5种优化你的安卓5.0 Lollipop代码的方法
简介
转载请注明 http://blog.csdn.net/sinat_30276961/article/details/48048865
原文地址
Android 5.0 Lollipop* 发布的同时,推出了名为 ART*(简称 Android 运行时)的创新型默认运行时环境。 它包含多项增强功能,可有效提升性能。 本文将介绍 ART 相 比于前代 Android Dalvik* 运行时所具备的部分全新特性,并分享五个技巧,帮助开发 人员进一步提升应用性能。
ART 有何新特性?
基于 Dalvik 运行时分析 Android 应用时,最终用户会面临两个主要难题:应用启动 时间较长以及大量的 jank。 应用断续、不稳定或中止时都会出现 jank,这是因为帧设 置耗费的时间过长,导致应用与屏幕刷新率不一致。 相比于之前的帧,如果一个帧的速度明显加快或减慢,该帧就会被认为出现异常。 用户将这种 jank 视作抖动,用户体验的流畅性会因此比预期的差。 为解决这些问题,ART 增加了几项全新特性:
提前编译: ART 在安装期间使用设备上 dex2oat 工具编译应用,并针对目标设备生成可执行的应用。 通过对比,Dalvik 使用解释器和即时编译,在安装期间将 APK 转换成优化型 dex 字节代码,并在应用运行的时候进一步将该优化型 dex 字节代码编译成面向热路径的原生机器代码。 因此,尽管安装时间长一些,但 有助于加快应用在 ART 中的登录速度。 在 ART 环境中,应用还需使用设备更多的闪存 空间,因为安装期间编译的代码需占用额外空间。
改进内存分配: Dalvik 上需要广泛分配内存的应用可 能会遭遇性能低下问题。 内存分配器中的独立大型对象空间和功能改进有助于解决这一 问题。
改进垃圾回收: ART 的垃圾回收速度更快、规模更大, 可减少碎片数量并提高内存利用率。
提升 JNI 性能: 优化型 JNI 调用和返回代码顺序可减少 JNI 调用时所使用的指令数量。
64 位支持: ART 充分利用 64 位架构,有效提升了基于 64 位硬件运行的应用性能。
由于这些特性,使用 Android SDK 编写的应用以及进行多个 JNI 调用的应用在用户体验方面均得以显著提升。用户还可因此延长电池续航时间,因为应用只需编译一次, 而且在常规使用过程中执行的速度更快,消耗的能源更低。
ART 与 Dalvik 性能对比
ART 首次在 Android KitKat 4.4 上以预览版发布时,其性能遭到了诟病。 但早期的性能对比不太公平,因为对比的对象分别是早期版 ART 与成熟优化版 Dalvik,所以应用在 ART 中的运行速度比 Dalvik 慢。
现在我们可以对比面向客户版本的 ART 和 Dalvik。 由于 ART 是 Android 5.0 内的唯一进行时,并排对比 Dalvik 与 ART 只能基于对比近期从 Android KitKat 4.4 更新 至 Android Lollipop 5.0 的设备。 就本文而言,我们使用采用英特尔® 凌动 TM 处理器的 TrekStor SurfTab xintron i7.0* 平板电脑进行测试,首先是 运行 Dalvik 的 Android 4.4.4,然后更新至运行 ART 的 Android 5.0。
由于我们对比的是不同版本的 Android 系统,Android 5.0 也可能会带来性能改进, 但基于内部性能测试,我们发现,ART 是实现性能改进的最主要原因。
我们运行性能指标评测,其中 Dalvik 能够积极优化重复执行的代码,预计能够带来优势,以及英特尔自己的游戏仿真。
数据显示,在五项性能指标评测中,ART 的表现要优于 Dalvik,而且在几个案例中明显超过了 Dalvik。
Relative Lollipop-ART to KitKat-Dalvik performance
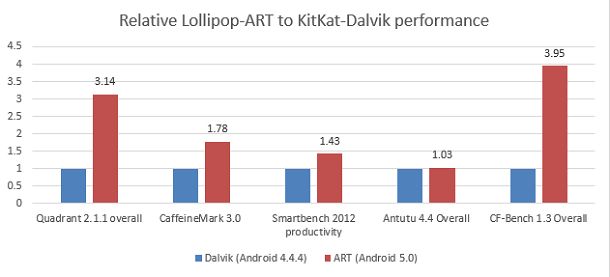
如欲了解更多有关这些性能指标评测的信息,请访问下列链接:
Quadrant 2.1.1*
CaffeineMark 3.0*
Smartbench 2012 productivity*
Antutu 4.4 Overall*( 请注意,我们测试的版本不再供下载)
CF-Bench 1.3 Overall*
