网络加载框架 - Retrofit
转载于 https://www.jianshu.com/p/0fda3132cf98
网络加载框架 - Retrofit
原来公司用的是OKGO来加载网络,现在全部替换为Retrofit了,用起来挺不适应的,现在我负责的模块代码中网络数据请求都是照葫芦画瓢搬过其他人的接口代码改成自己的。至于为什么按照这种格式写?这么写有什么好处?有没有其他的写法?懵逼了!因为之前没接触过Retrofit这东西,现在想着抽点时间好好研究一下。
Retrofit是什么?
Retrofit其实我们可以理解为OkHttp的加强版,它也是一个网络加载框架。底层是使用OKHttp封装的。准确来说,网络请求的工作本质上是OkHttp完成,而 Retrofit 仅负责网络请求接口的封装。它的一个特点是包含了特别多注解,方便简化你的代码量。并且还支持很多的开源库(著名例子:Retrofit + RxJava)。
还想说一点题外话,Retrofit和OkHttp(我们公司用到的OKGO框架也是封装人家的OkHttp)都是square公司(前一篇我写的简书文章Dragger也是他们的,我擦,真是大佬!)
Retrofit的好处?
- 超级解耦
解耦?解什么耦?
我们在请求接口数据的时候,API接口定义和API接口使用总是相互影响,什么传参、回调等,耦合在一块。有时候我们会考虑一下怎么封装我们的代码让这两个东西不那么耦合,这个就是Retrofit的解耦目标,也是它的最大的特点。
Retrofit为了实现解耦,使用了特别多的设计模式,这里附上一片很好的文章,里面讲的就是实现原理:
Retrofit分析-漂亮的解耦套路 - 可以配置不同HttpClient来实现网络请求,如OkHttp、HttpClient...
- 支持同步、异步和RxJava
- 可以配置不同的反序列化工具来解析数据,如json、xml...
- 请求速度快,使用非常方便灵活
Retrofit注解
- 请求方法
| 注解代码 | 请求格式 |
|---|---|
| @GET | GET请求 |
| @POST | POST请求 |
| @DELETE | DELETE请求 |
| @HEAD | HEAD请求 |
| @OPTIONS | OPTIONS请求 |
| @PATCH | PATCH请求 |
- 请求参数
| 注解代码 | 说明 |
|---|---|
| @Headers | 添加请求头 |
| @Path | 替换路径 |
| @Query | 替代参数值,通常是结合get请求的 |
| @FormUrlEncoded | 用表单数据提交 |
| @Field | 替换参数值,是结合post请求的 |
下面我们详细说说这些注解
我们先来看一段Retrofit请求的简单用法
- 添加依赖
由于Retrofit是基于OkHttp,所以还需要添加OkHttp库依赖
在build.grale添加如下依赖:
dependencies {
// Okhttp库
compile 'com.squareup.okhttp3:okhttp:3.1.2'
// Retrofit库
compile 'com.squareup.retrofit2:retrofit:2.0.2'
}
- 添加网络权限
<uses-permission android:name="android.permission.INTERNET"/>
- 创建接收服务器返回数据的类
public class News {
// 根据返回数据的格式和数据解析方式(Json、XML等)定义
...
}
- 创建用于描述网络请求的接口
public interface APi {
// @GET注解的作用:采用Get方法发送网络请求
// getNews(...) = 接收网络请求数据的方法
// 其中返回类型为Call,News是接收数据的类(即上面定义的News类)
// 如果想直接获得Responsebody中的内容,可以定义网络请求返回值为Call getNews(@Query("num") String num,@Query("page")String page) ;
}
这一块知识点很多,做好笔记了!
