HTTP协议:接口测试_发送请求_get方法
Requests模块说明
Requests是使用Apache2 Licensed许可证的HTTP库。用Python编写,真正的为人类着想。Python 标准库中的 urllib2 模块提供了你所需要的大多数 HTTP 功能,但是它的API太渣了。它是为另一个时代、另一个互联网所创建的。它需要巨量的工作,甚至包括各种方法覆盖,来完成最简单的任务。在Python的世界里,事情不应该这么麻烦。Requests使用的是 urllib3,因此继承了它的所有特性。Requests支持HTTP连接保持和连接池,支持使用 cookie 保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的 URL和POST数据自动编码。
请求与响应
HTTP就是一个发送请求和获取响应的过程,而requests模块只需要一步就能完成这样的一个过程,并且requests支持所有的HTTP请求的方法和响应数据,以下为requests模块的语法介绍:
response = requests.方法(URL,headers,data......)备注:
1、其中URL参数是必填的,毕竟HTTP请求就是对指定的URL进行发送,其他各种参数可根据实际请求的需要选择性使用
2、发送请求后会获取响应结果,然后把结果赋值给变量,最后通过变量的属性值取出需要的结果
3、如果url为https协议,则需要在get方法加上参数verify=false
Requests模块的7个主要方法
| 方法 | 说明 |
| requests.request( ) | 构造一个请求,支撑以下各个方法的基础方法 |
| requests.get( ) | 获取返回HTML网页的主要方法,对应HTTP的GET方法 |
| requests.post( ) | 向HTML网页提交post请求的方法,对应HTTP的POST方法 |
| requests.head( ) | 获取HTML网页信息头的主要方法,对应HTTP的HEAD方法 |
| requests.put( ) | 向HTML网页提交put请求的方法,对应HTTP的PUT方法 |
| requests.patch( ) | 向HTML网页提交局部修改的请求,对应HTTP的PATCH方法 |
| requests.delete( ) | 向HTML网页提交删除请求,对应HTTP的DELETE方法 |
Response返回对象的属性
| 属性 | 说明 |
| Response.status_code | HTTP请求的返回状态,200表示连接成功,404表示失败 |
| Response.text | HTTP响应内容的字符串形式,即URL对应的页面内容(获取返回的主体) |
| Response.headers | 获取返回的信息头 |
| Response.cookies | 获取返回的cookie |
| Response.encoding | 从HTTP header中获得响应内容的编码方式 |
| Response.apparent_encoding | 从内容中分析出的响应内容的编码方式(备选编码方式) |
| Response.content | HTTP响应内容的二进制形式(爬图片、视频之类的后可以用这种格式保存) |
| Response.json( ) | 针对响应为json字符串解码为python字典(响应为Json格式时才能用该函数) |
| Response.url | 返回访问的URL |
| Response.encoding = 'utf-8' | 设置响应报文编码 |
| Response.ok | 查看Response.ok的布尔值便可以知道是否登陆成功 |
| Response.raise_for_status( ) | 失败请求(非200响应)抛出异常 |
Request的get( )方法语法:
获得一个网页最简单直接的方法就是r = requests.get(url),向服务器请求资源
response = requests.get(url, params=None, **kwargs)
参数:
url:拟获取页面的url链接
params:url中的额外参数,字典或字节流格式(当params=None时,不会向URL中添加参数)
**kwargs:12个控制访问的参数
"""
data:字典,字节序列或文件对象,作为Request的内容
json:JSON格式的数据,作为Request的内容
headers:字典,HTTP定制头(模拟浏览器进行访问)
cokies:字典或CpplieJar,Request中的cookie
auth:元组,支持HTTP认证功能
files:字典类型,传输文件
timeout:设定超时时间,秒为单位
proxies:字典类型,设定访问代理服务器,可以增加登陆认证
allow_redirects:True//False,默认为True,重定向开关
stream:True/False,默认为True,获取内容立即下载开关
verify:True/False,默认为True,认证SSL证书开关
cert:本地SSL证书路径"""
"""
请求参数
URL参数
URL参数是唯一的必填参数,必须要有URL地址才能发送
例1:
#请求一个静态网页,使用get()方法
import requests
url = "https://www.163.com/"
response = requests.get(url)
print(response.status_code) #获取状态码
print(response.cookies) #获取cookie,这种获取的cookie不能用于登录,因为它不是完整的
print(response.headers) #获取响应头
print("以下为返回响应的主体",response.text)
"""
200
{'Transfer-Encoding': 'chunked', 'Vary': 'Accept-Encoding,User-Agent,Accept......
