Pt(Percona Toolkit)安装和使用文档
Pt安装步骤
[root@localhost~]# rpm -qa perl-DBI perl-DBD-MySQL perl-Time-HiRes perl-IO-Socket-SSL

检测是否又依赖包
[root@localhost ~]# yum -y install perl-DBI perl-DBD-MySQL perl-Time-HiRes perl-IO-Socket-SSL
安装依赖包
[root@localhost ~]# yum install http://www.percona.com/downloads/percona-release/redhat/0.1-4/percona-release-0.1-4.noarch.rpm
下载安装包
[root@localhost ~]# yum list | grep percona-toolkit

查看下载的安装包
[root@localhost ~]# yum install percona-toolkit
安装
[root@localhost ~]# pt-query-digest –help
查看是否安装成功
(命令正常就对了)
Pt使用
Pt-align(将表的信息按列对齐打印输出)
root@localhost sysbench-1.0]# iostat | pt-align
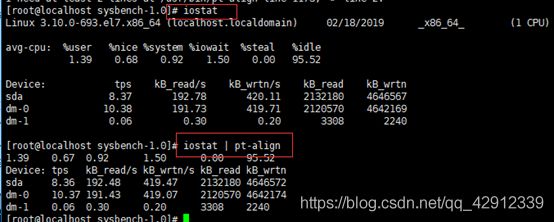
将表的信息按列对齐打印输出。如果没有指定文件,则默认输出STDIN
pt-archiver(归档数据)
全表归档,不删除原表数据,非批量插入
参数说明:
D:数据库名
t:数据库表名
u:数据库登录用户名(可有可无,默认root)
p:数据库密码(可有可无,默认没有密码)
h:数据库地址(当使用远程连接的时候,本地的数据库IP必须被远程的数据库所允许请求连接)(可有可无,默认localhost)
P:端口(可有可无,默认3306)
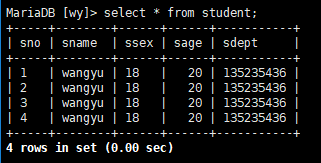
[root@localhost ~]# pt-archiver --source h=192.168.11.200,P=3306,D=wy,t=student,u=wangyu,p=111111 --dest
h=192.168.11.208,P=3306,D=wy,t=student,u=wangyu,p=111111 --no-check-charset --where ‘1=1’ --progress 1000 --no-delete --limit=1000 --statistics

命令执行完后的截图

数据库1表student的截图

数据库2表student的截图,数据转移成功(两个库的表结构要求一样)
全表归档,删除原表数据,非批量插入,非批量删除
[root@localhost ~]# pt-archiver --source
h=192.168.11.200,P=3306,D=wy,t=student,u=wangyu,p=111111 --dest
h=192.168.11.208,P=3306,D=wy,t=student,u=wangyu,p=111111 --no-check-charset --where ‘1=1’ --progress 1000 --limit=1000 --txn-size 1000 --statistics –purge

命令执行成功截图

数据库1中表还在但是数据已经删除
数据库2表中已有数据
全表归档,不删除原表数据,批量插入
[root@localhost ~]# pt-archiver --source
h=192.168.11.200,P=3306,D=wy,t=student,u=wangyu,p=111111 --dest
h=192.168.11.208,P=3306,D=wy,t=student,u=wangyu,p=111111 --no-check-charset --where ‘1=1’ --progress 1000 --no-delete --limit=1000 --statistics --txn-size
1000 --bulk-insert --bulk-delete

命令执行成功截图
全表归档,删除原表数据,批量插入,批量删除
[root@localhost ~]# pt-archiver --source
h=192.168.11.200,P=3306,D=wy,t=student,u=wangyu,p=111111 --dest
h=192.168.11.208,P=3306,D=wy,t=student,u=wangyu,p=111111 --no-check-charset --where ‘1=1’ --progress 1000 --no-delete --limit=1000 --statistics --txn-size 1000 --bulk-insert --bulk-delete --purge

