Unity3D机器学习 - 编写自定义Agent,创建自己的AI Bot
我最近一直在玩新的Unity3D机器学习系统,取得了一点进展。我想分享我发现的步骤,以获得一个新创建的Agent设置,并经过训练完成一项基本任务。 在这篇文章中,您将看到如何设置基本Agent,目的是使用增强机器学习来完成随机选择的数字。 我们将使用新的Unity ML Agent系统和tensorflow来创建和训练Agent完成任务,并讨论将其扩展到真实游戏AI的方法。
翻译自外国文章看参考
设置 Tensorflow和UnityML
如果您尚未安装 并设置tensorflow ,你需要按照下属链接设置:
https://unity3d.college/2017/10/25/machine-learning-in-unity3d-setting-up-the-environment-tensorflow-for-agentml-on-windows-10/
AgentML场景设置
一旦你完成了这个过程,打开Unity项目并创建一个新的场景。
我们需要的第一件事就是academy。 创建一个新的gameobject,将其命名为“NumberAcademy”。
将“TemplateAcademy”组件添加到“NumberAcademy”中。 我们的设置不需要Academy做任何特别的事情,所以我们可以从模板中提供的基础空白学院开始。

在Academy下,创建另一个子游戏对象。 将其命名为“NumberBrain”。
添加一个大脑组件。
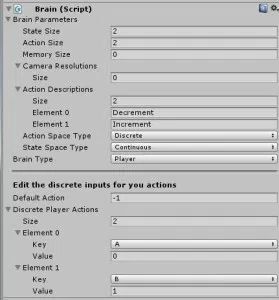
将State&Action大小变量设置为2。
将动作空间类型设置为离散。 我们将在我们的项目中使用2个离散的动作(向上或向下)。 我们使用离散量因为它们被表示为整数。
将状态空间类型设置为连续。 我们将跟踪两个浮点数状态,所以我们使用连续变量。

将大脑类型设置为“玩家”
添加2个动作。 选择你想要的任何2个键(我和A&B一起去),但是将值设置为0和1.绑定到值0的键递减#,绑定到1的键将增加它。
NumberDemoAgent脚本
创建一个名为NumberDemoAgent.cs的新脚本
将基类设置为代理(将:MonoBehaviour替换为:代理)
添加以下字段:
public class NumberDemoAgent : Agent
{
[SerializeField]
private float currentNumber;
[SerializeField]
private float targetNumber;
[SerializeField]
private Text text;
[SerializeField]
private Transform cube;
[SerializeField]
private Transform sphere;
int solved;
view rawNumberDemoAgent-Fields.cs hosted with ❤ by GitHub}
currentNumber和targetNumber字段在这里是最重要的。 一切都只是为了调试和可视化。
我们的代理将选择一个随机目标数,并尝试使用我们的递增和递减命令获取currentNumber到我们的目标。
接下来我们需要重写这个CollectState方法:
public override List CollectState()
{
List state = new List();
state.Add(currentNumber);
state.Add(targetNumber);
return state;
}
view rawNumberDemoAgent-CollectState.cs hosted with ❤ by GitHub
在这里,我们正在将我们的两个浮点数作为我们Agent状态返回当前和目标号。 请注意,如何与大脑上的2个状态变量相匹配,并且它们都是浮点数,这就是为什么我们将其设置为连续状态而不是离散的。
对于我们的Agent来说,我们需要选择随机的目标号码。 为此,我们将覆盖AgentReset()方法,如下所示:
public override void AgentReset()
{
targetNumber = UnityEngine.Random.RandomRange(-1f, 1f);
sphere.position = new Vector3(targetNumber * 5, 0, 0);
currentNumber = 0f;
}
view rawNumberDemoAgent-AgentReset.cs hosted with ❤ by GitHub我们需要的最后和最重要的部分是AgentStep()方法。 这是我们要采取的行动(又称输入),执行一些任务(响应行动)的地方,并引导我们的Agent做出成功的选择。
public override void AgentStep(float[] action)
{
if (text != null)
text.text = string.Format("C:{0} / T:{1} [{2}]", currentNumber, targetNumber, solved);
switch ((int)action[0])
{
case 0:
currentNumber -= 0.01f;
break;
case 1:
currentNumber += 0.01f;
break;
default:
return;
}
cube.position = new Vector3(currentNumber * 5f, 0f, 0f);
if (currentNumber < -1.2f || currentNumber > 1.2f)
{
reward = -1f;
done = true;
return;
}
float difference = Mathf.Abs(targetNumber - currentNumber);
if (difference <= 0.01f)
{
solved++;
reward = 1;
done = true;
return;
}
}
view rawNumberDemoAgent-AgentStep.cs hosted with ❤ by GitHub
你会看到的第一件事是我们的文本更新。这仅用于调试/可视化。它可以让我们看到当前的#,目标和我们成功解决问题的次数(达到目标号码)。
接下来是我们看待行动并执行我们任务的开关。在这种情况下,我们通过递减当前数字来响应动作0,或者通过递增来响应动作1。任何价值不应该发生,但如果我们得到一个,我们只是忽略它并返回。
然后,我们根据currentNumber移动我们的立方体(使用它为x偏移量)。这个立方体只是为了可视化,它对实际的逻辑或训练没有影响。
然后我们根据一些已知的限制检查currentNumber。因为我们选择-1和1之间的随机数,如果我们达到-1.2或+1.2,我们可以认为它是一个失败,因为它肯定是错误的方向。在这种情况下,我们将奖励设置为-1表示失败,然后将其标记为true,以便代理可以重置并重试。
最后,我们检查一下currentNumber是否在目标的0.01以内。 如果是这样,我们认为这是一场比赛,将奖励设为1.0,取得成功,并将其标记为已完成。 我们也增加了解决的计数器进行调试(很高兴看到它成功了多少次)。
这是完整的脚本:
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.UI;
public class NumberDemoAgent : Agent
{
[SerializeField]
private float currentNumber;
[SerializeField]
private float targetNumber;
[SerializeField]
private Text text;
[SerializeField]
private Transform cube;
[SerializeField]
private Transform sphere;
int solved;
public override List CollectState()
{
List state = new List();
state.Add(currentNumber);
state.Add(targetNumber);
return state;
}
public override void AgentStep(float[] action)
{
if (text != null)
text.text = string.Format("C:{0} / T:{1} [{2}]", currentNumber, targetNumber, solved);
switch ((int)action[0])
{
case 0:
currentNumber -= 0.01f;
break;
case 1:
currentNumber += 0.01f;
break;
default:
return;
}
cube.position = new Vector3(currentNumber * 5f, 0f, 0f);
if (currentNumber < -1.2f || currentNumber > 1.2f)
{
reward = -1f;
done = true;
return;
}
float difference = Mathf.Abs(targetNumber - currentNumber);
if (difference <= 0.01f)
{
solved++;
reward = 1;
done = true;
return;
}
}
public override void AgentReset()
{
targetNumber = UnityEngine.Random.RandomRange(-1f, 1f);
sphere.position = new Vector3(targetNumber * 5, 0, 0);
currentNumber = 0f;
}
}
view rawNumberDemoAgent.cs hosted with ❤ by GitHub
设置Agent
准备好脚本后,我们需要创建一个新的游戏对象并将其命名为“NumberDemoAgent”。
将NumberDemoAgent脚本附加到它并分配大脑。

