CVPR2020(Enhancement):论文解读《Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement》
文章目录
- 原文地址
- 论文阅读方法
- 初始(Abstract & Introduction & Conclusion)
- 相知(Body)
- 2. Related Work
- Conventional Methods
- Data-Driven Methods
- 3. Methodology
- 3.1 Light-Enhancement Curve (LE-Curve)
- 3.2 DCE-Net
- 3.3 Non-Reference Loss Functions
- 4. Experiment
- 4.1 Ablation Study
- 4.2 Benchmark Evaluations
- 4.2.1 Visual and Perceptual Comparison
- 4.2.2 Quantitative Comparison
- 4.2.3 Face Detection in the Dark
- 回顾(Review)
- 代码
原文地址
https://arxiv.org/abs/2001.06826
论文阅读方法
三遍论文法
初始(Abstract & Introduction & Conclusion)
Low-Light(低光照)图像会降低图像美学以及传递信息的质量,前者会影响观者体验,后者会导致错误信息的传递(例如:物体/人脸识别)。本文提出了一种新方法(light-weight deep network)用于解决Low-Light图像增强问题,它将这个任务转换为了一个image-specific曲线估计问题(图像作为输入曲线作为输出),这类曲线对在输入的动态范围内进行像素级调整,从而获得增强图像。
并且作者通过设置一系列non-reference的损失函数(spatial consistency loss, exposure control loss, color constancy loss, illumination smoothness loss,可以间接反映增强质量),使得网络在没有任何参考图像的情况下能够进行end-to-end训练,整个方法在多个数据集上都取得了SOTA。

从上图的示例可以看出来,Zero-DCE能够在保持固有颜色和细节的情况下,对图像进行很好的增强。
本文的主要贡献有三点:
- 提出了第一个与paired或unpaired data无关的low-light增强网络,这样既避免了过拟合的风险,也可以使得网络能很好地泛化到各种光照条件下。
- 设计了一个image-specific曲线,通过反复应用自身,能拟合成一条pixel-wise and higher-order曲线,可以在更广的动态范围内进行有效的映射。
- Zero-DCE能够在没有参考图像的情况下进行训练(通过设置task-specific的non-reference损失函数,其可间接评估增强质量)
除此之外,Zero-DCE是light-weight的,计算量很小,所以可以应用于其他任务,并提高检测精度(例如人脸检测)
相知(Body)
2. Related Work
Conventional Methods
作者在这节介绍了一些传统的方法(例如:HE-based,基于图像直方图分布,基于Retinex 理论的方法),作者认为这些传统方法要么是随机地改变图像的直方图分布,要么依赖于一些可能不正确的物理模型(真敢怼啊…),而本文提出的方法是通过image-specific曲线映射进行增强。这种策略可以增强图像,并且不会出现unrealistic artifacts。
同时,作者还与同样使用曲线映射的方法(Lu Yuan and Jian Sun - Automatic exposure correction of consumer photographs)进行了对比:本文提出的方法是data-driven,并设计了non-reference损失函数,这样会得到更好的鲁棒性,更广的动态调整范围以及更低的计算负担。
Data-Driven Methods
数据驱动的方法可以被分为两个分支,CNN-based和GAN-based。
1)CNN-based:绝大多数的CNN-based方法都需要paired data(low/normal light image)来进行监督训练。这些paired data通常通过在相机采集图片时改变相机的设置,或者使用图像修饰来进行仍合成。可想而知,这些基于paired data的方法通常是high cost(数据收集),并且数据集还存在一些虚假/不真实的图片(人工合成),这样会影响到模型的泛化能力(当模型应用在真实世界的不同光照下,通常会出现色偏等现象)。
2)GAN-based: unsupervised GAN-based方法可以避免在训练过程中使用paired data,例如EnlightenGAN(之前的SOTA,最好的GAN-based方法)使用了unpaired data来进行图像增强,然而这些unpaired data通常也需要精心挑选。
本文提出的Zero-DCE相比于上面的data-driven方法有三个优点:
- 探索了一种全新的学习策略(zero reference),消除了对paired/unpaired data的需求;
- 设置non-reference损失函数来对输出图像进行间接的评估;
- 提出的方法是high efficient和cost efficient的.
作者将以上三个优点归功于:zero reference learning framework + lightweight network structure + effective non-reference loss functions.
3. Methodology
Zero-DCE的框架如下图所示,它被用来学习一组best-fitting的增强曲线,框架迭代应用Curve,对输入图像的RGB通道中所有像素进行映射,从而获得最后的增强图像。

