如何在 PyFlink 1.10 中自定义 Python UDF?
我们知道 PyFlink 是在 Apache Flink 1.9 版新增的,那么在 Apache Flink 1.10 中 Python UDF 功能支持的速度是否能够满足用户的急切需求呢?

Python UDF 的发展趋势
直观的判断,PyFlink Python UDF 的功能也可以如上图一样能够迅速从幼苗变成大树,为啥有此判断,请继续往下看…
Flink on Beam
我们都知道有 Beam on Flink 的场景,就是 Beam 支持多种 Runner,也就是说 Beam SDK 编写的 Job 可以运行在 Flink 之上。如下图所示:
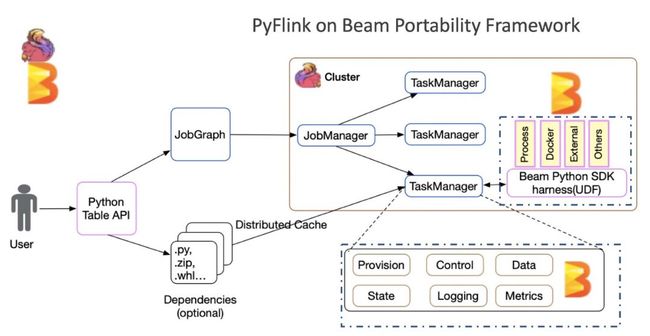
上面这图是 Beam Portability Framework 的架构图,他描述了 Beam 如何支持多语言,如何支持多 Runner,单独说 Apache Flink 的时候我们就可以说是 Beam on Flink,那么怎么解释 Flink on Beam 呢?
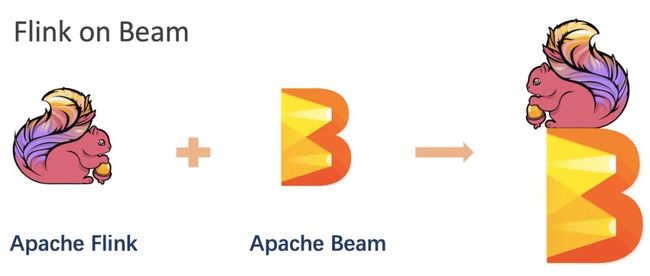
在 Apache Flink 1.10 中我们所说的 Flink on Beam 更精确的说是 PyFlink on Beam Portability Framework。我们看一下简单的架构图,如下:
Beam Portability Framework 是一个成熟的多语言支持框架,框架高度抽象了语言之间的通信协议(gRPC),定义了数据的传输格式(Protobuf),并且根据通用流计算框架所需要的组件,抽象个各种服务,比如 DataService,StateService,MetricsService 等。在这样一个成熟的框架下,PyFlink 可以快速的构建自己的 Python 算子,同时重用 Apache Beam Portability Framework 中现有 SDK harness 组件,可以支持多种 Python 运行模式,如:Process,Docker,etc.,这使得 PyFlink 对 Python UDF 的支持变得非常容易,在 Apache Flink 1.10 中的功能也非常的稳定和完整。那么为啥说是 Apache Flink 和 Apache Beam 共同打造呢,是因为我发现目前 Apache Beam Portability Framework 的框架也存在很多优化的空间,所以我在 Beam 社区进行了优化讨论,并且在 Beam 社区也贡献了 20+ 的优化补丁。
概要了解了 Apache Flink 1.10 中 Python UDF 的架构之后,我们还是切入的代码部分,看看如何开发和使用 Python UDF。
如何定义 Python UDF
在 Apache Flink 1.10 中我们有多种方式进行 UDF 的定义,比如:
Extend ScalarFunction, e.g.:
class HashCodeMean(ScalarFunction):
def eval(self, i, j):
return (hash(i) + hash(j)) / 2
Lambda Functio
lambda i, j: (hash(i) + hash(j)) / 2
Named Function
def hash_code_mean(i, j):
return (hash(i) + hash(j)) / 2
Callable Function
class CallableHashCodeMean(object):
def __call__(self, i, j):
return (hash(i) + hash(j)) / 2
我们发现上面定义函数除了第一个扩展 ScalaFunction 的方式是 PyFlink 特有的,其他方式都是 Python 语言本身就支持的,也就是说,在 Apache Flink 1.10 中 PyFlink 允许以任何 Python 语言所支持的方式定义 UDF。
如何使用 Python UDF
那么定义完 UDF 我们应该怎样使用呢?Apache Flink 1.10 中提供了 2 种 Decorators,如下:
Decorators - udf(), e.g. :
udf(lambda i, j: (hash(i) + hash(j)) / 2,
[for input types], [for result types])
Decorators - @udf, e.g. :
@udf(input_types=..., result_type=...)
