飞桨paddlepaddle论文复现——BigGAN论文翻译解读
飞桨paddlepaddle论文复现——BigGAN论文翻译解读
- 摘要
- 介绍
- GAN回顾
- 原始GAN
- DCGAN
- WGAN
- BigGAN
- scaling
- Hierarchical latent spaces分层潜在空间
- 截断技巧
- Orthogonal Regularization正交正则化
- 分析
- 表征不稳定性:生成器
- 表征不稳定性:判别器
- 总结
- 代码
- 致谢
- 未完待续
论文地址:LARGE SCALE GAN TRAINING FOR HIGH FIDELITY NATURAL IMAGE SYNTHESIS
github地址:https://github.com/sxhxliang/BigGAN-pytorch
飞桨论文复现课程:https://aistudio.baidu.com/aistudio/education/group/info/1340
飞桨官网:https://www.paddlepaddle.org.cn/
摘要
尽管最近在生成图像建模方面取得了进展,但是从像ImageNet这样的复杂数据集中成功生成高分辨率,多样化的样本仍然是一个难以实现的目标。 为此,我们以最大规模培训了生成对抗网络,并研究了这种规模所特有的不稳定性。 我们发现将正交正则化应用于生成器使得它适用于简单的“截断技巧”,允许通过截断潜在空间来精确控制样本保真度和变化之间的权衡。我们的修改导致模型在类别条件下的图像合成中达到了新的技术水平。 当我们使用128×128分辨率在ImageNet上进行训练时,我们的模型(BigGAN)的Inception Score(IS)为166.3,Fréchet Inception Distance(FID)为9.6,相比之前的最佳IS为52.52,FID为18.65。
介绍

近年来,生成图像建模的状态发展迅速,生成对抗网络处于使用直接从数据中学习的模型生成高保真、多样化图像的最前沿架构。 GANs训练是动态的,并且几乎对其设置的每个方面都很敏感(从优化参数到模型架构),不过大量的研究已经在经验和理论上都给出了证实,表明GANs可以在各种环境中进行稳定的训练。 尽管取得了这些进展,但是在条件ImageNet下建模的现有实际技术水平只达到了52.5的IS,而真实数据的IS值则为233。
在这项工作中,我们着手缩小GAN生成的图像与ImageNet数据集中的真实图像之间的保真度和变化差距。 我们为此目标做出以下三个贡献:
- 我们证明了GAN从缩放中获益匪浅,并且与现有技术相比,训练模型的参数为2到4倍,batch大小达到8倍。 我们介绍了两种简单的通用体系结构更改,可以提高可伸缩性,并修改正则化方案不断调节,从而显著提升性能。
- 作为我们修改的副作用,我们的模型变得适合“截断技巧”,这是一种简单的采样技术,可以对样本种类和保真度之间的权衡进行明确、细粒度的控制。
- 我们发现特定于大规模GAN的不稳定性,并根据经验表征它们。 利用此分析的见解,我们证明新颖技术和现有技术的结合可以减少这些不稳定性,但完全的训练稳定性只能以极高的性能成本实现。
我们的修改大大改善了类别条件下的GAN。 当我们在128×128分辨率下对ImageNet进行训练时,我们的模型(BigGAN)将最先进的IS和FID分别从52.52和18.65提高到166.3和9.6。 我们还成功地在ImageNet上以256×256和512×512分辨率训练BigGAN,并且在256×256处实现了TS和FID 为233.0和9.3以及在512×512处的IS和FID为241.4和10.9。最后,我们在更大的数据集上训练我们的模型 - JFT-300M - 并证明我们的设计选择在ImageNet传输良好。
GAN回顾
原始GAN
GAN目标函数(损失函数)公式: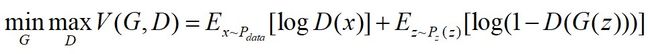
工作过程:
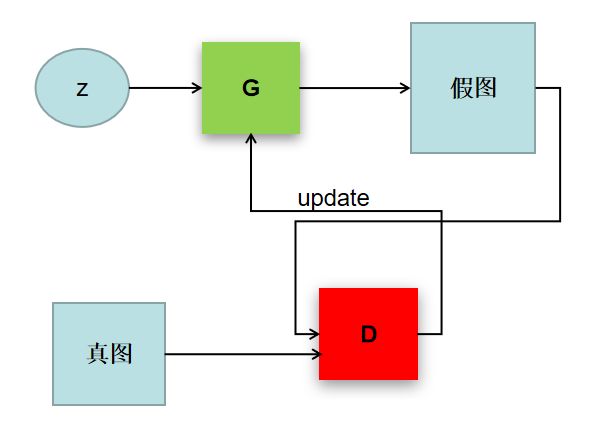
首先生成器产生一组数据,生成完数据之后将其固定住,将生成的数据与真实的数据一起送进判别器,训练判别器,直到判别器能将这两组数据准确区分开为止,此时固定住判别器,接下来训练生成器,生成器不断产生数据(也叫做假数据),直到判别器不能区分两组数据为止(判别器将假数据判别成真数据),如此往复,直到判别器再也不能区分由生成器生成的假数据和给定的真数据的区别为止(或者到达给定的迭代次数)。
推导过程可以参考:GAN的原理及推导 - 向前奔跑的少年 - 博客园
DCGAN
DCGAN的网络结构:
DCGAN 的判别器和生成器都使用了卷积神经网络(CNN)来替代GAN 中的多层感知机,同时为了使整个网络可微,拿掉了CNN 中的池化层,另外将全连接层以全局池化层替代以减轻计算量。
如上图,生成器G 将一个100 维的噪音向量扩展成64 * 64 * 3 的矩阵输出,整个过程采用的是微步卷积的方式。微步卷积是属于反卷积(去卷积,Deconvolution)的一种。
在DCGAN中我们需要用到卷积和反卷积:
卷积:
卷积有三种模式,分别是full、same、valid
从filter和image刚相交开始做卷积,白色部分为填0。(橙色部分为image, 蓝色部分为filter)
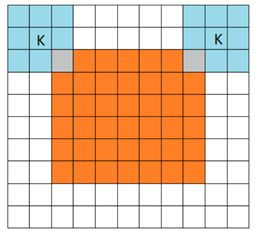

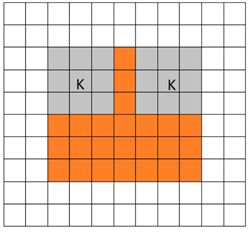

反卷积:
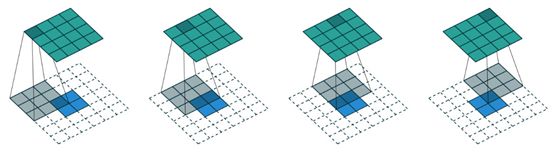

WGAN
WGAN推荐参考这篇博文:GAN的原理及推导 - 向前奔跑的少年 - 博客园
BigGAN

表1:我们提出的修改的模型下的Fréchet Inception Distance(FID,越低越好)和Inception Score(IS,越高越好)。 Batch是批量大小,Param是参数总数,Ch. 是每层中单元数的通道乘数,Shared表示是否使用共享嵌入,Hier.是否使用分层潜在空间,Ortho.是否正交正则化,Itr如果值为1000,则表示该设置对 1 0 6 10^6 106次迭代是稳定的,否则表示在该迭代次数下它就崩溃了。 除了行1-4之外,还计算了8个不同随机初始化的结果。
我们首先增加基线模型的批量大小,并立即发现这样做的巨大好处。表1的第1-4行表明,简单地将批量大小增加8倍,使现有技术IS提高了46%。我们推测这是每批次覆盖更多模式的结果,为两个网络提供更好的梯度。这种缩放的一个值得注意的副作用是我们的模型在更少的迭代中达到更好的最终性能,但变得不稳定并且经历完全的训练崩溃。我们将在第4节中讨论其原因和后果。对于这些实验,我们在崩溃后立即停止训练,并报告之前保存的检查点的分数。
然后,我们将每层中的宽度(通道数)增加50%,大约两倍于两个模型中的参数数量。这导致IS进一步提高21%,我们认为这是由于模型的容量相对于数据集的复杂性而增加。加倍深度似乎不会对ImageNet模型产生相同的影响,反而会降低性能。
scaling
在Batch size增大到原来 8 倍的时候,生成性能上的IS提高了 46%。文章推测这可能是每批次覆盖更多模式的结果,为生成和判别两个网络提供更好的梯度。增大Batch size还会带来在更少的时间训练出更好性能的模型,但增大Batch size也会使得模型在训练上稳定性下降。
batchsize是现有方法8倍,每个batch覆盖更多的mode,为网络提供更好的梯度,卷积网络用的信道数是现有方法的2-4倍,对复杂数据增加了模型的容量,增加宽度,后面提出的biggan-depp 增加了深度,用了残差+瓶颈网络,提高了评分,更快的收敛。但是副作用是训练不稳定,容易崩,同时在网络中,还使用了一层自注意力,每层都是用SN谱归一化。
Hierarchical latent spaces分层潜在空间
不止首次输入噪声Z,在中间的每个残差块都输入Z,生成128pixel 图片为例,每个残差块对应一个Z块,初始的全连接输入也需要一个。总共需要6个,z_dim=120, 也就是每次输入的z的维度是20。
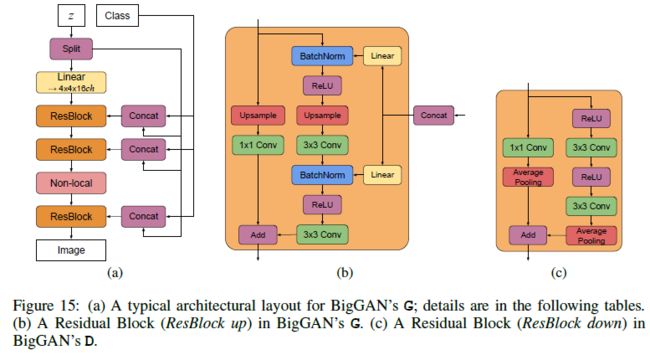
BigGAN在先验分布 z 的嵌入上做了改进,普遍的GAN都是将z作为输入直接嵌入生成网络,而 BigGAN 将噪声向量z送到G的多个层而不仅仅是初始层。
如下图,将噪声向量z通过split等分成多块,然后和条件标签c连接后一起送入到生成网络的各个层中,对于生成网络的每一个残差块又可以进一步展开为右图的结构。可以看到噪声向量z的块和条件标签c在残差块下是通过concat操作后送入BatchNorm层,其中这种嵌入是共享嵌入,线性投影到每个层的bias和weight。
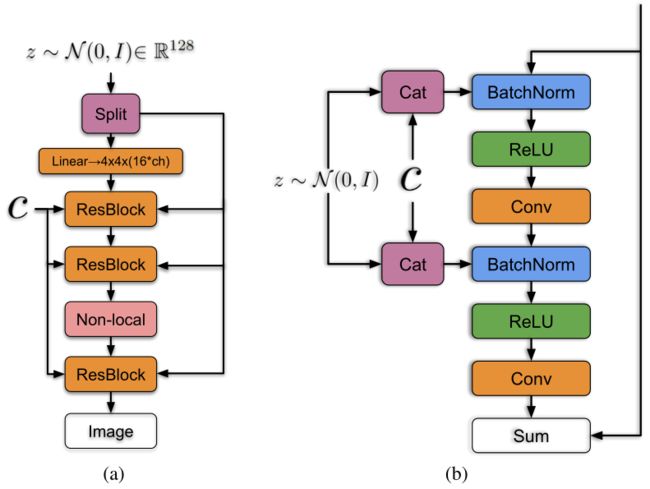
还在网络中加入了class-conditional-batchnorm
