在VMware虚拟机上分布式安装Hadoop架构(3)——Slave节点的hadoop安装配置
0、主要参考教程
1 、厦门大学数据库实验室
2、JeffreyZhou的博客园
00 大概步骤
1、在 Master 节点上配置 hadoop 用户、安装 SSH server、安装 Java 环境
2、在 Master 节点上安装 Hadoop,并完成配置
3、在其他 Slave 节点上配置 hadoop 用户、安装 SSH server、安装 Java 环境
4、将 Master 节点上的 /usr/local/hadoop 目录复制到其他 Slave 节点上
5、在 Master 节点上开启 Hadoop
3.1 建立Slave节点
先回顾一下前面所做的工作,主要是在master一个节点上:
- 在虚拟机上安装了一个ubuntu系统和hadoop用户
- 配置了主机名和IP映射,SSH免密登录,JDK环境
- 安装了hadoop,单机配置测试wordcount栗子
- 修改
slaves等5个配置文件
建立方式
1、利用虚拟机的方便,直接将现有的master节点克隆3份,完全克隆,并命名为Slaver1~3,那么上述的一些配置就不用再重复配置(hadoop用户,JDK环境)。
2、新安装一个slave节点,再次安装hadoop用户,ssh服务和JDK环境,再克隆三份,最后把master节点上,已经配置好的hadoop打包(/usr/local/hadoop 目录)发送到这三个slave节点上。
无论哪种方式,都是要基本配置好的三个DataNode节点。
3.2 配置Slave节点
在上述的建立方式中,无论用那种方式,都要再进行以下两项配置:
1. 主机名和IP配置
为了便于区分,先修改各个节点的主机名
$ sudo vimm /etc/hostname
主节点的主机名:
![]()
再修改各个节点的IP映射,
$ sudo vim /etc/hosts
本项目中,各个节点的IP关系如下:
127.0.0.1 ---- localhost
192.168.10.31 ---- master
192.168.10.20 ---- slaver1
192.168.10.10 ---- slaver2
192.168.10.23 ---- slaver3
注:
修改完成后要重启一下才会看到机器名的变化
2. SSH无密连接
这是很重要的一点,前面所配置的是本机,这里配置的ssh才是分布式操作的连接。不然master和slave节点虽然都把自己配置的好好的,但互相之间没关系怎么行。开始连接吧
首先生成 master 节点的公匙,在 master 节点的终端中执行
$ cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost就会自动生成
$ rm ./id_rsa* # 删除之前生成的公匙(如果有)
$ ssh-keygen -t rsa # 一直按回车就可以(即不设置密码)
让 Master 节点需能无密码 SSH 本机,在 Master 节点上执行:
$ cat ./id_rsa.pub >> ./authorized_keys
完成后可执行 ssh master 验证一下(可能需要输入 yes,成功后执行 exit 返回原来的终端)。
接着在 master 节点将上公匙传输到各个 slave 节点(每个slave节点操作一遍此配置):
$ scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop/
scp 是 secure copy 的简写,用于在 Linux 下进行远程拷贝文件,类似于 cp 命令,不过 cp 只能在本机中拷贝。执行 scp 时会要求输入 Slave1 上 hadoop 用户的密码(hadoop),输入完成后会提示传输完毕。
接着在 slave 节点上,将 ssh 公匙加入授权:
$ mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽
$ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
$ rm ~/id_rsa.pub # 用完就可以删掉了
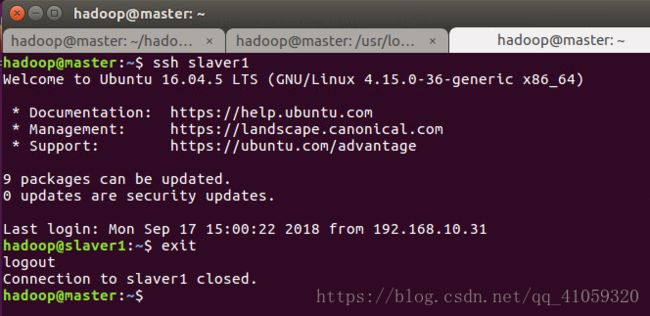
这样,在 master 节点上就可以无密码 SSH 到各个 slave 节点了,可在 master 节点上执行如下命令进行检验,如下图所示:
3. 从节点hadoop配置
若采用第一种建立方式,直接从master节点克隆系统,则不用进行此项配置。若自己新建立的系统,则要对其进行配置。
上一篇已经在master节点上配置好了hadoop环境,其实就是修改hadoop文件夹内的几个配置文件,上一步骤也在master和slave节点之间建立了通信连接,那么我们可以直接将master节点中的整个HADOOP_HOME文件夹复制过来就行了。
- 在master节点上执行:
$ cd /usr/local
$ sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
$ sudo rm -r ./hadoop/logs/* # 删除日志文件
$ tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
$ cd ~
$ scp ./hadoop.master.tar.gz slave1:/home/hadoop
- 在各个slave节点上执行:
$ sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
$ sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
$ sudo chown -R hadoop /usr/local/hadoop
3.3 后记
至此,hadoop分布式系统已经基本搭建完毕,下一步准备进行一些小测试来检查是否隐藏问题,再下一步就学习一下hadoop的源码吧。
由于中间时间有点久,中间可能有些问题忘了指出来,欢迎指出共同讨论。