SQL必知必会
基本知识:
- 连接Mysql的命令:mysql -u name -p password -h serverIP -p port
第三章:了解数据库和表
CREATE DATABASE crashcourse;
/*创建名为 crashcourse 的新数据库*/
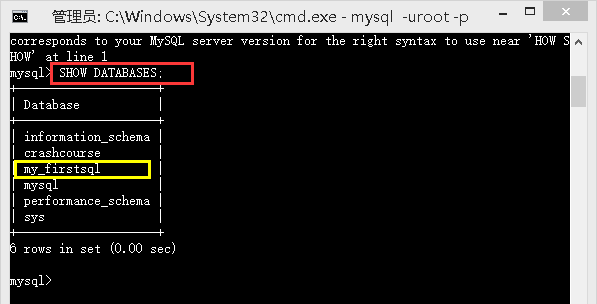
SHOW DATABASES;
/*显示全部数据库*/
USE crashcourse;
/*选择数据库crashcourse供我们使用*/
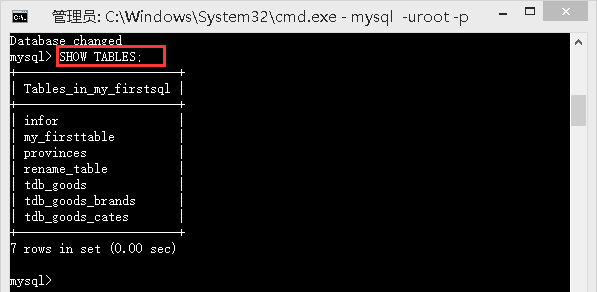
SHOW TABLES;
/*显示当前数据库下全部数据表*/
SHOW COLUMNS FROM my_table;
DESCRIBE my_table;
/*显示表my_table中各字段的信息*/
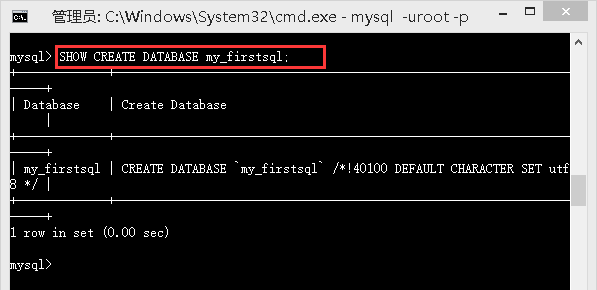
SHOW CREATE DATABASE crashcourse;
/*显示创建特定数据库(crashcourse)的mysql语句*/
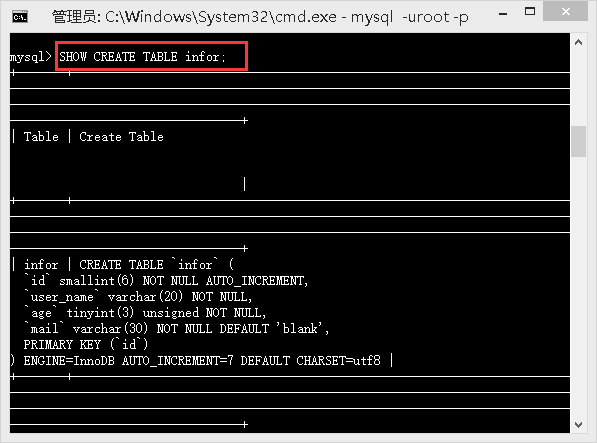
SHOW CREATE TABLE my_table;
/*显示创建特定数据表(my_table)的mysql语句*/
SHOW STATUS;
/*显示广泛的服务器状态信息*/
SHOW ERRORS;
/*显示服务器错误信息*/
SHOW WARNINGS;
/*显示服务器警告信息*/
STATUS;
/*服务器运行状态*/examples:
show databases
 |
use database
 |
show tables
 |
show create database database_name
 |
show create table table_name
 |
第四章:检索数据
//检索单列
SELECT column_nane FROM table_name;
//检索多列
SELECT column_nane1, column_name2 FROM table_name;
//检索所有列,使用*通配符返回表中所有列,通常不建议使用通配符*,过多使用会降低检索和应用程序的性能。
SELECT * FROM table_name;
//检索不同的行
获取表中某列或多列的不同值,只要在SELECT后加上一个DISTINCT即可,语法如下:
SELECT DISTINCT column_name FROM table_name;
注意:DISTINCT关键应用于所有列,而不是前置它的列,如果给出SELECT DISTINCT column_name1, column_name2,除非两个指定的列都不同,否则所有的行都被检索出来。
限制结果
LIMIT字句可以限制SELECT语句返回的数据数量。
LIMIT row_num:row_num表示行数,带一个值的LIMIT总是从第一行开始,返回row_num行
LIMIT no_of_rows, row_num:no_of_rows表示行号,row_num表示行数,带两个值的LIMIT返回第no_of_rows行开始的row_num行
LIMIT no_of_rows, row_num的替代语法为LIMIT row_num OFFSET no_of_rows,意为从行no_of_rows开始取row_num行。行号从0开始
SELECT prod_name
FROM products
LIMIT 5; // 返回前5行
LIMIT 5,5; // 返回从行5开始的5行
LIMIT 4 OFFSET 3; // 返回从第3行开始的4行。第五章:排序检索数据
1、排序数据
select 列名 from 表名;
通过order by子句,默认升序排序
select 列名 from 表名 order by 列名;
2、按多个列排序,先按照第一列排序,第一列相同在按第二列排序
select 列名, 列名, 列名 from 表名 order by 列名, 列名;
3、指定排序方向,按照降序排序
select 列名, 列名, 列名 from 表名 order by 列名 desc;
4、找出一列中的最高或最低值
select 列名 from 表名 order by 列名 desc limie 1;
第六章:过滤数据
表名:products
字段:product_id、product_name、product_price、vend_id(供应商)
使用WHERE子句
一般查询都是需要根据特定条件筛选出来需要的数据,需要制定搜索条件(search criteria),搜索条件也成为过滤条件(filter condition)
注:where子句在FROM之后,且在ORDER BY子句之前。
SELECT product_name FROM products WHERE product_price = 2.50
WHERE子句操作符
 |
6.1.检查单个值
SELECT product_price FROM products WHERE product_name = 'ironman'
注:MySQL在执行匹配时默认不区分大小写,所以ironman与IRONMAN一致。
查找商品价格低于10.0的商品名
注:引号的使用:单引号是用来限定字符串的,如果将值与字符串做比较,则需要使用限定引号。
SELECT product_name FROM products WHERE product_price < 10.0
6.2.不匹配检查
查出不是由供应商(id为1003)生产的商品名
SELECT product_name FROM products where vend_id != 1003
SELECT product_name FROM products where vend_id <> 1003
6.3.范围值查找
查找价格在5-10之间的产品名
SELECT product_name from products where product_price BETWEEN 5 AND 10
6.4.空值检查
在创建一个列不包含值时,称其为包含空值NULL。
SELECT product_name FROM products WHERE product_price is null
第七章:数据过滤
表名:products
字段:product_id、product_name、product_price、vend_id(供应商)为了提供更强的过滤控制,MySQL允许给出多个WHERE子句,这这些子句可以以:AND子句和OR子句的方式使用。
注:操作符(operator)用来联结或改变WHERE子句中的子句的关键字,也成逻辑操作符(logical operator)
操作符都是在WHERE后面的关键字
1.AND操作符
检索供应商id为1003且价格在5到10之间的产品名称
SELECT product_name FROM products WHERE vend_id = 1003 AND product_price BETWEEN 5 AND 102.OR操作符
检索供应商id为1000或1003的产品名称
SELECT product_name FROM products WHERE vend_id = 1000 OR vend_id = 1003注:OR:用于WHERE子句的关键字,用来检索匹配任一条件的行。
3.计算次序
AND比OR操作符的计算次序高,也就是说同时出现AND和OR时,会优先处理AND与其对应的条件。
可以通过()来调整优先级。
检索供应商id为1000或1003且产品价格大于10.0的产品名称
SELECT product_name FROM products WHERE (vend_id = 1000 OR vend_id = 1003) AND produce_price >=10004.IN操作符
IN操作符用于指定条件范围,使用()来限定范围
SELECT product_name FROM products WHERE vend_id IN (1000,1003) ORDER BY product_id注:IN的优点:
在使用合法选项清单时,IN操作符的语法更清晰且更直观。
在使用IN时,计算的次序更容易管理(操作符少)。
IN操作符一般比OR操作执行的快。
IN可以包含其他SELECT语句,能更动态建立WHERE语句。
5.NOT操作符
有且只有一个功能否定后面所跟的任何条件
查找除了供应商id为1000与1003的所有产品名称
SELECT product_name FROM products WHERE vend_id NOT IN(1000,1003)第八章:通配符过滤
表名:products
字段:product_id、product_name、product_price、vend_id(供应商)
1.LIKE操作符
通配符(wildcard)用来匹配值的一部分的特殊字符。
搜索模式(search pattern)由字面值、通配符或两者组合构成的搜索条件。