执行成功截图
Pt-online-schema-change(在线修改表结构)
命令参数
–user:
-u,连接的用户名
–password:
-p,连接的密码
–database:
-D,连接的数据库
–port
-P,连接数据库的端口
–host:
-h,连接的主机地址
–socket:
-S,连接的套接字文件
–ask-pass
隐式输入连接MySQL的密码
–charset
指定修改的字符集
–defaults-file
-F,读取配置文件
–alter:
结构变更语句,不需要alter table关键字。可以指定多个更改,用逗号分隔。如下场景,需要注意:
不能用RENAME来重命名表。
列不能通过先删除,再添加的方式进行重命名,不会将数据拷贝到新列。
如果加入的列非空而且没有默认值,则工具会失败。即其不会为你设置一个默认值,必须显示指定。
删除外键(drop foreign key constrain_name)时,需要指定_constraint_name,而不是原始的constraint_name。
如:CONSTRAINT fk_foo FOREIGN KEY (foo_id) REFERENCES bar (foo_id),需要指定:–alter “DROP FOREIGN KEY _fk_foo”
–alter-foreign-keys-method
如何把外键引用到新表?需要特殊处理带有外键约束的表,以保证它们可以应用到新表.当重命名表的时候,外键关系会带到重命名后的表上。
该工具有两种方法,可以自动找到子表,并修改约束关系。
auto:
在rebuild_constraints和drop_swap两种处理方式中选择一个。
rebuild_constraints:使用 ALTER TABLE语句先删除外键约束,然后再添加.如果子表很大的话,会导致长时间的阻塞。
drop_swap:
执行FOREIGN_KEY_CHECKS=0,禁止外键约束,删除原表,再重命名新表。这种方式很快,也不会产生阻塞,但是有风险:
1, 在删除原表和重命名新表的短时间内,表是不存在的,程序会返回错误。
2, 如果重命名表出现错误,也不能回滚了.因为原表已经被删除。
none:
类似"drop_swap"的处理方式,但是它不删除原表,并且外键关系会随着重命名转到老表上面。
–[no]check-alter
默认yes,语法解析。配合–dry-run 和 --print 一起运行,来检查是否有问题(change column,drop primary key)。
–max-lag
默认1s。每个chunk拷贝完成后,会查看所有复制Slave的延迟情况。要是延迟大于该值,则暂停复制数据,直到所有从的滞后小于这个值,使用Seconds_Behind_Master。如果有任何从滞后超过此选项的值,则该工具将睡眠–check-interval指定的时间,再检查。如果从被停止,将会永远等待,直到从开始同步,并且延迟小于该值。如果指定–check-slave-lag,该工具只检查该服务器的延迟,而不是所有服务器。
–check-slave-lag
指定一个从库的DSN连接地址,如果从库超过–max-lag参数设置的值,就会暂停操作。
–recursion-method
默认是show processlist,发现从的方法,也可以是host,但需要在从上指定report_host,通过show slave hosts来找到,可以指定none来不检查Slave。
METHOD USES
processlist SHOW PROCESSLIST
hosts SHOW SLAVE HOSTS
dsn=DSN DSNs from a table
none Do not find slaves
指定none则表示不在乎从的延迟。
==–check-interval ==
默认是1。–max-lag检查的睡眠时间。
–[no]check-plan
默认yes。检查查询执行计划的安全性。
==–[no]check-replication-filters ==
默认yes。如果工具检测到服务器选项中有任何复制相关的筛选,如指定binlog_ignore_db和replicate_do_db此类。发现有这样的筛选,工具会报错且退出。因为如果更新的表Master上存在,而Slave上不存在,会导致复制的失败。使用–no-check-replication-filters选项来禁用该检查。