def hash_code_mean(…):
return …
然后在使用之前进行注册,如下:
st_env.register_function("hash_code", hash_code_mean)
接下来就可以在 Table API/SQL 中进行使用了,如下:
my_table.select("hash_code_mean(a, b)").insert_into("Results")
目前为止,我们已经完成了 Python UDF 的定义,声明和注册了。接下来我们还是看一个完整的示例吧:)
案例描述
需求
假设苹果公司要统计该公司产品在双 11 期间各城市的销售数量和销售金额分布情况。数据格式
每一笔订单是一个字符串,字段用逗号分隔, 例如:
ItemName, OrderCount, Price, City
-------------------------------------------
iPhone 11, 30, 5499, Beijing\n
iPhone 11 Pro,20,8699,Guangzhou\n
案例分析
根据案例的需求和数据结构分析,我们需要对原始字符串进行结构化解析,那么需要一个按“,”号分隔的 UDF(split) 和一个能够将各个列信息展平的 DUF(get)。同时我们需要根据城市进行分组统计。
核心实现
UDF 定义
Split UDF
@udf(input_types=[DataTypes.STRING()],
result_type=DataTypes.ARRAY(DataTypes.STRING()))
def split(line):
return line.split(",")
Get UDF
@udf(input_types=[DataTypes.ARRAY(DataTypes.STRING()), DataTypes.INT()], result_type=DataTypes.STRING())
def get(array, index):
return array[index]
注册 UDF
注册 Split UDF
t_env.register_function("split", split)
注册 Get UDF
t_env.register_function("get", get)
核心实现逻辑
如下代码我们发现核心实现逻辑非常简单,只需要对数据进行解析和对数据进行集合计算:
t_env.from_table_source(SocketTableSource(port=9999))\ .alias("line")\ .select("split(line) as str_array")\ .select("get(str_array, 3) as city, " "get(str_array, 1).cast(LONG) as count, " "get(str_array, 2).cast(LONG) as unit_price")\ .select("city, count, count * unit_price as total_price")\
.group_by("city")\ .select("city, sum(count) as sales_volume, sum(total_price)
as sales")\
.insert_into("sink")
t_env.execute("Sales Statistic")
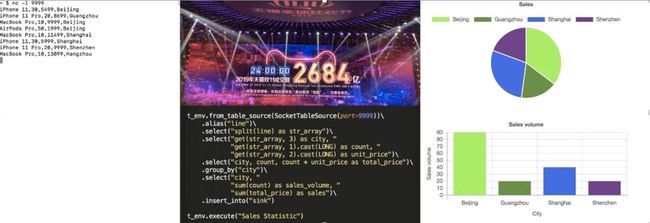
上面的代码我们假设是一个 Socket 的 Source,Sink 是一个 Chart Sink,那么最终运行效果图,如下:
我总是认为在博客中只是文本描述而不能让读者真正的在自己的机器上运行起来的博客,不是好博客,所以接下来我们看看按照我们下面的操作,是否能在你的机器上也运行起来?:)
环境
因为目前 PyFlink 还没有部署到 PyPI 上面,在 Apache Flink 1.10 发布之前,我们需要通过构建 Flink 的 master 分支源码来构建运行我们 Python UDF 的 PyFlink 版本。
源代码编译
在进行编译代码之前,我们需要你已经安装了 JDK8 和 Maven3x。
下载解压
tar -xvf apache-maven-3.6.1-bin.tar.gz
mv -rf apache-maven-3.6.1 /usr/local/
修改环境变量(~/.bashrc)
MAVEN_HOME=/usr/local/apache-maven-3.6.1
export MAVEN_HOME
export PATH=${PATH}:${MAVEN_HOME}/bin
除了 JDK 和 MAVEN 完整的环境依赖性如下:
JDK 1.8+ (1.8.0_211)
Maven 3.x (3.2.5)
Scala 2.11+ (2.12.0)
Python 3.6+ (3.7.3)
Git 2.20+ (2.20.1)
Pip3 19+ (19.1.1)
我们看到基础环境安装比较简单,我这里就不每一个都贴出来了。如果大家有问题欢迎邮件或者博客留言。
下载 Flink 源代码:
git clone https://github.com/apache/flink.git
编译
cd flink
mvn clean install -DskipTests
...
...
