基于spark的流式数据处理—SparkStreaming开发demo—文件流
概述
本文主要完成一个spark streaming的文件流demo,如果是编写一个独立的Spark Streaming程序,而不是在spark-shell中运行,则需要通过如下方式创建StreamingContext对象:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
// 创建StreamingContext对象
val conf = new SparkConf().setAppName("TestDStream").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(1))
文件流
在spark-shell中创建文件流,我这里的创建脚本如下:
cd /opt/IdeaProjects/
mkdir streaming
mkdir streaming/logfile
cd streaming/logfile/
运行完之后,记住这个文件路径:
/opt/IdeaProjects/streaming/logfile
创建文件流监听代码:
package sparkStreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Author: Garrett Wang
* @Description: 测试spark streaming的文件输入流测试
* @Date:Create:in 2019/12/25 17:04
* @Modified By:
* @Parameters
*/
object LzSparkStreamingFileInput {
def main(args: Array[String]): Unit = {
// 创建StreamingContext对象
val conf = new SparkConf().setAppName("TestDStream").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(1))
// 创建文件流,这里的文件路径切记,如果是本地文件已定是三个斜杠,当然也可以hdfs文件
val lines = ssc.textFileStream("file:///opt/IdeaProjects/streaming/logfile")
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_+_)
wordCounts.print()
// 执行这一步之后,程序就开始自动进入循环监听状态
ssc.start()
// 当出现异常时退出
ssc.awaitTermination()
}
}
在刚才的目录下创建一个文件,并编辑内容,如下所示:
vim log1.txt
内容如下:
Hello,my name is Garrett Wang
Hello,my name is Garrett Wang
运行上面代码启动流计算,运行命令如下:
spark2-submit --class sparkStreaming.LzSparkStreamingFileInput /opt/IdeaProjects/LzScalaSparkTest/target/scala-2.11/lzscalasparktest_2.11-0.3.jar
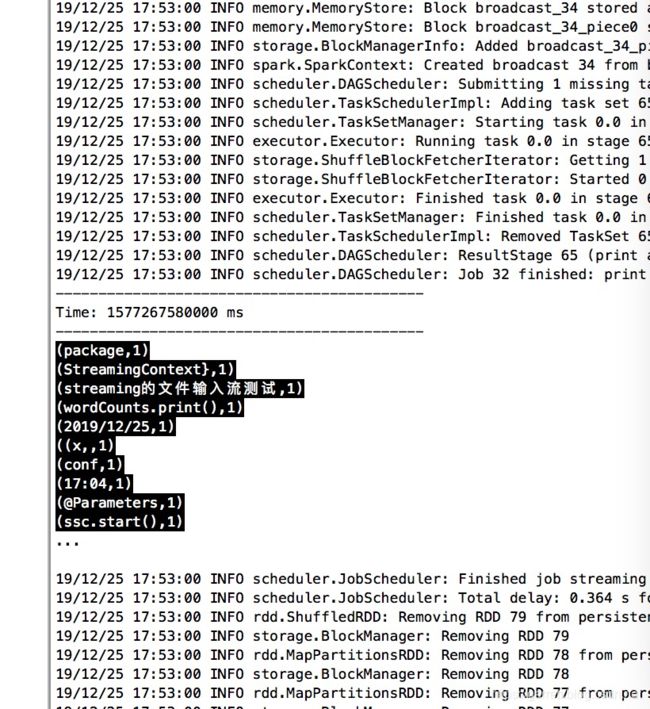
运行结果如下,每秒钟都会又一次刷新:
在监听的文件路径下面再创建一个文件,log2.txt,运行如下命令:
vim log2.txt
内容就用上述代码内容:
package sparkStreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Author: Garrett Wang
* @Description: 测试spark streaming的文件输入流测试
* @Date:Create:in 2019/12/25 17:04
* @Modified By:
* @Parameters
*/
object LzSparkStreamingFileInput {
def main(args: Array[String]): Unit = {
// 创建StreamingContext对象
val conf = new SparkConf().setAppName("TestDStream").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(1))
// 创建文件流,这里的文件路径切记,如果是本地文件已定是三个斜杠,当然也可以hdfs文件
val lines = ssc.textFileStream("file:///opt/IdeaProjects/streaming/logfile")
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_+_)
wordCounts.print()
// 执行这一步之后,程序就开始自动进入循环监听状态
ssc.start()
// 当出现异常时退出
ssc.awaitTermination()
}
}
输出结果如下: