,用于追加表。因此,当前模型的语义被新的动态表模型完全覆盖和保存。
结论和展望
Flink的关系型API能够很快实施流分析应用程序并用于多种生产环境。在这篇博文中,我们讨论了Table API和SQL的未来。这一努力将使更多人能够访问Flink和流处理。此外,用于查询历史和实时数据的统一语义以及查询和维护动态表的概念将使许多令人兴奋的用例和应用程序的实现变得非常容易。由于本文主要关注流和动态表上的关系查询的语义,因此我们没有讨论如何执行查询的详细信息,其中包括内部执行回收,处理迟发事件,支持早期结果以及边界空间要求。
最近几个月,Flink社区的许多成员一直在讨论和贡献关系API。迄今为止我们取得了很大的进展 虽然大多数工作都侧重于以追加模式处理流,但议程上的下一步是处理动态表以支持更新其结果的查询。如果您对使用SQL处理流的想法感到兴奋并希望为此付出努力,请提供反馈,加入邮件列表中的讨论,或者抓住JIRA问题进行工作。
原文阅读,请点击阅读原文。
推荐阅读:
1,Spark Streaming 中管理 Kafka Offsets 的几种方式
2,Flink DataSet编程指南-demo演示及注意事项
3,构建Flink工程及demo演示
4,Flink系列之时间
如果,Google 早已解决不了你的问题。
如果,你还想知道 Apple、Facebook、IBM、阿里等国内外名企的核心架构设计。
来,我们在深圳准备了知识星球,想助你成长: