学习笔记 | Apollo Udacity自动驾驶课程笔记——规划、控制
点击上方“AI算法修炼营”,选择加星标或“置顶”
标题以下,全是干货
这是学习笔记的最后一篇,感兴趣的可以关注之前的系列文章:一、高精度地图、厘米级定位、二:感知、预测
5
规划
1、路径规划使用三个输入,第一个输入为地图,Apollo提供的地图数据包括公路网和实时交通信息。第二个输入为我们当前在地图上的位置。第三个输入为我们的目的地,目的地取决于车辆中的乘客。
2、将地图转为图形
该图形由“节点”(node)和“边缘”(edge)组成。节点代表路段,边缘代表这些路段之间的连接。我们可以对一个节点移动到另一个节点所需的成本进行建模。

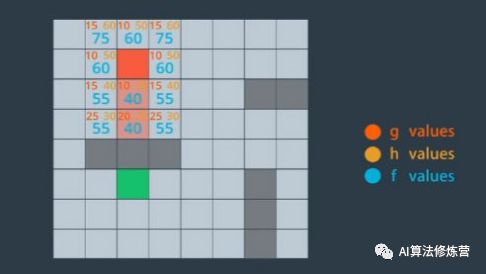
3、路径查找算法A*
从初始节点开始,我们需要确定8个相邻节点中,哪个是最有希望的候选节点。对于每个候选节点,我们考虑两件事情。首先,我们计算从开始节点到候选节点的成本。然后,我们估计从候选节点前往目的地的成本。对于每个候选节点,我们通过添加g值和h值来计算总和,即f值。最佳候选节点是f值最小的节点。
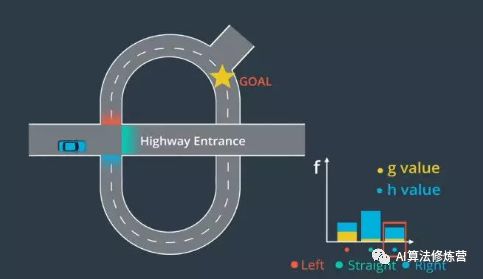
4、轨迹生成
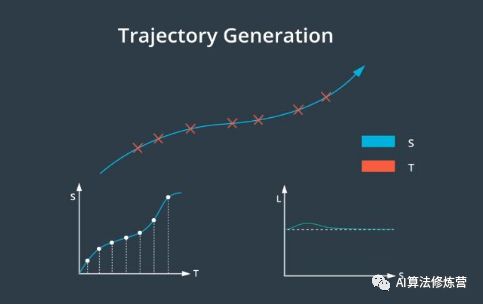
1、我们可能需要与试图在我们前面掉头的汽车互动,或者我们可能希望超过一辆在公路上行驶的慢车。这些场景需要更低级别、更高精确度的规划。我们将这一级别的规划称为轨迹生成。轨迹生成的目标是生成一系列路径点所定义的轨迹。
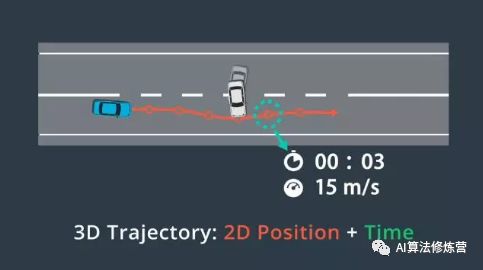
2、每个路径点分配了一个时间戳和速度,这些时间戳和空间上的两个维度(2D position)共同创建了一个三维轨迹(3D Trajectory)。我们还为每个路径点指定了一个速度,用于确保车辆按时到达每个路径点。
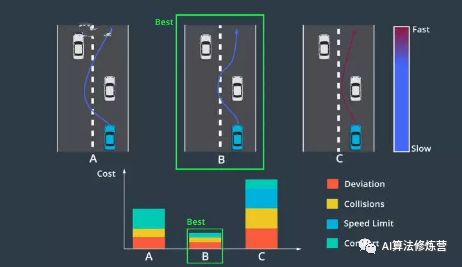
3、成本函数为每个轨迹分配了一个“成本”,我们选择成本最低的轨迹。轨迹“成本”由各种犯规处罚组成,例如:偏离道路中心,有可能产生碰撞,速度限制,轨迹的曲率和加速度让乘客感到不舒服等。
5、Frenet坐标系
1、我们通常使用笛卡尔坐标系描述物体的位置,但笛卡尔坐标系对车辆来说并不是最佳选择。即使给出了车辆位置(x,y),如果我们不知道道路在哪,就很难知道车辆行驶了多远也很难知道车辆是否偏离了道路中心。

2、Frenet坐标系描述了汽车相对于道路的位置。s代表沿道路的距离,也被称为纵坐标。d表示与纵向线的位移,也被称为横坐标。在道路的每个点上,横轴和纵轴都是垂直的。纵坐标表示道路中的行驶距离,横坐标表示汽车偏离中心线的距离。

6、路径-速度解耦规划
