文献阅读《SNIPER: Efficient Multi-Scale Training》
本周阅读了《SNIPER: Efficient Multi-Scale Training》这篇文献,在这篇文章中作者认识到了现有的proposal算法的种种不足,从而在《An Analysis of Scale Invariance in Object Detection – SNIP》提出了所谓正则尺度化图像金字塔的推荐算法,使用多个像素等级输入图片进行训练和测试,对于过大的输入图片则采取裁剪出部分目标来进行识别,而不是用单纯用anchor去提取目标。而SNIPER这篇文章作为它的姊妹篇或者加强版,主要讨论了在对大尺寸图片进行裁剪时,裁剪出的碎片的进一步处理问题。
首先在Introduction中介绍了本篇的中心思想:
目前的目标检测架构都是对输入图像的所有像素进行操作,从而产生proposals等,当采用多尺度的图像金字塔时,所需的存储空间很大,在训练时,单一GPU上能训练的图像数量很小(取决于GPU的显存和图像的分辨率),这样就造成了batch size很小,从而使训练时间很长。
但是现研究表明再进行多尺度训练的时候,实际上忽略一部分过大或者过小的目标是比较有利的。那这样的话,作者就认为我们每次都将全部图片都进行上下采样得到多尺度金字塔实际上没有必要。我们实际上可以用包围小目标的较小尺寸的图片碎片来进行训练和测试就可以加速训练和测试过程(SNIP的算法)。但在使用小图片来识别小目标的时候,由于小图片的上下文信息比较少,一般来说会提高假阳性率。如何去平衡这个上下文信息和加速训练间的关系就是这篇文章的中心
接着在背景中回顾过往的算法并提出新的算法
一开始的RCNN本身具有很好的尺度不变性,因为它先从图片中提取proposal,然后都resize到224去提取特征但是这样每个proposal不共享特征的计算,很慢,而Fast系列为了解决这个问题,输入大小不固定,不同尺度的图片都经过同一个的CNN提取特征然后拿proposal去对应位置扣特征,这就破坏了RCNN原来的尺度不变性,但是它很快且整体做特征提取能捕捉更多的context,得到广泛的应用。
而现在大家为了解决Fast系列的问题,往往进行多尺度的训练。RCNN中只对扣出来的proposal进行放缩,小的proposal会放大,合适的proposal就会不怎么变,太大的proposal会放小,总之都会resize到一个固定的尺度,检测网络只用适应这一种尺度,而Fast系列多尺度训练时,不管图片中的proposal大还是小都要跟着图片整体做放大或者缩小,这样检测网络还是去适应这些尺度,而且上一篇中引用Naiyan Wang的说法: 这更多是通过CNN来通过GPU的本身性能来强行存贮不同尺寸的物体来达到的,这其实浪费了大量的GPU性能。
而SNIP则独辟蹊径,它忽略了掉大图中的大proposal和小图中的小proposal,在训练时在某一个scale上只回传指定尺寸范围内的proposal,在测试时则构建一个输入图像金字塔,金字塔上的每一张图片只测试该图片指定尺度范围内的目标,最终合并做NMS输出结果。但这仍然是全像素的训练,相对还是比较慢。而SNIPER则是针对大图中分割出来的碎片(chips),它将这些chips都采样到512*512大小,不论它们来自图片金字塔的哪个级层。问题是与原始图像相比,这种仅仅是根据GT生产的chips是很小,大部分的图片背景都难以参加训练。这会导致ft增加。因此我们还需要生成一些包含负样本的chips来减少fp
而文章的主体则讲述了chips的生成,以及如何选择positive/negative chips.
