基于RISC-V的计算机原理 -chapter2-2
stored-program concept:
The idea that instructions and data of many types can be stored in memory as numbers and thus be easy to change, leading to the stored-program computer.
Hardware:
下图给出了本章所涵盖的指令集的预览;


2.2 Operations of the Computer
每台计算机都必须能够进行运算,RISC-V汇编语言符号:
add a, b, c
指示计算机将两个变量b和c相加,并将它们的和放入a中。
这种表示法是严格的——每个RISC-V算术指令只执行一个操作,并且必须始终正好有三个变量。
例如,假设我们要将四的和
变量b、c、d和e变成变量a(在这一节中,我们故意含糊其辞地说明什么是“变量”;在下一节中,我们将详细解释。)下面的指令序列添加了四个变量:
add a, b, c // The sum of b and c is placed in a
add a, a, d // The sum of b, c, and d is now in a
add a, a, e // The sum of b, c, d,
因此,四个变量加起来需要三条指令,上面每一行的双斜杠(//)右边的单词是对人类读者的注释,所以计算机会忽略它们。注意,与其他编程语言不同,这种语言的每一行最多只能包含一条指令。与C的另一个区别是,注释总是以行的结尾结束。
要求每条指令只有三个操作数,不多也不少,这符合保持硬件简单的原则:操作数可变的硬件比固定数的硬件复杂。这种情况说明了硬件设计的三个基本原则之一:
Design Principle 1: Simplicity favors regularity(简洁有规律)
在下面的两个例子中,我们可以展示c语言编写的程序与用这种更原始的符号表示的程序之间的关系
ex1:
a = b + c;
d = a -e;
RISC-V指令对两个源操作数进行操作,并将结果放在一个目标操作数中。因此,上面的两个简单语句直接编译成这两个RISC-V汇编语言指令:
add a, b, c
sub d, a, e
ex2:
f = (g + h) −(i + j);
编译器必须将此语句分解为几个汇编指令,因为每个RISC-V指令只执行一个操作。
第一条RISC-V指令计算g和h的和。我们必须将结果放在某个地方,这样编译器就创建了一个临时变量t0
add t0, g, h
虽然下一步的运算是减法,但在减法之前我们需要计算i和j的和。因此,第二条指令将i和j的和放入编译器创建的另一个临时变量t1中:
add t1, i, j
最后,减法指令从第一个和中减去第二个和,并将差放入变量f中,完成编译代码:
sub f, t0, t1
了解:
为了提高可移植性,Java最初被设想为依赖于一个软件解释器。这个解释器的指令集称为Java字节码(见2.15节),这与RISC-V指令集有很大不同。为了使性能接近于同等的C程序,现在的Java系统通常将Java字节码编译成本机指令集,如RISC-V。由于这种编译通常比C程序要晚得多,因此这种Java编译器通常被称为实时(JIT)编译器。第2.12节显示了在启动过程中jit如何比C编译器使用得晚,第2.13节显示了编译与解释Java程序。
2.3计算机硬件的操作数
与高级语言的程序不同,
算术指令的操作数是受限制的;它们必须来自直接建立在称为寄存器的硬件中的有限数量的特殊位置。
寄存器:是硬件设计中使用的”原语“(当计算机完成时,程序员也可以看到这些原语,因此可以将寄存器视为计算机构造的砖块。)
RISC-V体系结构中寄存器的大小是64位;64位的组出现得太频繁,以至于在RISC-V体系结构中给它们命名为双字——doubleword。(另一个流行的大小是一组32位,在RISC-V体系结构中称为word)
word
A natural unit of access in a computer, usually a group of 32 bits.
doubleword
Another natural unit of access in a computer, usually a group of 64 bits; corresponds to the size of a register in the RISC-V architecture.
一种编程语言的变量和寄存器之间的一个主要区别是寄存器的数量是有限的,通常在当前的计算机上是32个,比如RISC-V(寄存器数量的历史记录见2.21节)。
在本节中,我们增加了一个限制,即RISC-V算术指令的三个操作数必须分别从32个64位寄存器中选择一个。
限制32个寄存器的原因体现了硬件技术的三个基本设计原则之二:
Design Principle 2:Smaller is faster.