IcyRocks 1.0 版是由英特尔开发的工作负载,用以模拟真实游戏应用。 它的大部分计算都采用开源 Cocos2d* 函数库和 JBox2D*(一种 Java 物理引擎)。 它测量不同负载水平下每秒渲染的平均动画(帧)数 (FPS),然后通过求取这些 FPS 的平均数计算最 终的指标。 它还测量跳帧的程度(每秒的跳帧数),即不同负载水平下每秒抖动帧数的平均值。 它显示了 ART 较之 Dalvik 所实现的性能改进:
Relative ICY Rocks animations/second
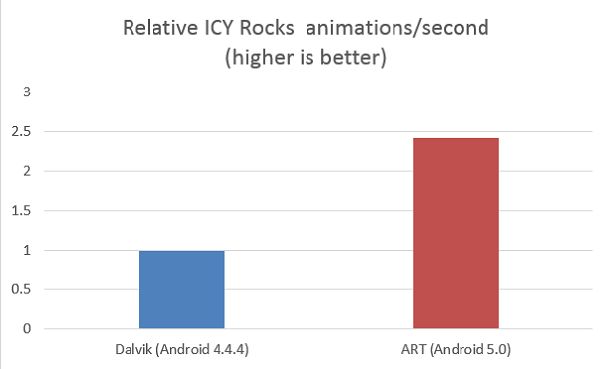
IcyRocks 1.0版也显示ART比Dalvik更连贯地渲染画面而较少出现跳帧,从而获得更平稳的用户体验。
Relative ICY Rocks JANK/second

基于这个性能评估,很显然ART相比Dalvik已经提供了更好的用户体验和更佳性能。
代码从 Dalvik 到 ART 的转换
代码从 Dalvik 到 ART 的转换非常透明,大多数运行于 Dalvik 的应用可直接运行于 ART,无需进行修改。 因此,用户升级至新的运行时后,许多应用都可实现性能改进。 最好测试带有 ART 的应用,尤其是使用 Java 原生接口的应用,因为 ART 的 JNI 错误处理比 Dalvik 更严格,如本文所述。
优化代码的 5 个技巧
得益于 ART 的上述功能改进,大多数应用将实现性能提升。 此外,您还可采用其他实践进一步针对 ART 优化您的应用。 我提供了部分简化的代码,以证明下列各种技巧的运行方式。
由于应用各不相同,其性能主要依赖于周围的代码和环境,因此无法为您提供明显的性能提升指示。 不过我们将解释这些技巧能够提升性能的原因,并建议您在自己的代码 环境中测试这些技巧,以验证它们对性能的影响。
这些技巧的使用非常广泛,但在 ART 案例中,可通过 dex 文件生成二进制可执行代码的 dex2oat 编译器将实施下列优化。
技巧 #1 – 尽可能使用本地变量,不要使用公共类域。
限制变量范围后,不仅可以增加代码的可读性,降低错误率,还可使代码更加便于优化。
在下列未优化代码中, v 的值在应用运行的时候计算。 因为 v 可绕过方法进行访问,它的值可通过任意代码更改,因此在编译期间处于未知状态。 编译器不知道 some_global_call() 操作是否更改了 v,因为任何代码都可绕过该方法更改 v。
在优化代码中,v 是本地变量,它的值可在编译期间计算。 因此,编译器能够直接将结果放在代码中,从而避免在运行时进行计算。
未优化代码
class A {
public int v = 0;
public int m(){
v = 42;
some_global_call();
return v*3;
}
}优化代码
class A {
public int m(){
int v = 42;
some_global_call();
return v*3;
}
}技巧 #2 – 使用关键词 final 提示该值为常量。
关键词 final 可用于防止代码被意外修改应为常量的变量,还可通过提示编译器该值为常量来提高性能。
在下列未优化代码中,v*v*v 的值必须在运行时计算,因为 v 的 值可以更改。 在下列优化代码中,为 v 赋值时,使用关键词 final 将告知编译器,该值不会被更改,因此可在编译期间执行计算,并将计算结果添加至代码,从而无需在运行时进行计算。
未优化代码
class A {
int v = 42;
public int m(){
return v*v*v;
}
}优化代码
class A {
final int v = 42;
public int m(){
return v*v*v;
}
}技巧 #3 – 使用关键词 final 定义类和方法
因为 Java 中的所有方法具备多形态特征,声明方法或类的最终性可告知编译器,该方法在任意子类中都不会被重新定义。
在下列未优化代码中,m() 必须在执行调用之前明确。
在优化代码中,由于方法 m() 已声明为最终方法,编译器知道应该调用哪个版本的 m()。 这样可避免方法查找和行内调用,从而该方法的内容可替换 m() 调用。 性能会因此显著提升。
未优化代码
class A {
public int m(){
return 42;
}
public int f(){
int sum = 0;
for (int i = 0; i < 1000; i++)