3.1 Light-Enhancement Curve (LE-Curve)
受到图像编辑软件的"Curves Adjustment"的启发,作者尝试设计一类能够将low-light图像自动映射到增强图像的曲线,曲线参数是self-adaptive的,并仅取决于输入图像。设计这样的曲线有三个要求:
- 增强图像的像素值归一化为[0,1],这避免了由于overflow truncation而导致的信息丢失;
- 设计的曲线应该是单调的,从而保留相邻像素间的差异(对比度);
- 曲线应该尽可能地简单,使得其在梯度反向传播过程中是可导的。
为了达到上述的三个要求,作者设计了一个二次曲线:
![]()
其中,x为像素坐标,LE(I(x); α)为输入图像I(x)的增强结果,α∈[-1,1]为可训练的曲线参数(修改曲线的大小并控制曝光度)。每个像素都归一化为[0,1],并且所有操作都是pixel-wise。使用时,在输入的RGB通道分别应用LE-Curve,这可以更好地保持固有颜色以及避免过拟合。
在不同的α参数设置下,图像如上图(b)所示,可以看到设计的曲线可以很好地满足上述的三个要求。此外,LE-Curve还能增加/减少输入图像的动态范围,这样不仅可以增强low-light区域,还可以避免过度曝光。
Higher-Order Curve:
通过迭代上式(1)定义的LE-Curve,可以使得调整变得更灵活,从而使得模型能够适应于各种challenging的弱光条件下:

其中,n为迭代的次数(控制曲率,本文将n设置为8,这可满足大多数情况),当n为1时,式(2)就退化为了(1)。上图©中提供了high-order Curve的示例,可以看到,相比于(b)中的图像,其具有更强大的调节能力(更大的曲率)。
Pixel-Wise Curve:
上面提到的高阶曲线可以在更宽的动态范围内调整图像,但由于α应用于所有的像素,所以仍为global adjustment。这种global mapping会导致over-/under- enhance局部区域,为了解决这个问题,作者重新定义α为一个pixel-wise参数(即.输入图像的每个像素都有其对应的曲线):

其中,Α为parameter map(与输入图像维度一致),作者假设局部区域内的像素都具有相同的强度(也具有相同的调整曲线,α一致),因此输出结果中相邻像素仍保持单调关系,所以pixel-wise的高阶曲线(式3)也满足设计的3个要求。

上图为三个通道的estimated curve parameter map的示例,可以看到不同通道的best-fitting parameter maps具有相似的调整趋势,但值不同,说其可以代表low-light图像三通道之间的相关性和差异性。曲线的parameter map能够准确地表示不同区域的亮度情况(例如墙上的两个亮点),因此可以直接通过pixel-wise curve mapping进行图像增强,如(e)所示,明亮区域保留,黑暗区域增强。
3.2 DCE-Net
为了学习到输入图像与上述best-fitting curve parameter map之间的映射关系,作者使用了Deep Curve Estimation Network (DCE-Net),输入为low-light图像,输出为一组用于高阶曲线的pixel-wise curve parameter maps。本文构建的CNN由7个具有对称结构的卷积层组成(类似于U-Net),前6层的卷积核为(3x3x32,stride=1)然后接一个ReLU激活,抛弃了down-sampling和bn层(作者认为这会破坏领域像素间的关系),最后一层卷积通道为24(用于8个迭代轮次的parameter maps),接一个Tanh激活函数。
整个网络的参数量为79,416,Flops为5.21G(input 为256x256x3),很轻量。
3.3 Non-Reference Loss Functions
为了使得模型的训练过程是Zero-reference的,作者提出了一系列non-reference loss用于评估增强图像的质量。
Spatial Consistency Loss:
Lspa 能够维持输入图像与其增强版本之间的邻域差异(对比度),从而促进增强后图像仍能保持空间一致性。

其中,K为局部区域的数量,Ω(i)是以区域i为中心的四个相邻区域(top, down, left, right),Y和I分别为增强图像和输入图像的局部区域平均强度值。这个局部区域的Size经验性地设置为4x4,如果为其他Size,loss将会变得稳定下来。
Exposure Control Loss:
为了控制under-/over-曝光的区域,设计了Lexp 来控制曝光程度,其可以衡量局部区域的平均强度与well-exposedness Level E之间的差距。作者遵循现有作法,将E设为RGB颜色空间中的gray leavel,本文实验中设为0.6(并且作者提到E在[0.4,0.7]之间基本无性能差异)。
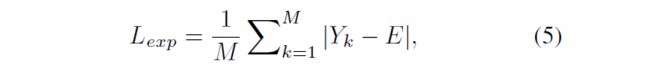
其中,M为不重叠的局部区域数量,区域Size为16x16,Y为增强图像中局部区域的平均像素强度值。
Color Constancy Loss:
根据Gray-World颜色恒等假设(关于Gray-World可以参照这篇博客:https://zhuanlan.zhihu.com/p/84783847),设计了Lcol 用于纠正增强图像中的潜在色偏,同时也建立了三个调整通道之间的关系。