通配符实际上是WHERE子句有特殊含义的字符,SQL支持几种通配符。
为了在搜索子句中使用通配符,必须使用LIKE操作符,LIKE指示MySQL,后跟的搜索模式利用通配符匹配而不是直接相等匹配进行比较。
2.百分号(%)通配符
最常使用的通配符是百分号(%)。在搜索串中,%表示任何字符出现任意次数。
找到所有的以iron开头的产品名
SELECT product_name FROM products WHERE product_name like 'iron%'注:通配符可在搜索模式中任意位置使用,并且可以使用多个通配符。
注:%可以代表0、1和多个字符,且%不能匹配NULL。
搜索产品名包含man的产品名
SELECT product_name FROM products WHERE product_name list '%man%'3.下划线(_)通配符
下划线的用途与%一样,但下划线只匹配单个字符而不是多个字符。
SELECT product _ name FROM products WHERE product_name like 'an_man'4.使用通配符的技巧
通配符的弊端:通配符搜索处理要比一般的搜索花费更长时间(全表搜索)。
通配符使用技巧:
1.不要过度使用通配符,如果其他操作符能达到相同的目的,应该使用其他操作符。
2.如果必须使用通配符,除非有必要,否则不要把通配符放到搜索模式的开始处,放到开始处,搜索起来最慢。
3.仔细注意通配符的位置,如果放错地方,可能会返回不想要的数据。
第九章:用正则表达式进行搜索
1、正则表达式REGEXP和LIKE的区别
SELECT prod_name
FORM products
WHERE prod_name LIKE '1000'
ORDER BY prod_name;
SELECT prod_name
FORM products
WHERE prod_name REGEXP '1000'
ORDER BY prod_name;
第一段代码不会返回结果,而第二段代码会返回
prod_name
JetPack 1000
因为第一段代码用的是LIKE匹配,但是它又没有使用通配符,所以他匹配的是整个列值,即JetPack 1000,结果是不匹配的。而第二段代码使用的是正则表达式匹配,他会在整个列值之下再度匹配,即匹配JetPack 1000中的1000,所以有结果返回。
2、进行OR匹配
正则表达式中使用OR匹配,使用操作符|,如下所示
输入:
SELECT prod_name
FROM products
WHERE prod_name REGEXP '1000|2000'
ORDER BY prod_name;
输出:
prod_name
JetPack 1000
JetPack 2000
注:操作符|可以多次使用,如 '1000|2000|3000'。
匹配几个字符之一
如果你只想匹配特定字符,可以使用操作符[]。
输入:
SELECT prod_name
FROM products
WHERE prod_name REGEXP '[123] ton'
ORDER BY prod_name;
输出:
prod name
1 ton anvil
2 ton anvil
分析:[123]是匹配1或2或3.反例分析:
输入:SELECT prod_name
FROM products
WHERE prod_name REGEXP '1|2|3 ton'
ORDER BY prod_name;
输出:prod_name
1 ton anvil
2 ton anvil
JetPack 1000
JetPack 2000
TNT (1 stick)分析:输出不符合期望,原因是'1|2|3 ton' 意味着 匹配 1 或 2 或 3 ton,|作用于整个串,除非把它用[]扩起来。
注:字符集合[]也可以被否定,比如[^123]表示匹配除1、2、3外的所有字符。
匹配范围
使用集合可以进行范围匹配,如[1-5]、[6-9]、[a-z]等。
输入:SELECT prod_name
FROM products
WHERE prod_name REGEXP '[1-5] Ton'
ORDER BY prod_name;
输出:
prod_name
.5 ton anvil
1 ton anvil
2 ton anvil3:匹配特殊字符串
要匹配正则表达式自身的字符,如[] | ^等,须加转义符\\ 。
输入:
输入:
SELECT vend_name
FROM vendors
WHERE vend_name REGEXP '\\.'