sum += m(); // m must be resolved before making a call
return sum;
}
}优化代码
class A {
public final int m(){
return 42;
}
public int f(){
int sum = 0;
for (int i = 0; i < 1000; i++)
sum += m();
return sum;
}
}技巧 #4 – 避免 JNI 调用小方法。
在很多情况下都可使用 JNI 调用,例如能够重复利用 C/C++ 代码库或函数库时,需要跨平台实施时,或需要性能提升时。 但最好能够最低限度地减少 JNI 调用的数量,因为调用的开销非常大。 如果 JNI 调用用于优化性能,其开销可能导致无法达到预期效果 。 尤其是频繁调用简短 JNI 方法可能会产生负面影响,而且将 JNI 调用放在循环中会增加开销。
代码示例
class A {
public final int factorial(int x){
int f = 1;
for (int i =2; i <= x; i++)
f *= i;
return f;
}
public int compute (){
int sum = 0;
for (int i = 0; i < 1000; i++)
sum += factorial(i % 5);
// if we used the JNI version of factorial() here
// it would be noticeably slower, because it is in a loop
// and the loop amplifies the overhead of the JNI call
return sum;
}
}技巧 #5 – 使用标准函数库,不要用自己的代码实施相同的功能
标准 Java 函数库经过了高度优化,通常使用内部 Java 机制获取最佳性能。 相比于使用您自己的代码实施相同功能,这种运行方式的速度要快得多。 试图避免因调用标准函数库而产生的开销实际上会导致性能下降。 在下列未优化代码中,有种自定义代码可 用来避免调用 Math.abs()。 不过,这种使用 Math.abs() 的代码运行速度会比较快,因为在编译期间,Math.abs() 由 ART 中的优化型内部实施所替代。
未优化代码
class A {
public static final int abs(int a){
int b;
if (a < 0)
b = a;
else
b = -a;
return b;
}
}优化代码
class A {
public static final int abs (int a){
return Math.abs(a);
}
}英特尔对 ART 的优化
英特尔与 OEM 合作提供优化版 Dalvik,基于英特尔处理器运行时可提升性能。 英特尔同样投资于改进 ART,使其基于全新运行时进一步增强性能。功能优化将通过 Android 开源项目 (AOSP) 提供,并/或直接通过设备厂商提供。 同先前一样,功能优化对开发人员和用户是透明的,因此无需更新应用便可轻松获得优势。
了解更多信息
如需了解更多有关优化面向英特尔处理器的 Android 应用,以及英特尔® 编译器的信 息,请通过网址 https://software.intel.com 访问英特尔开发人员专区。
关于作者
Anil Kumar 在英特尔公司工作已超过 15 年,在软件与服务事业部担任过多项职务。目前,他担任高级资深软件性能架构师,并在以下方面发挥着积极的作用:通过服务于各大标准组织帮助完善 Java 生态系统、积极参与性能指标评测(SPECjbb*、SPECjvm2008 ,SPECjEnterprise2010 等)、通过提升用户体验和资源利用率改进客户应用,以及提升面向软硬件配置的默认性能。
Daniil Sokolov 是英特尔软件与服务事业部的资深软件工程师。 过去 7 年,Daniil 一直专注于 Java 性能的各个领域。 目前,他主要致力于提升基于英特尔 Android 设备的用户体验和 Java 应用性能。
Xavier Hallade 是英特尔软件与服务事业部常驻法国巴黎的开发人员宣传官,主要致力于各种 Android 框架、函数库和应用,帮助开发人员增强对新硬件和新技术的支持。
他同时还是 Android 领域的谷歌开发专家,专注于 Android NDK 和 Android TV。