MySQL快速上手[学习笔记](三)
前言:
课程:《三大主流数据库快速上手》(点击跳转官方课程,b站有资源,可自搜)
笔记(点击跳转豆丁网)
此处是个人学习笔记,用作回顾用途
目录:
七、函数
八、视图
九、触发器
十、存储过程
七、函数
1.数学函数
| 函数 | 作用 |
| ABS(x) | 返回 x 的绝对值 |
| CEIL(x),CEILING(x) | 返回大于或等于 x 的最小整数 |
| FLOOR | 返回小于或等于 x 的最大整数 |
| RAND() | 返回 0~1 的随机数 |
| RAND(X) | 返回 0~1 的随机数,x 值相同时返回的随机数相同 |
| SIGN(X) | 返回 x 的符号。x 是负数、0、正数分别返回-1,0 和 1 |
| PI() | 返回圆周率(3.141593 |
| TRUNCATE(x,y) | 返回数值 x 保留到小数点后 y 位的值 |
| ROUND(x) | 返回离 x 最近的整数 |
| ROUND(x,y) | 保留 x 小数点后 y 位的值,但截断时要进行四舍五入 |
| POW(x,y),POWER(x,y) | 返回 x 的 y 次方(x^y) |
| SQRT(x) | 返回 x 的平方根 |
| EXP(x) | 返回 e 的 x 次方(e^x) |
| MOD(x,y) | 返回 x 除以 y 的余数 |
| LOG(x) | 返回自然对数(以 e 为底的对数) |
| LOG10(x) | 返回以 10 为底的对数 |
| RADIANS(x) | 将角度转换成弧度 |
| DEGREES(x) | 将弧度转换成角度 |
| SIN(x) | 求正弦值 |
| ASIN(x) | 求反正弦值 |
| COS(x) | 求余弦值 |
| ACOS(x) | 求反余弦值 |
| TAN(x) | 求正切值 |
| ATAN(x),ATAN2(x,y) | 求反正切值 |
| COT(x) | 求余切值 |
select ABS(1),ABS(-1),PI();
select sqrt(16),mod(3,2);
select ceil(8.9),floor(8.9);
2.字符串函数
| 函数 | 作用 |
| CHAR_LENGTH(s) | 返回字符串 s 的字符数 |
| LENGTH(s) | 返回字符串 s 的长度 |
| CONCAT(s1,s2,...) | 将字符串 s1,s2 等多个字符串合并为一个字符串 |
| CONCAT_WS(x,s1,s2,...) | 同上,但是每个字符串直接要加上 x |
| INSERT(s1,x,len,s2) | 将字符串 s2 替换 s1 的 x 位置开始长度为 len 的字符串 |
| UPPER(s),UCASE(s) | 将字符串 s 的所字母都变成大写字母 |
| LOWER(s),LCASE(s) | 将字符串 s 的所字母都变成小写字母 |
| LEFT(s,n) | 返回字符串 s 的前 n 个字符 |
| RIGHT(s,n) | 返回字符串 s 的后 n 个字符 |
| LPAD(s1,len,s2) | 字符串 s2 来填充 s1 的开始处,使字符串长度达到 len |
| RPAD(s1,len,s2) | 字符串 s2 来填充 s1 的结尾处,使字符串长度达到 len |
| LTRIM(s) | 去掉字符串 s 开始处的空格 |
| RTRIM(s) | 去掉字符串 s 结尾处的空格 |
| TRIM(s) | 去掉字符串 s 开始和结尾处的空格 |
| TRIM(s1 from s) | 去掉字符串 s 中开始和结尾处的字符串 s1 |
| REPEAT(s,n) | 将字符串 s 重复 n 次 |
| SPACE(n) | 返回 n 个空格 |
| REPLACE(s,s1,s2) | 用字符串 s2 替代字符串 s 中的字符串 s1 |
| STRCMP(s1,s2) | 比较字符串 s1 和 s2 |
| SUBSTRING(s,n,len),MID(s,n,len) | 获取字符串 s 中的 n 个位置开始长度为 len 的字符串 |
| LOCATE(s1,s),POSITION(s1 IN s),INSTR(s,s1); | 从字符串 s 中获取 s1 的开始位置 |
| REVERSE(s) | 将字符串 s 的顺序反过来 |
| ELT(n,s1,s2,...) | 返回第 n 个字符串 |
#concat
select concat('sha','ng','hai'),concat_ws('-','sha','ng','hai');
#insert
select insert('shanghai',6,3,'main');
#upper&lower
select upper('mysql'),lower('MYSQL');
#reverse
select reverse('abcdefg');
3.日期函数
| 函数 | 作用 |
| CURDATE(),CURRENT_DATE() | 返回当前日期 |
| CURTIME(),CURRENT_TIME() | |
| 返回当前时间 | NOW(),CURRENT_TIMESTAMP(),LOC ALTIME(),SYSDATE(),LOCALTIMEST |
| AMP() | 返回当前时间和日期 |
| UNIX_TIMESTAMP() | 以 UNIX 时间戳的形式返回当前时间 |