ORDER BY vend_name
输出:
vend_name
Furball Inc.注:
1、转义符转义\本身,须写为\\\。正则表达式一般是使用一个转义符转义,但是MySQL自己还需要一个,所以是两个。
2、转义符和元字符结合:
\\f 换页
\\n 换行
\\r 回车
\\t 制表
\\v 纵向制表
第九章因为用的不是很多,所以没有详细记载
第十章:创建计算字段
创建在数据库表中的数据一般不是应用程序所需要的格式。
我们需要从数据库中检索出转换、计算或格式化过的数据。
计算字段并不实际存在于数据库表中,计算字段是运行时在SELECT语句内创建的。
字段(field)基本上与列(column)的意思相同,经常互换使用。不过数据库一般称之为列,而术语字段通常用在计算字段的连接。
1.拼接字段
vendors表包含vendor_name与vendor_location两个字段。然后需要到处的数据格式为name(location)。
这是我们使用拼接(concatenate)将值联结到一起构成单个值。
SELECT Concat(vender_name, '(',vender_location,')') FROM vendors ORDER BY vendor_nameConcat()需要拼接一个或多个指定的串。各个串之间使用逗号隔开。
注:RTrim():去掉串右边的空格、LTrim():去掉串左边的空格、Trim():去掉串两边的空格。
删除数据右侧多余的空格来整理数据:
SELECT Concat(RTrim(vendor_name) ,'(',RTrim(vendor_location),')' )FROM vendors ORDER BY vendor_name2.使用别名
使用拼接字段出来的数据没有具体的列名,此时使用别名来替换。
别名(alias)是一个字段或值得替换值,别名用AS关键字赋予
SELECT Concat(vendor_name, '(',vender_location,')') AS vendor_title FROM vendors ORDER BY vendor_name;3.执行算数计算
orders表包含收到的订单:order_id quantity item_price order_num
现在计算订单号为2005的总价:
SELECT order_id,
quantity,
item_price,
quantity * item_price AS expanded_price
FROM orders
WHERE order_num = 2005MySQL的算术操作符:
 |
第十一章:使用数据处理函数
学习目的:
知道什么是函数,MySQL支持哪些函数,以及如何使用这些函数。
函数:SQL支持利用函数来处理数据。函数一般是在数据上执行的,它给数据的转换和处理提供了方便。
函数没有SQL的的可移植强。为了代码的可移植性,许多SQL程序员不赞成使用特殊功实现的功能。如果你决定使用函数,应该保证做好代码注释,以便后来人能确切知道所编写SQL代码的含义。
使用函数:
大多数SQL实现支持一下类型的函数:
- 用于处理文本串(如删除,填充,转换大小写)的文本函数。
- 用于在数值数据上进行算术操作(如返回绝对值、进行代数运算)的数值函数。
- 用于处理时间和日期值并从这些值中提取特定成分(如返回两个日期之差,检查日期的有效性等)的日期和时间函数。
- 返回DBMS正使用的特殊信息(如发挥用户登录信息,检查版本细节)的系统函数。
1:文本处理函数
 |
SOUNDEX是一个将任何文本串转换为描述语言表示的字母数字模式的算法。
Q:customers表中有一个顾 客Coyote Inc.,其联系名为Y.Lee。但如果这是输入错误,此联系名实际应该是Y.Lie,怎么办?
