【MySQL优化】一分钟带你了解单表优化
点击查看MySQL优化系列文章集锦,从头到尾全部案例均配备源码,让你轻松看文章,轻松实践
如你不想自己测试案例,可直接看优化总结,了解知识点即可
单表优化
- sql创建代码
- 添加测试数据
- 查询表数据
- sql需求:
- 写出SQL语句并执行
- 初步分析SQL语句
- 建立索引
- 在次使用explain分析
- 删除索引
- 重新建立索引,并查看分析
- 此次优化总结
- 博主微信欢迎交流
sql创建代码
CREATE TABLE IF NOT EXISTS `article` (
`id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
`author_id` INT(10) UNSIGNED NOT NULL,
`category_id` INT(10) UNSIGNED NOT NULL,
`views` INT(10) UNSIGNED NOT NULL,
`comments` INT(10) UNSIGNED NOT NULL,
`title` VARBINARY(255) NOT NULL,
`content` TEXT NOT NULL
);
添加测试数据
INSERT INTO `article` ( `author_id`, `category_id`,`views`,`comments`, `title` ,`content`) VALUES
(1, 1,1,1,'1','1'),
(2,2,2,2, '2', '2'),
(1, 1,3,3,'3', '3');
查询表数据
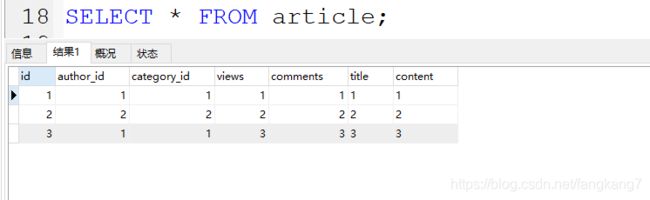
sql需求:
查询category_ id 为1且comments大于1的情况下,views最多的文章ID
写出SQL语句并执行
select id,author_id from article where category_id=1 and comments>1 order by views;
可以对比上边表数据对照看

初步分析SQL语句
可以看到进行了全表扫描,并且使用了文件排序 这种SQL是必须进行优化的

建立索引
# 创建索引
create index ind_article_ccv on article(category_id,comments,views);
# 查看表的所有索引
show index from article

在次使用explain分析
explain select id,author_id from article where category_id=1 and comments>1 order by views;
发现全表扫描我们解决了,但是文件排序还没有解决。那么这个方案也是不可以的

删除索引
# 删除索引
drop index ind_article_ccv on article
# 查看表的所有索引
show index from article

重新建立索引,并查看分析
那么我们在来给caterory_id和view建立一个索引
# 创建索引
create index ind_article_cv on article(category_id,views);
# 分析语句
explain select id,author_id from article where category_id=1 and comments>1 order by views;

此次优化总结
- 在第一次给三个字段都加上索引后,type变成了range这个是可以忍受的,但是extra里使用了filesort仍是无法忍受的
- 但是我们已经给他们三个字段建立了索引了,为什么没有用呢?
- 这是因为根据Btree索引的工作原理
- 先进行排序category_id
- 如果遇到相同的category_id则在排序comments,如果在遇到comments则再排序views
- 当comments字段在联合索引里处于中间位置时
- 因为comments>1是一个范围值(所谓range)
- MySQL无法利用索引在对后边的views部分进行检索,即range类型查询字段后面的索引会失效
博主微信欢迎交流
