MySQL索引优化分析3—单表查询优化
MySQL索引优化分析3——SQL查询优化之单表查询
- 1.数据准备
- 1.1 建表
- 1.2 设置参数log_bin_trust_function_creators
- 1.3 创建SQL函数,保证每条数据都不同
- 1.4 创建SQL存储过程
- 1.5 调用存储过程
- 1.6 批量删除某个表上的所有索引
- 2.单表使用索引及常见索引失效
- 2.1 索引失效-案例
- 1.索引全值匹配
- 2.最佳左前缀法则
- 3.不要在索引列上做任何操作
- 3.1 在查询的索引列上使用函数
- 3.2 在查询索引列上做转换
- 4.索引列上有范围查询时,范围条件右边的列将失效
- 5.使用不等于(!= 或者<>)时,索引失效
- 6.is not null 不能使用索引,is null可以使用索引
- 7.Like以通配符%或_开头,索引失效
- 8.字符串不加单引号,索引失效
- 9.减少使用or
- 10.尽量使用覆盖索引
- 2.2 索引失效总结
- 3.单表查询索引优化的一般性建议
当在一个表中使用索引时,其目的是为了提高SQL查询效率,前面两节也分别对Mysql数据库索引以及SQL查询的执行计划进行了介绍。问题是,SQL查询语句是如何使用表中索引来提高查询效率的?
本节将通过对一些不同索引设置及对应的不同SQL查询语句的SQL执行情况进行对比分析,来详细介绍SQL查询语句的索引优化。
1.数据准备
首先是实验案例的数据准备。通过批量数据脚本,创建dept 与emp 两个数据表,分别插入10万与50万条数据。
1.1 建表
首先创建一个部门表dept,一个员工表emp,相关字段、属性、数据库设置如下:
CREATE TABLE `dept` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`deptName` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
ceo INT NULL ,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
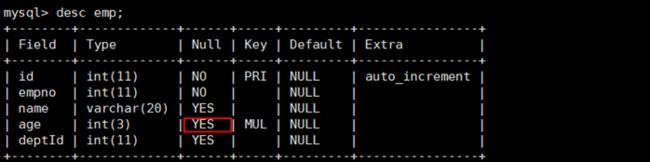
CREATE TABLE `emp` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`empno` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`deptId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
#CONSTRAINT `fk_dept_id` FOREIGN KEY (`deptId`) REFERENCES `t_dept` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
1.2 设置参数log_bin_trust_function_creators
如果创建函数时,假如报错:This function has none of DETERMINISTIC…
- 是由于开启过慢查询日志,因为我们开启了 bin-log, 我们就必须为我们的function指定一个参数。
show variables like 'log_bin_trust_function_creators';
set global log_bin_trust_function_creators=1;
这样添加了参数以后,如果mysqld重启,上述参数又会消失,永久方法:
windows下my.ini[mysqld]加上:
- log_bin_trust_function_creators=1
linux下 /etc/my.cnf 的 [mysqld]加上:
- log_bin_trust_function_creators=1
1.3 创建SQL函数,保证每条数据都不同
为了向表中批量插入随机的数据,创建两个SQL函数,用于插入数据时使用。
1.随机产生字符串函数
DELIMITER $$
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END $$
#假如要删除函数
drop function rand_string;
2.随机产生部门编号函数
#用于随机产生多少到多少的编号
DELIMITER $$
CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num -from_num+1)) ;
RETURN i;
END$$
#假如要删除函数
drop function rand_num;
1.4 创建SQL存储过程
通过存储过程,用于往1.1创建的表中插入n条数据,表中一些字段的值使用1.3中的SQL函数随机生成。
1.创建往emp表中插入数据的存储过程
DELIMITER $$
CREATE PROCEDURE insert_emp( START INT , max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
#set autocommit =0 把autocommit设置成0
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO emp (empno, NAME ,age ,deptid ) VALUES ((START+i) ,rand_string(6) , rand_num(30,50),rand_num(1,10000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END$$
#删除存储过程
DELIMITER ;
drop PROCEDURE insert_emp;
2.创建往dept表中插入数据的存储过程
#执行存储过程,往dept表添加随机数据
DELIMITER $$
CREATE PROCEDURE `insert_dept`( max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO dept ( deptname,address,ceo ) VALUES (rand_string(8),rand_string(10),rand_num(1,500000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END$$
#删除
DELIMITER ;
drop PROCEDURE insert_dept;
1.5 调用存储过程
调用1.4中的存储过程,传入设置参数,实现大批量数据的插入操作,作为后面SQL索引优化的实验准备。
#执行存储过程,往dept表添加1万条数据
DELIMITER ;
CALL insert_dept(10000);
#执行存储过程,往emp表添加50万条数据
DELIMITER ;
CALL insert_emp(100000,500000);
1.6 批量删除某个表上的所有索引
SQL索引优化会涉及诸多索引的创建与删除,这里创建一个能够批量删除表上索引的存储过程,使用时直接调用执行即可。
1.创建删除索引的存储过程
DELIMITER $$
CREATE PROCEDURE `proc_drop_index`(dbname VARCHAR(200),tablename VARCHAR(200))
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE ct INT DEFAULT 0;
DECLARE _index VARCHAR(200) DEFAULT '';
DECLARE _cur CURSOR FOR SELECT index_name FROM information_schema.STATISTICS WHERE table_schema=dbname AND table_name=tablename AND seq_in_index=1 AND index_name <>'PRIMARY' ;
DECLARE CONTINUE HANDLER FOR NOT FOUND set done=2 ;
OPEN _cur;
FETCH _cur INTO _index;
WHILE _index<>'' DO
SET @str = CONCAT("drop index ",_index," on ",tablename );
PREPARE sql_str FROM @str ;
EXECUTE sql_str;
DEALLOCATE PREPARE sql_str;
SET _index='';
FETCH _cur INTO _index;
END WHILE;
CLOSE _cur;
END$$
2.执行存储过程
# 查看索引
SELECT * FROM information_schema.STATISTICS ;
# 调用存储过程,删除dbname数据库中tablename上表的索引
CALL proc_drop_index("dbname","tablename");
2.单表使用索引及常见索引失效
一般的查询语句仅涉及单个表的查询,在可以实现查询目的的前提下,表索引的创建方式、筛选条件的设置都可以有多种不同选择,具体的应该如何操作?在单表上使用索引的注意事项和一些一般性建议,本节将会一一说明。
2.1 索引失效-案例
在单表查询中,存在以下几种索引不可用的情况,使用索引使应该在实现查询需求前尽可能地避免这些情况的出现。
1.索引全值匹配
1)案例:
SQL查询中经常出现的sql语句如下:
EXPLAIN SELECT SQL_NO_CACHE \* FROM emp WHERE emp.age=30 ;
EXPLAIN SELECT SQL_NO_CACHE \* FROM emp WHERE emp.age=30 and deptid=4;
EXPLAIN SELECT SQL_NO_CACHE \* FROM emp WHERE emp.age=30 and deptid=4 AND emp.name = 'abcd' ;
2)分析
员工emp表的三条查询语句,分别使用了age、deptid、name三个字段进行了筛选。可以考虑在这些字段上建立索引,来提高查询效率。但是索引的创建方式、筛选条件的设置可以有多种选择。
此时,索引应该如何建立 ?
3)建立全值索引
这里的全值索引,指的是为查询中的所有筛选字段建立复合索引,即一个索引包含多个列。
CREATE INDEX idx_age_deptid_name ON emp(age,deptid,NAME);
建立索引前:

