初探redis:Docker安装redis,redis的数据结构、发布订阅
redis
redis(REmote DIctionary Server),基于ANSI C语言编写的一个内存型NoSQL数据库(也可以持久化存储),性能极强,使用键值数据存储,提供多种语言的API。
之前的redis是单线程的(广义上来说,其实还有后台线程),因为所有命令都是串行的交给一个线程来处理,而最新的redis是支持多线程的。
redis的安装
之前使用传统的安装方式在Linux上安装redis,第一次搞得时候折腾了我几个小时。
这次就使用docker安装redis,方便快捷,
最后启动redis

通用命令
keys [pattern] 根据符号匹配查询,比如keys *查询所有
del key 删除指定key
exists key 判断key是否存在
type key 获取key的类型
expire key second 设置key的有效期,到期就删除
ttl 获取key的有效期(不存在返回-2,存在且没有有效期返回-1,否则返回剩余时间)
presist key 将有效期key转换为永久性key
五个基础数据结构
对于redis来说,key都是字符串,而value有五种基础类型。但是对于每个基础类型的数据结构,在其底层也有不同的内部编码(也就是底层的实现),就如同HashMap内部有链表和红黑树。
编码方式可以通过object encoding key 来查看
string
字符串类型,虽然是string类型,其实可以有多种类型,比如字符串、整数型。经常用于缓存,比如存储json数据等。
一个字符串类型最大不能超过512MB,这个大小通常是用不到的。字符串中数值类型也是有上限的,也就是Java中long类型的最大值(263-1,通常也是接触不到的)。
内部编码
- int:保存long类型的有符号整型,超出范围的数字则记为其他的字符串编码
- raw:保存长度大于44字节的字符串
- embstr:保存长度小于等于44字节的字符串
常见命令:
set key value 设置指定key的值
mset key1 value1 key2 value2... 批量设置key的值
get key 获取指定key的值
mget key1 key2 ... 批量获取key的值
incr key 数据类型自增1(非数据类型或超出范围会报错)
decr key 数据类型自减1
strlen key 返回指定key的字符串值的长度
hash
hash的存储类型,有些类似于Java中的HashMap结构,也就是一个哈希表结构。Hash中有field和value属性,也就是key-filed-value,可以将key-hash想象为HashMap
value中只能存储string类型
内部编码
- ziplist(压缩列表):ziplist是一种内存利用率很高的结构,是一块连续的内存块,采取的是时间换空间的思想。
- hashtable(散列表):当ziplist中数据超过某些限制时,会转换为hashtable编码
当field-value键值对少,value长度小的时候,使用压缩列表编码(键值对默认最多512个,value默认最大长度64字节),这些阈值可以设置,当某个阈值被打破时,就会转换。
常见命令:
hset key field value 设置指定key对应的field-value键值对
hmset key field1 value1 field2 value2... 批量设置key的field-value键值对
hget key field 获取指定key的field的value
hmget key field1 field2 ... 批量获取key的field的value
hgetall key 获取key对应的所有field-value
hkeys key 获取key中的所有field
hvals key 获取ke中的所有value
hincrby key field increment 对应value增加increment
hlen key 返回指定key的字段的数量
hexists key field 判断key中是否有field字段
hdel key field 删除指定key的field
使用string也能存储对象数据(比如json),hash也能存储对象数据。不过string是整体的,要修改需要全部读取出来,修改后再写回。而hash可以针对某个字段单独修改。所以string作为缓存通常用于读操作频繁的业务,而hash常用于写操作频繁的业务。
list
列表存储结构,可以类比于Java中的Linkedlist结构,也就是一个链表结构,在list内部编码中,也有linkedlist编码。