A: 现在试一下使用Soundex()函数进行搜索,它匹配所有发音类似于 Y.Lie的联系名:
SELECT cust_name,cust_contact
FROM customers
WHERE Soundex(`cust_contact`) = Soundex('Y Lei');2:日期和时间处理函数:
日期和时间采用相应的数据类型和特殊的格式存储,以便能快速和有效地排序或过滤,并且节省物理存储空间。
一般,应用程序不使用用来存储日期和时间的格式,因此,日期和时间函数总是被用来读取、统计和处理这些值。由于这个原因,日期和时间函数在MySQL中具有重要作用。
 |
MySQL使用的日期格式:yyyy-mm-dd
SELECT cust_id, order_num
FROM orders
WHERE Date(order_date) ='2005-09-01'
如果要用日期,请使用Date()。检索出2005年9月下的所有订单。
方法一:
SELECT cust_id, order_num
FROM orders
WHERE Date(order_date) BETWEEN '2005-09-01' AND '2005-09-30';
方法二:
SELECT cust_id, order_num
FROM orders
WHERE Year(order_date) =2005 AND Month(order_date) = 9; |
十二章:汇总数据
聚集函数:聚集函数(aggregate function)运行在行组上,计算和返回单个值的函数。
我们经常需要汇总数据而不用把它们实际检索出来,为此MySQL提供了专门的函数,以便分析和报表生成。其用途如下:
- 确定表中行数(或者满足某个条件或包含某个特定值的行数)
- 获得表中行组的和。
- 找出表列(或所有行或某些特定行)的最大值、最小值和平均值。
 |
1 AVG()返回某列的平均值,只能用于单个列,且列名作为参数,如果计算多个列的平均数需要多个AVG()
AVG()通过对表中的行数计数并计算特定列值之和,求得该列的平均值。可用来返回所有列的平均值也可用来返回特定列或行的平均值
SELECT AVG(price) AS avg_price FROM products;
SELECT AVG(price) AS avg_price FROM products WHERE id=1002;2 COUNT()返回某列的行数
COUNT(*)对表中的行进行计数,不管表列中包含的是空值还是非空值
COUNT(column) 对特定列中具有值的行进行计数,忽略NULL值
SELECT COUNT(*) AS num FROM customers;
SELECT COUNT(cust_email) AS num_cast FROM customers3 MAX()MIN()返回指定列的最大/小值,需要指定列名
SELECT MAX(price) AS max_price FROM products
SELECT MIN(price) AS min_price FROM products4 SUM()返回某列的和
SELECT SUM(quanity) AS orders FROM orderitem WHERE order_num=20005;
得出总的订单金额
SELECT SUM(quanity*price) AS total_price FROM orderitem WHERE order_num=20005;对以上5个函数都是默认为所有行,如果只包含不同的值,指定DISTINCT参数
SELECT AVG(DISTINCT price) AS avg_price FROM WHERE id=1003 考虑不同价格的平均值
如果指定列名,DISTINCT 只能用于COUNT()不能用于COUNT(*),所以不允许使用COUNT(DISTINCT),否则产生错误
组合聚集函数
SELECT COUNT(*) AS num_items,
MIN(price) AS price_min,
MAX(price) AS price_max,
AVG(price) AS price_avg,
FROM products;十三章:分组数据
学习目的:
了解如何分组数据,以便能汇总表内容的子集。GROUP BY 和HAVING的使用。
数据分组:
分组允许把数据分成多个逻辑组,以便能对每个组进行聚集计算。
分组是在SELECT语句的GROUP BY子句中建立的。
GROUP BY 子句指示MySQL分组数据,然后对每个组而不是整个结果进行聚合。
在使用GROUP BY 之前,因该知道一些重要的规定。
- GROUP BY子句可以包含任意数目的列。这使得能对分组进行嵌套,为数据分组提供更细致的控制。
- 如果在GROUP BY子句中嵌套了分组,数据将在最后规定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)。