以下为返回响应的主体
.......
""" 例1_1:
import requests
method = 'GET'
url = 'https://hao.360.com/'
response = requests.request(method=method, url=url)
print(response.text)
"""
360导航_一个主页,整个世界
"""说明:
在get( )方法中将变量url直接传入,即完成了带着URL的get请求,结果会赋值给变量response,在response中包含了返回结果的所有数据,可以根据需要获取想要的数据(本例子中分别获取了状态码、cookie、信息头、返回主体)
headers参数
1、headers参数是最常用的参数之一,例1只是一个最简单的请求(没有带其他参数),而很多时候需要带入headers参数发送请求,才可以获取响应的请求结果
2、特别是网站有反爬虫机制时更需要带上headers参数(User-Agent),另外该参数也可以模拟PC端请求和手机端请求(将User-Agent改为请求的手机型号)
例2:
import requests
aims_url = "https://www.163.com/"
#以字典形式传入User-Agent值
device = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36 "}
reponse = requests.get(url=aims_url,headers=device)
print(reponse.status_code)
#print(reponse.cookies)
print(reponse.headers)
print("以下为返回响应的主体",reponse.text)
"""
200
{'Vary': 'Accept-Encoding,User-Agent,Accept', 'Content-Type': 'text/html; charset=GBK'......
以下为返回响应的主体
.......
"""
cookies参数
1、cookies也是最常用的参数之一,因为只要涉及需要登录后才能获取的数据,都需要用到cookies参数
2、如何获取cookie:一种是通过post发送登录请求后,获取返回值的cookies属性;另一种是通过抓包工具获取cookies值
3、cookies参数以字典的形式发送,只需要对应的将name和value传入即可
例3:
import requests
aims_url = "https://i.taobao.com/my_taobao.htm?spm=a21bo.2017.1997525045.1.5af911d97PxzIj"
#以字典形式传进cookie值
cookie_value = {"Cookie":"thw=cn; cna=qnh; v=0; t=b1cc0586709de; "
"cookie2=12d27; _tb_token_=71b173;"
" unb=18230; sg=%E5%8606; _l_g_=UgD3D; skt=bbbb52; "
"cookie1=UU2Bu%2Fc5x8n67owg%3D; "
"csg=65578; uc3=vt3=Fid2=Uoncj%k2=GDijVg2=V%3D; existhop=M%3D;"
" tracknick=zhD%5Cu8B0%5u5FC6; "
"lgc=zh%5C0D%5Cu73B0%5Cu5FC6; _cc_=W5iHLLyFfA%3D%3D; "
"dnk=zh%5Cu5Cu6u7684%5Cu8BB0%5Cu5FC6; _nk_=zh%5Cu4E08BB0%5Cu5FC6;"
" cookie17=Uoncjg9Q%3D%3D; tg=0; mt=ci=110_1; _mw_us_time_=1557409494218;"
" uc1=cooke16=Vqe21=kie15=Whop=fals&pas=0&cokie14=U8tag=8&lng=zh_CN;"
" isg=BKys8kMmYhn; l=bBP-KUd8ByCC."}
#以字典形式传入User-Agent值
device = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36 "}
reponse = requests.get(url=aims_url,headers=device,cookies=cookie_value)
print("返回的状态码为",reponse.status_code)
print("返回的响应头为",reponse.headers)
print("返回的响应内容为",reponse.text)
"""
返回的状态码为 200
返回的响应头为 {'x-content-type-options': 'nosniff', 'Date': 'Thu, 09 May 2019 14:
我的淘宝
""" 说明:
将获取的cookie信息以字典的形式赋值给变量cookie_value,再get()方法中加一个cookies参数,将变量cookie_value赋值给参数cookies,即完成了带着cookie信息的get请求
例3_1:
import requests
cookie_value = "JSESSIONID=8D50DgBCFE3Cg53D704D9"
web_url = "http://mail.163.com/js6/main.jsp?sid=" \
"xCsXkCUUCJYwVBCjouUUtnRzyRTfyHOs&df=163nav_icon#module=welcome.WelcomeModule%7C%7B%7D"
response = requests.get(url =web_url,headers ={"cookie":cookie_value})
print(response.status_code)
print(response.headers)
print(response.text)
"""
200
{'Content-Type': 'text/html', 'Vary': 'Accept-Encoding', 'Server': 'nginx'.......