在value为list的结构下,存放的是一个有序的链表,可存储多个节点且允许有重复的节点,节点都是string类型,在链表头部和尾部都能进行操作(类似双端队列),且list都有索引。一个列表最多有232-1个节点。
内部编码
- ziplist:元素个数默认最多512个,value默认最大长度64字节。
- linkedlist(链表):当ziplist中数据超过某些限制时,会转换为linkedlist编码
redis3.2之后提供了quicklist的内部编码,是结合了两种编码设计出来的结构,可以看看它的详细介绍
常见命令:
lpush key value1 value2... 从左边插入每个元素
rpush key value1 value2... 从右边插入每个元素
lrange key start stop 获取列表指定范围内的元素,所有下标可以为负(列表第一个元素下标为0或-len,最后一个元素下标为len-1或-1)
lindex key index 获取指定下标的元素
llen key 获取列表长度
lrem key count value 删除list中多少个值为value的元素,count<0,从右边删除|count|个;count>0,从左边删除count个;count=0,全删除
lpop key 弹出(删除)左边第一个元素
rpop key 弹出右边第一个元素
blpop key1 key2... timeout 阻塞等待一段时间,如果有数据就立刻从左边弹出,如果没有就等待时间截至或有数据来,类似于Java的阻塞队列
blpop key1 key2... timeout 从右边阻塞弹出
set
集合Set是string类型的无序集合,可类比于Java中的HashsSet。集合中的元素都是是唯一的,不能出现重复的元素。
他的存储结构和hash相同,仅用hash中的field来存储,不使用value。可以回想一下Java中也是如此设计,HashSet的内部实现也是利用的HashMap。集合中最多可容纳的元素数量为 232 - 1。
内部编码
- intset(整数集合):集合中的元素必须都是整数,且元素个数默认最多为512个。
- hashtable:当intset的条件不满足时,就会使用hashtable作为set内部编码。
常见命令:
集合内操作:
sadd key member1 member2... 向集合中添加元素(已存在则添加失败)
srem key member... 删除集合中的元素
smembers key 获取集合中的所有元素
scard key 获取集合元素的个数
sismember key member 判断集合中是否存在元素
srandmember key count 随机获取集合中count个元素
spop key 随机弹出一个元素
集合间操作:
sinter key1 key2 获取两个集合的交集
sunion key1 key2 获取两个集合的并集
sdiff key1 key2 获取两个集合的差集(key1和key2有顺序)
zset
zset是有序集合(sorted set),可以联想Java中的TreeSet。和set一样,不能存放相同的元素。而不同的是,每个元素的顺序交给double类型的score来控制,通过score从小到大来排序,score是可以相同的。
zset中最多存放232-1个元素。
内部编码
- ziplist:集合中的元素个数默认最多为512个,且每个元素的值默认最长为64字节。
- skiplist(跳表):当ziplist的条件不满足时,就会使用skiplist作为zset的内部实现。
跳表是解决链表过长导致的查询效率低下的问题,采取的是空间换时间的思想。跳表的查询和更新操作可以达到O(logn)。
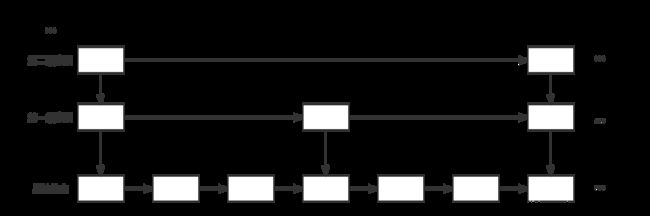
比如这样一个简单模拟的单向跳表,往上建立多级索引,可以快速找到某个区间范围内的元素,这也是为什么redis要用跳表来实现zset。
常见命令:
集合内操作:
zadd key score1 member1 score1 member2... 往zset中添加元素和元素对应的分数,添加相同元素会失败,但会覆盖更新score
zrank key memeber 获取某个元素的索引
zrevrank key member 获取某个元素反向排序下的索引
zscore key member 获取某个元素的分数
zincrby key increment member 给集合中某个元素的分数增加increment
zrange key start stop [withscores] 通过索引获取指定范围内的元素(和分数)
zrangebyscore key min max [withscores] [limit] 根据分数范围查询(和分数)(限制查询结果)
zrevrange key start stop [withscores] 通过索引获取指定范围内的元素(和分数),从高到低排序