| UNIX_TIMESTAMP(d) | 将时间 d 以 UNIX 时间戳的形式返回 |
| FROM-UNIXTIME(d) | 把 UNIX 时间戳的时间转换为普通格式的时间 |
| UTC_DATE() | 返回 UTC(Universal Coordinated Time)日期 |
| UTC_TIME() | 返回 UTC 时间 |
| MONTH(d) | 返回日期 d 中的月份值,范围是 1~12 |
| MONTHNAME(d) | 返回日期 d 中的月份名称,如 February |
| DAYNAME(d) | 返回日期 d 是星期几,若 Monday |
| DAYOFWEEK(d) | 返回日期 d 是星期几,1 表示星期日 |
| WEEKDAY(d) | 返回日期 d 是星期几,0 表示星期一 |
| WEEK(d) | 计算日期 d 是本年的第几个星期,范围是 0~53 |
| WEEKOFYEAR(d) | 计算日期 d 是本年的第几个星期,范围是 1~53 |
| DAYOFYEAR(d) | 计算日期 d 是本年的第几天 |
| DAYOFMONTH(d) | 计算日期 d 是本月的第几天 |
| YEAR(d) | 返回日期 d 中的年份值 |
| QUARTER(d) | 返回日期 d 是第几季度,范围是 1~4 |
| HOUR(t) | 返回时间 t 中的小时值 |
| MINUTE(t) | 返回时间 t 中的分钟值 |
| SECOND(t) | 返回日期 t 中的秒钟值 |
| EXTRACT(type FROM d) | 从日期d 中获取指定的值,type 指定返回的值,如 YEAR |
| TIME_TO_SEC(t) | 将时间转换成秒 |
| SEC_TO_TIME(s) | 将秒为单位的时间 s 转换成时分秒的格式 |
| TO_DAYS(d) | 计算日期 d~0000 年 1 月 1 日的天数 |
| FROM_DAYS(n) | 计算从 0000 年 1 月 1 日开始 n 天后的日期 |
| DATEDIFF(d1,d2) | 计算日期 d1~d2 之间相隔的天数 |
| ADDDATE(d,n) | 计算起始日期 d 加上 n 天的日期 |
| ADDDATE(d,INTERVAL expr type) | 计算起始日期 d 加上一个时间段后的日期 |
| DATE_ADD(d,INTERVAL expr type) | 同上 |
| SUBDATE(d,n) | 计算起始日期 d 减去 n 天的日期 |
| SUBDATE(d,INTERVAL expr type) | 计算起始日期 d 减去一个时间段后的日期 |
| ADDTIME(t,n) | 计算起始时间 t 加上 n 秒的时间 |
| SUBTIME(t,n) | 计算起始时间 t 减去 n 秒的时间 |
| DATE_FORMAT(d,f) | 照表达式 f 的要求显示日期 d |
| TIME_FORMAT(t,f) | 照表达式 f 的要求显示时间 t |
| GET_FORMAT(type,s) | 根据字符串 s 获取 type 类型数据的显示格式 |
select curdate(),current_time(),now();
select month('2020-06-19 09:07:47');
4.条件判断函数
(1)IF(exp,v1,v2)
(2)IFNULL(v1,v2)
(3)CASE
①case when expr1 then v1 [when expr2 then v2]… else vn end(相当于 if)
②case expr1 when e1 then v1 [when e2 then v2]…else vn end(相当于 switch)
5.系统信息函数
| 函数 | 作用 |
| VERSION() | 返回数据库的版本号 |
| CONNECTION_ID() | 返回服务器的连接数 |
| DATABASE(),SCHEMA() | 返回当前数据库名 |
| USER(),SYSTEM_USER(),SESSION_USER() | 返回当前用户 |
| CURRENT_USER(),CURRENT_USER | |
| CHARSET(str) | 返回字符串 str 的字符集 |
| COLLATION(str) | 返回字符串 str 的字符排列方式 |
| LAST_INSERT_ID() | 返回最近生产的 auto_increment 值 |
6.加密函数
(1)PASSWORD(str)
select password('root');
#mysql8.0没有这个函数,使用authentication_string
select user,host,authentication_string from mysql.user;
(2)MD5(str)
select md5('111222333');
(3)ENCODE(str,pwd_str)和DECODE(scty,pwd_str)
select encode('root','r');
#(如果要存储,则需存储的字段类型为 blog)
select decode(encode('root','r')'r');
#(对 encode 加密后的数据进行解密)
mysql8提示找不到encode()/decode()方法,可以尝试更换connnector版本为5.x,或者用md5()等加密函数替代。