路径-速度解耦规划将轨迹规划分为两步:路径规划、速度规划。1)首先在路径规划步骤中生成候选曲线,这是车辆可行驶的路径,然后按成本对路径进行排名并选择成本最低的路径。;2)确定沿这条路线行进的速度。
7、路径生成与选择
为了在路径-速度解耦规划中生成候选路径,首先将路段分割成单元格。。然后对这些单元格中的点进行随机采样。通过从每个单元格中取一个点并将点连接,我们创建了候选路径。通过重复此过程可以构建多个候选路径。使用成本函数对这些路径进行评估并选择成本最低的路径,成本函数可能考虑以下因素:与车道中心的偏离、与障碍物的距离、速度和曲率的变化、对车辆的压力、或希望列入的任何其他因素。
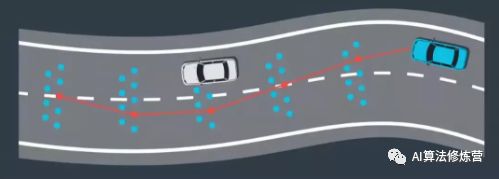
8、ST图
选择路径后的下一步是选择与该路径关联的速度曲线,在ST图中,“s”表示车辆的纵向位移、“t”表示时间。ST 图上的曲线是对车辆运动的描述,因为它说明了车辆在不同时间的位置。由于速度是位置变化的速率,所以可以通过查看曲线的斜率从 ST 图上推断速度。斜坡越陡则表示在更短的时间段内有更大的移动,对应更快的速度。
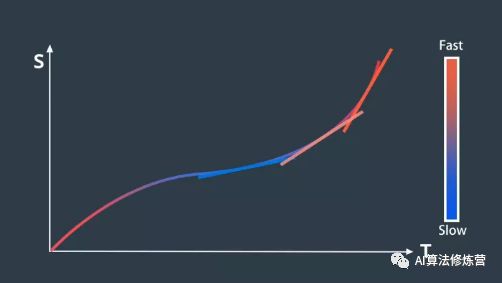
9、速度规划
1、为构建最佳速度曲线需要将 ST 图离散为多个单元格。单元格之间的速度有所变化,但在每个单元格内速度保持不变,该方法可简化速度曲线的构建并维持曲线的近似度。在 ST 图中可以将障碍物绘制为在特定时间段内阻挡道路的某些部分的矩形。例如,假设预测模块预测车辆将在 t0 到 t1 的时间段内驶入的车道。由于该车将在此期间占据位置 s0 到 s1,因此在 ST 图上绘制了一个矩形,它将在时间段 t0 到 t1 期间阻挡位置 s0 到 s1。为避免碰撞,速度曲线不得与此矩形相交。既然有了一张各种单元格被阻挡的 ST 图,便可以使用优化引擎为该图选择最佳的速度曲线。优化算法通过复杂的数学运算来搜索受到各种限制的低成本解决方案。这些限制可能包括:法律限制,如速度限制;距离限制,如与障碍物的距离;汽车的物理限制,如加速度限制。

2、路径-速度解耦规划在很大程度上取决于离散化。路径选择涉及将道路划分为单元格,速度曲线构建涉及将 ST 图划分为单元格。尽管离散化使这些问题更容易解决,但该解决方案生成的轨迹并不平滑。为了将离散解决方案转换为平滑轨迹,可使用“二次规划”技术(Quadratic Programming)。二次规划将平滑的非线性曲线与这些分段式线性段拟合。尽管二次规划背后的数学运算很复杂,但对于我们的目的而言,细节并不是必需的。

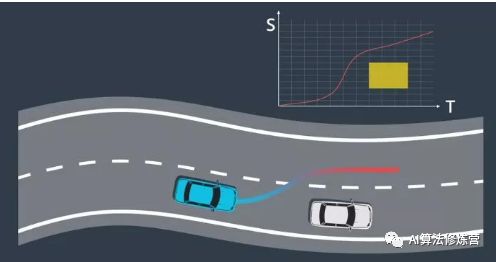
10、路径-速度规划的轨迹生成
回顾一下端到端路径-速度解耦规划。假设我们正在路上行驶,感知系统观察到一辆缓慢行驶的车辆离我们越来越近。首先,在这辆车的周围生成多条候选路线,使用成本函数对这些候选路径进行评估并选择成本最低的路径。然后使用 ST 图来进行速度规划,根据其他车辆随时间变化的位置阻挡了 ST 图的部分区域。优化引擎可帮助确定该图的最佳速度曲线,该曲线受制于约束和成本函数。我们可以使用二次规划让路径和速度曲线变平滑。最后,将路径和速度曲线合并构建轨迹。这里的轨迹在速度较快时为红色,在速度较慢时为蓝色。我们使用该轨迹来安全地绕开其他车辆并继续我们的旅程。
11、Lattice 规划
1、通过使用 Frenet 坐标可以将环境投射到纵轴和横轴上,目标是生成三维轨迹:纵向维度、横向维度、时间维度。将三维问题分解成两个单独的二维问题,这是通过分离轨迹的纵向和横向分量来解决的。其中一个二维轨迹是具有时间戳的纵向轨迹称之为 ST 轨迹,另一个二维轨迹是相对于纵向轨迹的横向偏移称之为 SL 轨迹。

2、Lattice 规划具有两个步骤即先分别建立 ST 和 SL 轨迹,然后将它们合并为生成纵向和横向二维轨迹。先将初始车辆状态投射到 ST 坐标系和 SL 坐标系中,通过对预选模式中的多个候选最终状态进行采样。来选择最终车辆状态。对于每个候选最终状态构建了一组轨迹将车辆从其初始状态转换为最终状态,使用成本函数对这些轨迹进行评估并选择成本最低的轨迹。
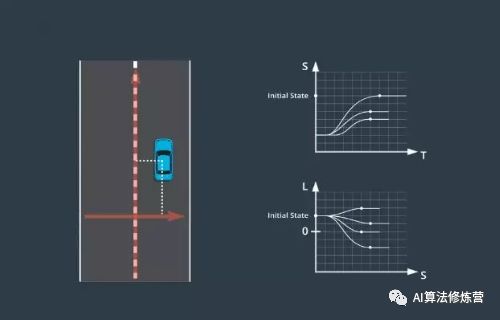
12、ST轨迹的终止状态
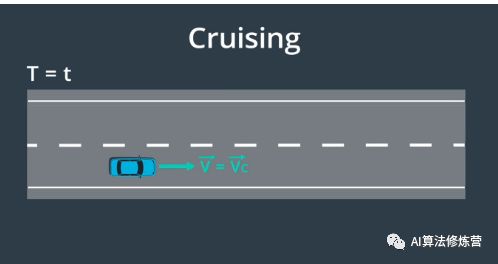
1、根据情况可以将状态分成 3 组:巡航 、跟随、停止。巡航意味着车辆将在完成规划步骤后定速行驶,实际上在对图上的点进行采样,在图中横轴代表时间,纵轴代表速度。对于该图上的点,这意味着汽车将进入巡航状态,在时间 t 以 s 点的速度巡航,对于这种模式,所有最终状态的加速度均为零。
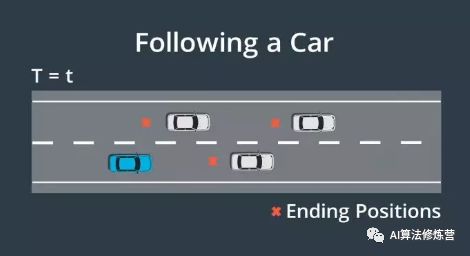
2、下一个要考虑的模式为跟随车辆,在这种情况下要对位置和时间状态进行采样,并尝试在时间t出现在某辆车后面,在跟随车辆时,需要与前方的车保持安全距离,这时速度和加速度将取决于要跟随的车辆,这意味着在这种模式下,速度和加速度都会进行修正。
3、最后一种模式是停止,对于这种模式只需对汽车何时何地停止进行抽样,这里速度和加速度会被修正为 0 。

13、SL轨迹的终止状态
根据这样一个假设来进行SL 规划,即无论车辆进入怎样的终止状态,车辆都应该稳定地与车道中心线对齐。这意味着只需要在一个小区域内,对横向终止位置进行采样。具体来说采样的是道路上相邻车道中心线周围的位置。为了确保稳定性,汽车驶向的终止状态应该与车道中心一致。当用横向位置与纵向位置作图时 ,想要的候选轨迹应该以车辆与车道对齐并直线行驶而结束。为了达到这种终止状态,车的朝向和位置的一阶和二阶导数都应该为零。这意味着车辆既不是横向移动的,那是一阶导数;也不是横向加速,那是二阶导数。这意味着车辆正沿着车道直行。