==–[no]swap-tables ==
默认yes。交换原始表和新表,除非你禁止–[no]drop-old-table。
–[no]drop-triggers
默认yes,删除原表上的触发器。 --no-drop-triggers 会强制开启 --no-drop-old-table 即:不删除触发器就会强制不删除原表。
–new-table-name
复制创建新表的名称,默认%T_new。
–[no]drop-new-table
默认yes。删除新表,如果复制组织表失败。
–[no]drop-old-table
默认yes。复制数据完成重命名之后,删除原表。如果有错误则会保留原表。
–max-load
默认为Threads_running=25。每个chunk拷贝完后,会检查SHOW GLOBAL STATUS的内容,检查指标是否超过了指定的阈值。如果超过,则先暂停。这里可以用逗号分隔,指定多个条件,每个条件格式: status指标=MAX_VALUE或者status指标:MAX_VALUE。如果不指定MAX_VALUE,那么工具会这只其为当前值的120%。
–critical-load
默认为Threads_running=50。用法基本与–max-load类似,如果不指定MAX_VALUE,那么工具会这只其为当前值的200%。如果超过指定值,则工具直接退出,而不是暂停。
==–default-engine ==
默认情况下,新的表与原始表是相同的存储引擎,所以如果原来的表使用InnoDB的,那么新表将使用InnoDB的。在涉及复制某些情况下,很可能主从的存储引擎不一样。使用该选项会默认使用默认的存储引擎。
==–set-vars ==
设置MySQL变量,多个用逗号分割。默认该工具设置的是: wait_timeout=10000 innodb_lock_wait_timeout=1 lock_wait_timeout=60
–chunk-size-limit
当需要复制的块远大于设置的chunk-size大小,就不复制.默认值是4.0,一个没有主键或唯一索引的表,块大小就是不确定的。
–chunk-time
在chunk-time执行的时间内,动态调整chunk-size的大小,以适应服务器性能的变化,该参数设置为0,或者指定chunk-size,都可以禁止动态调整。
–chunk-size
指定块的大小,默认是1000行,可以添加k,M,G后缀.这个块的大小要尽量与–chunk-time匹配,如果明确指定这个选项,那么每个块就会指定行数的大小.
–[no]check-plan
默认yes。为了安全,检查查询的执行计划.默认情况下,这个工具在执行查询之前会先EXPLAIN,以获取一次少量的数据,如果是不好的EXPLAIN,那么会获取一次大量的数据,这个工具会多次执行EXPALIN,如果EXPLAIN不同的结果,那么就会认为这个查询是不安全的。
–statistics
打印出内部事件的数目,可以看到复制数据插入的数目。
–dry-run
创建和修改新表,但不会创建触发器、复制数据、和替换原表。并不真正执行,可以看到生成的执行语句,了解其执行步骤与细节。–dry-run与–execute必须指定一个,二者相互排斥。和–print配合最佳。
–execute
确定修改表,则指定该参数。真正执行。–dry-run与–execute必须指定一个,二者相互排斥。
–print
打印SQL语句到标准输出。指定此选项可以让你看到该工具所执行的语句,和–dry-run配合最佳。
–progress
复制数据的时候打印进度报告,二部分组成:第一部分是百分比,第二部分是时间。
–quiet
-q,不把信息标准输出。
实例
增加字段
[root@localhost ~]# pt-online-schema-change --user=wangyu --password=111111 --host=192.168.11.200 --alter “ADD COLUMN conten text” D=wy,t=student --no-check-replication-filters --alter-foreign-keys-method=auto --recursion-method=none --print –execute