[INFO] flink-walkthrough-datastream-scala ................. SUCCESS [ 0.192 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 18:34 min
[INFO] Finished at: 2019-12-04T23:03:25+08:00
[INFO] ------------------------------------------------------------------------
构建 PyFlink 发布包
cd flink-python; python3 setup.py sdist bdist_wheel
...
...
adding 'apache_flink-1.10.dev0.dist-info/WHEEL'
adding 'apache_flink-1.10.dev0.dist-info/top_level.txt'
adding 'apache_flink-1.10.dev0.dist-info/RECORD'
removing build/bdist.macosx-10.14-x86_64/wheel
安装 PyFlink(PyFlink 1.10 需要 Python3.6+)
pip3 install dist/*.tar.gz
...
...
Successfully installed apache-beam-2.15.0 apache-flink-1.10.dev0 avro-python3-1.9.1 cloudpickle-1.2.2 crcmod-1.7 dill-0.2.9 docopt-0.6.2 fastavro-0.21.24 future-0.18.2 grpcio-1.25.0 hdfs-2.5.8 httplib2-0.12.0 mock-2.0.0 numpy-1.17.4 oauth2client-3.0.0 pbr-5.4.4 protobuf-3.11.1 pyarrow-0.14.1 pyasn1-0.4.8 pyasn1-modules-0.2.7 pydot-1.4.1 pymongo-3.9.0 pyyaml-3.13 rsa-4.0
也可以查看一下,我们核心需要 apache-beam 和 apache-flink,如下命令:
jincheng:flink-python jincheng.sunjc$ pip3 list
Package Version
----------------------------- ---------
alabaster 0.7.12
apache-beam 2.15.0
apache-flink 1.10.dev0
atomicwrites 1.3.0
如上信息证明你我们所需的 Python 依赖已经没问题了,接下来回过头来在看看如何进行业务需求的开发。
PyFlinlk 的 Job 结构
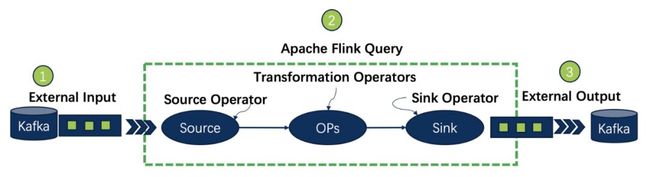
一个完成的 PyFlink 的 Job 需要有外部数据源的定义,有业务逻辑的定义和最终计算结果输出的定义。也就是 Source connector, Transformations, Sink connector,接下来我们根据这个三个部分进行介绍来完成我们的需求。
Source Connector
我们需要实现一个 Socket Connector,首先要实现一个 StreamTableSource, 核心代码是实现 getDataStream,代码如下:
@Override
public DataStream getDataStream(StreamExecutionEnvironment env) {
return env.socketTextStream(hostname, port, lineDelimiter, MAX_RETRY)
.flatMap(new Spliter(fieldNames.length, fieldDelimiter, appendProctime))
.returns(getReturnType());
}
上面代码利用了 StreamExecutionEnvironment 中现有 socketTextStream 方法接收数据,然后将业务订单数据传个一个 FlatMapFunction, FlatMapFunction 主要实现将数据类型封装为 Row,详细代码查阅 Spliter。
同时,我们还需要在 Python 封装一个 SocketTableSource,详情查阅 socket_table_source.py。
Sink Connector
我们预期要得到的一个效果是能够将结果数据进行图形化展示,简单的思路是将数据写到一个本地的文件,然后在写一个 HTML 页面,使其能够自动更新结果文件,并展示结果。所以我们还需要自定义一个 Sink 来完成该功能,我们的需求计算结果是会不断的更新的,也就是涉及到 Retraction(如果大家不理解这个概念,可以查阅我以前的博客),目前在 Flink 里面还没有默认支持 Retract 的 Sink,所以我们需要自定义一个 RetractSink,比如我们实现一下 CsvRetractTableSink。
CsvRetractTableSink 的核心逻辑是缓冲计算结果,每次更新进行一次全量(这是个纯 demo,不能用于生产环境)文件输出。源代码查阅 CsvRetractTableSink。
同时我们还需要利用 Python 进行封装,详见 chart_table_sink.py。
在 chart_table_sink.py 我们封装了一个 http server,这样我们可以在浏览器中查阅我们的统计结果。
业务逻辑
完成自定义的 Source 和 Sink 之后我们终于可以进行业务逻辑的开发了,其实整个过程自定义 Source 和 Sink 是最麻烦的,核心计算逻辑似乎要简单的多。
设置 Python 版本(很重要)
如果你本地环境 python 命令版本是 2.x,那么需要对 Python 版本进行设置,如下:
t_env.get_config().set_python_executable("python3")
PyFlink 1.10 之后支持 Python 3.6+ 版本。
读取数据源
PyFlink 读取数据源非常简单,如下:
...