zrevrangebyscore key min max [withscores] 根据分数范围查询(和分数),从高到低排序
zrem key member ... 删除指定的元素
zremrangebyrank key start stop 根据索引范围删除
zremrangebyscore min max 根据分数范围删除
zcard key 获取集合元素的个数
zcount key min max 获取分数范围内的元素个数
集合间操作:
zinterstore destination key1 key2... 将多个zset的交集存放在distination中
zunionstore destination key1 key2... 将多个zset的并集存放在distination中
高级数据类型
除了上面的基础数据结构外,redis还提供了其他的数据类型
BitMap
位图并不是redis提供的一种新型的数据结构,而是提供的操作二进制的方式。我们之前存储的string类型,在底层也是二进制数据。比如字符a,ASCII码中为97,转换为二进制就是0110 0001。
我们之前存储的最小单位都是字节,通过位图,我们就能操作更小的单位。
比如存储员工的性别,使用字节存储,M为男F为女,一个字节存储一个员工性比。
而使用位来存储,1为男0为女,1111 0000,就可以表示4个男性4个女性。这样能更加节省空间,不过数据操作更加复杂,这是时间换空间的思想。
在redis中,我们就可以通过操作bit来操作value
getbit key offset 获取key对应偏移量上的值
setbit key offset value 更新key对应偏移量上的值(1或0),比如{key1:a} setbit key1 6 1 这样key就更新为了c
bitop op destkey key1... 进行位运算,op=and、or、xor、not
bitcount key [start end] 获取指定key范围内的1的个数
HyperLogLog
HyperLogLog也不是一种新的数据结构,它的本质还是string,它的作用是用来进行基数统计,通常是统计独立用户数。
HyperLogLog可以说是一种算法,采用这种算法,利用很少的空间就能存储大量的元素数量,HyperLogLog只是计算元素基数,并不会存储数据本身。因此通常使用12kb就能存储264个不同元素的基数。不过它会有一定的误差(0.81%),对于大量的数据来说,并不精准,通常会有一定范围内的波动。
pfadd key element1 element2... 添加指定元素到hyperloglog
pfcount key... 估算给定的hyperloglog的基数值
pfmerge destkey sourcekey1 sourcekey2... 合并多个hyperloglog
Geo
Geo是基于zset的数据类型,它的作用也很单一,就是处理地理位置的计算。
比如存储几个不同的位置的坐标(经纬度),可以计算不同位置之间的距离,也可以计算某个坐标一定范围的其他坐标等。
需要处理地理位置的数据时,就可以用上这个数据类型的API。
Pipeline
redis也是基于客户端-服务器端模型,这和TCP协议有些类似,即请求/响应,客户端发出一个请求,服务器端完成命令后返回。在HTTP的长连接中就有流水线这种方式来提高服务效率,同样redis也具备这个功能,可以批量地传输命令。
如果一次传输,只携带一条命令,那么执行n条命令的时间就是:n次网络时间+n次命令时间。
而网络时间往往才是大头,因为redis的性能极强,处理一个命令的时间很短,所以我们需要减少网络时间的消耗。
redis本身提供有M命令,比如mset、mget这种一次批量处理命令,不过M命令并不能满足所有需求,pipeline的优势就体现出来了。。
比如我们要添加n条数据:
| 命令 | 时间 | 数据量 |
|---|---|---|
| n个命令 | n次网络时间+n次命令时间(Nx1) | 1次1条 |
| M命令 | 1次网络时间+1次命令时间(1xN) | 1次n条 |
| 流水线 | 1次网络时间+n次命令时间(Nx1) | 1次n条 |
不过M命令和流水线命令不同的是,M命令是限制了只有那几种M命令,是一个原子操作。
而流水线命令中,包括了各种若干个子命令,并不是原子的。

发布订阅
发布订阅是一种消息通信模式,可以类比于生产者-消费者模型,分别有这两种角色:
- 发布者:发布消息
- 订阅者:订阅消息
在redis中,有发布者、订阅者、频道。就像用阻塞队列来实现的生产者-消费者模型。
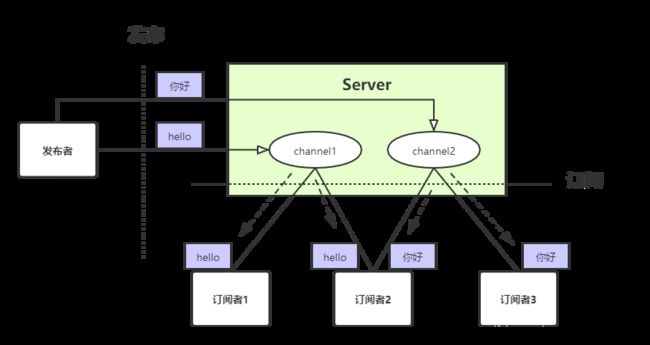
不过订阅者只能接收到订阅后的消息,订阅前的历史消息并不能收到。