①Retrofit将Http请求抽象成Java接口,并在接口里面采用注解来配置网络请求参数。用动态代理将该接口的注解“翻译”成一个Http请求,最后再执行 Http请求
注意: 接口中的每个方法的参数都需要使用注解标注,否则会报错
②APi接口中的最后一个注释,Responsebody是Retrofit网络请求回来的原始数据类,没经过Gson转换什么的,如果你不想转换,比如我就想看看接口返回的json字符串,那就像注释中说的,把Call的泛型定义为ResponseBody:Call
③GET注解
说白了就是我们的GET请求方式。
这里涉及到Retrofit创建的一些东西,Retrofit在创建的时候,有一行代码:
baseUrl("http://apis.baidu.com/txapi/")
这个http://apis.baidu.com/txapi/是我们要访问的接口的BaseUrl,而我们现在用GET注解的字符串 "word/word"会追加到BaseUrl中变为:http://apis.baidu.com/txapi/world/world
在我们日常开发中,BaseUrl具体是啥由后端接口童鞋给出,之后接口童鞋们会出各种各种的后缀(比如上面的 "word/word")组成各种各行的接口用来供移动端数据调用,实现各种各样的功能
④@Query
简单点来说呢
@Query("num")String num, @Query("page")String page;
就是键值对,Retrofit会把这两个字段一块拼接到接口中,追加到http://apis.baidu.com/txapi/world/world后面,变为http://apis.baidu.com/txapi/world/world?num=10&page=1,这样,这个带着响应头的接口就是我们最终请求网络的完整接口。
这里补充一点哈,GET请求方式,如果携带的参数不是以
?num=10&page=1
拼接到接口中(就是不带?分隔符),那就不用Query注解了,而是使用Path注解,像我们项目中的Get请求:
@GET(URL.CLAIM_APPLICATION_BOOKINFO + "{claimId}")
Observable>> getClaimApplicationBookInfo(@Header("Authorization") String authorization, @Path("claimId") String claimId);
上面的GET注解的接口通过{}占位符来标记的claimId,就用@Path注解在传入claimId的值。
@Query与@Path功能相同,但区别明显不一样。像@Query的例子,我如果使用@Path来注解,那么程序就会报错。这块要搞清楚!
还有一点哈,有的url既有“{}”占位符,又有“?”后面的键值对(key-value),那Retrofit既得使用@Query注解又得使用@Path注解,也就是说,两者可以同时使用。
⑤@Headers
@Headers("apikey:81bf9da930c7f9825a3c3383f1d8d766")
这个很好理解,这个接口需要添加的header:
apikey:81bf9da930c7f9825a3c3383f1d8d766
@Headers就是把接口的header注解进去。还有很多添加header的方式,比如:
public interface APi {
@GET("word/word")
Call getNews(@Header("apikey")String apikey, @Query("num")String num, @Query("page")String page) ;
}
这个就是在代码中动态的添加header,用法如下:
Call news = mApi.getNews("81bf9da930c7f9825a3c3383f1d8d766", "1", "10");
关于header的其他添加方式,大家可以看看下面的文章:
Retrofit之请求头
这里再补充一点:@Header与@Headers的区别
举个例子:
//@Header
@GET("user")
Call getUser(@Header("Authorization") String authorization)
//@Headers
@Headers("Authorization:authorization")
@GET("user")
Call getUser()
以上两个方法的效果是一致的。
区别就在于使用场景和使用方式
使用场景:@Header用于添加不固定的请求头,@Headers用于添加固定的请求头
使用范围:@Header作用于方法的参数;@Headers作用于方法
- 创建Retrofit对象
Retrofit retrofit = new Retrofit.Builder()
//设置数据解析器
.addConverterFactory(GsonConverterFactory.create())
//设置网络请求的Url地址
.baseUrl("http://apis.baidu.com/txapi/")
.build();
// 创建网络请求接口的实例
mApi = retrofit.create(APi.class);
这一块知识点有三个:
①此处特意说明一下这个网络请求的URL的组成:Retrofit把网络请求的URL 分成了两部分设置:
第一部分:在创建Retrofit实例时通过.baseUrl()设置,就是上面的
.baseUrl("http://apis.baidu.com/txapi/")
