TensorFlow学习笔记10----Logging and Monitoring Basics with tf.contrib.learn
原文教程:tensorflow官方教程
记录关键内容与学习感受。未完待续。。
Logging and Monitoring Basics with tf.contrib.learn
——当训练一个模型时,实时地跟踪和验证处理过程是很有价值的。在本教程中,你将学习如何使用tensorflow的日志功能和监督API,来审计一个关于鸢尾花分类的神经网络分类器的训练过程。这个教程的代码依赖于tf.contrib.learn Quickstart,如果你没有完成这个教程,你最好先完成此教程,特别是如果你想补充tf.contrib.learn的学习。
1、安装
——对于这个教程,建立在tf.contrib.learn Quickstart的代码之上。
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
import numpy as np
# data sets
IRIS_TRAINING = "iris_training.csv"
IRIS_TEST = "iris_test.csv"
# load datasets.
training_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename = IRIS_TRAINING,
target_dtype = np.int,
features_dtype = np.float32
)
test_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename = IRIS_TEST,
target_dtype = np.int,
features_dtype = np.float32
)
# specify that all features have real-value data
feature_columns = [tf.contrib.layers.real_valued_column("",dimension=4)]
# build 3 layer dnn with 10,20,10 units respectively.
classifier = tf.contrib.learn.DNNClassifier(
feature_columns = feature_columns,
hidden_units = [10,20,10],
n_classes = 3,
model_dir = "/tmp/iris_model"
)
# fit model.
classifier.fit(
x = training_set.data,
y = training_set.target,
steps=2000
)
# evaluate accuracy.
accuracy_score = classifier.evaluate(
x = test_set.data,
y = test_set.target
)["accuracy"]
print('Accuracy:{0:f}'.format(accuracy_score))
# classify two new flower samples.
new_samples = np.array(
[[6.4,3.2,4.5,1.5], [5.8,3.1,5.0,1.7]], dtype=float
)
y = list(classifier.predict(new_samples, as_iterable=True))
print('Predictions: {}'.format(str(y)))——将上述代码复制到一个文件中,下载与之相关的training和test数据集到同一个目录下。
——在以下的模块中,你将会主见地对上述代码做一些更新,添加日志和监控功能。最终合并后的代码可以从这里下载。
2、综述
——tf.contrib.learn Quickstart tutorial介绍了如何实现一个神经网络分类器,将鸢尾花的例子分为三种类别。
——但是教程中的这份code运行后,输出没有包含任何跟踪模型是如何在中间过程训练的日志,仅仅只有打印的结果,如下:
Accuracy: 0.933333
Predictions: [1 2]——实际运行结果截图:
![]()
![]()
——没有任何日志,模型训练感觉就像发生在一个黑盒子中,你无法知道发生了什么,tensorflow是如何进行梯度下降,获取模型是否恰当的合并的信息,或者是升级决定提早停止是否是合适的。
——一个解决这个问题的方法是,分片模型训练,到多个fit函数中,每次调用一个比较小的步数,使得验证的正确度主键增加。然而,在实践中并不推荐,这对训练模型将会大大减慢。幸运的是,tf.contrib.learn提供了另一个解决方法:Monitor API设计用来帮助你在训练的中间过程记录度量和验证模型。在下面部分,你将学习在tensorflow上如何如何有效记录日志,设置ValidationMonitor来做流验证,并且是tensorboard形象化你的度量。
3、Enabling Logging with TensorFlow
——tensorflow对于日志信息有五个不同的级别。为了表明级别上升性,它们是DEBUG,INFO,WARN,ERROR,和FATAL。当你在这几个级别中设置日志时,tensorflow将会输出与这个级别相关的、以及更高级别的所有日志文件。例如,如果你设置了一个ERROR级别的日志,你得到的输出日志信息将包括ERROR和FATAL,如果你设置的级别是DEBUG,你将会得到所有5个级别的日志信息。
——默认情况下,tensorflow设置成WARN级别的日志,但是当跟踪模型训练时,你可以调整级别到INFO,它将提供fit操作过程中额外的反馈。
——在你代码最开始的地方添加如下一行,(在你的imports模块之后):
tf.logging.set_verbosity(tf.logging.INFO)
——当你运行代码时,你将看到如下一样额外的日志输出:
INFO:tensorflow:Training steps [0,200]
INFO:tensorflow:global_step/sec: 0
INFO:tensorflow:Step 1: loss_1:0 = 1.48073
INFO:tensorflow:training step 100, loss = 0.19847 (0.001 sec/batch).
INFO:tensorflow:Step 101: loss_1:0 = 0.192693
INFO:tensorflow:Step 200: loss_1:0 = 0.0958682
INFO:tensorflow:training step 200, loss = 0.09587 (0.003 sec/batch).——实际运行结果截图:


![]()
——在INFO级别下,tf.contrib.learn每100步后,自动输出training-loss
metrics到stderr中。
4、Configuring a ValidationMonitor for Streaming Evaluation
——记录训练损失对于获取你的模型是否收敛的信息是很有帮助的,但是如果你想进一步地洞悉训练过程到底发生了什么,tf.contrib.learn提供几个高级别的Monitors,你可以添加到你的fit操作中,进一步地跟踪度量或者是在模型训练过程中,调试低级别的tensorflow操作,包括:
| Monitor | Description |
|---|---|
| CaptureVariable | Saves a specified variable’s values into a collection at every n steps of training |
| 在训练的每n步之后,保存一个指定变量的值到一个聚集中。 | |
| PrintTensor | Logs a specified tensor’s values at every n steps of training |
| 在训练的每n步之后,记录指定的tensor的值。 | |
| SummarySaver | Saves Summary protocol buffers for a given tensor using a SummaryWriter at every n steps of training |
| 使用一个SummaryWriter在训练的每n步之后,保存指定tensor的简要协议缓冲。 | |
| ValidationMonitor | Logs a specified set of evaluation metrics at every n steps of training, and, if desired, implements early stopping under certain conditions |
| 在训练的每n步之后记录验证度量的指定集合,如果需要,在确定的条件下实现提早停止。 |
4.1 Evaluating Every N Steps
——在鸢尾花神经网络分类器,当记录训练损失时,你可能想同时的验证测试数据,来看看模型是如何归纳的。你可以通过配置ValidationMonitor,来完成测试数据(test_set.data和test_set.target)的验证,并且设置every_n_steps来确定多长时间验证一次。every_n_steps的默认值是100,这里设置every_n_steps为50,在模型训练中每50次进行一次验证。
validation_monitor = tf.contrib.learn.monitors.ValidationMonitor(
test_set.data,
test_set.target,
every_n_steps=50
)——-将这几行代码放在实例化classifier之前。
——ValidationMonitors依赖于保存检查点以完成验证操作,因此,如果你想修改classifier的实例化以添加一个包含save_checkpoints_secs的RunConfig,save_checkpoints_secs指定了在训练过程中,间隔多少秒来保存检查点。因为鸢尾花数据非常小,训练的很快,设置save_checkpoints_secs为1(每1秒保存一个检查点)来保证有足够多的检查点的数据是合理的。
classifier = tf.contrib.learn.DNNClassifier(
feature_columns=feature_columns,
hidden_units=[10,20,10],
n_classes=3,
model_dir="/tmp/iris_model",
config=tf.contrib.learn.RunConfig(save_checkpoints_secs=1)
)——注意:model_dir参数指定了模型数据存放的一个具体路径(/tmp/iris_model),这个路径比自动产生的更容易引用。每次你运行这个代码,任何存在于/tmp/iris_model的数据都会被加载,并且模型训练将会一直持续,在最后一次运行时(例如,连续运行两次脚本在训练过程中将会执行4000步—-每次fit操作会有2000步)会中断。为了重新开始模型训练,在运行代码之前要删除/tmp/iris_model。
——最后,为了依附于你的validation_monitor,更新fit调用,包括monitors参数,在模型训练中需要所有monitors的一个列表来运行。
classifier.fit(
x=training_set.data,
y=training_set.target,
steps=2000,
monitors=[validation_monitor]
)——现在,当你运行代码时,你可以在你的日志输出中看到验证度量,例如:
INFO:tensorflow:Validation (step 50): loss = 1.71139, global_step = 0, accuracy = 0.266667
...
INFO:tensorflow:Validation (step 300): loss = 0.0714158, global_step = 268, accuracy = 0.966667
...
INFO:tensorflow:Validation (step 1750): loss = 0.0574449, global_step = 1729, accuracy = 0.966667——实际运行截图:




4.2 Customizing the Evaluation Metrics
——默认情况,如果没有验证度量被指定,ValidationMonitor将同时记录loss和正确度,但是你可以自定义度量的列表,每50步运行一次。tf.contrib.metrics module为分类模型提供各种额外的度量函数,你可以在盒子之外使用ValidationMonitor,包括streaming_precision和streaming_recall。为了在每一个验证环节要确定你要运行的那个准确的度量,在ValidationMonitor构造函数添加一个ValidationMonitor参数,metrics包含了一个字典的键值对,每一个键就是你想记录的度量的名字,与之相关联的值就是计算度量的函数。
——-如下所示恢复ValidationMonitor的构造函数,除了正确度(loss总是被记录的,但是不需要明确的指定),添加精度和回调的记录。
validation_metrics = {
"accuracy":tf.contrib.metrics.streaming_accuracy,
"percision":tf.contrib.metrics.streaming_precision,
"recall":tf.contrib.metrics.streaming_recall
}
validation_monitor = tf.contrib.learn.monitors.ValidationMonitor(
test_set.data,
test_set.target,
every_n_steps=50,
metrics=validation_metrics
)——重新运行这个代码,你可以在你的日志输出中看到精度和回调,如下:
INFO:tensorflow:Validation (step 50): recall = 0.0, accuracy = 0.266667, global_step = 0, precision = 0.0, loss = 1.71139
...
INFO:tensorflow:Validation (step 150): recall = 1.0, accuracy = 0.966667, global_step = 132, precision = 1.0, loss = 0.157797
...
INFO:tensorflow:Validation (step 1600): recall = 1.0, accuracy = 0.966667, global_step = 1589, precision = 1.0, loss = 0.055873——第一次运行出现了错误:“ValueError: Metrics passed provide only name, no prediction, but predictions are dict. Metrics: {‘recall’: , ‘percision’: , ‘accuracy’: }, Labels: Tensor(“output:0”, shape=(?,), dtype=int64).”截图如下:
![]()
——-查找了半天也没找出什么原因,然后看到别人在写validation_metrics的时候键值的写法上有些不同,于是尝试了一下,竟然可以,修改代码如下:
validation_metrics = {
"accuracy":
tf.contrib.learn.MetricSpec(
metric_fn=tf.contrib.metrics.streaming_accuracy,
prediction_key=tf.contrib.learn.PredictionKey.CLASSES),
"precision":
tf.contrib.learn.MetricSpec(
metric_fn=tf.contrib.metrics.streaming_precision,
prediction_key=tf.contrib.learn.PredictionKey.CLASSES),
"recall":
tf.contrib.learn.MetricSpec(
metric_fn=tf.contrib.metrics.streaming_recall,
prediction_key=tf.contrib.learn.PredictionKey.CLASSES)
}——–截图如下:
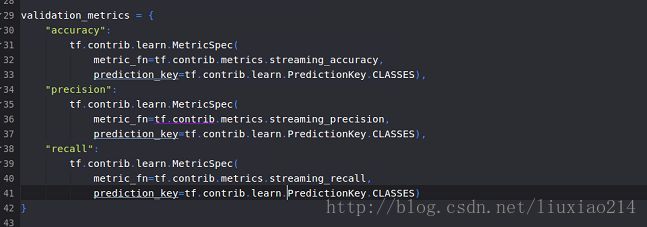
——最终运行结果如下:
![]()
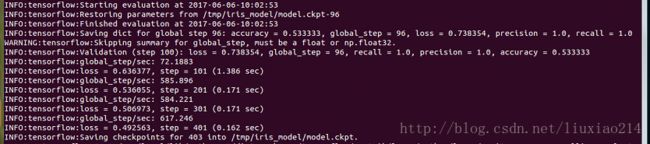

![]()