原因:mysql8安装时,可选择两套不同的加解密(点击跳转参考链接)
7.其它函数
(1)format(x,n)
对 x 进行格式化,保留 n 位小数
select format(3896.59,3), format(3896.59,1);

(不够补位–0,采取四舍五入方式)
(2)IP 地址和数字互相转化
inet_aton(ip)
inet_ntoa(n)
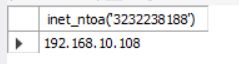
select inet_aton('192.168.10.108');

select inet_ntoa('3232238188');
(3)重复执行指定操作函数 benchmark(n,expr)
执行n次expr并测算时间
select benchmark(100000000,now());
_第1张图片](http://img.e-com-net.com/image/info8/18af892440bc4f378cc79b9e973fcb3d.png)
BENCHMARK()的返回值总是0,但是mysql客户端会打印一行来输出语句的大概执行时间。
八、视图
语法:
create
[algorithm = {undefined | merge | temptable}]
view 视图名 [{属性清单}]
as select 语句
[with [cascaded|local] check option];
algorithm:选择的算法
with check option:表示更新视图时要保证在该视图的权限范围之内
undfined:表示 MySQL 自动选择所需使用的算法
merge:表示将视图的语句与视图的定义合并,使得视图定义的某一部分取代语句的对应部分
temptable:将视图的结果存入临时表
cascaded:表示更新视图时要满足所有相关视图和表的条件
local:表示更新视图时,要满足该视图本身的定义的条件即可
(一)创建视图
1.查看是否有权限创建
select select_priv,create_view_priv from mysql.user where user ='root'
_第2张图片](http://img.e-com-net.com/image/info8/a6f8358239b740f1a3ef25c2ed291fa3.png)
2.创建视图
①在单表中创建视图
create view book_view1 as select * from book;
create view book_view2(name) as select bookname from book;
②在多表中创建视图
create algorithm=merge view
book_view3(bookname,stuname)
as select bookname,stuname
from book as a,stu as b where a.stuid = b.stuid;
(二)查看视图
1.查看视图内容
select * from book_view1;
_第3张图片](http://img.e-com-net.com/image/info8/7897e79cfdf7458ea4d3b7dfe00e60c8.jpg)
2.desc查看视图结构
desc book_view1;
_第4张图片](http://img.e-com-net.com/image/info8/a84cc6951e494eb1a318e8986b4b70d7.png)
3.查看是虚拟表还是实体表
show table status like 'book_view1' \G;
_第5张图片](http://img.e-com-net.com/image/info8/f30536c25ba441cb8a523c33b8ff9357.jpg)
(book_view1 是虚拟表)
show table status like 'book' \G;
_第6张图片](http://img.e-com-net.com/image/info8/39501114e18e45eebf349874deda04b1.jpg)
(book是实体表)
4.在view和views中查看视图
show create view book_view1 \G;

select * from information_schema.views \G;
_第7张图片](http://img.e-com-net.com/image/info8/3512a05e9e4a44b4bae9fc6751874a47.jpg)
(三)修改视图
1.通过 create or replace view 修改
(如果没有则创建,有则修改)
create or replace algorithm=temptable
view book_view1(name)
as select bookname from book;
2、通过 alter 修改
(只能修改不能创建)
alter view book_view2(name)
as select stuname
from stu
with check option;
(四)更新视图(更新视图实际上是更新表)
select * from book;
_第8张图片](http://img.e-com-net.com/image/info8/5711cb8a3e7944a5a0279413dc0905c9.png)
create view book_view4(name)