接下来创建一个Text对象并将其放在可以看到的位置(理想情况下在屏幕中间很大)。
将文本对象分配给NumberDemoAgent。
创建一个立方体和一个球体,并将它们分配给NumberDemoAgent(这些将帮助您看到发生了什么,比阅读#更容易)。
在玩家模式下测试
现在按播放 你应该可以用你的两个热键左右移动多维数据集(记住我用A&B的热键)。
当你把球送到球体时,它应该增加解决的计数并重置。 如果你走得太远,错误的方式也应该重置(记住1.2限制)。
训练
一旦它在播放器模式下工作,选择大脑并将“大脑类型”更改为“外部”
保存场景并构建可执行文件,其中包含的场景是唯一的(启用了调试模式)。
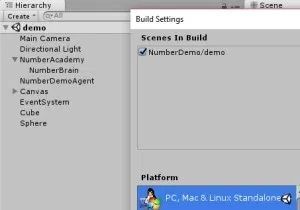
对于您的输出文件夹,选择您的ml-agents项目的python子目录(包含在您下载或克隆源项目时)。 例如,我的位于这里:C:\ ml-agents \ python。
将目录更改为刚构建的python文件夹。 ex. “cd c:\ml-agents\python”
Anaconda / Jupyter
输入命令“jupyter notebook”(您可能需要按第二次输入btw)
不久之后应该提示您的Web界面,如下所示:
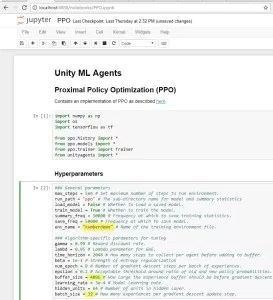
更改突出显示的部分以匹配。在env_name上,不要仅仅放入“numberdemo”,使用你构建可执行文件的名称,Buffer_size和batch_size。你可以复制(重要的是要注意,这些#只是通过测试/尝试
发现,即使在工作之后,我仍然几乎不了解他们发生了什么)。
完成编辑超级参数后,请按顺序运行步骤。
从步骤1和2开始。*消失,#完成后,
出现。
当你运行步骤3,你应该看到一个窗口出现在你的游戏(一个小窗口)。第一次,你也可以获得一个Windows权限对话框,确保允许它。
一旦你开始步骤4 ...等待..并观察结果进来(第一个可能需要一分钟,以便耐心等待)
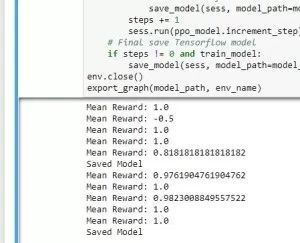
一旦保存了几次,点击停止按钮。然后转到步骤5并运行它。这将导出您的训练数据到“python / models / ppo”子文件夹中的.bytes文件。

复制.bytes文件(再次命名为匹配您的可执行文件名称),并将其放在您的Unity项目中。
选择大脑并将“大脑类型”设置为“内部”。
将.bytes文件分配给“图形模型”字段。
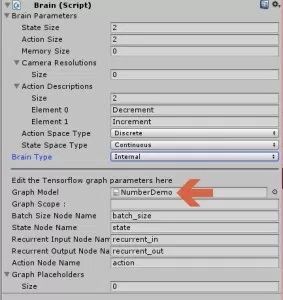
结论
这是一个非常简单的示例,旨在帮助您了解该系统的工作原理。 我很高兴看到你们可以建立更大的更有趣的项目来控制游戏AI,并制作有趣的游戏/漫游器。
参考网址
Unity ML Agents GitHub – https://github.com/Unity-Technologies/ml-agents
HyperParameters Doc – https://github.com/Unity-Technol ... st-practices-ppo.md
Machine Learning Playlist –https://www.youtube.com/watch?v= ... A4iHoDUx7vg37sVoL-E