索引后:
![]()
4.结论:
在查询中,不考虑增删性能的前提下,可以通过建立为筛选条件中的字段都建立索引的方式最大限度的提高查询性能。但要注意的是,全值索引对应的查询筛选条件必须满足一些限定要求。
2.最佳左前缀法则
在全值索引的情况下,如果系统经常出现的sql如下:
# 1.在age,deptid,NAME上建立复合索引
CREATE INDEX idx_age_deptid_name ON emp(age,deptid,NAME);
# 2.查看以下两种查询方式的执行计划
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 AND emp.name = 'abcd'
# 或者
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.deptid=1 AND emp.name = 'abcd'
注意,筛选条件:
- 1)没有使用全部的索引列
- 2)没有按照索引列的顺序,使用第一个索引age
那原来的 全值索引:idx_age_deptid_name 还能否正常使用?
答案是不能,如果索引了多列要遵守最左前缀法则:
- 指的是查询从索引的最左前列开始,并且不跳过索引中的列。
案例1
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 AND emp.name = 'abcd'

1)从key字段可以看出,使用了全值索引idx_age_deptid_name
2)虽然索引可以正常使用,但是只有部分被使用到了:
- 有age筛选条件,但缺少deptid字段的筛选条件
- key_len字段值只为:5,也就是只用到了一个单值索引age
案例2