成功截图

新增了一个字段
删除字段
[root@localhost ~]# pt-online-schema-change --user=wangyu --password=111111 --host=192.168.11.200 --alter "drop COLUMN conten " D=wy,t=student --no-check-replication-filters --alter-foreign-keys-method=auto --recursion-method=none --print –execute



修改字段
[root@localhost ~]# pt-online-schema-change --user=wangyu --password=111111 --host=192.168.11.200 --alter “modify column sage int default 0” D=wy,t=student --no-check-replication-filters --alter-foreign-keys-method=auto --recursion-method=none --print --execute

![]()
字段改名
[root@localhost ~]# pt-online-schema-change --user=wangyu --password=111111 --host=192.168.11.200 --alter “change column sage address int” D=wy,t=student --no-check-alter --no-check-replication-filters --alter-foreign-keys-method=auto --recursion-method=none --print --execute

![]()
增加索引
[root@localhost ~]# pt-online-schema-change --user=wangyu --password=111111 --host=192.168.11.200 --alter “add index idx_address(address)” D=wy,t=student --no-check-alter --no-check-replication-filters
–alter-foreign-keys-method=auto --recursion-method=none --print --execute

![]()
删除索引
[root@localhost ~]# pt-online-schema-change --user=wangyu --password=111111 --host=192.168.11.200 --alter “drop index idx_address” D=wy,t=student --no-check-alter --no-check-replication-filters --alter-forei=gn-keys-method=auto --recursion-method=none --print –execute
![]()
pt-config-diff(比较配置文件和参数)
比较多份配置文件的不同
[root@localhost ~]# pt-config-diff /etc/my.cnf /my.cnf

打印出来的不一样的参数
比较本地配置文件和远程配置文件
[root@localhost ~]# pt-config-diff /etc/my.cnf h=192.168.11.208,u=wangyu,p=111111,P=3306

pt-deadlock-logger(记录MySQL死锁的原因日志)
–create-dest-table :创建指定的表。
–dest :创建存储死锁信息的表。
–database :-D,指定链接的数据库。
–table :-t,指定存储的表名。
–log :指定死锁日志信息写入到文件。
–run-time :运行次数,默认永久
–interval :运行间隔时间,默认30s。
u,p,h,P :链接数据库的信息。
[root@localhost ~]# pt-deadlock-logger
h=192.168.11.200,u=wangyu,p=111111

pt-diskstats(直接显示磁盘IO信息)
[root@localhost ~]# pt-diskstats

pt-duplicate-key-checker(查找数据库中重复的索引和外键)
[root@localhost ~]# pt-duplicate-key-checker

pt-find(查找MySQL中的表并执行操作)
查找大于5k的表
[root@localhost ~]# pt-find --tablesize +5k

查找大于5k的表
找出innodb存储引擎格式的表
[root@localhost ~]# pt-find --engine INNODB

找出innodb存储引擎格式的表(引擎区分大小写)
找出一天前innodb引擎格式的表
[root@localhost ~]# pt-find --ctime +1 --engine InnoDB

找出一天前innodb引擎格式的表
找到InnoDB格式的数据表,并将其转化为MyISAM格式
[root@localhost ~]# pt-find --engine InnoDB --exec “ALTER TABLE %D.%N ENGINE=MyISAM”

Innodb引擎格式的表没有了全变成了myisam格式的了
找到所有表并打印它们的总数据和索引大小,并首先对最大的表进行排序
[root@localhost ~]# pt-find --printf “%T\t%D.%N\n” |sort -rn

找到所有表并打印它们的总数据和索引大小,并首先对最大的表进行排序
pt-summary(查看当前系统的信息)
[root@localhost ~]# pt-summary