SNIPER在每一张图像上产生n种不同尺度的chips,分别为{s_1,…s_n},每一种尺寸产生的chips记为C_i。对于每一种尺度,首先将图片resize到对应的W_i * H_i大小。然后用K*K大小的chips按d个像素等距离放置在图片上。这样就生成了chips
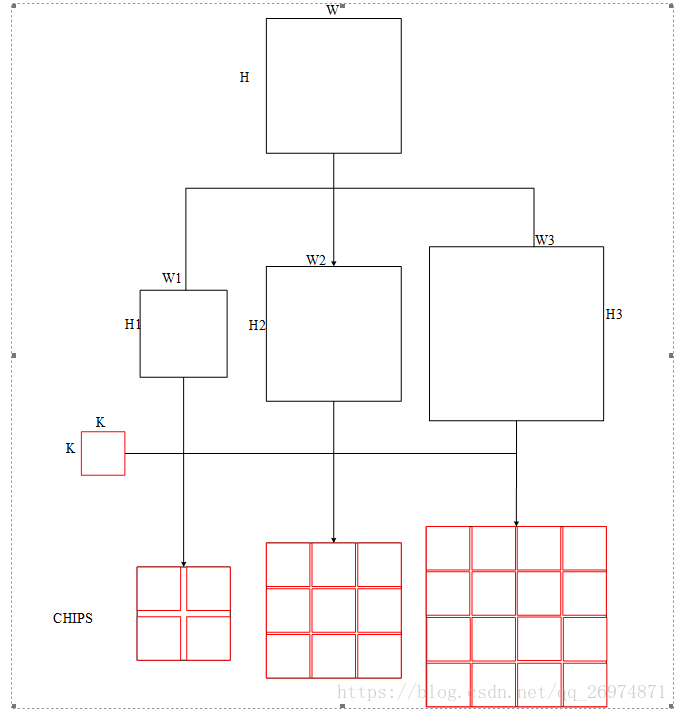
Positive Chip Selection
对于每一种尺寸产生的chips,都会选定一个有效范围,Ri=[rmax,rmin]在面积限定范围内的gt bbox被记为gi 。我们选定的该chip区域,要完全包含符合面积条件的所有对象。最后我们把所有的chips结合到一块,就应该包含整张图像所有我们要进行训练的对象。对于每一个gt bbox,可能同时被多个尺寸的chips包含在内,也可能在同一尺寸的多个chips内。与某一chip有部分重叠,没有完全包含在该chip内的gt instances,超出的部分被剪裁掉,但是仍然参与后面的标签分配。
因为作为网络输入的chips的size远远小于原始图像的size,而且SNIPER通过挑选chips的方式,去除了训练样本中大量的background,因此,可以有效的节省存储空间,提高训练速度。下图是选择chips的一个例子

可以看到组左图中可以生成不同范围的chips(虚线框),右图中可以看到这些chips都是统一大小,所以在不同chips上的有效目标和无效目标是不尽相同(绿色实线标识,不同chips的有效范围Ri不同)
Negative Chip Selection
我们知道Positive Chip包含了所有正样本,但是它们包含的背景实在太少了,这样网络见到的都是易于识别出物体的chip,这样难免会出现很多False Positive,所以需要生成一些Negative Chip来参与训练,这些Negative Chip代表的就是那些带有挑战性的,很难确定有木有物体的chip。那么怎么做的呢?
因为我们的RPN本身就有挑选包含目标的区域的功能。我们反其道而行之,挑出那些不被推荐的区域不就是背景了。
所以第一步用轻量的rpn来对chips进行推荐,然后在每个scale上,去掉positive chip中有所推荐的部分。
第二步对于剩余部分,选择Ri范围内存在的M个以上推荐的chips构成负样本池
第三步训练时从所有尺度的负样本池中选取每张图片的固定数目的负样本碎片进行训练。

图中红色点是rpn生成的被过滤过的negative proposal,然后红色框就是包含一定数量negative proposal的negative chip,可以看到这些都是很有调整性,易出现false positive情况的chip
标签分配
由RPN网络产生的proposals,与gt bbox等IoU大于0.5,即标注为正例。在训练时,gt bbox不受Ri限制,但proposal必须落在Ri范围内一个chip中包含300个proposals。
在训练过程中,每一个batch随机选择一定数量的chips进行训练。在COCO数据集上,每一张图像平均生成约5个大小为512*512的chips。
实验部分做了召回率实验和ap实验
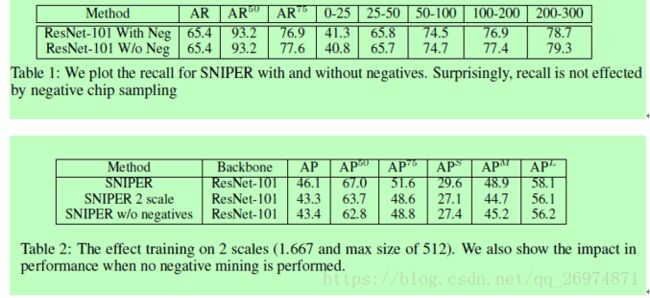
可以看到召回率不受负样本影响,而携带负样本的训练模型要比无负样本的要高。
从数学上我们可以知道rec=tp/(tp+fn)与fp无关。而pre=tp/(tp+fp)。Ap的值则是pre和rec曲线包围的面积,在召回率不变的情况下,fp上升,pre减小,ap也就减小了这和实验结果一致。
文章的问题
虽然作者宣称自己自己做的是end-to-end的网络结构,实际上是training chips for end-to-end。也就是真正较为繁琐的chips的生成选择是被作者割裂到了识别过程之外的。也就是说作者所宣称达到的更高的识别效率(更少的计算,更快的速度,更高的识别率)是以增加数据预处理的时间和步骤作为代价的。一张完整的图片进行SNIP/SNIPER识别先要被采样到多个尺度,再被分割成多张图片再进行识别。一张图片是被当成了多张图片进行识别最后进行竞争筛选得出结果的