截断技巧
训练的时候用Z~N(0,1)。测试采样的时候,z用截断,就是超过一定范围的时候数,不要,重新来,直到在范围内。

Orthogonal Regularization正交正则化
对于许多模型而言,由不同采样引起的分布,相比在训练中看到的会不一样,很容易造成一些麻烦。我们的一些较大模型不适合截断,在馈送截断噪声时会产生饱和伪影(图4(b))。为了抵消这种情况,我们试图通过将G调节为平滑来强制实现截断的适应性,以便z的整个空间映射到良好的输出样本。为此,我们转向正交正则化,它直接强制正交性条件:
R β ( W ) = β ∣ ∣ W T W − I ∣ ∣ F 2 R_β(W) = β||W^TW - I||^2_F Rβ(W)=β∣∣WTW−I∣∣F2
其中W是权重矩阵和β是超参数。 众所周知,这种正则化往往过于局限,因此我们探索了几种旨在放松约束的变体,同时为我们的模型赋予了理想的光滑度。 我们发现最好的版本从正则化中删除了对角项,并且目标是最小化滤波器之间的成对余弦相似性,但不限制它们的范数:
R β ( W ) = β ∣ ∣ W T W ⨀ ( 1 − I ) ∣ ∣ F 2 R_β(W) = β||W^TW {\bigodot} (1- I)||^2_F Rβ(W)=β∣∣WTW⨀(1−I)∣∣F2
其中1表示一个矩阵,其中所有元素都设置为1。我们扫描β值并选择为 1 0 − 4 10^{-4} 10−4,从而找到足够小的额外正则化,以提高我们的模型易于截断的可能性。 在表中,我们观察到没有正交正则化时,只有16%的模型适合截断,而有正交正则化训练时则有60%。
分析

图5,光谱归一化之前G(a)和D(b)层中第一个奇异值 σ 0 σ_0 σ0的典型图。 G中的大多数层都具有良好的光谱,但是没有约束,一个小的子集在整个训练过程中会增长并在崩溃时爆炸。 D的光谱噪声较大,但表现更好。 从红色到紫色的颜色表示增加深度。
表征不稳定性:生成器
我们在训练期间监测一系列权重,梯度和损失统计数据,以寻找可能预示训练崩溃开始的指标,我们发现每个权重矩阵中的前三个奇异值 σ 0 σ_0 σ0, σ 1 σ_1 σ1, σ 2 σ_2 σ2是最有用的,大多数G层具有良好的光谱范式,但有些层(通常是G中的第一层,过于完整且非卷积)表现不佳,光谱范式在整个训练过程中增长,在崩溃时爆炸。
为了确定这种症状是否是塌陷造成的或者仅仅是一种症状,我们研究了对G施加额外调节以明确抵消光谱爆炸的影响。首先,我们直接使每个权重的顶部奇异值 σ 0 σ_0 σ0正则化,朝向固定值 σ r e g σ_{reg} σreg或者以某个比率 r ⋅ s g ( σ 1 ) r{\cdot}sg(σ_1) r⋅sg(σ1)朝向第二奇异值(其中sg为停止梯度操作以防止正则化增加 σ 1 σ_1 σ1)。 或者,我们使用部分奇异值分解来代替 σ 0 σ_0 σ0。给定权重W,其第一个奇异向量 μ 0 μ_0 μ0和 ν 0 ν_0 ν0,以及 σ 0 σ_0 σ0将被值 σ c l a m p σ_{clamp} σclamp钳制,我们的权重变为:
W = W − m a x ( 0 , σ 0 − σ c l a m p ) ν 0 μ 0 T W = W - max(0,σ_0-σ_{clamp})ν_0μ_0^T W=W−max(0,σ0−σclamp)ν0μ0T
其中 σ c l a m p σ_{clamp} σclamp被设置为 σ r e g σ_{reg} σreg或 r ⋅ s g ( σ 1 ) r{\cdot}sg(σ_1) r⋅sg(σ1)。 我们观察到无论有无光谱归一化,这些技术都具有防止 σ 0 σ_0 σ0或 σ 0 σ 1 \frac{σ_0}{σ_1} σ1σ0逐渐增加和爆炸的效果,但即使在某些情况下它们可以温和地提高性能,但没有任何组合可以防止训练崩溃。 这一证据表明,虽然调节G可能会改善稳定性,但它不足以确保稳定性。 因此,我们将注意力转向D。
表征不稳定性:判别器
与G一样,我们分析D的权重的光谱以深入了解其行为,然后通过施加额外的约束来寻求稳定训练。图5(b)显示了D的的典型图。与G不同,我们看到光谱是嘈杂的, σ 0 σ 1 \frac{σ_0}{σ_1} σ1σ0表现良好,并且奇异值在整个训练过程中增长,但只是在崩溃时跳跃而不是爆炸。