...
t_env.from_table_source(SocketTableSource(port=9999)).alias("line")
上面这一行代码定义了监听端口 9999 的数据源,同时结构化 Table 只有一个名为 line 的列。
解析原始数据
我们需要对上面列进行分析,为了演示 Python UDF,我们在 SocketTableSource中并没有对数据进行预处理,所以我们利用上面 UDF 定义 一节定义的 UDF,来对原始数据进行预处理。
...
...
.select("split(line) as str_array")
.select("get(str_array, 3) as city, " "get(str_array, 1).cast(LONG) as count, " "get(str_array, 2).cast(LONG) as unit_price")
.select("city, count, count * unit_price as total_price")
统计分析
核心的统计逻辑是根据 city 进行分组,然后对 销售数量和销售金额进行求和,如下:
...
...
.group_by("city")
.select("city, sum(count) as sales_volume, sum(total_price)
as sales")\
计算结果输出
计算结果写入到我们自定义的 Sink 中,如下:
...
...
.insert_into("sink")
完整的代码(blog_demo.py)
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.demo import ChartConnector, SocketTableSource
from pyflink.table import StreamTableEnvironment, EnvironmentSettings, DataTypes
from pyflink.table.descriptors import Schema
from pyflink.table.udf import udf
env = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(
env,
environment_settings=EnvironmentSettings.new_instance().use_blink_planner().build())
t_env.connect(ChartConnector())\
.with_schema(Schema()
.field("city", DataTypes.STRING())
.field("sales_volume", DataTypes.BIGINT())
.field("sales", DataTypes.BIGINT()))\
.register_table_sink("sink")
@udf(input_types=[DataTypes.STRING()],
result_type=DataTypes.ARRAY(DataTypes.STRING()))
def split(line):
return line.split(",")
@udf(input_types=[DataTypes.ARRAY(DataTypes.STRING()), DataTypes.INT()],
result_type=DataTypes.STRING())
def get(array, index):
return array[index]
t_env.get_config().set_python_executable("python3")
t_env.register_function("split", split)
t_env.register_function("get", get)
t_env.from_table_source(SocketTableSource(port=6666))\
.alias("line")\
.select("split(line) as str_array")\
.select("get(str_array, 3) as city, "
"get(str_array, 1).cast(LONG) as count, "
"get(str_array, 2).cast(LONG) as unit_price")\
.select("city, count, count * unit_price as total_price")\
.group_by("city")\
.select("city, "
"sum(count) as sales_volume, "
"sum(total_price) as sales")\
.insert_into("sink")
t_env.execute("Sales Statistic")
上面代码中大家会发现一个陌生的部分,就是 from pyflink.demo import ChartConnector, SocketTableSource. 其中 pyflink.demo 是哪里来的呢?其实就是包含了上面我们介绍的 自定义 Source/Sink(Java&Python)。下面我们来介绍如何增加这个 pyflink.demo 模块。
安装 pyflink.demo
为了大家方便我把自定义 Source/Sink(Java&Python)的源代码放到了这里 ,大家可以进行如下操作:
下载源码
git clone https://github.com/sunjincheng121/enjoyment.code.git
编译源码
cd enjoyment.code/PyUDFDemoConnector/; mvn clean install
构建发布包
python3 setup.py sdist bdist_wheel
...
...
adding 'pyflink_demo_connector-0.1.dist-info/WHEEL'
adding 'pyflink_demo_connector-0.1.dist-info/top_level.txt'
adding 'pyflink_demo_connector-0.1.dist-info/RECORD'
removing build/bdist.macosx-10.14-x86_64/wheel
安装 Pyflink.demo
pip3 install dist/pyflink-demo-connector-0.1.tar.gz
...
...