其中,Jp 代表增强图像通道p的平均强度,(p, q)代表一对通道。
Illumination Smoothness Loss:
为了保持相邻像素间的单调关系,在每个curve parameter map A上增加了平滑度损失。
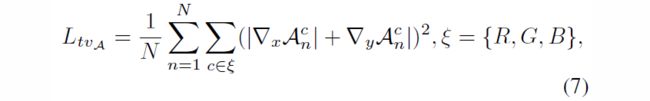
其中,N为迭代次数,▽x,▽y 分别代表水平和垂直方向的梯度操作。
Total Loss:
![]()
其中Wcol,WtvA 为Loss的权重(源码中Exposure control loss前也有权重)
4. Experiment
为了充分发挥Zero-DCE的宽动态范围调整能力,训练集合并了low-light和over-exposed图像(Part 1 of SICE数据集,3022张不同曝光程度的图像,其中2422张图片用于训练),图像尺寸为512x512。
batch size为8,单卡2080Ti,使用(0, 0.02)高斯函数初始化权重,bias初始为常量,使用ADAM优化器(lr=1e-4),Wcol 为0.5,WtvA 为20,从而平衡loss间尺度差距。
4.1 Ablation Study
Contribution of Each Loss:

从上图可以看出,移除Lspa 会导致对比度降低(例如云的区域);移除Lexp 会导致低亮度区域曝光不足;移除Lcol 会出现严重的色偏现象;移除LtvA 会降低邻域间的相关性,从而导致明显的artifacts。
Effect of Parameter Setting:

参数方面主要探讨Zero-DCE的深度宽度以及迭代的次数。如上图所示,L-F-N代表Zero-DCE有L层卷积,每层有F个feature map以及迭代次数为N。
Impact of Training Data:

使用不同数据集对Zero-DCE进行训练:1)原训练集中(2422)的900张low-light图像Zero-DCELow ;2)DARK FACE中9000张未标注的low-light图像Zero-DCELargeL ;3)SICE数据集Part 1 and Part2组合的4800张多重曝光图像Zero-DCELargeLH
从©(d)中可以看出,移除曝光数据后,Zero-DCE都会过度曝光那些well-lit区域(例如脸部);从(e)中可以看出,使用更多的多重曝光的训练数据,Zero-DCE对黑暗区域的恢复效果会更好。
4.2 Benchmark Evaluations
在多个数据集(NPE LIME MEF DICM VV以及SICE的Part2)上与目前SOAT的方法进行了对比。
4.2.1 Visual and Perceptual Comparison
上图为不同方法的可视化比较,除此之外,作者还行进行User Study以量化不同方法的主观视觉质量。
User Study:提供输入图像作为参考,邀请15人对这些增强图像的视觉质量进行独立评估,标准为——a) 是否存在over-/under-exposed artifacts和over-/under- enhanced区域;b) 是否存在色偏;c) 是否存在不自然的纹理以及噪声,评分范围为1-5,越高越好。
Perceptual Index:除了使用US score,还应用perceptual Index来评估感知质量,越低越好。
最后US和PI的结果如下表所示,左列为US,右列为PI。

4.2.2 Quantitative Comparison

除此之外,作者还对比了不同方法的计算速度(简单点说就是又快又好)。

4.2.3 Face Detection in the Dark
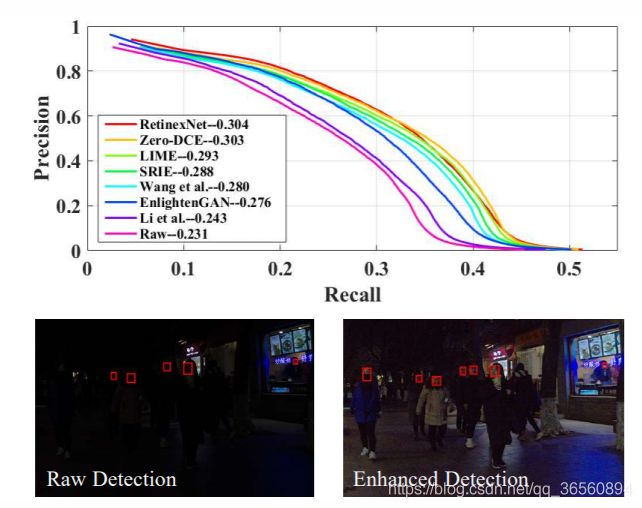
同时,作者还在基于DARK FACE数据集的人脸检测任务上应用了Zero-DCE,可以看到效果还是提升了不少。
回顾(Review)
Zero-DCE发表于CVPR2020,如同其在文章中所说,在多个数据集基准上均为SOTA,排名第一。博主也是第一次接触Low-Light Enhancement这个领域,整篇文章读下来,给人的感觉就是idea简明,效果很好,并且为Zero-Reference类似于自监督的思想,Curve所用参数都由神经网络给出,与且仅与输入图像有关。
看了一些其他博客关于这篇文章的讨论,还是有很多值得深思的地方,比如本文未考虑噪声情况(这里作者也提到未来会考虑噪声影响)。但目前与其他方法比对起来,效果还是不错的,并且速度是真的快、模型也lightweight,而且训练时间也短,作者说只需要30min,这个优势还是很明显的。
代码
整篇文章的代码比较简单,这里先贴上原作者的Code(点我),届时我在放上自己的复现代码。
以上为个人的浅见,水平有限,如有不对,望大佬们指点。
未经本人同意,请勿转载,谢谢。