说明:
1、cookie也可以通过headers参数传递,只是不同之处在于使用cookies参数时:cookie是以字典的形式发送的{Cookie:Value};而使用headers参数时:在headers之中cookie只是其中的一个键(cookie值是一个字符串),所以需要把cookie放到该键对应的值里面,而对应的值是以key=value的形式传入的
2、两种方法中建议使用cookies参数:一方面把cookie单独分离出来,不用与headers其他参数放在一起,让代码更加清晰;另一方面通过post请求返回的cookies是可以直接赋值到cookies参数之中的,不需要在做转换
备注:如何查找Cookie
1、登录时获得Cookies:打开登录页面并输入账号、密码后打开抓包工具,点击【登录】按钮,此时就可以抓到登录时的请求
注:这种方法也适用于获取提交的表单(打开抓包工具后,输入数据并提交)

2、进入我们需要的网页后,点击F5刷新

3、登录后打开抓包工具再打开我们需要的网页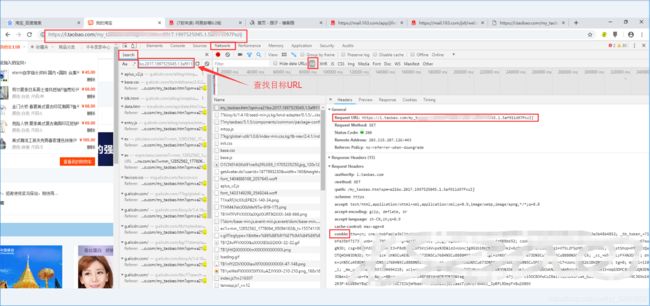
备注:
1、通过这个方式找Cookie会发现其实一个URL(整个网页)是由很多子URL(元素JS脚本等)组成的,即每个资源都存在一个URL(路径),做测试时不仅可以获取整个URL(页面),也可以获得其中某个字URL(元素),所以需要确定好哪个才是我们需要的URL信息
2、在登录时最好勾选【记住密码】之类的
3、抓取Cookie时,建议使用后两种方法,登录时获取的cookies可能并不是完整的
params参数
1、params参数可以存放请求的表单(即URL中的参数部分),并会以key1=value1&key2=value2(字典)的形式跟在URL之后发送,为了区分URL和参数,最好不要将表单放在URL之中
2、URL中的参数部分可以直接放在URL中直接发送,也可以使用params参数进行发送(实现将URL与参数分离。使用params关键字以一个字符串字典来传递这些参数)
例4:
#URL:http://tieba.baidu.com/home/main?id=e4d6e4b880e59b9eefe4ba8ce59b9ee7869fe4b8b65f5e?t=14249&fr=userbar
import requests
cookie_value = {"JSESSIONID":"8D50D286BF57F0FABCFE3C3353D704D9"}
web_url = "http://tieba.baidu.com/home/main"
url_parameter = {"id":"e4d6e4b880e59b9eefe4ba8ce59b9ee7869fe4b8b65f5e?t=1424",
"fr":"userbar"}
response = requests.get(url =web_url,cookies=cookie_value,params=url_parameter)
print(response.url)#判断拼接后的URL是否正确
print(response.status_code)
print(response.headers)
print(response.cookies)
print(response.text)
"""
http://tieba.baidu.com/home/main?fr=userbar&id=e4d6e4b880e59b9eefe4ba8ce59b9ee7869fe4b8b65f5e%3Ft%3D14249
200
{'X-Xss-Protection': '1; mode=block', 'P3p': 'CP=" OTI DSP COR IVA OUR IND COM "'.......
例4_1:
import requests
lists = ['python', 'php', 'Java']
for params in lists:
url = 'http://www.baidu.com/s?wd=%s' % (str(params))
r = requests.get(url)
print(r.url)
#或
import requests
lists = ['python', 'php', 'Java']
for i in lists:
params = {"wd":str(i)}
url = "http://www.baidu.com/s"
r = requests.get(url=url,params=params)
print(r.url)
"""
http://www.baidu.com/s?wd=python
http://www.baidu.com/s?wd=php
http://www.baidu.com/s?wd=Java
"""注:
1、将需要发送的表单以字典的形式赋值到变量(url_parameter)中
2、在get方法中加一个params参数,然后将变量(url_parameter)赋值给params参数,即完成了带着params信息的get请求
3、如果字典中存在None的值,是不会添加到url请求中的
4、GET方法中使用params参数来存放表单,参数位于URL中;POST方法中使用data参数来存放表单,参数位于Headers中
保存会话
会话对象,能够跨请求保持某些参数
使用session.get(url)发出get请求会带上之前保存在session中的cookie,能够请求成功
例5:
import requests
aims_url = "http://www.weather.com.cn/weather1d/101010100.shtml#search"
session = requests.session()#实例化session
response = session.get(aims_url,stream=True)
response.encoding = "utf-8" #响应报文编码不为utf-8,因此需要设置下
print(response.headers)#获得返回报文的信息头
print(response.status_code)
print(response.text)
"""
{'Connection': 'keep-alive', 'X-Via': '1.1 PS-PEK-01vfL225:3.....