第二部分:在网络请求接口的注解设置,就是在上面的APi接口中用GET注解的字符串:
@GET("word/word")
Retrofit的网络请求的完整Url = 创建Retrofit实例时通过.baseUrl()设置的url
+网络请求接口的注解设置(下面称 “path“ )
(第四种类型存疑)
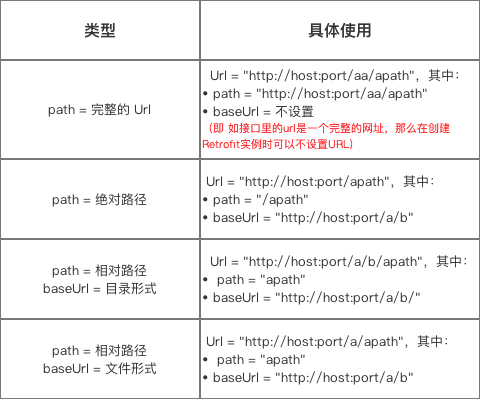
建议采用第三种方式来配置,并尽量使用同一种路径形式。
②关于数据解析器(Converter)
//设置数据解析器
.addConverterFactory(GsonConverterFactory.create())
这个有啥用?这句话的作用就是使得来自接口的json结果会自动解析成定义好了的字段和类型都相符的json对象接受类。在Retrofit 2.0中,Package 中已经没有Converter了,所以,你需要自己创建一个Converter, 不然的话Retrofit只能接收字符串结果,你也只能拿到一串字符,剩下的json转换的活还得你自己来干。所以,如果你想接收json结果并自动转换成解析好的接收类,必须自己创建Converter对象,然后使用addConverterFactory把它添加进来!
Retrofit支持多种数据解析方式,在使用时注意需要在Gradle添加依赖:
| 数据解析器 | Gradle依赖 |
|---|---|
| Gson | com.squareup.retrofit2:converter-gson:2.0.2 |
| Jackson | com.squareup.retrofit2:converter-jackson:2.0.2 |
| Simple XML | com.squareup.retrofit2:converter-simplexml:2.0.2 |
| Protobuf | com.squareup.retrofit2:converter-protobuf:2.0.2 |
| Moshi | com.squareup.retrofit2:converter-moshi:2.0.2 |
| Wire | com.squareup.retrofit2:converter-wire:2.0.2 |
| Scalars | com.squareup.retrofit2:converter-scalars:2.0.2 |
像上面代码中,就是使用了第一种Gson数据解析器
③再来引入另一个方法:addCallAdapterFactory()
上文代码中没有这个方法,但是得知道它的作用,有必要作为补充知识点
看一下我们的接口返回:
Call news = mApi.getNews("1", "10");
返回的Call
Observable news = mApi.getNews("1", "10").subscribeOn(...).observeOn(...);
它返回的是一个Observable类型(观察者模式)。从上面可以看到,Retrofit接口的返回值可以分为两部分,第一部分是返回值类型:Call或者Observable,另一部分是泛型:News
addCallAdapterFactory()影响的就是第一部分:Call或者Observable。Call类型是Retrofit默认支持的(Retrofit内部有一个DefaultCallAdapterFactory),所以你如果不用RXJava + Retrofit结合使用,那就自动忽略掉这个方法,而如果你想要支持RXJava(就是想把返回值定义为Observable对象),就需要我们自己用addCallAdapterFactory()添加:
addCallAdapterFactory(RxJavaCallAdapterFactory.create())
像我们项目中Retrofit创建的代码就是:
retrofit = new Retrofit.Builder()
.baseUrl(URL.SERVICE_URL)
.addCallAdapterFactory(RxJava2CallAdapterFactory.create())
.addConverterFactory(GsonConverterFactory.create())
.client(okHttpClient)
.build();
同理,Retrofit不光支持多种数据解析器,也支持多种网络请求适配器:Guava、Java8、RXJava ,使用时也需要在Gradle添加依赖:
| 网络请求适配器 | Gradle依赖 |
|---|---|
| Guava | com.squareup.retrofit2:adapter-guava:2.0.2 |
| Java8 | com.squareup.retrofit2:adapter-java8:2.0.2 |
| RXJava | com.squareup.retrofit2:adapter-rxjava:2.0.2 |
像上面的代码,就是用的RXJava
- 发起网络请求
//对发送请求进行封装
Call news = mApi.getNews("1", "10");
//发送网络请求(异步)
news.enqueue(new Callback() {
//请求成功时回调
@Override
public void onResponse(Call call, Response response) {
//请求处理,输出结果-response.body().show();
}
@Override
public void onFailure(Call call, Throwable t) {
