二值化神经网络(Binarized Neural Networks, BNN)模型解读
论文链接:https://arxiv.org/pdf/1602.02830.pdf
介绍
时至今日,深度神经网络一般都需要多个GPU才可以训练,这使得在低功耗设备运行神经网络模型有极大的挑战,现在也有大量的研究工作是关于在通用或者专用硬件上做加速。
本篇论文做了以下贡献:
- 介绍了一种训练BNN的方法,在训练阶段使用二值化的权重和激活值计算参数梯度;
- 基于Torch7和Theano框架完成了两个实验,实验结果表明在MNIST、CIFAR-10和SVHN数据集上训练二值化神经网络是可能的,而且都达到了最先进的结果;
- 不管是在训练还是推理阶段,对于前向传播,BNNs可以大幅度减小内存大小和访问量,使用位运算替代算术运算,都可以极大程度的提升能效;而且,二值化的卷积神经网络会导致卷积核复用;
- 最后,自行设计了一种二值矩阵乘法GPU核,在没有任何精度损失的前提下,比未优化前的GPU核在MNIST上的速度快了7倍。
一. 二值化神经网络
在本节主要讨论了二值化函数,展示了如何用它来计算参数梯度,以及通过它如何完成反向传播。
1. 决定式 VS 随机二值化
在训练BNN时,我们将权重和激活值限制为 +1 和 -1,从硬件角度来看这两个值是大有好处的,为了能将真实值转变为这两个值,我们使用两种不同的二值化函数,第一个二值化函数是决定式的:
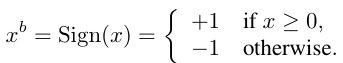
其中x是真实变量值,Sign(x)是符号函数,这样的函数是非常简单粗暴的;第二个二值化函数是随机式的:


随机式的二值化比符号函数看起来要更有吸引力,但是很难实现,因为量化过程中需要硬件产生随机位,因此在实际应用过程中采用第一种函数多一些。
2. 梯度计算和累加
虽然BNN在训练过程中使用的是二值化的权重和激活值,但是梯度值是不可以用二值化存储的,原因在于:
- 随机梯度下降更新参数时,梯度的量级很小;
- 梯度具有累加效果。梯度中是包含有噪声的,而噪声一般都是正态分布的,多次累加可以将噪声平均消耗掉;
而且,当计算参数梯度时,二值化相当于给权重和激活添加了噪声,这类似于正则化使得模型的泛化性能更好。我们训练BNN的方法可以看作是Dropout的一种变体,只是计算参数梯度时Dropout是把一般的激活值设置为0,而二值化网络是对权重和参数进行二值化。
3. 离散化梯度传播
在反向传播过程中要用到符号函数的导数,符号函数的导数几乎处处是0,因此是不可以采用的,我们需要对符号函数进行宽松化,就得到了一种变形:
![]()

二值化操作函数为:
![]()
假设损失函数为C,C对q的导数已知,那么C对r的导数为:
![]()
1|r|<=1 就是Htanh函数;
在具体的算法应用时,对于隐藏层单元:
- 我们利用符号函数的非线性获得激活值,即直接使用Sign(a)获得二值化后的激活值。
- 对于权重,Htanh和Sign两种函数都有用到:
- 在对参数进行更新时,对权重使用Htanh函数进行裁减,使得权重永远在[-1, 1]之间;
- 量化权重时,使用Sign(w)直接得到二值化的权重值;


算法1分为两个步骤,第一个步骤是计算参数梯度,其中又包括前向传播和反向传播两个过程;第二个步骤是对参数梯度进行累加。

4. Shift based Batch Normalization

Batch Normalization,即批量归一化,通常是在送入激活层之前使用,可以加速训练并降低整个权重尺度的影响(因为BN将数据归一化,使之均值为0,标准差为1),但是在训练过程中,BN需要做很多次乘除运算占用了大量的计算力资源和时间。
针对二值化网络中BN层的前向运算,我们设计了一种基于移位的批量归一化技术(SBN)如算法2所示,它将批量归一化中的乘除运算全都变为了移位操作。
BN层的前向传播如下图所示:

通过实验对比发现,用基于移位的BN代替BN没有准确率的损失。
5. Shift based AdaMax
找最优解的一种优化方法,算法如下:

6. First Layer
在BNN中,某一层的输出就是下一层的输入,除了第一层之外所有层的输入都是二值化的,但是这对于我们来说不是一个麻烦,原因有两点:
- 第一层的通道数x相比于内部层来说很少(对于彩色图片来说,就是3),因此不管是从计算量还是参数量来说,第一层都是最小的卷积层;
- 将输入层的像素点用m位定点数表示,举个例子,一般用8位的定点数表示一个像素点,那么我们可以用下面的公式进行优化:

这样的话第一层的运算就是点乘和移位 ,各层的计算方法如下:

针对前向传播的优化主要就是要对二值化的权重与激活值乘法(即+1与-1之间的乘法)做优化,作者的GPU矩阵乘法核就是基于此优化实现的,优化方法主要就是xnor和popcount操作,xnor操作就是按位异或操作,popcount就是计算一个二进制串中的"1"的数目。
举个例子说明:假设某一层隐藏层的激活向量二值化后a=[1,-1, 1, 1, -1],同时又有二值化后的权值W=[-1,1,1,-1,-1]。在程序中是以a=[1,0,1,1,0],W=[0,1,1,0,0]表示的。
那么按照正常的乘法应该是:a1*w1+a2*w2+a3*w3+a4*w4+a5*w5=1*-1+-1*1+1*1+1*-1+-1*-1=-1
按照作者给出的操作应该是:a^W=[1^0,0^1,1^1,1^0,0^0]=11010,popcount(a^w)=3
然后使用-(2 x popcount(a^w) - len(vecor_length)),这里vector_length = 5,因此,最后的结果是-1,与我们直接对a和w做乘加运算的结果相同。
二. Benchmark Results
- 在Torch7实验中,在训练阶段激活值是采用随机二值化的,而在Theano中是确定式二值化的;
- 在Torch7中,我们使用基于移位的BN和AdaMax。而在Theano中,使用的是vanilla BN和AdaMax。


三. Very Power Efficient in Forward Pass
无论是通用的还是专用的计算机硬件,都是由存储器、算术运算器进而控制单元组成,在前向传播过程中,BNN可以大幅度地减少内存大小和访问量,使用移位操作代替算术运算导致能效的大大提高;而且,二值化的CNN导致了卷积核的复用,使得时间复杂度降低了60%。
1. 内存大小和访问量
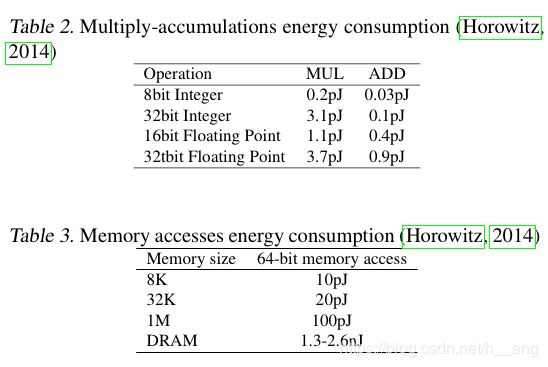
与32位的DNN相比,BNN内存大小和访问量均减少了32倍。
2. XNOR-Count
深度学习中最主要的运算就是乘加运算,在BNN中,权重和激活值都被约束为-1和1。因此,大多数32位浮点数乘加运算可以被1位XNOR-Count操作代替,这将会给硬件带来重大影响,举个例子,32位浮点数乘法运算需要200 Xilinx FPGA slices,而1位XNOR仅需要一个slice。
3. 利用 Filter Repetitions
二值化的卷积网络中卷积核的数量是由卷积核的尺寸决定的。举个例子,如果卷积核的尺寸是 3 x 3,那么不同的二维卷积核数量上限就是 2^9 = 512个,但是通常卷积核都是三维的,假定Ml表示第l层卷积核的数量,那么我们需要存储一个4维矩阵 Ml x M(l-1) x k x k,所以,不同的三维卷积核数量上限就是 2 **(M(l-1) x k x k)。
因为我们现在有二值化的卷积核,许多 k x k 的二维卷积核都是重复的,通过使用专用的硬件,我们可以仅仅用不同的卷积核在feature map上做卷积,然后合理的进行加减就可以得到 3维卷积的结果。同时类似于[-1, 1, -1]和[1, -1, 1]可以看作是重复的。通过这种复用同一层卷积核的数量平均可以降低到原来的42%,XNOR-popcount 操作的数量可以减少3倍。
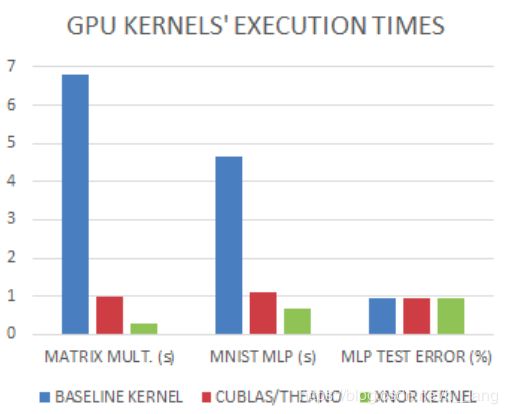
4. Seven Times Faster on GPU at Run-Time
通过在寄存器内部使用一种叫做SIMD方法角度BNN的GPU核实现,其基本思想是在一个32位寄存器中存储32位二值化变量,从而在位操作上获得32倍的加速。使用SWAR,仅3个指令就可以计算32个connections,从而原来32个时钟周期才可以做完的操作现在只需要 1 + 4 + 1 = 6个时钟,达到了32/6=5.3倍的加速。
为了验证上面的理论结果,设计了两个GPU核,一个是未经优化的乘法核,另一个是采用了SWAR进行优化的XNOR核,两者的对比如下:
四. 展望
未来的工作应该是探索进一步加速训练时间(比如通过二值化一些梯度),还有就是将基准测试的结果扩展到其他模型或者数据集上。
源码链接:https://github.com/MatthieuCourbariaux/BinaryNet