- GROUP BY 子句中列出的每个列都必须是检索列或是有效的表达式(不能是聚集函数)。如果在SELECT中使用表达式,则必须在GROUP BY 子句中指定相同的表达式,不能使用别名。
- 除聚集计算语句外,SELECT 语句中的每个列都必须在GROUP BY 子句中给出。
- 如果分组列中具有NULL值,则NULL将作为一个分组返回。如果列中有多行NULL,它们将分为一组。
- GROUP BY 子句必须出现在WHERE子句之后,在ORDER BY 子句之前。
创建分组
SELECT id,COUNT(*) AS prods FROM products GROUP BY id 过滤分组
HAVING过滤分组,WHERE过滤行;HAVING支持所有的WHERE操作符,语法是相同的只是关键字有差别
SELECT id,COUNT(*) AS orders FROM orders GROUP BY id HAVING COUNT(*) >=2
SELECT id,COUNT(*) AS orders FROM orders WHERE price >=10 GROUP BY id HAVING COUNT(*) >=2分组和排序
ORDER BY 排序产生的输出,任意列都可以使用(甚至非选择的列也可以使用),不一定需要GROUP BY 分组行,但是输出可能不是分组的排序;只可能使用选择列或表达式列,而且必须使用每个选择列表达式。如果与聚集函数一起使用列(或表达式),则必须使用
eg : SELECT num,SUM(quanity*price) AS ordertotal FROM orders GROUP BY num HAVING SUM(quanity*price) >=50为按总计订单价格排序输出,需要添加ORDER BY子句
SELECT num,SUM(quanity*price) AS ordertotal FROM orders GROUP BY num HAVING SUM(quanity*price) >=50 ORDER BY ordertotal |
 |
第十四章:
1、查询(query):任何SQL语句都是查询。但此属于一般指SELECT语句。
2、子查询(subquery):嵌套在其他查询中的查询。
目标:查询订购物品TNT2的用户信息。
前提:有三个表,orderitems表存储物品的订单编号和物品信息,orders表存储订单编号和客户ID,customers表存储客户ID和客户信息。
分解:
1、检索包含物品TNT2的所有订单编号。
2、检索步骤1返回的订单编号的关联的客户ID。
3、检索步骤2返回的客户ID的客户信息。
输入:
SELECT order_num
FROM orderitems
WHERE prod_id = 'TNT2';
输出:
order_num
201
205
输入:
SELECT cust_id
FROM orders
WHERE order_num IN (201,205);
输出:
cust_id
101
103
输入:
SELECT cust_name,cust_contact
FROM customers
WHERE cust_id IN (101,103);
输出:
cust_name cust_conctact
Coy Peter Y Lee
New Ketter Y Sam
嵌套查询:
输入:
SELECT cust_name,cust_contact
FROM customers
WHERE cust_id IN (SELECT cust_id
FROM orders
WHERE order_num IN (SELECT order_num
FROM orderitems
WHERE prod_id = 'TNT2'));
输出:
cust_name cust_conctact
Coy Peter Y Lee
New Ketter Y Sam
注:在WHERE子句中使用子查询,应保证SELECT语句和WHERE子句中列的数目相同。3、作为计算字段使用子查询
输入:
SELECT cust_name,
cust_state,
(SELECT COUNT(*)
FROM orders
WHERE orders.cust_id=customers.cust_id) AS orders
FROM custmers
ORDER BY cust_name;
输出:
cust_name cust_state orders
R Fudd MI 3
Wascals AZ 2分析:orders是一个计算字段,由圆括号里的子查询建立,该子查询调用了2次,每检索到一个客户调用一次。可以看到子查询中的WHERE子句使用了全限定名,因为此处要区分字段的来源。
4、相关子查询(correlated subquery):涉及外部查询的子查询。
任何时候,只要列名具有多意性,就要必须使用这种语法(表名和列名由一个句点分隔)。上面再customers表中使用了orders表就是相关子查询,须用全限定名。