python3字符集编码、中文编码原理与总结
前言
python3在编码问题上会涉及到系统默认编码、本地默认编码和ssh工具终端通信编码三大不同层面,三者可以组合出不同的编码情况,不仔细梳理清楚确实容易弄混。本文在最后会给出一个真实的业务案例,若能搞清楚那么解决python3编码也不在话下了。
系统默认编码
系统默认编码在python3中可以这么理解,是指python3解释器以什么样的编码形式读取.py文件,形象点可以这么认为,你是python3解释器,你面前是磁盘上存储的二进制数据流(.py文件),假设是这样 0101010001110101... ,现在你应该如何解析这个py文件呢?是以utf-8的编码解析0101010001110101...,还是用gb18030解析0101010001110101...?所以显然,用不同的编码解析就有可能得到不同的结果,于是中文就会乱码
举个例子,假设在刚才的py文件中有个中文 “你好”(假设哈),用红色表示,0101010001110101...,那么这个1010001在不同的编码下就会被解析成不同的字符串,print出来也就乱码了
这就是系统默认编码,可通过 sys.getdefaultencoding() 查看
import sys,locale
print(sys.getdefaultencoding())
# >>> 'utf-8'系统默认编码与python3解释器相关,还与下面的相关
#-*- coding: utf-8 -*-这种声明表示强制python3解释器以什么样的编码读取 .py文件,如果没有该声明,python3解释器就会采用系统默认编码来解析二进制流(py文件)
注意,这里提供了一个很重要的思考视角,即把py文件看成二进制数据流0101010001110101...的视角。还要注意,这串二进制流本身是有编码的(即这个py文件的编写者保存时采用的编码,一般是编辑器设置的编码),以错误的编码去读就会乱码
本地默认编码
本地默认编码在python3中可以这么理解,是指python3程序以什么样的编码形式与文件建立联系(读与写)。
在读方面,其任务就是把文件中的二进制流(eg. 1010001)读成内存中的Unicode字符串(eg. 你好),在python3程序内存中,一切字符串皆以Unicode表示,可以这么认为,Unicode就是字符串,字符串就是Unicode,其都表示字符串本身,其永远是正确的。为什么?因为Unicode并不是一个字符编码集,Unicode是一个抽象的字符串大一统,代表一种规范,一种 “接口”,只抽象地为每个字符串赋予ID(Unicode码),并不提供任何存储上的实现,而UTF-8就是Unicode规范下的最流行的实现,因为UTF-8规定了什么样的Unicode该存储成什么样的二进制流,也即写在磁盘上的字符串。
同样,在写方面,其任务就是以什么样的编码将内存中的Unicode字符串写成磁盘上的二进制流
这就是本地默认编码,可通过 locale.getdefaultlocale() 查看
import sys,locale
print(locale.getdefaultlocale())
# >>> ('zh_CN', 'UTF-8')本地默认编码与open函数有关
with open("file.txt","r") as f:
read_data = f.read() # 以本地默认编码来读with open("file.txt","r",encoding = "gb18030") as f:
read_data = f.read() # 强制以gb18030读with open("file.txt","a+") as f:
f.write("你好") # 以本地默认编码写with open("file.txt","a+",encoding = "gbk") as f:
f.write("你好") # 强制以gbk写举个读写文件中文乱码的例子。从起点来看,是从打开编辑器开始。假设A在windows下编辑file.txt,输入了 “真棒”,此时的 “真棒” 代表字符串本身,在内存中,是绝对正确的。然后A的编辑器默认以GB2312保存了,“真棒” 变成了这样:0101101010100111。B把该文件拷到了linux下,用locale命令可看到本地编码为en_US.UTF-8,于是B写的代码 open("file.txt","r") 开始以utf-8读取0101101010100111,在内存中可能就被解析成了�Ϻ�,好,现在考大家一个问题,对于�Ϻ�,B以下列哪种方式写入会更好?
A. with open("output.txt","w") as f:
f.write("�Ϻ�")
B. with open("output.txt","w",encoding = "utf-8") as f:
f.write("�Ϻ�")
C. with open("output.txt","w",encoding = "gb2312") as f:
f.write("�Ϻ�")由于字符串"�Ϻ�"在内存中,本质是Unicode码,它用GB2312实现等同于"你好",用UTF-8实现就不是"你好"了,"�Ϻ�"就是"�Ϻ�"本身,那么写入文件后理所当然就变成了另一段二进制流,假设变成了1111010111111000,此时可发现,我用UTF-8读1111010111111000那就是"�Ϻ�",如果用GB2312读,那就不知到变成啥了,也许是这样����,变得更奇怪。
如果用GB2312写,那么�Ϻ�就被写成了0101101010100111,和最开始的file.txt一模一样,虽然B在linux下读会乱码,但至少A在windows下读还是"真棒",无乱码。至于A选项,由于B的本地编码是en_US.UTF-8,所以A和B选项是一样的,不管在那个系统读都是乱码。故C会更好。
ssh工具终端通信编码