1)大量的寄存器可能会增加时钟周期时间(because it takes electronic signals longer when they must travel farther.)(Another reason for not using more than 32 is the number of bits it would take in the instruction format, as Section 2.5 demonstrates. )
2) 这个原则不是绝对的Guidelines such as “smaller is faster” are not absolutes; 31 registers may not be faster than 32.
3)第4章说明了寄存器在硬件结构中的中心作用;正如我们将在该章中看到的,寄存器的有效使用对程序性能至关重要。
ex1:
将程序中写的变量和寄存器联系起来是编译器的工作:
例如,我们前面的例子中的赋值语句:
f=(g+h)—(i+j);
变量f、g、h、i和j分别分配给寄存器x19、x20、x21、x22和x23。编译的RISC-V代码是什么?
编译后的程序与前面的示例非常相似,只是我们用上面提到的寄存器名加上两个临时寄存器x5和x6替换变量,这两个临时寄存器对应于上面的临时变量:
add x5, x20, x21// register x5 contains g + h
add x6, x22, x23// register x6 contains i + j
sub x19, x5, x6// f gets x5 –x6, which is (g + h)-(i + j)
Memory Operands:
过渡:编程语言既有简单的数据类型,也有复杂的,如数组,结构 。如果复合数据结构可以包含比计算机中的寄存器更多的数据元素。计算机如何表示和访问?
回想一下第一章中介绍并在第61页重复的计算机的五个部件。处理器只能在寄存器中保留少量数据,但计算机内存包含数十亿个数据元素。因此,数据结构(数组和结构)保存在内存中
如上所述,算术运算只发生在RISC-V指令中的寄存器上;因此,RISC-V必须包括在存储器和寄存器之间传输数据的指令。——这种指令称为数据传输指令。要访问内存中的字或双字,指令必须提供内存地址。
内存只是一个大的一维数组,地址作为该数组的索引,从0开始。
例如,在下图中,第三个数据元素的地址是2,内存[2]的值是10。

如果这些元素是双字,那么这些地址就不正确,因为RISC-V实际上使用字节寻址,每个双字表示8个字节。图2.3显示了顺序双字地址的正确内存寻址:下图是实际RISC-V内存地址,由于RISC-V对每个字节进行寻址,双字地址是8的倍数:双字中有8个字节。

计算机基于此,分成使用最左边或“大端”字节的地址作为双字地址的计算机和使用最右边或“小端”字节的计算机。RISC-V属于后一个阵营。这个顺序只在以双字和八个单独字节访问相同数据时才重要,所以很少有人需要知道。
注意:字节寻址也会影响数组索引。
To get the proper byte address in the code above, the offset to be added to the base register x22 must be 8×8, or 64, so that the load address will select A[8] and not A[8/8].
Load and store:
The instruction complementary to load is traditionally called:store它将数据从寄存器复制到存储器
The format of a store is similar to that of a load: the name of the operation, followed by the register to be stored, then the base register, and finally the offset to select the array element
在许多体系结构中,要求数据在内存中按自然边界对齐,即word必须从4的倍数的地址开始,dw必须从8的倍数的地址开始。此要求称为对齐限制(第4章说明了对齐导致更快的数据传输的原因)。RISC-V和Intel x86没有对齐限制,但MIPS有。
由于加载和存储中的地址是二进制数(As the addresses in loads and stores)我们可以看到为什么主内存的DRAM是二进制大小,而不是十进制大小。(use the term tebibyte (TiB) for 240 bytes, defining terabyte (TB)
ex1:
假设变量h与寄存器x21关联,并且数组A的基址(A[0])在x22中。下面C赋值语句的RISC-V汇编代码是什么?