200
【北京天气】北京今天天气预报,今天,今天天气,7天,15天天气预报,天气预报一周,天气预报15天查询
.......
"""
获取返回信息
获取响应头
例5:
import requests
aims_url = "http://www.weather.com.cn/weather1d/101010100.shtml#search"
r=requests.get(aims_url,stream=True)
print(r.headers)#获得返回报文的信息头
print(r.headers.get('Content-Type')) #获取响应报文类型
print(r.request.headers) #获得请求报文的信息头
"""
{'Server': 'nginx', 'Content-Encoding': 'gzip', ', 'Content-Type': 'text/html', 'Connection': 'keep-alive'}
text/html
print(r.request.headers)
{'Accept': '*/*', 'User-Agent': 'python-requests/2.21.0', 'Accept-Encoding': 'gzip, deflate', 'Connection': 'keep-alive'}
"""注:
1、r.headers返回的是一个字典
2、可以使用r.headers.get('参数键名')方法来取得部分响应头
3、可以使用r.request.headers直接获得请求头(也就是我们向服务器发送的头信息)
获取响应信息的输出格式
例6:
import requests
aims_url = "https://blog.csdn.net/qq_25987491/article/details/80058044"
r=requests.get(aims_url)
print(r.encoding)
#上面代码输出结果为:UTF-8(响应信息是以utf-8格式输出的)
修改响应信息输出格式
例6_1:
import requests
aims_url = "https://blog.csdn.net/qq_25987491/article/details/80058044"
r=requests.get(aims_url)
r.encoding = 'ISO-8859-1'
print(r.encoding)
#上面代码输出结果为:ISO-8859-1(响应信息是以ISO-8859-1格式输出的)注:
以字节流返回响应信息:r.content返回的是二进制字节流(r.text是以字符串形式返回)
例6_3:
import requests
imgUrl = "https://ss0.bdstatic.com/5aV1bjqh_Q23odCf/static/superman/img/logo_top_86d58ae1.png"
def saveImage( imgUrl,imgName ="default.jpg" ):
r = requests.get(imgUrl, stream = True)
image = r.content
destDir="D:\\"
print("保存图片"+destDir+imgName)
try:
with open(destDir+imgName ,"wb") as jpg:
jpg.write(image)
print("成功")
return
except IOError:
print("IO Error")
return
finally:
jpg.close
saveImage(imgUrl)
#输出结果为:URL对应的图片(网页中的对应元素)
获取格式为JSON的响应
例7:
import requests
aims_url = "http://httpbin.org/get"
r=requests.get(aims_url,stream=True)
print(r.json())
#上面代码输出结果为:
#{'args': {}, 'url': 'https://httpbin.org/get', 'headers': {'Accept': '*/*', 'Host': 'httpbin.org', 'Accept-Encoding': 'gzip}}备注:
只有响应格式本身为JSON的数据才能使用该方法获取,若响应格式不是JSON并使用了该方法会报"json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)"
关于重定向
有时候我们在请求url时,服务器会自动把我们的请求重定向,比如github会把我们的http请求重定向为https请求。我们可以使用r.history来查看重定向:
例8:
>>> r = requests.get('http://pythontab.com/')
>>> r.url
'http://pythontab.com/'
>>> r.history
[]从上面的例子中可以看到,我们使用http协议访问,结果在r.url中,打印的却是https协议。那如果我非要服务器使用http协议,也就是禁止服务器自动重定向,该怎么办呢?使用allow_redirects 参数:
r = requests.get('http://pythontab.com', allow_redirects=False)
关于请求时间
我们可以使用timeout参数来设定url的请求超时时间(时间单位为秒):
例9:
requests.get('http://pythontab.com', timeout=1)
关于代理
我们也可以在程序中指定代理来进行http或https访问(使用proxies关键字参数),如下:
例10:
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
requests.get("http://pythontab.com", proxies=proxies)
下载页面
使用Requests模块也可以下载网页,代码如下:
例11:
import requests
r=requests.get("https://www.baidu.com/")
with open("haha.html","wb") as html:
html.write(r.content)
html.close()
#下载下来的网页是以HTML文件形式保存的