查询条件中没有age字段,导致全值索引idx_age_deptid_name没有被使用。
结论:最左前缀法则
过滤条件要使用索引必须按照索引建立时的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法被使用。(说明:一般情况下顺序可以打乱,但不能缺失)
问题:全值索引的作用机制?
类似于一层一层的网,先通过上层的age索引查询目标记录然后通过下层deptid索引查询,最后是name索引。
3.不要在索引列上做任何操作
不要在索引列上做任何操作(计算、函数、(自动or手动)类型转换),否则会导致索引失效而转向全表扫描。
3.1 在查询的索引列上使用函数
以下这两条sql哪种写法更好:
# 1.在NAME上建立单值索引
CREATE INDEX idx_name ON emp(NAME);
# 2.查看以下两种查询方式的执行计划
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.name LIKE 'abc%'
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE LEFT(emp.name,3) = 'abc'
第一种:正常查找
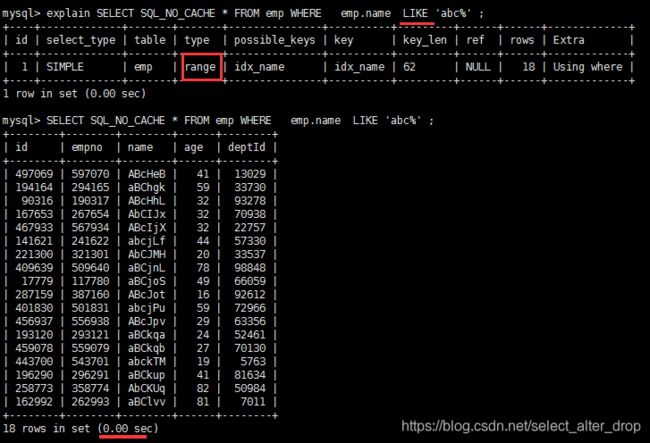
使用 emp.name LIKE ‘abc%’:查询类型是 range,使用了name字段上的索引idx_name。
range查询类型:
- 只检索给定范围的行,使用一个索引来选择行。key 列显示使用了哪个索引。
- 一般就是在你的where语句中出现了between、<、>、in等的查询
- 这种范围扫描索引扫描比全表扫描All要好,因为它只需要开始于索引的某一点,而结束于另一点,不用扫描全部索引。
第二种:在查询上使用函数
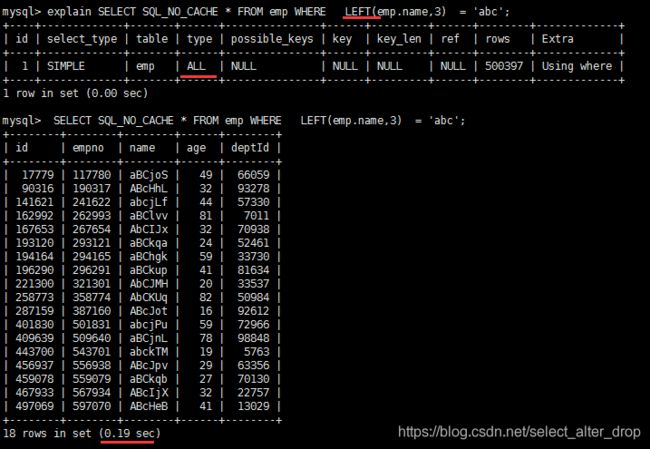
使用函数进行筛选 LEFT(emp.name,3) = ‘abc’:查询类型是 ALL,即全表扫描。
结论:等号左边无计算
3.2 在查询索引列上做转换
create index idx_name on emp(name);
案例:字符串不加单引号
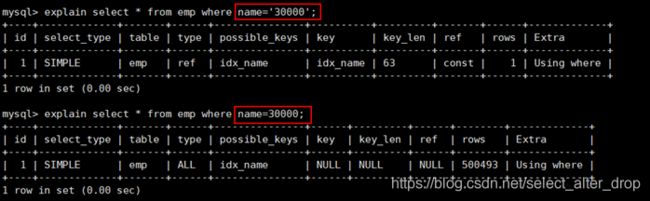
结论:字符串不加单引号,则会在列上做一次转换!
4.索引列上有范围查询时,范围条件右边的列将失效
1)如果系统经常出现的sql如下:
# 1.在age,deptid,NAME上建立复合索引
CREATE INDEX idx_age_deptid_name ON emp(age,deptid,NAME);
# 2.查看以下查询方式的执行计划
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 AND emp.deptId>20 AND emp.name = 'abc' ;
2)那么索引 idx_age_deptid_name这个索引还能正常使用么?

