基于飞桨PaddlePaddle复现论文U-GAN-IT
基于飞桨PaddlePaddle复现论文U-GAN-IT
百度顶会论文复现营
U-GAN-IT论文讲解视频
U-GAN-IT论文原文地址
U-GAN-IT项目github地址
感谢百度AI Studio平台以及论文复现营的老师同学助教们!一起进步鸭!
1、引言
图像到图像的翻译旨在学习在两个不同域中映射图像的功能。由于该主题的广泛应用,包括图像修复,风格迁移,因此在机器学习和计算机视觉领域引起了研究人员的广泛关注。当给出配对样本时,可以使用条件生成模型以监督方式训练映射模型。在没有成对数据的无监督环境下,则需要进行多项工作,比如使用共享潜在空间和周期一致性假设实现图像的转换。
尽管取得了这些进步,但先前的方法仍显示出性能差异,具体取决于域之间形状和纹理的变化量。例如,它们对于映射局部纹理的样式转换任务(例如photo2vangogh和photo2portrait)是成功的,但是当遇到图像中形状变化较大的图像翻译任务(例如selfi2anime和cat2dog)是不成功的。 因此,通常需要通过限制数据分布的复杂性来避免图像裁剪和对齐等预处理步骤. 此外,现有的方法无法通过固定的网络体系结构和超参数获得保留形状的图像转换(例如horse2zebra)和更改形状的图像转换(例如cat2dog)所需的结果。需要针对特定数据集调整网络结构或超参数设置。
2、本文实现的工作
- 提出了一种无监督的图像到图像翻译的新方法,可以满足纹理和图像差别很大的两个图像域之间的转换问题。该方法具备新的attention模块和新的归一化功能AdaLIN。
- attention模块通过基于辅助分类器获得的attention map增强生成器的生成能力,从而区分源域和目标域,也增强了判别器的判别能力,更好地区分了原始图像和生成图像。
- AdaLIN功能帮助我们的attention-guided模型灵活地控制形状和纹理的变化量,而无需修改模型架构或超参数。即在相同的模型架构和超参数情况下实现保留形状的图像转换(例如horse2zebra)和更改形状的图像转换(例如cat2dog)。如下图所示
3、预备知识
3.1 GAN
GAN即生成对抗网络,由一个生成器和一个判别器组成。以图像生成模型为例,生成器的目标是要尽可能地生成接近真实的图像,而判别器的目标是要尽可能地区分真假图片,在生成器和判别器的这种博弈关系中,构成了GAN。GAN的模型可以简化为:生成器生成图片->判别器学习区分生成的图片和真实图片->生成器根据判别器的结果改进自己->生成新的图片-> ······。
3.2 cycleGAN
cycleGAN论文地址
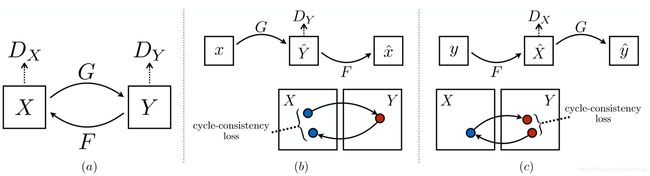
此模型包含两个映射函数G:X→Y和F:Y→X,以及相关的对抗性标识符DY和DX。DY鼓励G将X转换为与域Y不可区分的输出,对于DX和F则反之亦然。为了进一步规范化映射,我们引入了两个循环一致性损失函数,如果我们从一个域转换为另一域然后再转换为最初的域,则应该和最初的域几乎一致:(b)前向循环一致性损失:X→G(X)→F(G(X))≈X,以及©后向循环一致性损失:Y→F(Y)→ G(F(Y))≈Y。
4、模型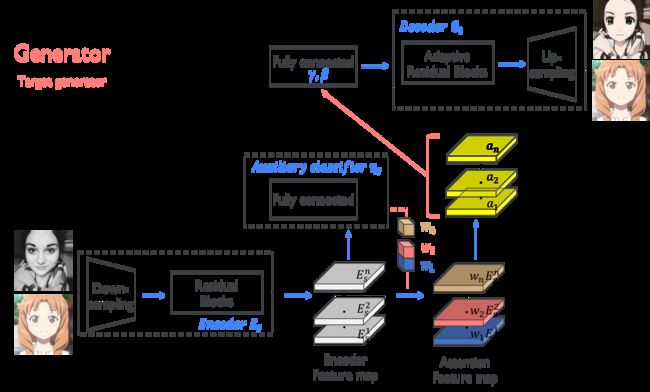