D光谱中的峰值可能表明它周期性地接收到非常大的梯度,但我们观察到Frobenius规范是平滑的,表明这种效应主要集中在前几个奇异方向上。我们假设这种噪声是通过对抗训练过程进行优化的结果,其中G定期产生强烈干扰D的batch。如果这种频谱噪声与不稳定性有因果关系,那么自然的反制是使用梯度惩罚,这明显地规范了D的雅可比行列式的变化。我们从(Mescheder等人,2018)那里探索 R 1 R_1 R1零中心梯度罚分:
R 1 = γ 2 E P D ( x ) [ ∣ ∣ ∇ D ( x ) ∣ ∣ F 2 ] R_1 = \frac{γ}{2}E_{P_{D(x)}}[||\nabla{D(x)}||^2_F] R1=2γEPD(x)[∣∣∇D(x)∣∣F2]
默认建议强度 γ γ γ为10时,训练变得稳定并改善G和D中光谱的平滑度和有界性,但性能严重下降,导致IS减少45%。减少惩罚可以部分缓解这种恶化,但会导致频谱越来越不良;即使将惩罚力度降低到1(没有发生突然崩溃的最低强度),IS也会减少20%。使用正交正则化,DropOut和L2的各种改良重复该实验,揭示了这些正则化策略的行为效果:对D的惩罚足够高时,可以实现训练稳定性但是性能成本很高。
我们还观察到D在训练期间的损失接近于零,但在崩溃时经历了急剧的向上跳跃。这种行为的一个可能的解释是D过度拟合训练集,记忆训练样本而不是学习真实和生成图像之间的一些有意义的边界。作为D记忆的简单测试,我们在ImageNet训练和验证集上评估未折叠的鉴别器,并测量样本分类为真实或生成的百分比。虽然训练精度始终高于98%,但验证准确度仅在50-55%的范围内,并不比随机猜测更好(无论正则化策略如何)。这证实了D确实记住了训练集;我们认为这符合D的角色,这不是明确的概括,而是提炼训练数据并为G提供有用的学习信号。
总结
我们发现稳定性不仅仅来自G或D,而是来自他们通过对抗性训练过程的相互作用。 虽然他们的不良症状调节可用于追踪和识别不稳定性,但确保合理的调节是训练所必需的,但不足以防止最终的训练崩溃。 可以通过强烈约束D来强制实现稳定性,但这样做会导致性能上的巨大成本。 使用现有技术,可以通过放松这种调节并允许在训练的后期阶段发生塌陷来实现更好的最终性能,此时模型经过充分训练以获得良好的结果
代码
生成器:
class Generator(nn.Module):
def __init__(self, code_dim=100, n_class=1000, chn=96, debug=False):
super().__init__()
self.linear = SpectralNorm(nn.Linear(n_class, 128, bias=False))
if debug:
chn = 8
self.first_view = 16 * chn
self.G_linear = SpectralNorm(nn.Linear(20, 4 * 4 * 16 * chn))
self.conv = nn.ModuleList([GBlock(16*chn, 16*chn, n_class=n_class),
GBlock(16*chn, 8*chn, n_class=n_class),
GBlock(8*chn, 4*chn, n_class=n_class),
GBlock(4*chn, 2*chn, n_class=n_class),
SelfAttention(2*chn),
GBlock(2*chn, 1*chn, n_class=n_class)])
# TODO impl ScaledCrossReplicaBatchNorm
self.ScaledCrossReplicaBN = ScaledCrossReplicaBatchNorm2d(1*chn)
self.colorize = SpectralNorm(nn.Conv2d(1*chn, 3, [3, 3], padding=1))
def forward(self, input, class_id):
codes = torch.split(input, 20, 1)
class_emb = self.linear(class_id) # 128
out = self.G_linear(codes[0])
# out = out.view(-1, 1536, 4, 4)
out = out.view(-1, self.first_view, 4, 4)
ids = 1
for i, conv in enumerate(self.conv):
if isinstance(conv, GBlock):