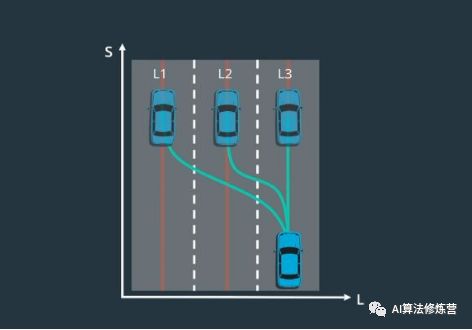
14、Lattice规划的轨迹生成
一旦同时拥有了 ST 和 SL 轨迹,就需要将它们重新转换为笛卡尔坐标系。然后可以将它们相结合构建由二维路径点和一维时间戳组成的三维轨迹。ST 轨迹是随时间变化的纵向位移,SL 轨迹是纵向轨迹上每个点的横向偏移。由于两个轨迹都有纵坐标 S,所以可以通过将其 S 值进行匹配来合并轨迹。
6
控制
1、控制流程
1、控制器预计有两种输入:目标轨迹与车辆状态。目标轨迹来自规划模块,在每个轨迹点,规划模块指定一个位置和参考速度。在每个时间戳都对轨迹进行更新。我们还需要了解车辆状态,车辆状态包括:通过本地化模块来计算的车辆位置、从车辆内部传感器获取的数据(如速度、转向和加速度)。我们使用这两个输入来计算目标轨迹与实际行进轨迹之间的偏差。
2、控制器的输出是控制输入(转向、加速和制动)的值。当偏离目标轨迹时,我们希望采取行动来纠正这种偏差。对于普通汽车,我们使用方向盘控制行驶方向(即转向)、使用油门加速、使用刹车减速(即制动)。这也是无人驾驶汽车所做的。一旦将这三个值传递给车辆,汽车实际上已经开始无人驾驶了。之后将介绍不同的控制算法,如何计算这三个输出-转向、加速和制动。
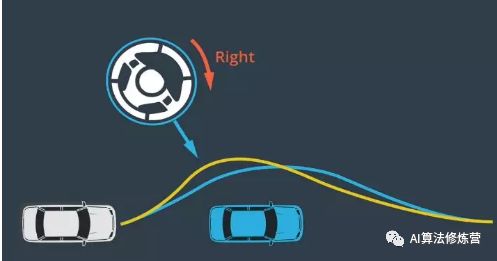
2、PID控制
1、P代表“比例”(Proportional)P控制器在车辆开始偏离时立即将其拉回目标轨迹。比例控制意味着,车辆偏离越远,控制器越难将其拉回目标轨迹。
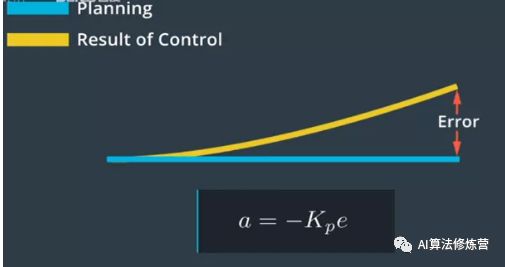
2、在实践中P控制器的一个问题在于,它很容易超出参考轨迹。当车辆越来越接近目标轨迹时,我们需要控制器更加稳定。PID控制器中的D项致力于使运动处于稳定状态,D代表“微分”(Derivative)。PD控制器类似于P控制器,它增加了一个阻尼项,可最大限度地减少控制器输出的变化速度
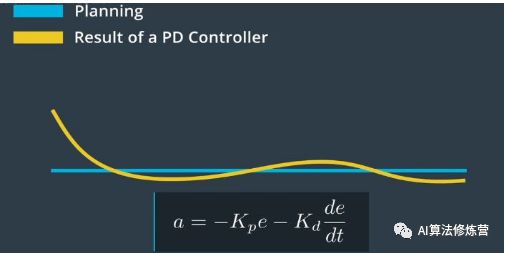
3、PID控制器中的最后一项I代表积分(Integral),该项负责纠正车辆的任何系统性偏差。例如,转向可能失准,这可能造成恒定的转向偏移。在这种情况下,我们需要稍微向一侧转向以保持直行。为解决这一问题,控制器会对系统的累积误差进行惩罚。我们可以将P、I和D组件结合构成PID控制器。
3、PID优劣对比
PID控制器很简单,但它在很多情况下的效果很好。对于PID控制器,你只需要知道你的车辆与目标轨迹之间的偏差。但是PID控制器只是一种线性算法,对于非常复杂的系统而言,这是不够的。例如,为控制具有多个关节的四轴飞行器或机器人,我们需要建立机器人的物理模型。对无人驾驶而言,我们需要应用不同的PID控制器来控制转向和加速,这意味着很难将横向和纵向控制结合起来。另一个问题在于PID控制器依赖于实时误差测量,这意味着受到测量延迟限制时可能会失效。
