Docker搭建mongodb主从复制集群(nodejs+mongoose)
这里有精心准备的PPT,大家可以先过目一下
PPT链接
为什么需要搭建mongodb集群?
- 数据备份
- 数据恢复
- 读写分离
首先我们先准备一个nodejs实例
以express脚手架为例
http://www.expressjs.com.cn/starter/generator.html
先配置node连接mongodb的配置信息
const mongoose = require('mongoose');
mongoose.connect(
"mongodb://192.168.77.137:27017,192.168.77.137:27018/test?replicaSet=rs", //连接多个数据库用来配合主从集群
{
useNewUrlParser: true,
poolSize: 5,
readPreference: "secondary" //集群配置
});
//判断连接是否生效
const conn = mongoose.connection;
conn.on("open", () => {
console.log('mongodb连接成功');
})
conn.on("error", () => {
console.log('mongodb连接失败');
});
骨架和路由的配置
const express = require('express');
const router = express.Router();
const mongoose = require("mongoose");
const user = mongoose.model('user', mongoose.Schema({
username: { type: String },
password: { type: String },
user_ssh: { type: String }
}, { collection: "user", versionKey: false, strict: true }));
/* GET home page. */
router.get('/', function (req, res, next) {
res.render('index', { title: 'Express' });
});
router.get('/test', async function (req, res, next) {
const data = await user.find({username:"zzw"});
res.send(data);
});
router.get('/add', async function (req, res, next) {
const data = await user.create({username:"zzw"});
res.send(data);
});
router.get('/err', function (req, res, next) {
process.exit();
});
module.exports = router;
更多配置请看这里
primary //默认模式,所有的读操作都从当前副本集主节点
primaryPreferred //多数情况下,从主节点读取数据,但是如果主节点不可用了,会从从节点读取
secondary //所有读操作都从副本集的从节点读取
secondaryPreferred //多数情况下, 从从节点进行读操作,但是如果从节点都不可用了,从主节点读取
nearest //从副本集中延迟最低的成员读取,不考虑成员的类型
然后我们可以开始配置mongodb集群了
保证您的机器已经安装了docker
https://www.docker.com/
安装mongodb
1. docker search mongo //搜索所有mongo镜像
2. docker pull mongo //拉取官方镜像
3. docker imsages //查看所有镜像
4. docker run -p 27017:27017 -v $PWD -d mongo //$pwd选择当前目录为mongodb工作目录,也可以自己指定
5. docker ps -a //查看mmongo工作状态
为了方便演示,我们采用一主一从的方式
因为是一主一从,所以我们启动两个mongodb的docker容器,如果您搭建一主多从,则多启动几个容器即可
docker run -d -p 27017:27017 --name="mongo_master" -v $PWD mongo --noprealloc --smallfiles --replSet rs
