基于Huffman 和LZ77的压缩(二)Huffman压缩的实现
点我查看上一篇
点我获取代码
基于上篇的分析
1一步一步思路分析
1 压缩:
前提:知道Huffman树
1 先回顾构造哈夫曼树的步骤:
1 获取字符的出现次数(权值)
2 根据出现次数构建Huffman树
3 根据Huffman树,获取每个字符的编码
4 根据Huffman编码改写原文件
2 准备条件:
一: 统计文件中每个字符出现次数
统计方式:遍历
存储方式所有字符容器:数组
思想方式: 哈希
每个字符信息存储:struct
1 哪个字符
2 出现次数,
3 Huffman编码
二: Huffman树的节点保存什么?
1 双向指针(孩子双亲)
2 权值
三 怎么建造森林?
将所有的字符信息结点都当成一颗二叉树,存放在在一起,称为森林。
选取什么容器做森林?
我们每次从森林中取2颗权值最小的二叉树,那么我们采用小堆来做森林。
容器:优先级队列。
优先级队列默认大堆:那么我们需要修改比较器;
四 森林创建完毕,便可以由森林来生成Huffman树
五 但是Huffman编码到时候怎么获取?
有了Huffman树,我们便可以获取Huffman编码(左走0,右走1)
要是从根开始,那只能获取一条路径的编码,便走到叶子了。
我们反着走,从叶子开始,反向走到根(保存双亲节点的原因)
求得的路径必然唯一,因为从根到叶子叶子的路径必然唯一。
现在Huffman编码都有了 ,那么我们就可以进行文本替换了。
六 怎么替换?
读取一段文件数据,存在读缓冲区中,逐个从读缓冲区中读取字符,每个字符和自己的Huffman编码存在同一个结构体中,很容易获取。
直到原文件读取结束。
2 能压缩,也还必须能解压缩
七 那么我们怎么解压缩?
拿到一个压缩文件,想直接解压缩肯定不行-----------不知道Huffman 树呀!
也就是说并不知道什么样的一串二进制编码对应着什么样的字符
因此,想要解压缩,我们必须得保存字符和相应权值信息,解压缩时,利用权值信息再构造Huffman树,再拿着一串二进制编码,从树顶向树根走,走到叶子,就找到了对应的字符,存下来,接着从头再来。
八 你可能会问,那为什么不保存Huffman树呢?
我也想过这个问题,发现好像还真没办法存到文件中,Huffman树是new出来的 本来在堆上,所以没办法存在文件中。 所以还是 老老实实存字符和权值(出现次数)这个信息吧,大不了将来再构造一次Huffman树。
九 言归正传,我们的解压缩可以根据构造的Huffman树来进行。
到我们从压缩文件中读一组数据,
逐个字节翻译为二进制(0/1)
再从Huffman树顶开始向下走,走到叶子就是一个Huffman编码,然后翻译为对应字符, 直到解压缩完成。
遇到的问题
: 最后解压缩的时候多了几个字符。
分析发现:
最后的字节没有占满1字节导致的。
解决策略,计数==原文件大小停止翻译
遇到的问题:
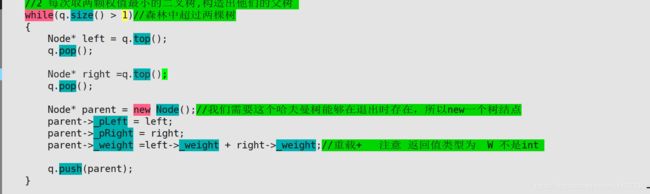

都是运算符重载一下就OK
出现问题 1
: 将出现0次的字符也加入到了Huffman树中:没有意义
**解决方案:**在创建Huffman树期间要将出现0次的结点过滤掉
思考疑虑1:
思考 – 疑虑1: :写入文件时,要是一个字节写哈夫曼编码时,将编码分为两半,会影响吗?
思考 – 疑虑2 解压缩呢? 只拿着压缩数据没法解压缩呀-------么有Huffman 树呀
解决方案:存储Huffman树的节点信息
压缩文件:
需要:
1原文件后缀,以后好还原
2 编码的行数。
3 (编码)字符及出现次数的信息
4 压缩数据
5 源文件大小
遇到问题: Linux下不支持itoa函数
解决方法 : 用sprintf函数替换
想知道: 进行压缩和解压缩性能分析时,
解压缩文件有没有正常翻译为无损文件?
