前言
本文收录于专辑:http://dwz.win/HjK,点击解锁更多数据结构与算法的知识。
你好,我是彤哥。
上一节,我们一起学习了如何将递归改写为非递归,其中,用到的数据结构主要是栈。
栈和队列,可以说是除了数组和链表之外最基础的数据结构了,在很多场景中都有用到,后面我们也会陆陆续续的看到。
今天,我想介绍一下,在Java中,如何构建一个高性能的队列,以及我们需要掌握的底层知识。
学习其他语言的同学,也可以看看,在你的语言中,是如何构建高性能队列的。
队列
队列,是一种先进先出(First In First Out,FIFO)的数据结构,类似于实际生活场景中的排队,先到的人先得。
使用数组和链表实现简单的队列,我们前面都介绍过了,这里就不再赘述了,有兴趣的同学可以点击以下链接查看:
重温四大基础数据结构:数组、链表、队列和栈
今天我们主要来学习如何实现高性能的队列。
说起高性能的队列,当然是说在高并发环境下也能够工作得很好的队列,这里的很好主要是指两个方面:并发安全、性能好。
并发安全的队列
在Java中,默认地,也自带了一些并发安全的队列:
| 队列 | 有界性 | 锁 | 数据结构 |
|---|---|---|---|
| ArrayBlockingQueue | 有界 | 加锁 | 数组 |
| LinkedBlockingQueue | 可选有界 | 加锁 | 链表 |
| ConcurrentLinkedQueue | 无界 | 无锁 | 链表 |
| SynchronousQueue | 无界 | 无锁 | 队列或栈 |
| LinkedTransferQueue | 无界 | 无锁 | 链表 |
| 无界 | 加锁 | 堆 | |
| 无界 | 加锁 | 堆 |
这些队列的源码解析快捷入口:死磕 Java并发集合之终结篇
总结起来,实现并发安全队列的数据结构主要有:数组、链表和堆,堆主要用于实现优先级队列,不具备通用性,暂且不讨论。
从有界性来看,只有ArrayBlockingQueue和LinkedBlockingQueue可以实现有界队列,其它的都是无界队列。
从加锁来看,ArrayBlockingQueue和LinkedBlockingQueue都采用了加锁的方式,其它的都是采用的CAS这种无锁的技术实现的。
从安全性的角度来说,我们一般都要选择有界队列,防止生产者速度过快导致内存溢出。
从性能的角度来说,我们一般要考虑无锁的方式,减少线程上下文切换带来的性能损耗。
从JVM的角度来说,我们一般选择数组的实现方式,因为链表会频繁的增删节点,导致频繁的垃圾回收,这也是一种性能损耗。
所以,最佳的选择就是:数组 + 有界 + 无锁。
而JDK并没有提供这样的队列,因此,很多开源框架都自己实现了高性能的队列,比如Disruptor,以及Netty中使用的jctools。
高性能队列
我们这里不讨论具体的某一个框架,只介绍实现高性能队列的通用技术,并自己实现一个。
环形数组
通过上面的讨论,我们知道实现高性能队列使用的数据结构只能是数组,而数组实现队列,必然要使用到环形数组。
环形数组,一般通过设置两个指针实现:putIndex和takeIndex,或者叫writeIndex和readIndex,一个用于写,一个用于读。

当写指针到达数组尾端时,会从头开始,当然,不能越过读指针,同理,读指针到达数组尾端时,也会从头开始,当然,不能读取未写入的数据。

而为了防止写指针和读指针重叠的时候,无法分清队列到底是满了还是空的状态,一般会再添加一个size字段:

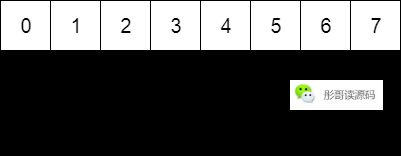
所以,使用环形数组实现队列的数据结构一般为:
public class ArrayQueue {
private T[] array;
private long wrtieIndex;
private long readIndex;
private long size;
}
在单线程的情况下,这样不会有任何问题,但是,在多线程环境中,这样会带来严重的伪共享问题。
伪共享
什么是共享?
在计算机中,有很多存储单元,我们接触最多的就是内存,又叫做主内存,此外,CPU还有三级缓存:L1、L2、L3,L1最贴近CPU,当然,它的存储空间也很小,L2比L1稍大一些,L3最大,可以同时缓存多个核心的数据。CPU取数据的时候,先从L1缓存中读取,如果没有再从L2缓存中读取,如果没有再从L3中读取,如果三级缓存都没有,最后会从内存中读取。离CPU核心越远,则相对的耗时就越长,所以,如果要做一些很频繁的操作,要尽量保证数据缓存在L1中,这样能极大地提高性能。