as select bookname from book where id=1;
select * from book_view4;
_第9张图片](http://img.e-com-net.com/image/info8/6bb642f933c240aca4f6c2e12d4c0960.png)
update book_view4 set name ='python教程';
select * from book_view4;
_第10张图片](http://img.e-com-net.com/image/info8/b60465c68a444a82a0617f0cae71b3f1.jpg)
(五)删除视图
drop view if exists book_view3;
#判断用户是否有删除权限
select drop_priv from mysql.user where user= 'root';
_第11张图片](http://img.e-com-net.com/image/info8/8dabc6e5d37b495b91d9f4d92b39a619.png)
九、触发器
触发器的作用:修改一个表的数据,相关联的表的相应数据也会跟着修改。
官方一点的说法:触发器是一种与表操作有关的数据库对象,当触发器所在表上出现指定事件时,将调用该对象,即表的操作事件触发表上的触发器的执行。
在MySQL中,创建触发器语法如下:(点击跳转参考文章)
CREATE TRIGGER trigger_name trigger_time trigger_event
ON tbl_name FOR EACH ROW trigger_stmt
其中:
trigger_name:标识触发器名称,用户自行指定;
trigger_time:标识触发时机,取值为 BEFORE 或 AFTER;
trigger_event:标识触发事件,取值为 INSERT、UPDATE 或 DELETE;
tbl_name:标识建立触发器的表名,即在哪张表上建立触发器;
trigger_stmt:触发器程序体,可以是一句SQL语句,或者用 BEGIN 和 END 包含的多条语句。
由此可见,可以建立6种触发器,即:BEFORE INSERT、BEFORE UPDATE、BEFORE DELETE、AFTER INSERT、AFTER UPDATE、AFTER 、DELETE。
另外有一个限制是不能同时在一个表上建立2个相同类型的触发器,因此在一个表上最多建立6个触发器。
(一)创建和使用触发器
1、创建单条执行语句的触发器
语法:create trigger 触发器名 before | after 触发事件
on 表名 for each row 执行语句
/*创建account表*/
CREATE TABLE account
(
acct_num INT,
amount DECIMAL(10,2)
);
/*创建myname表*/
CREATE TABLE myname(
id int(11) DEFAULT NULL,
name char(20) DEFAULT NULL
);
要求:在向表account新增数据后,便会触发myname表新增一条记录1 ,‘after insert’
CREATE TRIGGER trig_insert AFTER INSERT ON account
FOR EACH ROW INSERT INTO myname VALUES (1,'after insert');
insert into account values('1','100');
select * from account;
_第12张图片](http://img.e-com-net.com/image/info8/cff1f2476dc04704acb8a3c8fc8f94ba.png)
select * from myname;
_第13张图片](http://img.e-com-net.com/image/info8/301d7f5b58ec4405a70dfcfb5b61cbd0.png)
2、创建多条执行语句的触发器
语法:create trigger 触发器名 before | after 触发事件
on 表 名 for each row begin
执行语句
end
(在执行多条语句时,会以分号结束,为解决问题,delimiter #)
设有4个测试数据表:
CREATE TABLE test1(a1 INT);
CREATE TABLE test2(a2 INT);
CREATE TABLE test3(a3 INT NOT NULL AUTO_INCREMENT PRIMARY KEY);
CREATE TABLE test4(
a4 INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
b4 INT DEFAULT 0
);
要求:创建一个包含多个执行语句的触发器
/*创建触发器*/
DELIMITER //
CREATE TRIGGER testref BEFORE INSERT ON test1
FOR EACH ROW BEGIN
INSERT INTO test2 SET a2 = NEW.a1;
DELETE FROM test3 WHERE a3 = NEW.a1;
UPDATE test4 SET b4 = b4 + 1 WHERE a4 = NEW.a1;
END
//
DELIMITER ;