conv_code = codes[ids]
ids = ids+1
condition = torch.cat([conv_code, class_emb], 1)
# print('condition',condition.size()) #torch.Size([4, 148])
out = conv(out, condition)
else:
out = conv(out)
out = self.ScaledCrossReplicaBN(out)
out = F.relu(out)
out = self.colorize(out)
return F.tanh(out)
判别器:
class Discriminator(nn.Module):
def __init__(self, n_class=1000, chn=96, debug=False):
super().__init__()
def conv(in_channel, out_channel, downsample=True):
return GBlock(in_channel, out_channel,
bn=False,
upsample=False, downsample=downsample)
gain = 2 ** 0.5
if debug:
chn = 8
self.debug = debug
self.pre_conv = nn.Sequential(SpectralNorm(nn.Conv2d(3, 1*chn, 3,padding=1),),
nn.ReLU(),
SpectralNorm(nn.Conv2d(1*chn, 1*chn, 3,padding=1),),
nn.AvgPool2d(2))
self.pre_skip = SpectralNorm(nn.Conv2d(3, 1*chn, 1))
self.conv = nn.Sequential(conv(1*chn, 1*chn, downsample=True),
SelfAttention(1*chn),
conv(1*chn, 2*chn, downsample=True),
conv(2*chn, 4*chn, downsample=True),
conv(4*chn, 8*chn, downsample=True),
conv(8*chn, 16*chn, downsample=True),
conv(16*chn, 16*chn, downsample=False))
self.linear = SpectralNorm(nn.Linear(16*chn, 1))
self.embed = nn.Embedding(n_class, 16*chn)
self.embed.weight.data.uniform_(-0.1, 0.1)
self.embed = spectral_norm(self.embed)
def forward(self, input, class_id):
out = self.pre_conv(input)
out = out + self.pre_skip(F.avg_pool2d(input, 2))
# print(out.size())
out = self.conv(out)
out = F.relu(out)
out = out.view(out.size(0), out.size(1), -1)
out = out.sum(2)
out_linear = self.linear(out).squeeze(1)
embed = self.embed(class_id)
prod = (out * embed).sum(1)
# if self.debug == debug:
# print('class_id',class_id.size())
# print('out_linear',out_linear.size())
# print('embed', embed.size())
# print('prod', prod.size())
return out_linear + prod
训练:
class Trainer(object):
def __init__(self, data_loader, config):
# Data loader
self.data_loader = data_loader
# exact model and loss
self.model = config.model