4、线性二次调节器LQR
1、线性二次调节器(Linear Quadratic Regulator 或LQR)是基于模型的控制器,它使用车辆的状态来使误差最小化。Apollo使用LQR进行横向控制。横向控制包含四个组件:横向误差、横向误差的变化率、朝向误差和朝向误差的变化率。变化率与导数相同,我们用变量名上面的一个点来代表。我们称这四个组件的集合为X,这个集合X捕获车辆的状态。除了状态之外,该车有三个控制输入:转向、加速和制动。我们将这个控制输入集合称为U。
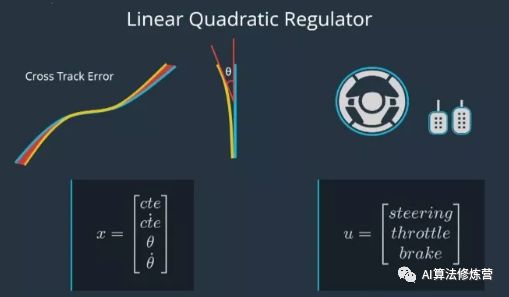
2、LQR处理线性控制,这种类型的模型可以用等式来表示(详见下图)。x(上方带点)=Ax+Bu,x(上方带点)向量是导数,或X向量的变化率。所以x点的每个分量只是x对应分量的导数。等式x点=Ax+Bu,该等式捕捉状态里的变化,即x点是如何受当前状态 x 和控制输入 u的影响的。这个等式是线性的,因为我们用∆x来改变x时,并用∆u来改变u。x点的变化也会让这个等式成立(见下图等式)。现在我们了解了LQR中的L。


3、接下来我们学习LQR中的Q。这里的目标是为了让误差最小化,但我们也希望尽可能少地使用控制输入。由于使用这些会有成本,例如:耗费气体或电力。为了尽量减少这些因素,我们可以保持误差的运行总和和控制输入的运行总和。当车往右转的特别厉害之际,添加到误差总和中。当控制输入将汽车往左侧转时,从控制输入总和中减去一点。然而,这种方法会导致问题。因为右侧的正误差只需将左侧的负误差消除即可。对控制输入来说也是如此。相反,我们可以让x和u与自身相乘,这样负值也会产生正平方,我们称这些为二次项。我们为这些项分配权重,并将它们加在一起。最优的u应该最小化二次项的和随时间的积分。在数学中我们将这个积分值称为成本函数(形式见下图)。我们经常以紧凑的矩阵形式表示加权二次项的总和。这里的Q和R代表x和u的权重集合。xT和uT是转置矩阵,这意味着它们几乎与x和u相同,只是重新排列以便矩阵相乘。x乘以xT,u乘以uT,实质上是将每个矩阵乘以它自己。最小化成本函数是一个复杂的过程,但通常我们可以依靠数值计算器为我们找到解决方案。Apollo就提供了一个这样的求解方案。在LQR中,控制方法被描述为u=-Kx。其中,K代表一个复杂的skeme,代表如何从x计算出u。所以找到一个最优的u就是找到一个最优的K。许多工具都可以轻松地用来解决K,尤其当你提供了模拟车辆物理特征的A、B,以及x和u的权重Q、R。


5、模型控制预测