/*分别向test3和test4表中插入测试数据*/
INSERT INTO test3 (a3)
VALUES (NULL), (NULL), (NULL), (NULL), (NULL),
(NULL), (NULL), (NULL), (NULL), (NULL);
INSERT INTO test4 (a4) VALUES (0), (0), (0), (0), (0), (0), (0), (0), (0), (0);
/*查看触发器未执行前的结果*/
SELECT * FROM test1;
SELECT * FROM test2;
SELECT * FROM test3;
SELECT * FROM test4;
/*向test1表中插入数据,激活触发器的调用事件调用触发器*/
INSERT INTO test1 VALUES (1), (3), (1), (7), (1), (8), (4), (4);
/*查看触发器执行后的结果*/
SELECT * FROM test1;
SELECT * FROM test2;
SELECT * FROM test3;
SELECT * FROM test4;
(二)查看触发器
1.show triggers
_第14张图片](http://img.e-com-net.com/image/info8/802f65a9b3544f84802699777a4ac739.jpg)
2.通过 triggers 表查看
select * from information_schema.triggers \G;
_第15张图片](http://img.e-com-net.com/image/info8/d1d61947047b4529ab78eb78c0fc8526.jpg)
3.查询指定的
select * from information_schema.triggers where trigger_name='trig_insert' \G;
_第16张图片](http://img.e-com-net.com/image/info8/b82d8fbcc9144f458ccc75ca279415d1.jpg)
(三)删除触发器
drop trigger trig_insert;
检查:
select * from information_schema.triggers where trigger_name='trig_insert' \G;

十、存储过程
语法:
create procedure sp_name({proc_parameter[…]})
[characteristic …] routine_body
sp_name:存储过程名称
proc_parameter:存储过程的参数列表
characteristic:存储过程的特性
routine_body:SQL 语句的内容,可以用
begin…end 来标志 SQL 语句的开始和结束
proc_parameter 由 3 部分组成:输入输出类型、参数名和参数类型
形式:[in | out | inout] param_name type
characteristic 取值:
☞language sql:说明 routine_body 是由 SQL 语句组成
☞[not] deterministic:执行结果是否确定
☞{contains sql | no sql | reads sql data | modifies sql data}:
①contains sql:子程序包含 SQL 语句,但不包含读或写数据的 SQL[默认]
②no sql:子程序中不包含 SQL 语句
③reads sql data:包含可读数据的语句
④modifies sql data:包含可写数据语句
☞sql security {definer | invoker}:who 有权限来执行
①definer:只有定义者方可执行[默认]
②invoker:调用者可以执行
☞comment ‘string’:注释信息
(一)创建存储过程(点击跳转参考资料)
①简单的存储过程
语法:
create procedure 存储过程名(参数)
begin
sql 语句…
end;
delimiter //
create procedure p_book()
begin
select * from book;
end;
//
调用存储过程的语法:
call 存储过程名(实参);
call p_book();
_第17张图片](http://img.e-com-net.com/image/info8/c935cb7df8c941e3bc7cc2aef450c971.png)
②带参数的存储过程(in、out 、inout)
in可以省略不写,默认就是in类型
delimiter //
create procedure pro_book(in x int)
begin
select * from book where id=x;
end
//
call pro_book(3);
_第18张图片](http://img.e-com-net.com/image/info8/8b55eb8e8f3c46a5a3f3d0dc88082b5b.png)
调用out存储过程前,需要先定义一个变量:set @变量类名 = 值;
calll 存储过程名(@变量名);
select * from stu;
insert into stu values('12','张三');
delimiter //
