Microarchitecture:Micro Fusion
Micro Fusion Tech
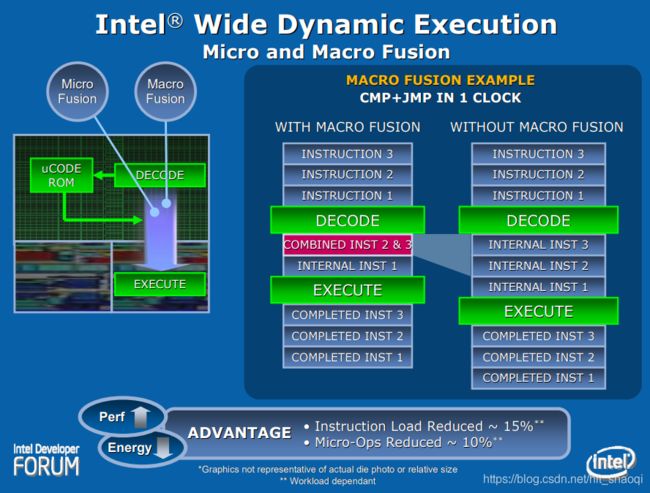
在没有进入Micro Fusion技术之前,单条复杂指令需要被译码为多条uops。Micro-fusion 技术则会将这些这些uops进行融合为一个单条的复杂micro-op。在之前如果被译码为N条uops,以在乱序core中执行,那么这个单条的复杂micro-op也同样需要被执行N次。
本质上MicroFusion 就是将复杂指令使用复杂uop表示,在译码之前,复杂指令只占用一条entry,而在译码之后,该uop只占用一条ROB,但是该uop会在多个(可能是不同的)执行单元中执行多次,而ROB可以持续追踪不同uop的结果。这样也就变相的增加了ROB的利用率。
Micro-fusion 可以应用在memory-to-register 的操作上,不需要担心译码带宽的损失。Micro-fusion 提升了从译码到retire的指令带宽并节约了功耗。
使用单uop指令的指令序列会增加程序的size,会降低从legacy pipeline的取指带宽。
uop fusion有如下的优势:
-
译码变得高校,因为fused op 可以在任何一个译码器中译码,然而产生两条op的只能在Decode0 中译码
-
load操作在寄存器重命名和retire单元遇到的瓶颈被解决掉,因为产生了更少的uops
-
ROB的容量增大了,如上所述。
Micro Fusion Test
我们可以将microarchitecure分为如下的两部分:

Fused domain表示decoder 产生的uops的数量。Fused uops 记为1。
执行单元无法执行fused uops,因为这样的uops将会在执行阶段split。
Unfused的domain表示进入各个执行单元的数量。
比如add DWORD [rsp+4],1 指令

图中所示,在译码后,会产生两条fused ops, 在执行阶段它们会分成4条uops,一个进入port0/1/5,两个进入2/3,最后一个进入port4。
如果使用add DWORD [rsp + 4], 1 指令进行测试,设置如下几个指标:
-
Fused:IDQ.DSB_UOPS 代表从IDQ到DSB的uops的数量
-
Fused:UOPS_RETIRED.RETIRE_SLOTS 代表每个周期使用的retirement slot的数量
-
Unfused:UOPS_RETIRED.All 为micro-ops retired的数量。
Benchmark Cycles UOPS_RETIRED.RETIRE_SLOTS UOPS_RETIRED.ALL
add [esp], 1 1.10 2.08 4.08
Read-Modify-Write 指令被译码为2个fused uops:load+op 和 write_addr+write_data。
Micro Fusion Case
下面是可以被所有译码器译码的micro-fused的micro ops。
-
所有的Store to memory, 包括store 立即数。store在内部按照两个单独的功能执行,store-address 和 store -data
-
所有的将load和计算操作结合的指令,比如
-
ADDPS XMM9, OWORD PTR [RSP+40]
-
FADD DOUBLE PTR [RDI+RSI*8]
-
XOR RAX, QWORD PTR [RBP+32]
-
-
load and jump 形式的指令
-
JMP [RDI+200]
-
RET
-
-
对立即数操作数和内存操作的CMP and Test
使用RIP相对寻址的指令在以下的case中不会被融合
-
RIP需要加上立即数
-
指令是控制流操作,使用RIP相对地址的重定向目标地址()an indirect target specified using RIP-relative addressing)
-
JMP [RIP+5000000]
-
在这些case中,无法被micro-fused融合的指令需要被指派进入decoder0, 以发射两条micro-ops,导致了decode带宽的降低。
在64bit code中,使用RIP相对地址操作对于全局数据来说很普遍。考虑到这些case中无法使用micro-fusion, 性能相对于32bit的程序,可能会下降。
Reference
micro-fusion & macro-fusion
MicroFusion in Intel CPUs
Intel® 64 and IA-32 Architectures Optimization Reference Manual
欢迎关注我的公众号《处理器与AI芯片》