//请求失败时候的回调
}
});
上面是一个简单的GET请求的全过程。
补充一点,Retrofit还有个发起同步网络请求的方式:
//对发送请求进行封装
Call news = mApi.getNews("1", "10");
//发送网络请求(同步)
Response response = news.execute();
接下来我们看下POST请求
Retrofit的POST请求
POST请求与GET请求算是我们日常开发中最最常用的两种网络访问方式,Retrofit的POST请求在用法上与GET区别不算大。
拿我早期写过的一个比较不合格的代码举个例子就能看出来(先声明,这种写法是不合格的,但是接口能跑通,看下去你就知道了):
①首先都是定义一个API接口:
public interface IServiceApi {
@POST("/claims/preclaims")
Observable> postClaimPreclaims(@Header("Authorization") String authorization, @QueryMap HashMap deviceInfo, @Body RequestBody body);
}
拿出笔记啦(因为大部分都和GET请求一样,所以这里讲的就简单点)
①和GET请求相比,流程的开头都是创建了一个API的接口,然后用@POST注释,指定了对应的接口地址,我的返回值需要把获取到的Json字符串转成PublicResponseEntity
但是我项目中用到的是RxJava + Retrofit,所以把返回值定义为了Observable
②方法中的第一个参数:我是在代码中动态的添加了一个header,这没啥可说的,上面的GET请求中说完了已经,看第二个。
③方法中的第二个参数:通过@QueryMap往接口中注解很多个参数,看到这里很容易联想到@Query,在上面的GET请求中@Query是一个一个往接口中注入参数的,而@QueryMap从名字也能看出来,如果Query参数比较多,那么可以通过@QueryMap方式将所有的参数集成在一个Map统一传递。
③第三个参数:通过@Body注解了一个RequestBody,
好!又出来一个新的注解@Body,它的源码中对他的注释大体意思是:使用这个注解可以把参数放到请求体中,适用于 POST/PUT请求,一脸懵逼呀,只知道它适用于对于POST/PUT。
其实,@Body可以注解很多东西的,HashMap、实体类等,例如:
public interface IServiceApi {
@POST("/claims/preclaims")
Observable- postClaimUser(@Body User user)
;
}
那这么一看,@Body和@QueryMap差别不是很大哈,都可以对很多参数进行封装传递。话是这么说,但是它俩还是有差别的:
@QueryMap注解会把参数拼接到url后面,所以它适用于GET请求;
@Body会把参数放到请求体中,所以适用于POST请求。
如果你的项目是采用POST请求方式,不管是使用实体类还是使用HashMap最好采用@Body注解。虽然你使用QueryMap 可能也不会有什么问题(PS:这种共用的情况只适用于POST请求,GET请求不能使用@Body注解,否则会报错),就像上面我的不合格代码一样,POST请求中一直采用@QueryMap,虽然也能拿到接口数据,但是这么写是不合格的。
引以为戒吧~~
接下来就是调用了:
一样的创建Retrofit对象
Retrofit retrofit = new Retrofit.Builder()
.baseUrl(URL.SERVICE_URL)
.addCallAdapterFactory(RxJava2CallAdapterFactory.create())
.addConverterFactory(GsonConverterFactory.create())
.client(okHttpClient)
.build();
// 创建网络请求接口的实例
IServiceApi mApi = retrofit.create(IServiceApi .class);
一样的发起网络请求:
//对发送请求进行封装
Observable> news = mApi.postClaimPreclaims("你的Header信息", "你要传到接口中的HashMap参数", "你的实体类");
//发送网络请求(异步)
news.enqueue(new Callback() {
//请求成功时回调
@Override
public void onResponse(Call call, Response response) {
//请求处理,输出结果-response.body().show();
}
@Override
public void onFailure(Call call, Throwable t) {
//请求失败时候的回调
}
});
OK,到这里,你就能成功拿到一次POST请求的数据了。
这一块我讲的比较少,因为我也是在边写边学,不会的不敢写,先把掌握到的写下来做个积累,以后慢慢把学到的东西补充进来。
Retrofit下载文件
其实用Retrofit下载文件方式与其他请求几乎无异,拿我用到下载PDF的程序来举例子
step1:编写API,执行下载接口功能
public interface IServiceApi {
····
//PDF文件Retrofit下载
@Streaming
@GET
Observable retrofitDownloadFile(@Url String fileUrl) ;
...