A[12]=h+A[8];
虽然C语句中只有一个操作,但现在有两个操作数在内存中,因此我们需要更多的RISC-V指令。
ld x9, 64(x22) // Temporary reg x9 gets A[8]
add x9, x21, x9 // Temporary reg x9 gets h + A[8]
最后一条指令用96(8×12)作为偏移量,寄存器x22作为基址寄存器,将和存储在A[12]中
sd x9, 96(x22)// Stores h + A[8](x9) back into A[12]
许多程序的变量多于寄存器数量,因此,编译器试图保持寄存器中最常用的变量,其余的放在内存中,使用加载和存储在寄存器和内存之间移动变量。把不常用的变量(或以后需要的变量)放入内存的过程称为溢出寄存器。(spilling registers)
一个RISC-V算术指令可以读取两个寄存器,对它们进行操作,并写入结果。
RISC-V数据传输指令只读取一个操作数或写入一个操作数,而不对其进行操作。
因此,寄存器比内存占用更少的访问时间和更高的吞吐量,使得寄存器中的数据访问速度和使用更简单。访问寄存器也比访问内存消耗更少的能量。实现最高性能和节能,指令集体系结构必须有足够的寄存器,编译器必须有效地使用寄存器
ex:让我们看看寄存器与内存的能量和性能。假设是64位数据,寄存器的速度大约是2015年DRAM的200倍,能效是DRAM的10000倍.这些巨大的差异导致了缓存,从而降低了进入内存的性能和能量损失
Constant or Immediate Operands:
很多时候程序会在一个操作中使用一个常量,例如,递增一个索引以指向数组的下一个元素。(事实上,在运行SPEC CPU2006基准测试时,超过一半的RISC-V算术指令都有一个常量作为操作数)仅使用我们目前看到的指令,我们就必须从内存中加载一个常量才能使用它。(当程序加载时,常量会被放入内存中)例如,要将常量4添加到寄存器x22,我们可以使用代码
ld x9, AddrConstant4(x3) // x9 = constant 4,假设x3+AddrConstant4是常数4的内存地址。
add x22, x22, x9
另一种避免加载指令的方法是提供算术指令的版本,其中一个操作数是常数。这种带有一个常量操作数的快速加法指令称为add immediate或addi。要将4添加到寄存器x22,我们只需编写
addi x22,x22,4//x22=x22+4
常量操作数经常出现;事实上,addi是大多数RISC-V程序中最流行的指令。通过在算术指令中包含常量,运算比从内存加载常量要快得多,并且消耗的能量更少。
常数零还有另一个作用,那就是通过提供有用的变量来简化指令集。例如,可以使用带零的子指令否定寄存器中的值,例如,可以使用第一个操作数为零的子指令对寄存器中的值求反。因此,RISC-V指定寄存器x0硬连接到值0。The using frequency of it justify the inclusions of constants is another example of the great idea from of making the common case fast.
1)尽管本书中的RISC-V寄存器是64位宽的,但是RISC-V架构师构想了ISA的多种变体。除了这个称为RV64的变体之外,一个名为RV32的变体还有32位寄存器,其降低的成本使RV32更适合于非常低成本的处理器。
2)RISC-V偏移量加上基址寄存器的寻址方式is an excellent match to structures as well as arrays, since the register can point to the beginning of the structure and the offset can select the desired element.
3)数据传输指令中的寄存器最初是为了保存一个带有偏移量的数组的索引而发明的,用于数组的起始地址。因此,基址寄存器也称为索引寄存器,今天的存储器要大得多,数据分配的软件模型也更为复杂,因此the base address of the array is normally passed in a register since it won’t fit in the offset, as we shall see.