4.3 Early Stopping with ValidationMonitor
——注意,在上述的日志输出中,在150步的时候,模型已经实现了精度和回调都是1.0的比率,这里提出问题,模型训练提早停止是有好处的。
——除了记录验证度量,当指定的情形是met,通过三个参数,ValidationMonitors使得实现提早停止也是很容易的:
| Param | Description |
|---|---|
| early_stopping_metric | Metric that triggers early stopping (e.g., loss or accuracy) under conditions specified in early_stopping_rounds and early_stopping_metric_minimize. Default is “loss”. |
| - | 在指定early_stopping_rounds和early_stopping_metric_minimize之下,触发提早停止(如loss和正确度)的度量。默认是loss。 |
| early_stopping_metric_minimize | True if desired model behavior is to minimize the value of early_stopping_metric; False if desired model behavior is to maximize the value of early_stopping_metric. Default is True. |
| - | 如果希望的模型行为是最小化early_stopping_metric的值的话就为true,如果希望的模型行为是最大化early_stopping_metric的值的话就是false,默认为true。 |
| early_stopping_rounds | Sets a number of steps during which if the early_stopping_metric does not decrease (if early_stopping_metric_minimize is True) or increase (if early_stopping_metric_minimize is False), training will be stopped. Default is None, which means early stopping will never occur. |
| - | 设置一个步数,在这个步数之后,如果early_stopping_metric没有减少(如果early_stopping_metric_minimize是true)或者提高(如果early_stopping_metric_minimize是false),训练将会停止。默认是None,这意味着提早停止永远不会发生。 |
.
——以下关于ValidationMonitor构造函数的修正版明确了,如果超过200步(early_stopping_rounds=200)之后,损失loss(early_stopping_metric=”loss”)没有减少(early_stopping_metric_minimize=True),模型训练将会在那个点立刻停止,并且不会完成在fit中指定的2000步的训练。
validation_monitor = tf.contrib.learn.monitors.ValidationMonitor(
test_set.data,
test_set.target,
every_n_steps=50,
metrics=validation_metrics,
early_stopping_metric="loss",
early_stopping_metric_minimize=True,
early_stopping_rounds=200
)——-运行这份代码,如果模型训练提前停止的话:
...
INFO:tensorflow:Validation (step 1450): recall = 1.0, accuracy = 0.966667, global_step = 1431, precision = 1.0, loss = 0.0550445
INFO:tensorflow:Stopping. Best step: 1150 with loss = 0.0506100878119.——实际运行结果:


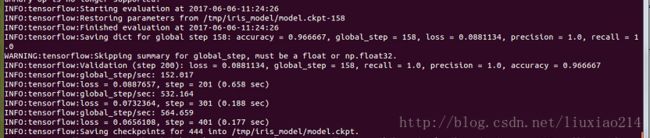
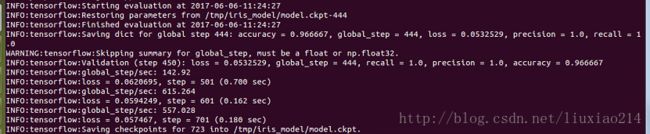



——事实上,这里训练在1450步(自己的实际运行是1050)的时候停止,这表明在过去的200步中,loss没有减少,总的来说,在1150步的时候,测试数据集产生了最小的损失值。这意味着超参数额外的校准可以通过减少步数来进一步的提高模型。
5、Visualizing Log Data with TensorBoard
——通过阅读ValidationMonitor产生的日志,在训练过程中,提供了大量的模型性能上的原始数据,但是看到这些数据的可视化是有用的,可以进一步的洞察它的趋势—例如,随着训练步数的改变,正确度是如何改变的。你可以使用tensorBoard(tensorflow包装过的一个分离的程序)画出图,通过设置logdir的命令行参数到你存储模型训练数据的路径中(这里是/tmp/iris_model)。在你的命令行下运行下面代码:
$ tensorboard --logdir=/tmp/iris_model/——截图:

——接着在你的浏览器中输入提供的URL(这里是http://0.0.0.0:6006)。如果你点击accuracy部分,你将会看到如下的一个图像,这里显示了随着训练步数标注的正确度。
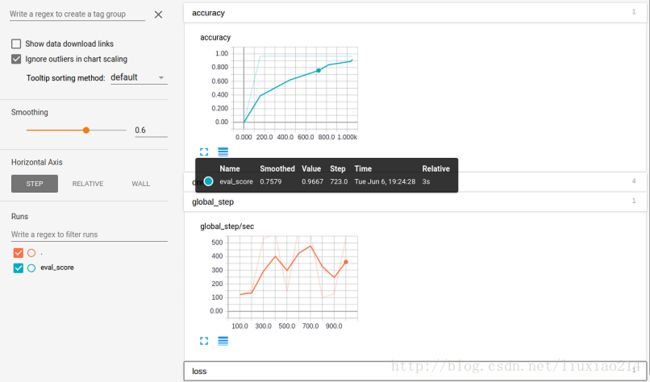

——更多关于TensorBoard的使用,点击TensorBoard: Visualizing Learning和TensorBoard: Graph Visualization。
——以上,结束。