pt-heartbeat(监视MySQL的延迟操作)
常用参数
–ask-pass
连接数据库时提示密码
–charset
默认字符集
–check
检查从的延迟后退出,如果在级联复制中,还可以指定–recurse参数,这时候,会检测从库的从库的延迟情况。
–check-read-only
检查server是否是只读的,如果是只读,则会跳过插入动作。
–config
将参数写入到参数文件中
–create-table
创建heartbeat表如果该表不存在,该表由–database和–table参数来确认
–create-table-engine
指定heartbeat表的存储引擎
–daemonize
脚本以守护进程运行,这样即使脚本执行的终端断开了,脚本也不会停止运行。
–database
指定heartbeat表所在的数据库
–dbi-driver
pt-heartbeat不仅能检测MySQL之间的心跳延迟情况,还可以检测PG。
该参数指定连接使用的驱动,默认为mysql,也可指定为Pg
–defaults-file
指定参数文件的位置,必须为绝对路径。
–file
将最新的–monitor信息输出到文件中,注意最新,新的信息会覆盖旧的信息。
–frames
统计的时间窗口,默认为1m,5m,15m,即分别统计1min,5min和15min内的平均延迟情况。
单位可以是s,m,h,d,注意:时间窗口越大,需要缓存的结果越多,对内存的消耗也越大。
–interval
update和check heartbeat表的频率,默认是1s
–log
在脚本以守护进程执行时,将结果输出到log指定的文件中
–master-server-id
指定master的server_id,在检测从的延迟时,必须指定该参数,不然会报错误
–monitor
持续的检测并输出从的延迟情况
其中,检测并输出的频率有–interval参数决定,默认为1s
–pid
创建pid文件
–port
指定登录的端口,缩写为-P
–print-master-server-id
同时输出主的server_id,在–monitor情况下,默认输出为
–recurse
在–check模式下,用于检测级联复制中从的延迟情况。其中,–recurse用于指定级联的层级
–recursion-method
在级联复制中,找到slave的方法。有show processlist和show slave hosts两种。
–replace
在–update模式下,默认是使用update操作进行记录的更新,但有时候你不太确认heartbeat表中是否任何记录时,此时可使用replace操作。
–run-time
指定脚本运行的时间,无论是针对–update操作还是–monitor操作均实用
–sentinel
“哨兵”,如果指定的文件存在则提出,默认为/tmp/pt-heartbeat-sentinel
–slave-user
设置连接slave的用户
–slave-password
设置连接slave的用户密码
–set-vars
设置脚本在与MySQL交互过程时的会话变量,但似乎并没有什么用
–skew
指定check相对于update的延迟时间。默认为0.5秒
即–update更新一次后,–check会在0.5秒后检查此次更新所对应的主从延迟情况
–table
指定心跳表的名字,默认为heartbeat
–update
更新master中heartbeat表的记录
–user
指定连接的用户
–utc
忽略系统时区,而使用UTC。如果要使用该选项,则–update,–monitor,–check中必须同时使用。
–version
打印版本信息
–[no]version-check
检查pt,连接的MySQL Server,Perl以及DBD::mysql的版本信息。
命令实例
[root@localhost ~]# pt-heartbeat --user=wangyu --password=111111 -h 192.168.11.200 --D test --master-server-id=1 –monitor
![]()
pt-mysql-summary(查看当前MySQL的详细信息)
[root@localhost ~]# pt-mysql-summary

pt-query-digest(从日志,进程列表和tcpdump分析MySQL查询)
分析慢查询日志
[root@localhost ~]# pt-query-digest --report /var/log/mariadb/mariadb.log
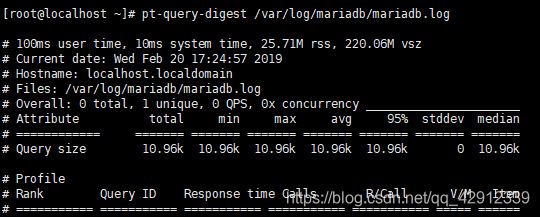
分析慢查询日志
报告最近半个小时的慢查询
[root@localhost ~]# pt-query-digest --report --since 1800s /var/log/mariadb/mariadb.log
报告最近半个小时的慢查询
报告一个时间段的慢查询
[root@localhost ~]# pt-query-digest --report --since ‘2013-02-10 21:48:59’ --until ‘2013-02-16 02:33:50’ /var/log/mariadb/mariadb.log
报告一个时间段的慢查询
通过tcpdump抓取mysql的tcp协议数据,然后再分析
[root@localhost ~]# tcpdump -s 65535 -x -nn -q -tttt -i any -c 1000 port 3306 > mysql.tcp.txt
[root@localhost ~]# pt-query-digest --type tcpdump mysql.tcp.txt

通过tcpdump抓取mysql的tcp协议数据,然后再分析
分析bin-log日志
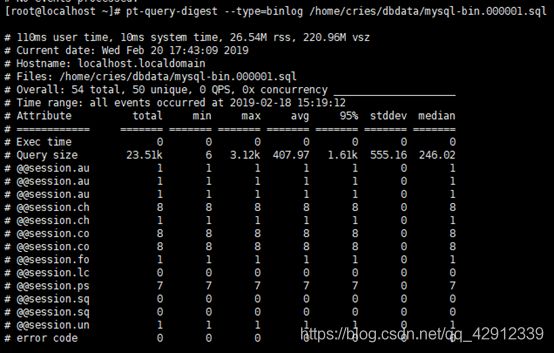
[root@localhost ~]# mysqlbinlog /home/cries/dbdata/mysql-bin.000001 > /home/cries/dbdata/mysql-bin.000001.sql
把log日志转码
[root@localhost ~]# pt-query-digest --type=binlog /home/cries/dbdata/mysql-bin.000001.sql
分析log日志
pt-pmp(聚合所选程序的GDB堆栈跟踪)
[root@localhost ~]# pt-pmp