4)从32位地址计算机到64位地址计算机,意味着编译器编写器可以选择C语言中数据类型的大小。显然,指针应该是64位的,但是整数呢?此外,C具有int、long int和long long int数据类型。问题来自于从一种数据类型转换到另一种数据类型,在C代码中存在意外溢出,不幸的是,这不是罕见的。为了保持示例的简单性,在本书中,我们假设指针都是64位的,并声明所有的C整数都是长整数,以保持它们的大小相同。
2.4 Signed and Unsigned Numbers
首先,快速回顾一下计算机是如何表示数字的。人类被教导用基数10来思考,但数字可以用任何基数来表示。
数字作为一系列高电平和低电平电子信号保存在计算机硬件中,因此它们被认为是基2数字。
least significant bit:The rightmost bit in an RISC-V doubleword.
most significant bit:The leftmost bit in an RISC-V doubleword
RISC-V双字的长度是64位,因此我们可以表示so we can represent 2^64 different 64-bit patterns. It is natural to let these combinations represent the numbers from 0 to 2^(64 -1)(18,446,774,073,709,551,615ten)
11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111101 two= 18,446,774,073,709,551,613ten
11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111110 two= 18,446,744,073,709,551,614ten
11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111111 two= 18,446,744,073,709,551,615ten
也就是说,64位二进制数可以用位值乘以2的幂来表示(这里席是指X的第i位):
![]()
由于我们很快就会看到的原因,这些正数被称为无符号数。
ps:
基2对人类来说是不自然的;我们有10个手指,所以发现基10是自然的。为什么计算机不使用十进制?
事实上,第一台商用计算机确实提供了十进制算法。问题是计算机仍然使用开关信号,所以一个十进制数字只是由几个二进制数字表示。十进制被证明是低效的,后来的计算机将还原为所有二进制。
数字实际上有无穷多个数字,除了一些最右边的数字外,几乎所有的数字都是0。我们通常不显示前导0。硬件可以设计成对这些二进制位模式进行加、减、乘和除。
如果这类操作的正确结果数字不能由这些最右边的硬件位表示,则称发生了溢出。
计算机程序计算正数和负数,所以我们需要一种能区分正数和负数的表示法。最明显的解决方案是添加一个单独的符号,它可以方便地用一个位表示;
首先,在哪里放置标志位并不明显。右边?在左边?早期的电脑两者都试过了。
其次,符号和数量的加法器可能需要额外的步骤来设置符号,因为我们无法预先知道正确的符号是什么。
最后,一个单独的符号位意味着符号和量值都有一个正零和一个负零,这可能会给不注意的程序员带来问题。
Because of these shortcomings, sign and magnitude representation was soon abandoned.In the search for a more attractive alternative, the question arose。
如果我们试图从一个小数字中减去一个大数字,无符号数字的结果是什么。答案是,它将尝试从前导0的字符串中借用,因此结果将具有前导1的字符串。考虑到没有明显更好的选择,最后解决方案是选择使硬件简单的表示:前导0表示正,前导1表示负。
这个表示有符号二进制数的约定称为two’s complement representatio
但是:
| Two’s complement does have one negative number that has no |
| corresponding positive number: -9,223,372,036,854,775,808ten. |
这种不平衡对不专心的程序员来说也是一个问题,但是sign和magnity对程序员和硬件设计者来说都有问题。
Two’s complement does have one negative number that has no corresponding positive number,2的补码表示法的优点是所有负数在最重要的位上都有1。因此,硬件只需要测试这个位,看看一个数字是正数还是负数(数字0被认为是正数)。
What is the decimal value of this 64-bit two’s complement number?
