渗透测试信息收集笔记(信息搜集、后台查找)
文章目录
- 信息收集
- 什么是信息搜集
- 主动信息搜集与被动信息搜集
- 信息搜集后的渗透流程
- 信息收集的手段
- Whois信息(针对没有隐私保护URL)
- 子域名
- 利用搜索引擎site与inurl
- 子域名挖掘机
- 穷举爆破
- 目标真实IP
- CDN介绍
- 判断是否加了CDN
- 具体操作
- 无CDN
- 有CDN:
- 旁站与C段
- 邮箱
- CMS类型
- 敏感文件
- 端口信息扫描全端口一般使用Nmap,masscan进行扫描探测
- 服务器和中间件
- 其他
- 后台查找
- 源代码
- Robots.txt
- 扫描器
- Google搜索引擎
- 其他问题
信息收集
什么是信息搜集
主动信息搜集与被动信息搜集
主动信息搜集是与目标主机进行直接交互,从而拿到我们的目标信息,而被动信息搜集恰恰与主动信息搜集相反,不与目标主机进行直接交互,通过搜索引擎或者社交等方式间接的获取目标主机的信息。
当我们拿到一个目标进行渗透测试的时候,我们关注目标主机的whois信息,子域名,目标IP,旁站C段查询,邮箱搜集,CMS类型,敏感目录,端口信息,服务器与中间件信息。
信息搜集后的渗透流程
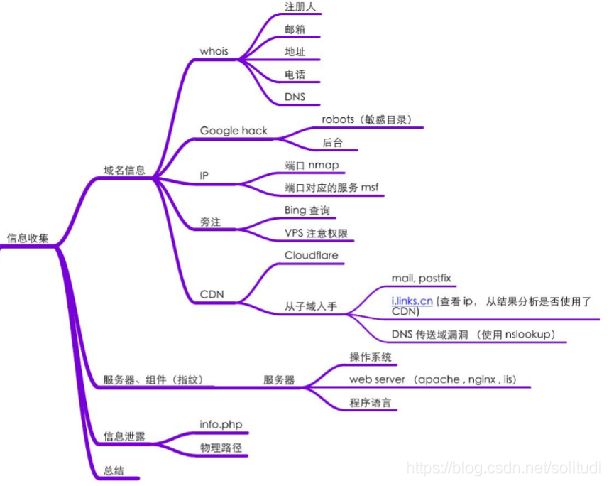
信息收集的手段
Whois信息(针对没有隐私保护URL)
提供两个URL:
https://www.whois.com/whois
http://whois.chinaz.com/
whois信息可以获取关键注册人的信息,包括注册公司、注册邮箱、管理员邮箱、管理员联系手机等,对后期社工很有用。同时该工具还可以查询同一注册人注册的其他的域名,域名对应的NS记录、MX记录,自动识别国内常见的托管商(万网、新网等)。常用的工具有:chinaz,kali下的whois命令。
子域名
利用搜索引擎site与inurl
site 和 inurl 是Google、百度等网页搜索引擎通用的语法(搜狗貌似对inurl时而无能)。
site——把搜索范围限定在特定站点中eg: 虫子 site:http://chongbuluo.com ; java site:net要体现域名特征(即便是后缀~),所以侧重是在某个站或某类域名域名后缀的站。inrul——把搜索范围限定在url链接中 假如你想通过Google搜索一部影片,需要在第一个结果中就出现这个电影在时光网预告片播放页链接,那么有两种实现:绑架者 预告片 site:http://movie.mtime.com
绑架者 inurl:http://movie.mtime.com trailer.html后面inurl语法要求网页链接中必须同时出现http://movie.mtime.com和trailer.html,而这个 trailer.html 就是时光网电影预告片页面特有的尾巴;显然要用site语法来实现这个需求,只能通过电影名和「 预告片」的组合。所以,inurl侧重的是链接,链接就可以是域名,从这个维度来讲,inurl可搜索到的结果一般是要比site多的,比如Google搜索:绑架者 site:http://sina.com 测试时返回结果数: 约 5,750 条结果
绑架者 inurl:http://sina.com 测试时返回结果数: 约 649,000 条结果 后者为什么多出很多?因为有大量的结果是 http://sina.com.cn 站内的。当然链接也可以是域名之外的任何部分。
链接:https://www.zhihu.com/question/57972574/answer/155170343
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
子域名挖掘机
子域名挖掘机Layer
subDomainsBrute
穷举爆破
目标真实IP
CDN介绍
https://www.zhihu.com/question/36514327?rf=37353035
判断是否加了CDN