key_len为10:只使用了前两个age、deptid索引,并没有使用name这个字符串属性的列。
MySQL认为它执行查询时必须检查的行数 rows :13534。
3)如果这种sql 出现较多,应该建立:
# 在age,NAME,deptid上建立复合索引
create index idx_age_name_deptid on emp(age,name,deptid);
# drop index idx_age_name_deptid on emp
4)效果:

key_len为72:age,NAME,deptid三个索引都被使用。MySQL认为它执行查询时必须检查的行数 rows :1。
建议:将可能做范围查询的字段的索引顺序放在最后
5.使用不等于(!= 或者<>)时,索引失效
案例:
CREATE INDEX idx_name ON emp(NAME)
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.name <> 'abc'
执行计划如下:

结论:mysql 在使用不等于(!= 或者<>)时,有时会无法使用索引会导致全表扫描。
6.is not null 不能使用索引,is null可以使用索引
下列哪个sql语句可以用到索引:
UPDATE emp SET age =NULL WHERE id=123456;
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE age IS NULL;
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE age IS NOT NULL;
执行计划如下:

结论:is not null用不到索引,is null可以用到索引。
7.Like以通配符%或_开头,索引失效
在name字段上有索引,查询结果直接上图:

结论:匹配前缀不能出现模糊匹配!
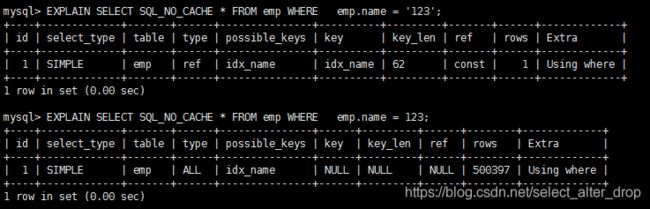
8.字符串不加单引号,索引失效
如图:123数值型会转换为字符串’123’,涉及自动的类型转换,会导致索引失效。
9.减少使用or

建议:使用union all或者union来替代

10.尽量使用覆盖索引
覆盖索引是:select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖。
即查询列和索引列一致,不要写select * !
explain SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 and deptId=4 and name='XamgXt';
explain SELECT SQL_NO_CACHE age,deptId,name FROM emp WHERE emp.age=30 and deptId=4 and name='XamgXt';

2.2 索引失效总结
假设有复合索引:index(a,b,c)
| Where语句 | 索引是否被使用(Y/N) |
|---|---|
| where a = 3 | Y,使用到a |
| where a = 3 and b = 5 | Y,使用到a,b |
| where a = 3 and b = 5 and c = 4 | Y,使用到a,b,c |
| where b = 3 或者 where b = 3 and c = 4 或者 where c = 4 | N |
| where a = 3 and c = 5 | 使用到a, 但是c不可以,b中间断了 |
| where a = 3 and b > 4 and c = 5 | 使用到a和b, c不能用在范围之后,b断了 |
| where a is null and b is not null | is null 支持索引 但是is not null 不支持,所以 a 可以使用索引,但是 b不可以使用 |
| where a <> 3 | 不能使用索引 |
| where abs(a) =3 | 不能使用 索引 |
| where a = 3 and b like ‘kk%’ and c = 4 | Y,使用到a,b,c |
| where a = 3 and b like ‘%kk’ and c = 4 | Y,只用到a |
| where a = 3 and b like ‘%kk%’ and c = 4 | Y,只用到a |
| where a = 3 and b like ‘k%kk%’ and c = 4 | Y,使用到a,b,c |
3.单表查询索引优化的一般性建议
1)对于单键索引,尽量选择针对当前query过滤性更好的索引:
- 没有排序和分组,则综合看type,key,key_len,rows
- 有分组和排序时,额外看Extra看是否使用额外排序
2)在选择组合索引的时候,当前Query中过滤性最好的字段在索引字段顺序中,位置越靠前越好:最左前缀法则,如id、age这些字段
3)在选择组合索引的时候,尽量选择可以能够包含当前query中的where字句中更多字段的索引:索引的全值匹配
4)在选择组合索引的时候,如果某个字段可能出现范围查询时,尽量把这个字段放在索引次序的最后面
5)书写sql语句时,尽量避免造成索引失效的情况