11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111100 two

正如对无符号数字的操作会溢出硬件的容量来表示结果一样,对两个补数的操作也会溢出硬件的容量。
有符号加载与无符号加载既适用于加载,也适用于算术加载。有符号加载的功能是重复复制符号以填充寄存器的其余部分(称为符号扩展),但其目的是在该寄存器中放置数字的正确表示。无符号加载只需在数据的左边填充0,因为位模式表示的数字是无符号的。将64位双字加载到64位寄存器中时,该点是无意义的;有符号和无符号加载是相同的。
RISC-V确实提供了两种类型的字节加载:加载字节无符号(lbu)将该字节视为无符号数,因此零扩展以填充寄存器的最左边的位,而加载字节(lb)使用有符号整数。由于C程序几乎总是使用字节来表示字符,而不是将字节视为非常短的有符号整数,
lbu实际上只用于字节加载。
与上面讨论的有符号数字不同,内存地址自然从0开始,一直到最大的地址。换句话说,负地址是没有意义的。
方法2:2
2ten=00000000 00000000 00000000 00000000 00000000 00000000
00000000 00000010
Negating this number by inverting the bits and adding one,

用n位表示的一个数,用多于n位表示。捷径是从较小数量的符号位中取最有效的位,然后复制它以填充较大数量的新位。
这个技巧之所以有效,是因为正数2的补数在左边有无穷多个0,负数2的补数有无穷多个1。表示数字的二进制位模式隐藏前导位以适应硬件的宽度;符号扩展只是还原其中的一些。
2.5在计算机中表示指令
指令作为一系列高电平和低电平电子信号保存在计算机中,可以用数字表示。
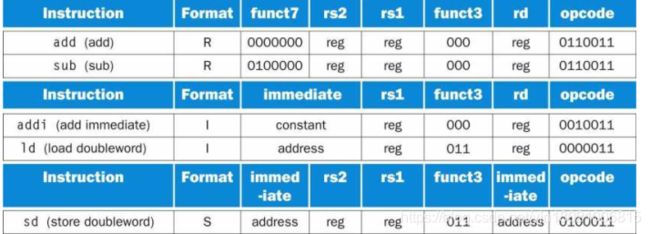
Translating a RISC-V Assembly Instruction into a Machine Instruction:
ex1:我们将展示真正的RISC-V语言版本的指令,用符号表示为add x9, x20, x21

指令的每一段都称为字段。第一、第四和第六字段(在本例中包含0、0和51)共同告诉RISC-V计算机该指令执行加法。第二个字段给出加法运算的第二个源操作数(21表示x21)的寄存器编号,第三个字段给出加法运算的另一个源操作数(20表示x20)。第五个字段包含寄存器的编号,第五个字段包含要接收总和的寄存器的编号(x9为9)。因此,此指令添加寄存器
x20到寄存器x21并将和放入寄存器x9。
为什么经常用16进制:一长串令人厌烦的二进制数字。我们通过使用比二进制更高的基数来避免这种单调乏味的情况,这种基数很容易转换成二进制。由于几乎所有的计算机数据大小都是4的倍数,所以十六进制(以16为基数)数字很受欢迎。由于基数16是2的幂,我们可以通过用一个十六进制数字替换四个二进制数字的每组来进行简单的转换,反之亦然。

RISC-V字段被命名以便于讨论:

当指令需要比上面显示的字段更长的字段时,就会出现问题。例如,加载寄存器指令必须指定两个寄存器和一个常量。如果地址使用上述格式的5位字段之一,则加载寄存器指令中的最大常量将仅限于25-1或31。此常量用于从数组或数据中选择元素
结构,通常需要比31大得多。这个5位字段太小,无法使用。
Hence, we have a conflict between the desire to keep all instructions the same length and the desire to have a single instruction format. 这种冲突导致我们得出最终的硬件设计原则:
Design Principle 3: Good design demands good compromises
RISC-V设计人员选择的折衷方案是保持所有指令的长度相同,而对于不同类型的指令需要不同的指令格式。
例如,上面的格式称为R-type(用于寄存器)。
第二种指令格式是I-type,由一个常量操作数(包括addi)的算术操作数和加载指令使用。I-type格式的字段是12位立即数被解释为2的补码值,所以它可以表示从-2^11到2^11-1的整数。当I-type格式用于加载指令,立即数表示字节偏移量,因此加载双字指令可以引用 any doubleword within a region of ±2^11 or 2048 bytes (±2^8 or 256 doublewords) of the base address in the base register rd.