百度在线ping
http://ping.chinaz.com/zhjw.scu.edu.cn
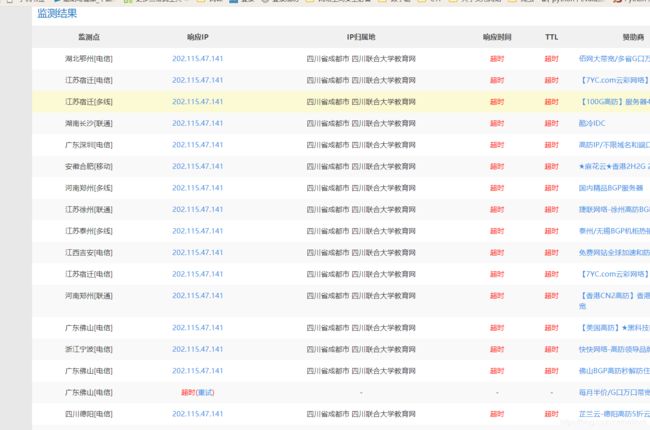
如果返回IP都是一样的基本上就都是没加CDN
具体操作
无CDN
没加CDN的网站只需要ping www.chabug.org 就行了
有CDN:
二级域名法
一、有种情况主域名加了CDN但是二级域名没有加CDN假如又在同意服务器就可以ping二级域名获取真实IP
https://github.com/boy-hack/w8fuckcdn
域名历史解析https://x.threatbook.cn/
旁站与C段
旁站是和目标网站在同一台服务器上的其它的网站;如果从目标站本身找不到好的入手点,这时候,如果想快速拿下目标的话,一般都会先找个目标站点所在服务器上其他的比较好搞的站下手,然后再想办法跨到真正目标的站点目录中。
C段是和目标机器ip处在同一个C段的其它机器;通过目标所在C段的其他任一台机器,想办法跨到我们的目标机器上。
URL:http://webscan.cc/
邮箱
首先确定目标的邮件服务器所在的真实位置,看看邮件服务器自身有没有什么错误配置,比如,没有禁用VREY或者EXPN命令导致用户信息泄露。然后从whois中获取域名的注册人、管理员邮箱,利用搜索引擎或者社工库查看有木有泄露的密码,然后尝试泄露的密码进行登录,最后从目标站点上搜集邮箱,例如网站上的联系我们,我们发发邮件钓鱼什么的。
CMS类型
内容管理系统
识别方式:
网站特有文件/templets/default/style/dedecms.css — dedecms
网站独有文件的md5 cms 带了一个favicon.ico
网站命名规则
返回头的关键字
网页关键字
URL特征
Script特征
robots.txt wp-admin
网站路径特征
网站静态资源 bootstrap前端框架
爬取网站目录信息
工具:
云悉:http://yunsee.cn
Whatweb:http://whatweb.bugscaner.com/look/
敏感文件
.git .svn .DB_store源代码泄露
扫描
御剑 www.zip>整个网站的备份或者是源代码
dirbrute
端口信息扫描全端口一般使用Nmap,masscan进行扫描探测
自写脚本https://www.chabug.org/tools/510.html
不同端口对应服务
服务器和中间件
Web容器:apache nginx iis6.0 > 解析漏洞,但并不是都有
服务器版本:Linux windows
Window7 ms17-010 msf
其他
Waf 防火墙
https://github.com/Ekultek/WhatWaf
安全狗 cookie格式
Safedog:asdawasdwa
360主机卫士
360:asdasdad
护卫神:
Hsw:dwadwadwa
历史漏洞信息
https://bugs.shuimugan.com/
后台查找
源代码
个别网站他的图片上传到了后台目录下,在引用的时候就可能会暴露自己的后台
Robots.txt
robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。因为一些系统中的URL是大小写敏感的,所以robots.txt的文件名应统一为小写。robots.txt应放置于网站的根目录下。
扫描器
有很多扫描器:
御剑
Wwwscan
W9scan
awvs
…
坏处:主动式 日志文件庞大
Google搜索引擎
在robots中如果没有禁止搜索引擎收录后台的话,可以用这种方法
inurl:www.chabug.org intitle:后台 管理 登录
site:www.chabug.org intext:登录
更多语法:https://zhuanlan.zhihu.com/p/22161675
其他问题
解决DEDECMS历史难题–找后台目录
https://xz.aliyun.com/t/2064