1、模型预测控制(或MPC)是一种更复杂的控制器,它非常依赖于数学优化,但基本上可以将MPC归结为三个步骤:1、建立车辆模型。2、使用优化引擎计算有限时间范围内的控制输入。3、执行第一组控制输入。MPC是一个重复过程,它着眼未来,计算一系列控制输入,并优化该序列。但控制器实际上只实现了序列中的第一组控制输入,然后控制器再次重复该循环。为什么我们不执行整个控制输入序列呢?那是因为我们只采用了近似测量与计算。如果实现了整个控制输入序列,实际产生的车辆状态与我们的模型有很大差异,最好在每个时间步不断地重新评估控制输入的最优序列。
2、MPC的第一步为定义车辆模型,该模型近似于汽车的物理特性,该模型估计了假如将一组控制输入应用于车辆时会发生什么。接下来,我们决定MPC预测未来的能力。预测越深入,控制器就越精确,不过需要的时间也越长。所以,我们需要在准确度与快速获取结果之间做出取舍。获取结果的速度越快,越能快速地将控制输入应用到实际车辆中。

3、下一步是将模型发送到搜索最佳控制输入的优化引擎。该优化引擎的工作原理是通过搜索密集数学空间来寻求最佳解决方案。为缩小搜索范围,优化引擎依赖于车辆模型的约束条件。优化引擎可间接评估控制输入,它通过使用以下方法对车辆轨迹进行建模:通过成本函数对轨迹进行评估。成本函数主要基于与目标轨迹的偏差;其次,基于其他因素,如加速度和提升旅客舒适度的措施。
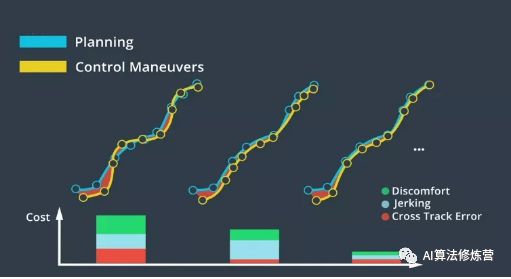
6、总结
控制实际上是无人驾驶汽车实现自动移动的方式。在控制中,我们使用转向、加速和制动来运行我们的目标轨迹。我们研究了几种不同类型的控制器。PID控制是一种简单而强大的控制算法,线性二次调节器和模型预测控制是另外两种类型的控制器,它们更复杂,但也更强大、更准确。Apollo支持所有这三种控制器,而你也可以选择最适合自己的控制器!
目标检测系列秘籍一:模型加速之轻量化网络秘籍二:非极大值抑制及回归损失优化秘籍三:多尺度检测秘籍四:数据增强秘籍五:解决样本不均衡问题秘籍六:Anchor-Free
语义分割系列一篇看完就懂的语义分割综述最新实例分割综述:从Mask RCNN 到 BlendMask
面试求职系列决战春招!算法工程师面试问题及资料超详细合集
一起学C++系列内存分区模型、引用、函数重载
竞赛与工程项目分享系列如何让笨重的深度学习模型在移动设备上跑起来基于Pytorch的YOLO目标检测项目工程大合集点云配准领域全面资料、课程、数据集合集分享10万奖金天文数据挖掘竞赛!0.95高分Baseline分享目标检测应用竞赛:铝型材表面瑕疵检测
SLAM系列视觉SLAM前端:视觉里程计和回环检测视觉SLAM后端:后端优化和建图模块视觉SLAM中特征点法开源算法:PTAM、ORB-SLAM视觉SLAM中直接法开源算法:LSD-SLAM、DSO
视觉注意力机制系列Non-local模块与Self-attention之间的关系与区别?视觉注意力机制用于分类网络:SENet、CBAM、SKNetNon-local模块与SENet、CBAM的融合:GCNet、DANetNon-local模块如何改进?来看CCNet、ANN