让我们看看第71页的加载寄存器指令:
ld x9,64(x22)//Temporary reg x9得到一个[8]
这里,22(对于x22)放在rs1字段中,64放在immediate字段中,9(对于x9)放在rd字段中。
S-type格式的12位immediate被分成两个字段,分别提供低5位和高7位。RISC-V架构师之所以选择这种设计,是因为它在所有指令格式中将rs1和rs2字段保持在同一位置。尽可能保持指令格式的相似性可以降低硬件复杂性

In case you were wondering, the formats are distinguished by the values in the opcode field: each format is assigned a distinct set of opcode values in the first field (opcode) so that the hardware knows how to treat the rest of the instruction.
我们现在可以举一个例子,从程序员写什么到计算机执行什么。
If x10 has the base of the array A and x21 corresponds to h, the assignment statement
A[30] = h + A[30] + 1;
is compiled into:
ld x9, 240(x10) // Temporary reg x9 gets A[30],30*8=240
add x9, x21, x9 // Temporary reg x9 gets h+A[30],
addi x9, x9, 1 // Temporary reg x9 gets h+A[30]+1
sd x9, 240(x10) // Stores h+A[30]+1 back into A[30]
保持所有指令大小相同的愿望与拥有尽可能多的寄存器的愿望冲突,因为寄存器数量的任何增加都会在指令格式的每个寄存器字段中至少多消耗一个位。
考虑到这些限制和更小更快的设计原则,现在大多数指令集都有16或32个通用寄存器
RISC-V汇编语言程序员在处理常量时不必使用addi。程序员只需编写add,汇编程序就会生成正确的操作码和正确的指令格式,这取决于操作数是全部寄存器(R-type)还是一个常量(I-type)。
对于不同的操作码和格式,我们使用RISC-V中的显式名称,因为我们认为在引入汇编语言和机器语言时比较容易混淆
尽管RISC-V既有add指令又有sub指令,但它没有与addi对应的subi。这是因为immediate字段表示2的补码整数,所以addi可用于减去常量。
我们将在第4章中看到,相关指令的二进制表示的相似性简化了硬件设计。这些相似性是RISC-V体系结构中规则性的另一个例子。
到目前为止,三种RISC-V指令格式是R,I,S;
R-type格式有两个源寄存器 操作数和一个目标寄存器操作数。
I-type格式将一个源寄存器操作数替换为12位立即字段。
S-type格式有两个源操作数和12位立即数字段,但不是目标寄存器操作数。S-type立即数字段分为两部分,在最左边的字段和第二个最右边的位4-0字段。
今天的计算机基于两个关键原则:
1、指令用数字表示。
2、程序像数据一样存储在存储器中,以便读或写。这些原理引出了存储程序的概念
图2.7展示了这个概念的强大功能;特别是,内存可以包含编辑器程序的源代码、相应的编译机器代码、编译程序正在使用的文本,甚至生成机器代码的编译器。
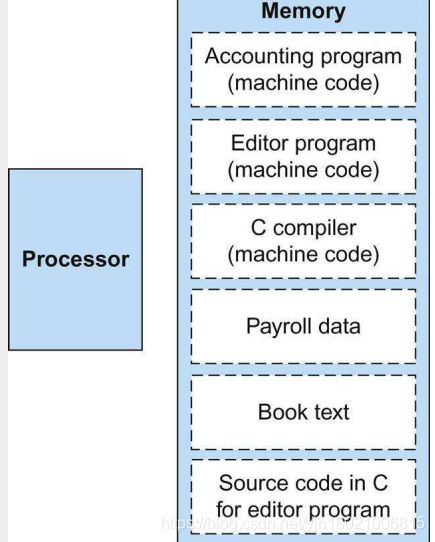
Stored programs allow a computer that performs accounting to become a computer that helps an author write a book.
The switch 只需将程序和数据加载到内存中,然后告诉计算机在内存中的给定位置开始执行。
把指令当作数据处理,大大简化了both the memory hardware and the software of computer systems.
具体来说,数据所需的存储技术也可以用于程序,programs like compilers, for instance, can translate code written in a notation far more convenient for humans into code that the computer can understand.
One consequence of instructions as numbers is程序通常以二进制数字的文件形式发送。