从模型结构上来看生成器和判别器的结构几乎相同,但是生成器比判别器多了AdaLIN和Decoder部分
从模型的流程上来看生成器首先对输入的图像进行下采样,然后通过残差模块得到编码特征图,然后将该特征图经过全连接层得到一个节点的预测,再将全连接层的参数和编码特征图相乘得到attention特征图,再对attention特征图通过AdaLIN引导至可适应残差块,最后上采样得到转换后的图像。
对于本文的U-GAT-IT来说,是由两个GAN网络组成的,一个网络实现将源图像变为目标图像,另一个GAN网络则可以将目标图像变为原图像的模式。
5、AdaLIN
本文提出的AdaLIN自适应归一化方法是在传统的归一化方法上进行的改进。一般来说实例级归一化Instance Normalization (IN)和层级归一化Layer
Normalization(LN)使用场景较多,LN更多的是考虑输入通道之间的相关性,所以在不同图像风格的转换上更加彻底,而IN更多的是考虑到的是单个通道的内容,从而可以更好地保存原图像的语义信息,所以本文将这两种归一化方式结合起来,提出了AdaLIN,它可以在IN和LN之间动态选择。
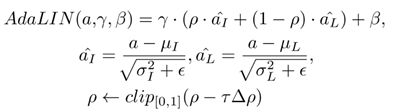
要注意的是AdaLIN仅对图像的map做归一化。
6、损失函数
6.1 对抗损失
对抗损失用于使翻译后的图像的分布与目标图像的分布相匹配:![]()
6.2 周期损失
周期损失是为了减轻模式坍塌问题,我们将周期一致性约束应用于生成器。给定一个图像X∈Xs,在X从Xs到Xt以及从Xt到Xs的顺序转换之后,图像应成功转换回原始域:

6.3 身份损失
身份损失是为了确保输入图像和输出图像的颜色分布相似,我们将身份一致性约束应用于生成器。给定图像X∈Xt,使用Gs→t转换X后,图像不应改变。

6.4 CAM损失
生成器中对图像域分类,希望源域和目标域可以尽可能分开,这部分利用交叉熵损失。
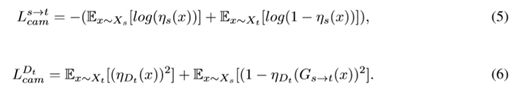
7、实验
本文用五个不成对的图像数据集(包括四个代表性的图像翻译数据集)和一个新创建的由真实照片和动画作品(即selfie2anime)组成的数据集评估了每种方法的性能。所有图像均调整为256×256进行训练。
8、实验结果
计算真实图像和生成图像之间的最大均值差异,值越小表示真是图像与生成图像之间有更多视觉相似性,图像翻译的效果越好。


其中从顶到下数据集分别为selfie2anime,horse2zebra, cat2dog, photo2portrait, and photo2vangogh,(a)Source images, (b)U-GAT-IT, ©CycleGAN, (d)UNIT, (e)MUNIT, (f)DRIT, (g)AGGAN
可以很明显地看出U-GAT-IT的效果最好。
9、代码分析
- 其中main.py是程序的入口,训练时运行该程序即可
- UGATIT.py给出了训练步骤和流程,其中包括了优化器的定义,网络的调用以及反向传播等操作
- 网络的结构在networks.py文件中进行了定义,其中包括生成器和判别器的定义,以及网络各层的搭建和定义
- dataset.py主要是进行数据的读取和预处理
- utils.py进行了一些网络需要的参数的定义
持续更新中。。。。。。