文章目录
- 1、重复元素判定
- 2、字符元素组成是否相同的判定
- 3、查看变量的内存占用
- 4、查看字符串占用的字节数
- 5、打印某个字符串n次,不需要循环
- 6、切割列表的元素,分成指定元素个数(n)的若干个列表
- 7、压缩:去掉布尔型元素
- 8、解包:将打包好的列表按照类别分成元组
- 9、链式对比
- 10、逗号链接:join
1、重复元素判定
def If_uni(li):
return len(li) == len(set(li))
x = [1, 2, 3, 3, 4, 4, 5, 6, 7]
y = [1, 2, 3, 4, 5]
z = ('a', 'b', 'c', 1, 2, 3)
v1 = If_uni(x)
v2 = If_uni(y)
v3 = If_uni(z)
print(v1, v2, v3, sep='\n')

2、字符元素组成是否相同的判定
from collections import Counter
def anagram(one, two):
return Counter(one) == Counter(two)
v = anagram("abcd3", "3acdb")
print(v)

3、查看变量的内存占用
import sys
v1 = 30
v2 = "I love China!"
print(sys.getsizeof(v1), sys.getsizeof(v2), sep='\n')

4、查看字符串占用的字节数
def byte_size(string):
return(len(string.encode('utf-8')))
v1 = byte_size('')
v2 = byte_size('Hello World')
print(v1, v2, sep='\n')
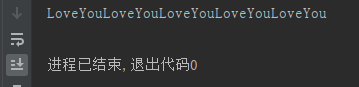
5、打印某个字符串n次,不需要循环
n = 5
s ="LoveYou"
print(s * n)
6、切割列表的元素,分成指定元素个数(n)的若干个列表
from math import ceil
def chunk(lst, n):
return list(
map(lambda x: lst[x * n:x * n + n],
list(range(0, ceil(len(lst) / n))))
)
v1 = chunk([1,2,3,4,5,6,7,8],3)
print(v1)

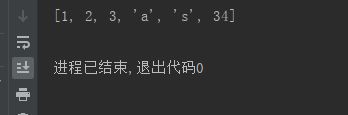
7、压缩:去掉布尔型元素
def compact(lst):
return list(filter(bool, lst))
v1 = compact([0, 1, False, 2, '', 3, 'a', 's', 34])
print(v1)
8、解包:将打包好的列表按照类别分成元组
a = [['a', 'b'], ['c', 'd'], ['e', 'f']]
transposed = zip(*a)
print(transposed)

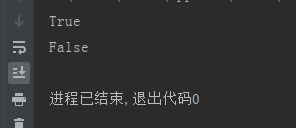
9、链式对比
a = 5
print( 2 < a < 8)
print(1 == a < 2)
10、逗号链接:join
hobbies = ["basketball", "football", "swimming"]
print("My hobbies are: " + ", ".join(hobbies))