该编码问题一般出现在使用ssh客户端工具连接服务器上。一般地,ssh客户端工具都会有自己的字符编码解析方式,而服务器也会以自身编码方式把字符串转成二进制流,并发送给ssh客户端,如果两者不相同,就会出现乱码。服务器端会根据LANG变量转换字符串。比如现在我本地和服务器的LANG=zh_CN.UTF-8,通过ssh root@your_ip -v 可查看debug信息
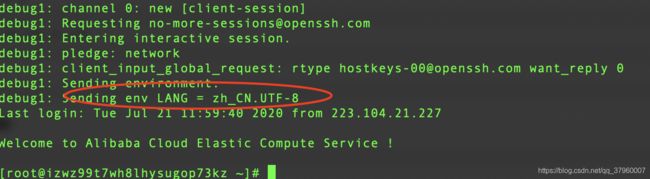
可以看到,本地告诉服务器自身的LANG为zh_CN.UTF-8,于是服务器端也会自动调整自身的LANG为zh_CN.UTF-8,于是通信正常,无乱码
再做实验,还是这个本地终端,我把LANG临时改成zh_CN.GB18030(注意,该终端还是会按zh_CN.UTF-8解析,因为终端在打开时读取系统配置已经定下了,就和其他一些终端设置好的字符集编码一样,设置好了就不会变了),再次ssh连接
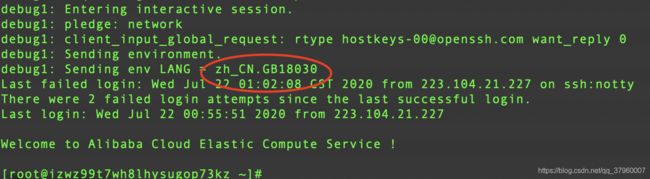
本地向服务端发送了LANG信息,于是服务端也调整成了zh_CN.GB18030,再进行实验
上面乱码是因为"未找到命令"在服务端按gb18030打成二进制流,发给客户端按照utf-8解析。可以看到,服务端后面换成zh_CN.UTF-8后乱码问题就没有了。
真实业务案例
对方是某国企,办公是win7,服务器centos6,echo $LANG后输出zh_CN.GB18030。你在mac上工作,环境统一是zh_CN.UTF-8,编写完python程序后将配置文件和代码一起发给对面。对面有个需求,用python提取服务器上1T的涉密日志文件,将处理后的数据写入到新文件中,涉密日志文件中有中文,通过file命令查看涉密文件的编码显示ISO 8859。对面还有个需求,他们希望可以通过修改配置文件的方式来完成不同数据的提取,比如配置文件中写上海,则提取有关上海的数据,写北京,则提取有关北京的数据。你自己也有个需求,就是需要查看程序日志,以便进行bug处理。
那么问题来了,应该以什么编码保存配置文件?以什么编码让py程序读取配置文件?以什么编码读取涉密日志文件?又以什么编码保存python程序处理文件(py文件中有直接定义的中文字符串)?又以什么编码来生成日志进行调试?
请仔细思考一番再往下看
- 配置文件编码应该为gb18030,使用如下代码生成
with open("extract.config","w",encoding="gb18030") as f:
f.write("xxx配置信息xxx")因为对面是gb18030环境,只有读gb18030格式的文件才不会乱码,你mac上不注意保存了是utf-8格式,对面读取后会乱码。你可能会想,你直接编辑配置文件发给对面就是,虽然是utf-8编码,但你程序里用utf-8读配置文件不一样的可以正确读取吗?的确,这样确实可以正确读取,但是对面可能会更改配置文件,由于对面LANG=zh_CN.GB18030,在他更改中文保存后配置文件实际上就变成了gb18030,甚至不可识别的格式,所以程序用utf-8读显然不行
- py程序应该以gb18030读取配置文件。
因为配置文件是gb18030,程序读取理所应当是gb18030
- 应该以gb18030、gbk、或gb2312的格式读取涉密日志文件。
虽然file命令显示涉密日志格式为ISO 8859,但实际上ISO 8859并不是特定的字符编码集,ISO 8859是表示单字节编码,是一个很宽泛的概念,因此ISO 8859可以表示很多编码,既可以表示GB2312、又可以表示GB18030。那为什么不可以表示utf-8呢?可是可以,只是file命令处理utf-8的文件会显示utf-8,而不是ISO 8859,所以排除。又由于涉密日志中存在中文,所以可以知道其编码是gb18030、gbk、gb2312的一种,但实际上,gb18030是兼容gbk的,gbk又是兼容gb2312的,所以只中文不是太偏,三种编码都可以正确读取。考虑到对面本地默认编码是gb18030,所以文件写入更可能是gb18030,因此用gb18030处理是最妥的
- 应该以utf-8的编码格式读取python程序文件
你是在mac上工作,编辑器、系统等所有环境统一为utf-8,所以你保存的py文件是utf-8编码格式的。由于代码里有中文,参考系统默认编码一节,可知代码里的 "你好" 在磁盘上是二进制,例如由红色部分表示:0101010001110101...,所以你要在代码头部加上#-*- coding: utf-8 -*- 来强制python3解释器用utf-8读取你的代码,这样你好才不会乱码。同理,如果你在windows下保存的代码格式是GB2312,那么你就要加上#-*- coding: gb2312 -*-,这样中文才不会乱码
- 应该以utf-8的编码写入日志调试文件
需要调试bug的不是客户,是作为开发的你,你在mac上工作,本地和系统默认编码都是utf-8,日志当然要用utf-8写。有人会问,不是utf-8又怎样,到时候在转一下不就行了?确实,这也行,但稍微麻烦点,所以最好utf-8,可以直接打开分析日志。这里延伸下,如果是对面想读你的日志呢?那当然就要使用gb18030写入了。
总之,用什么编码写文件,就用什么编码读文件。如果文件是py文件,也就是你的代码,同样适用于前一条,你mac上编辑器用utf-8保存了中文,就要加上utf-8声明 #-*- coding: utf-8 -*-来告诉python3解释器如何读,这不也是“用什么编码写文件,就用什么编码读文件”的一种么 ?只不过普通文件是在open指明如何读,而py文件是在开头加声明指明如何读罢了
但是,用什么编码读文件,不见得就要用什么编码写文件。因为只要你正确地读了,内存端的Unicode字符串就是正确的,用什么编码写这个字符串就得看你业务需求了
搞懂了这些,其实很多编码问题也就迎刃而解了。希望对大家有所帮助!