create procedure pro_stu(out x int)
begin
select max(stuid) into x from stu where stuname = '张三';
end
//
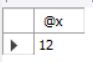
set @x=1;
call pro_stu(@x);
select @x;
delimiter //
create procedure pro__stu(in a varchar(20),out b int)
begin
select max(stuid) into b from stu where stuname = a;
end
//
set @b=1;
call pro__stu('张三',@x)
select @x;
(二)创建存储函数
语法:
create function sp_name([func_parameter[…]])
returns type
[characteristic…] routine_body
sp_name:存储函数名称func_parameter:存储函数参数列表
returns type:指定返回值的类型
func_parameter 由 2 部分组成:参数名和参数类型
形式:param_name type
mysql 创建函数时出现 Error Code : 1418 错误解决办法:(点击挑转参考资料)
SET GLOBAL log_bin_trust_function_creators = 1;
delimiter //
create function name_from_stu(sid int)
returns varchar(20)
begin
return(
select stuname from stu
where stuid = sid);
end //
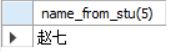
select name_from_stu(5)
(三)变量的使用
注意:在存储过程或存储函数中使用!!!)
1、声明变量:
语法:declare 参数名 [,…] 类型 [default value]
declare mysql int default 100;
2、赋值
语法:set 变量名=值[,变量名=值]
set mysql = 10;
语法:select 字段[,…] into 变量名[,…] from 表名 where 条件
selext age into mysql from employee where e_no= 1001;
(四)流程控制
注意:在存储过程或存储函数中使用!!!)
1、IF 语句语法:
if 条件 then 执行语句
else if 条件 then 执行语句
…
else 执行语句
end if
2、CASE 语句(等值判断) 语法:
①
case 变量
when 变量值 then 执行语句
…
else 执行语句
end case
②
case
when 条件 then 执行语句
…
else 执行语句
end case
3、LOOP 语句
无限循环,直到遇到 leave 才停止
语法:
[循环开始的标识:]loop
执行语句
end loop [循环结束标识]
4、LEAVE 语句例 子
save_num loop
执行语句
条件判断
leave save_num
end loop save_num
5、ITERATE 语句
(只能跳出本次循环)
语法:
iterate label
6、REPEAT 语句
(跳出所有循环)
语法:
开始标志 repeat
条件
结束标志(end repeat)
7、WHILE 语句语法
开始标志 while 条件
执行语句
end while
(五)查看存储过程和存储函数
1、通过 show status 查看存储过程和函数状态
语法:show {procedure | function} status [like ‘pattern’]
show procedure status like 'p_book' \G;
_第19张图片](http://img.e-com-net.com/image/info8/173146d5090d4a02b18cb640da104900.png)
2、通过 show create 查看存储过程和函数定义语法:
show create {procedure | function} sp_name
show create procedure p_book \G;
_第20张图片](http://img.e-com-net.com/image/info8/2427809eb58e477ab60106dd85d04e00.jpg)
3、通过 information_schema.Routines 查看存储过程和函数信息
语法:
select * from information_schema.Routines where routine_name =’sp_name’
(六)删除存储过程和存储函数
语法:drop {procedure | function} sp_name
select * from information_schema.Routines where routine_name='p_book' \G;
_第21张图片](http://img.e-com-net.com/image/info8/aae928061f494b9086e7647478e4e0b1.jpg)