pt-kill(杀死符合特定条件的MySQL查询)
常用命令
host:连接数据库的地址
port:连接数据库的端口
user:连接数据库的用户名
passowrd:连接数据库的密码
charset:指定字符集
match-command:指定杀死的查询类型
match-user:指定杀死的用户名,即杀死该用户的查询
busy-time:指定杀死超过多少秒的查询
kill:执行kill命令
victims:表示从匹配的结果中选择,类似SQL中的where部分,all是全部的查询
interal:每隔多少秒检查一次
print:把kill的查询打印出来
实例
每隔10s 打印处于sleep状态的连接数
[root@localhost
~]# pt-kill --defaults-file xx --match-command Sleep --print --victims all
–interval 10
![]()
打印空闲连接
[root@localhost ~]# pt-kill --match-command Sleep --idle-time 5 --interval 10 --print --victims all

添加—kill参数就是杀死
pt-slave-find(查找并打印MySQL从属的复制层次结构树)
[root@localhost ~]# pt-slave-find -h 192.168.11.200 -u wangyu -p 111111 -P 3306

pt-show-grants(规范化并打印MySQL授权)
[root@localhost ~]# pt-show-grants

pt-visual-explain(将EXPLAIN输出格式化为树)
[root@localhost ~]# pt-visual-explain --connect /home/cries/dbdata/mysql-bin.000001.sql

pt-variable-advisor (分析MySQL变量并就可能出现的问题提出建议)
[root@localhost ~]# pt-variable-advisor localhost

pt-table-usage(分析查询如何使用表)
[root@localhost ~]# pt-table-usage --query=“select * from t01 join t02 on t01.id=t02.id where t01.code=2”

[root@localhost ~]# pt-table-usage --query=“select * from wy.wangyu;”

pt-table-sync(有效地同步MySQL表数据)
[root@localhost ~]# pt-table-sync --execute h=192.168.11.200,u=wangyu,p=111111,P=3306,D=wy,t=lock1 h=192.168.11.208
使主从不一致的数据进行同步
pt-table-checksum(主要用来检查主从数据是否一致)
常用参数
–no-check-replication-filters 表示不需要检查
Master 配置里是否指定了 Filter。
默认会检查,如果配置了 Filter,如 replicate_do_db,replicate-wild-ignore-table,binlog_ignore_db 等,在从库checksum就与遇到表不存在而报错退出,所以官方默认是yes(–check-replication-filters)但我们实际在检测中时指定–databases=,所以就不存在这个问题,干脆不检测。
–no-check-binlog-format 不对binlog的格式进行检查
–replicate-check-only 只显示主从不一致部分,此参数不会生成新的checksums数据,只会根据checksums表已经有的数据来显示
==–databases=,-d:==要检查的数据库,逗号分隔。 --databases-regex 正则匹配要检测的数据库,–ignore-databases[-regex]忽略检查的库。Filter选项。
–tables=,-t:要检查的表,逗号分隔。如果要检查的表分布在不同的db中,可以用–tables=dbname1.table1,dbnamd2.table2的形式。
同理有–tables-regex,–ignore-tables,–ignore-tables-regex。–replicate指定的checksum表始终会被过滤。
[root@localhost ~]# pt-table-checksum --nocheck-replication-filters --no-check-binlog-format --databases=test h=192.168.11.200,u=wangyu,p=111111,P=3306

TS :完成检查的时间
ERRORS :检查时候发生错误和警告的数量
DIFFS :0表示一致,1表示不一致。当指定–no-replicate-check时,会一直为0,当指定–replicate-check-only会显示不同的信息
ROWS :表的行数
CHUNKS :被划分到表中的块的数目
SKIPPED :由于错误或警告或过大,则跳过块的数目
TIME :执行的时间
TABLE :被检查的表名
pt-stalk(出现问题时收集有关MySQL的取证数据)
[root@localhost ~]# pt-stalk