缓存行
而数据在三级缓存中,也不是说来一个数据缓存一下,而是一次缓存一批数据,这一批数据又称作缓存行(Cache Line),通常为64字节。

每一次,当CPU去内存中拿数据的时候,都会把它后面的数据一并拿过来(组成64字节),我们以long型数组为例,当CPU取数组中一个long的时候,同时会把后续的7个long一起取到缓存行中。
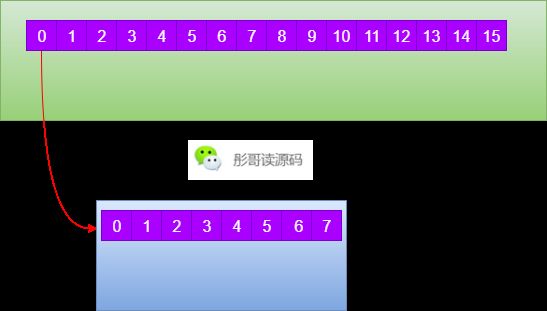
这在一定程度上能够加快数据的处理,因为,此时在处理下标为0的数据,下一个时刻可能就要处理下标为1的数据了,直接从缓存中取要快很多。
但是,这样又带来了一个新的问题——伪共享。
伪共享
试想一下,两个线程(CPU)同时在处理这个数组中的数据,两个CPU都缓存了,一个CPU在对array[0]的数据加1,另一个CPU在对array[1]的数据加1,那么,回写到主内存的时候,到底以哪个缓存行的数据为准(写回主内存的时候也是以缓存行的形式写回),所以,此时,就需要对这两个缓存行“加锁”了,一个CPU先修改数据,写回主内存,另一个CPU才能读取数据并修改数据,再写回主内存,这样势必会带来性能的损耗,出现的这种现象就叫做伪共享,这种“加锁”的方式叫做内存屏障,关于内存屏障的知识我们就不展开叙述了。
那么,怎么解决伪共享带来的问题呢?
以环形数组实现的队列为例,writeIndex、readIndex、size现在是这样处理的:

所以,我们只需要在writeIndex和readIndex之间加7个long就可以把它们隔离开,同理,readIndex和size之间也是一样的。
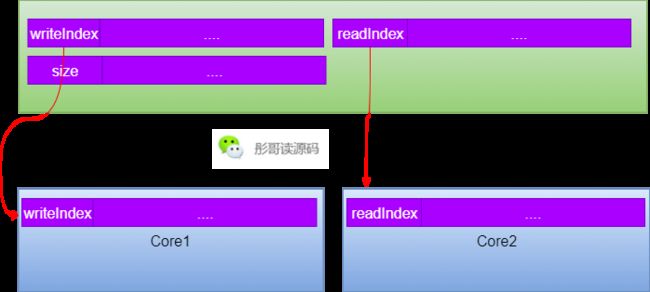
这样就消除了writeIndex和readIndex之间的伪共享问题,因为writeIndex和readIndex肯定是在两个不同的线程中更新,所以,消除伪共享之后带来的性能提升是很明显的。
假如有多个生产者,writeIndex是肯定会被争用的,此时,要怎么友好地修改writeIndex呢?即一个生产者线程修改了writeIndex,另一个生产者线程要立马可见。
你第一时间想到的肯定是volatile,没错,可是光volatile还不行哦,volatile只能保证可见性和有序性,不能保证原子性,所以,还需要加上原子指令CAS,CAS是谁提供的?原子类AtomicInteger和AtomicLong都具有CAS的功能,那我们直接使用他们吗?肯定不是,仔细观察,发现他们最终都是调用Unsafe实现的。
OK,下面就轮到最牛逼的底层杀手登场了——Unsafe。
Unsafe
Unsafe不仅提供了CAS的指令,还提供很多其它操作底层的方法,比如操作直接内存、修改私有变量的值、实例化一个类、阻塞/唤醒线程、带有内存屏障的方法等。
关于Unsafe,可以看这篇文章:死磕 java魔法类之Unsafe解析
当然,构建高性能队列,主要使用的是Unsafe的CAS指令以及带有内存屏障的方法等:
// 原子指令
public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
// 以volatile的形式获取值,相当于给变量加了volatile关键字
public native long getLongVolatile(Object var1, long var2);
// 延迟更新,对变量的修改不会立即写回到主内存,也就是说,另一个线程不会立即可见
public native void putOrderedLong(Object var1, long var2, long var4);
好了,底层知识介绍的差不多了,是时候展现真正的技术了——手写高性能队列。
手写高性能队列
我们假设这样一种场景:有多个生产者(Multiple Producer),却只有一个消费者(Single Consumer),这是Netty中的经典场景,这样一种队列该怎么实现?
直接上代码:
/**
* 多生产者单消费者队列
*
* @param
*/
public class MpscArrayQueue {
long p01, p02, p03, p04, p05, p06, p07;
// 存放元素的地方
private T[] array;
long p1, p2, p3, p4, p5, p6, p7;
// 写指针,多个生产者,所以声明为volatile
private volatile long writeIndex;
long p11, p12, p13, p14, p15, p16, p17;
// 读指针,只有一个消费者,所以不用声明为volatile
private long readIndex;
long p21, p22, p23, p24, p25, p26, p27;
// 元素个数,生产者和消费者都可能修改,所以声明为volatile
private volatile long size;
long p31, p32, p33, p34, p35, p36, p37;
// Unsafe变量
private static final Unsafe UNSAFE;
// 数组基础偏移量
private static final long ARRAY_BASE_OFFSET;
// 数组元素偏移量
private static final long ARRAY_ELEMENT_SHIFT;
// writeIndex的偏移量
private static final long WRITE_INDEX_OFFSET;
// readIndex的偏移量
private static final long READ_INDEX_OFFSET;
// size的偏移量
private static final long SIZE_OFFSET;
static {
Field f = null;
try {
// 获取Unsafe的实例
f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
UNSAFE = (Unsafe) f.get(null);
// 计算数组基础偏移量
ARRAY_BASE_OFFSET = UNSAFE.arrayBaseOffset(Object[].class);
// 计算数组中元素偏移量
// 简单点理解,64位系统中有压缩指针占用4个字节,没有压缩指针占用8个字节
int scale = UNSAFE.arrayIndexScale(Object[].class);
if (4 == scale) {
ARRAY_ELEMENT_SHIFT = 2;
} else if (8 == scale) {
ARRAY_ELEMENT_SHIFT = 3;
} else {
throw new IllegalStateException("未知指针的大小");
}
// 计算writeIndex的偏移量
WRITE_INDEX_OFFSET = UNSAFE
.objectFieldOffset(MpscArrayQueue.class.getDeclaredField("writeIndex"));
// 计算readIndex的偏移量
READ_INDEX_OFFSET = UNSAFE
.objectFieldOffset(MpscArrayQueue.class.getDeclaredField("readIndex"));
// 计算size的偏移量
SIZE_OFFSET = UNSAFE
.objectFieldOffset(MpscArrayQueue.class.getDeclaredField("size"));
} catch (Exception e) {
throw new RuntimeException();
}
}
// 构造方法
public MpscArrayQueue(int capacity) {
// 取整到2的N次方(未考虑越界)
capacity = 1 << (32 - Integer.numberOfLeadingZeros(capacity - 1));
// 实例化数组
this.array = (T[]) new Object[capacity];
}
// 生产元素
public boolean put(T t) {
if (t == null) {
return false;
}
long size;
long writeIndex;
do {
// 每次循环都重新获取size的大小
size = this.size;
// 队列满了直接返回
if (size >= this.array.length) {
return false;
}
// 每次循环都重新获取writeIndex的值
writeIndex = this.writeIndex;
// while循环中原子更新writeIndex的值
// 如果失败了重新走上面的过程
} while (!UNSAFE.compareAndSwapLong(this, WRITE_INDEX_OFFSET, writeIndex, writeIndex + 1));
// 到这里,说明上述原子更新成功了
// 那么,就把元素的值放到writeIndex的位置
// 且更新size
long eleOffset = calcElementOffset(writeIndex, this.array.length-1);
// 延迟更新到主内存,读取的时候才更新
UNSAFE.putOrderedObject(this.array, eleOffset, t);
// 往死里更新直到成功
do {
size = this.size;
} while (!UNSAFE.compareAndSwapLong(this, SIZE_OFFSET, size, size + 1));
return true;
}
// 消费元素
public T take() {
long size = this.size;
// 如果size为0,表示队列为空,直接返回
if (size <= 0) {
return null;
}
// size大于0,肯定有值
// 只有一个消费者,不用考虑线程安全的问题
long readIndex = this.readIndex;
// 计算读指针处元素的偏移量
long offset = calcElementOffset(readIndex, this.array.length-1);
// 获取读指针处的元素,使用volatile语法,强制更新生产者的数据到主内存
T e = (T) UNSAFE.getObjectVolatile(this.array, offset);
// 增加读指针
UNSAFE.putOrderedLong(this, READ_INDEX_OFFSET, readIndex+1);
// 减小size
do {
size = this.size;
} while (!UNSAFE.compareAndSwapLong(this, SIZE_OFFSET, size, size-1));
return e;
}
private long calcElementOffset(long index, long mask) {
// index & mask 相当于取余数,表示index到达数组尾端了从头开始
return ARRAY_BASE_OFFSET + ((index & mask) << ARRAY_ELEMENT_SHIFT);
}
}
是不是看不懂?那就对了,多看几遍吧,面试又能吹一波了。
这里使用的是每两个变量之间加7个long类型的变量来消除伪共享,有的开源框架你可能会看到通过继承的方式实现的,还有的是加15个long类型,另外,JDK8中也提供了一个注解@Contended来消除伪共享。
本例其实还有优化的空间,比如,size的使用,能不能不使用size?不使用size又该如何实现?
后记
本节,我们一起学习了在Java中如何构建高性能的队列,并学习了一些底层的知识,毫不夸张地讲,学会了这些底层知识,面试的时候光队列就能跟面试官吹一个小时。
另外,最近收到一些同学的反馈,说哈希、哈希表、哈希函数他们之间有关系吗?有怎样的关系?为什么Object中要放一个hash()方法?跟equals()方法怎么又扯上关系了呢?
下一节,我们就来看看关于哈希的一切,想及时获取最新推文吗?还不快点来关注我!
关注公号主“彤哥读源码”,解锁更多源码、基础、架构知识。