docker run -d -p 27018:27017 --name="mongo_slave" -v $PWD mongo --noprealloc --smallfiles --replSet rs
//$pwd指定当前目录为mongodb的工作目录
//noprealloc
默认false:使用预分配方式来保证写入性能的稳定,预分配在后台进行,并且每个预分配的文件都用0进行填充。这会让MongoDB始终保持额外的空间和空余的数据文件,从而避免了数据增长过快而带来的分配磁盘空间引起的阻塞。
设置noprealloc= true来禁用预分配的数据文件,会缩短启动时间,但在正常操作过程中,可能会导致性能显著下降
//smallfiles
smallfiles:是否使用较小的默认文件。默认为false,不使用。
设置为true,使用较小的默认数据文件大小。smallfiles减少数据文件的初始大小,并限制他们到512M,也减少了日志文件的大小,并限制他们到128M。
如果数据库很大,各持有少量的数据,会导致mongodb创建很多文件,会影响性能
//replSet
使用此设置来配置复制副本集。指定一个副本集名称作为参数,所有主机都必须有相同的名称作为同一个副本集。
更详细的mongodb.conf配置文件解析链接
https://my.oschina.net/pwd/blog/399374
现在我们已经启动了两个mongodb容器了
![]()
接下来就需要配置mongodb的集群文件了
//以刚运行的27017端口的mongodb数据库为主节点进入数据库
//一次执行一下命令
mongo --port 27017 //连接数据库
myconf = {"_id":"rs","members":[{"_id":0,"host":"192.168.77.111:27017"},{"_id":1,"host":"192.168.77.137:27018"}]} //配置mongodb集群文件
rs.initiate(myconf) //初始化配置文件
此时我们的mongodb配置文件已经初始化完毕
rs.isMaster(); //查看主节点配置信息
rs.slaveOk(); //设置为从节点
rs.status(); //查看状态
rs.conf(); //查看配置
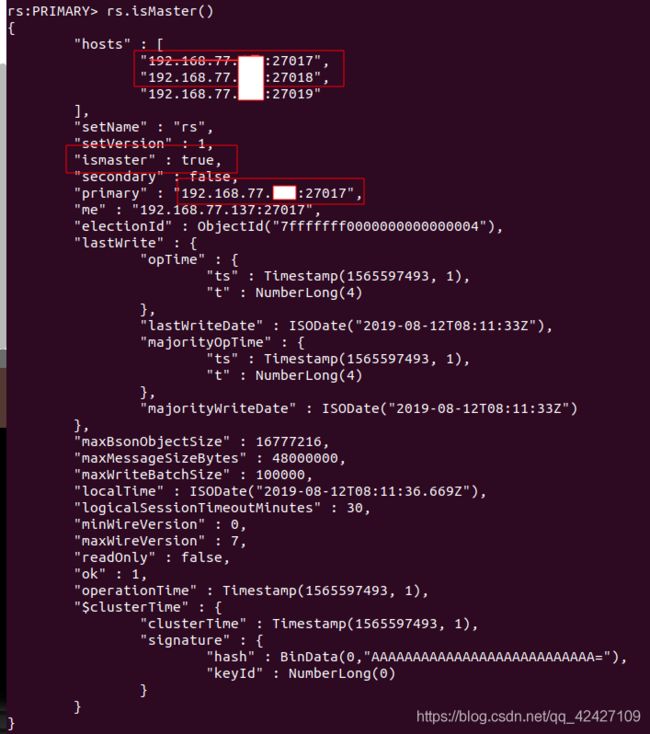
现在我们的主从复制集群已经搭建完毕了,我们可以在主节点添加数据同步至从节点,也可以根据mongoose配置的策略进行从节点的读取
如何查看读取了哪一个从节点?
先进入端口为27017和27018的数据库
db.getProfilingStatus()
日志等级查看
db.setProfilingLevel(level)
level:
0: 关闭
1: 记录慢查询
2: 记录所有操作
为了测试,我们先讲等级设置为1,记录所有操作
db.system.profile.find() //查询所有操作记录
27017下可以看到插入记录

27018下可以看到查询记录
![]()
ts://命令执行时间
info://命令的内容
query://代表查询
order.order: //代表查询的库与集合
reslen://返回的结果集大小,byte数
nscanned://扫描记录数量
nquery://后面是查询条件
nreturned://返回记录数及用时
millis://所花时间
重新指定主节点
rs.conf();
cfg=rs.conf();
cfg.members[0].priority=1
cfg.members[1].priority=1
cfg.members[2].priority=10
rs.reconfig(cfg);
同样的我们也可以在local数据集下oplog.rs集合中查看所有的增删改操作记录,也正是这个文件保证了主从数据的一致性
参考链接:
https://blog.csdn.net/adparking/article/details/41823393 //数据监控
https://blog.csdn.net/jhc23/article/details/81099281 //日志监控
https://my.oschina.net/pwd/blog/399374 //mongodb配置文件解析
https://www.cnblogs.com/jinjiangongzuoshi/p/9301062.html //主从搭建步骤
https://www.cnblogs.com/Joans/p/7723554.html //oplog.rs集合解析
https://blog.csdn.net/ochangwen/article/details/52400958 //集群监控