self.adv_loss = config.adv_loss
# Model hyper-parameters
self.imsize = config.imsize
self.g_num = config.g_num
self.z_dim = config.z_dim
self.g_conv_dim = config.g_conv_dim
self.d_conv_dim = config.d_conv_dim
self.parallel = config.parallel
self.gpus = config.gpus
self.lambda_gp = config.lambda_gp
self.total_step = config.total_step
self.d_iters = config.d_iters
self.batch_size = config.batch_size
self.num_workers = config.num_workers
self.g_lr = config.g_lr
self.d_lr = config.d_lr
self.lr_decay = config.lr_decay
self.beta1 = config.beta1
self.beta2 = config.beta2
self.pretrained_model = config.pretrained_model
self.dataset = config.dataset
self.use_tensorboard = config.use_tensorboard
self.image_path = config.image_path
self.log_path = config.log_path
self.model_save_path = config.model_save_path
self.sample_path = config.sample_path
self.log_step = config.log_step
self.sample_step = config.sample_step
self.model_save_step = config.model_save_step
self.version = config.version
self.n_class = config.n_class
self.chn = config.chn
# Path
self.log_path = os.path.join(config.log_path, self.version)
self.sample_path = os.path.join(config.sample_path, self.version)
self.model_save_path = os.path.join(config.model_save_path, self.version)
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('build_model...')
self.build_model()
if self.use_tensorboard:
self.build_tensorboard()
# Start with trained model
if self.pretrained_model:
print('load_pretrained_model...')
self.load_pretrained_model()
致谢
非常感谢百度论文复现营 AI Studio以及飞桨团队,无偿的让我们参加这次复现营,请到行业大牛带领我们读论文,进行论文复现,在群里为我们尽心尽力的答疑,并且还赠送免费算力让我们跑程序,利用这次机会我学到了很多,也非常感谢大佬G-Lab计算机视觉实验室对论文的翻译,让我在短时间内快速的理解了论文,希望我接下来的科研之路能够越来越顺利,也希望百度AI Studio和飞桨团队越来越好,共同打造好属于我们自己的框架。
未完待续
接下来会是讲解代码
参考文献:
[1]: https://aistudio.baidu.com/aistudio/education/group/info/1340
[2]: https://www.dazhuanlan.com/2019/12/12/5df1233a03c1f/
[3]: http://www.gwylab.com/index.html