采用 工具beyond Compare (付费)来对比
也可以在Linux下用md5码来对比。
命令: mu5sum + 文件
遇到问题:
解压缩时可能会只解压缩一部分而误认为解压缩完毕。
分析: 这种情况是由于文本的类型而导致的。
下面科普一下原因
函数名: feof
功 能: 检测流上的文件结束符
用 法: int feof(FILE *stream);
返回值: 如果遇到文件结束,函数feof(fp)的值为1,否则为0。
**EOF是文本文件结束的标志。**在文本文件中,数据是以字符的ASCⅡ代码值的形式存放,普通字符的ASCⅡ代码的范围是32到127(十进制),EOF的16进制代码为0x1A(十进制为26),因此可以用EOF作为文件结束标志。
PS: 对文本文件的结束判断可以看文件末尾是否读到EOF控制字符。
但是对于二进制文件来说,所有的内容都是以10101的形式存储的,因此在文件中间也可能存在-1的情况,这样就不能用EOF作为二进制文件末尾的标识。
对于以上的问题,**标准C提供了feof()这个方法来统一判断读取文件是否结束,而不用担心是文本文件还是二进制文件。**正如上面所示,这个feof()方法的返回值只有两个0或1。
如果你用fgetc()函数逐个读取文件中的字符,并判断读取是否结束,如果是二进制文件那个读取到的字符就可能是-1值,就不是EOF——也就是说二进制文件不能这么判断文件是否读取结束
多数程序员都会在不经意间遇到下面这两个问题:
1. linux上用vim写的文件test.txt拷贝到windows上, 结果所有的内容都显示在一行中。(当然, 如果你Windows上的编辑显示器够智能, 那就是另外一回事了)
2. Windows上建立的test.txt拷贝到linux上, 结果linux程序运行异常。(当然, 如果你的linux程序足够健壮, 那就没有问题了)
ps. 当你在Windows上写好linux shell script, 拷贝到linux下运行, 就会出问题。
为什么会出现上面的问题呢? 这就需要我们了解\r\n和\n了。
实话实说, 我发现很多地方讲\r\n和\n, 都说得不太清楚, 下面我来说一下, 希望是更清楚, 而不是更模糊:
Windows系统中有如下等价关系:
用enter换行 <====> 程序写\n <====> 真正朝文件中写\r\n(0x0d0x0a) <====>程序真正读取的是\n
linux系统中的等价关系:
用enter换行 <====> 程序写\n <====> 真正朝文件中写\n(0x0a) <====> 程序真正读取的是\n
现在, 我们看看本文开头部分的问题。 假设有一个linux下的unix.txt文件, 那么, 它在文件中的换行标志是:\n, 现在把unix.txt拷贝靠Windows上, 那好啊, Windows那双犀利的眼神仿佛是在对unix.txt文件说: 别跟我整什么\n, 我只认识文件中的\r\n, 如果你这个unix.txt文件里面有\r\n, 那我就认为是换行符, 否则, 我不认你。
md5 码一致, 说明压缩解压缩都没问题
最后 : 通过测试发现,不能压缩二进制文件,不能压缩图片,视频,音频文件。
图片的实现底层其实就是Huffman树,
而音频文件其实为二进制文件。
总之
Huffman压缩的思想就是将出现次数多的字符尽量用最短的编码,而编码是01串,那么将来几个比特位就可以保存了,这样节省的空间就越多。
所以:Huffman压缩只能压缩文本文件,并不能压缩二进制文件。
因此,HuffMan 压缩后的文件为二进制文件。
极端情况:
将来256个字符都出现,对应的Huffman树最多也只有10层。所以也不会将文本文件压缩之后变大
本来一个字符需要1个字节来保存,现在我压缩,那么我就可以用几个比特位来存储,将来我再存储一份(每个字符的信息)Huffman树的各结点信息,就可以实现解压缩。
下一篇:
基于LZ77算法的文件压缩