Successfully built pyflink-demo-connector
Installing collected packages: pyflink-demo-connector
Successfully installed pyflink-demo-connector-0.1
出现上面信息证明已经将 PyFlink.demo 模块成功安装。接下来我们可以运行我们的示例了 :)
运行示例
示例的代码在上面下载的源代码里面已经包含了,为了简单,我们利用 PyCharm 打开enjoyment.code/myPyFlink。同时在 Terminal 启动一个端口:
nc -l 6666
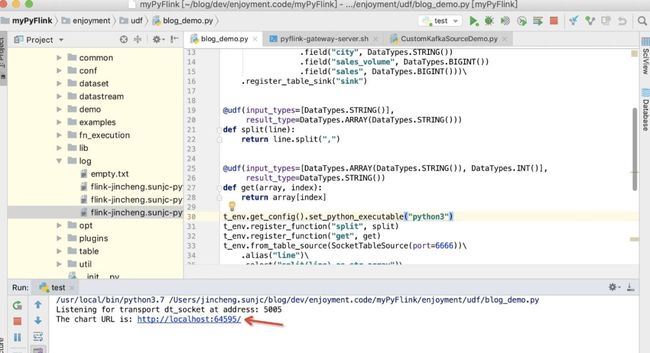
启动 blog_demo,如果一切顺利,启动之后,控制台会输出一个 web 地址,如下所示:
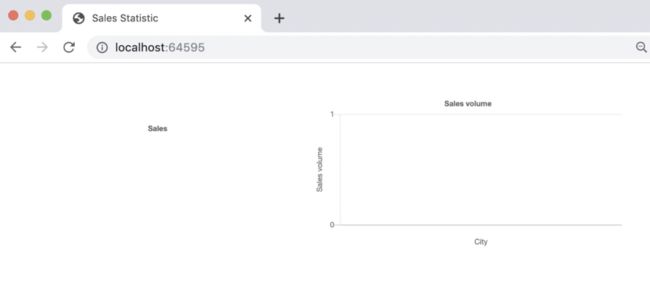
我们打开这个页面,开始是一个空白页面,如下:
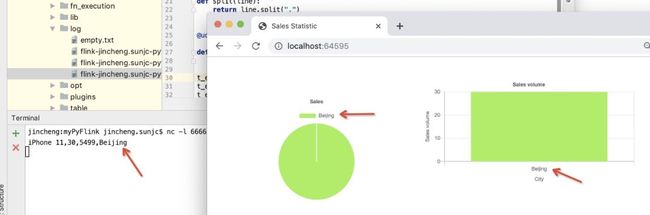
我们尝试将下面的数据,一条,一条的发送给 Source Connector:
iPhone 11,30,5499,Beijing
iPhone 11 Pro,20,8699,Guangzhou
MacBook Pro,10,9999,Beijing
AirPods Pro,50,1999,Beijing
MacBook Pro,10,11499,Shanghai
iPhone 11,30,5999,Shanghai
iPhone 11 Pro,20,9999,Shenzhen
MacBook Pro,10,13899,Hangzhou
iPhone 11,10,6799,Beijing
MacBook Pro,10,18999,Beijing
iPhone 11 Pro,10,11799,Shenzhen
MacBook Pro,10,22199,Shanghai
AirPods Pro,40,1999,Shanghai
当输入第一条订单 iPhone 11,30,5499,Beijing,之后,页面变化如下:
随之订单数据的不断输入,统计图不断变化。一个完整的 GIF 演示如下:

(更清晰的 GIF 演示请点击“阅读原文”)
小结
本篇从架构到 UDF 接口定义,再到具体的实例,向大家介绍了在 Apache Flink 1.10 发布之后,如何利用 PyFlink 进行业务开发,其中 用户自定义 Source 和 Sink部分比较复杂,这也是目前社区需要进行改进的部分(Java/Scala)。真正的核心逻辑部分其实比较简单,为了大家按照本篇进行实战操作有些成就感,所以我增加了自定义 Source/Sink 和图形化部分。但如果大家想简化实例的实现也可以利用 Kafka 作为 Source 和 Sink,这样就可以省去自定义的部分,做起来也会简单一些。
文中绿色字体部分均有跳转,点击「阅读原文」可查看原版文章~
Apache Flink 系列入门教程
▼ 进阶篇
1.Runtime 核心机制剖析
2.时间属性深度解析
3.Checkpoint 原理剖析与应用实践
4.Flink on Yarn / K8s 原理剖析及实践
5.数据类型和序列化
6.Flink 作业执行深度解析
7.网络流控和反压剖析
8.详解 Metrics 原理与实战
▼ 基础篇
1.Flink 基础概念解析
2.Flink 开发环境搭建和应用的配置、部署及运行
3.Flink Datastream API 编程
4.Flink 客户端操作
5.Flink Time & Window
6.Flink 状态管理及容错机制
7.Flink Table API 编程
8.Flink SQL 编程实践
9.5分钟从零构建第一个 Flink 应用
10.零基础实战教程:如何计算实时热门商品
关注 Ververica,获取更多 Flink 技术干货

你也「在看」吗?