}
上面的代码有几个注意的点:
①@Streaming 是注解大文件的,小文件可以忽略不加注释,但是大文件一定需要注释,不然会出现OOM。
②fileUrl就是PDF的下载地址,通过参数形式传进来
③正常来讲,API接口的返回类型是Call
public interface IServiceApi {
····
//PDF文件Retrofit下载
@Streaming
@GET
Call retrofitDownloadFile(@Url String fileUrl) ;
...
}
但是我项目中是Retrofit结合RXJava来使用的,我把它的返回值类型定义为Observable
step2:实现一个下载管理工具
它的作用有很多:写入文件、判断文件类型、计算文件大小...当然最主要的还是用来把下载下来的文件写入本地
public class DownLoadManager {
//Log标记
private static final String TAG = "eeeee";
//APK文件类型
private static String APK_CONTENTTYPE = "application/vnd.android.package-archive";
//PNG文件类型
private static String PNG_CONTENTTYPE = "image/png";
//JPG文件类型
private static String JPG_CONTENTTYPE = "image/jpg";
//文件后缀名
private static String fileSuffix="";
/**
* 写入文件到本地
* @param file
* @param body
* @return
*/
public static boolean writeResponseBodyToDisk(File file, ResponseBody body) {
Log.d(TAG, "contentType:>>>>" + body.contentType().toString());
//下载文件类型判断,并对fileSuffix赋值
String type = body.contentType().toString();
if (type.equals(APK_CONTENTTYPE)) {
fileSuffix = ".apk";
} else if (type.equals(PNG_CONTENTTYPE)) {
fileSuffix = ".png";
}
// 其他类型同上 需要的判断自己加入.....
//下面就是一顿写入,文件写入的位置是通过参数file来传递的
InputStream is = null;
byte[] buf = new byte[2048];
int len = 0;
FileOutputStream fos = null;
try {
is = body.byteStream();
long total = body.contentLength();
fos = new FileOutputStream(file);
long sum = 0;
while ((len = is.read(buf)) != -1) {
fos.write(buf, 0, len);
sum += len;
int progress = (int) (sum * 1.0f / total * 100);
}
fos.flush();
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
} finally {
try {
if (is != null)
is.close();
} catch (IOException e) {
}
try {
if (fos != null)
fos.close();
} catch (IOException e) {
}
}
}
}
上面的代码没啥需要注意的点,都挺基本的Android代码,硬要说的话,就注意一下ResponseBody这个类吧,导包的时候有很多,别导错了,要导入OKHTTP的包,因为Retrofit的底层就是OKHTTP,当时我在这里手快导错了,蒙了一下。
step3:接下来就是调用API下载写入文件了
我项目结构是MVVM,又使用了RXJava和Dagger2,看起来代码写的简单没多少,但是没用过的可能看不懂。那这里贴两份代码,一份我项目中的代码(强烈推荐这种写法,Retrofit结合RXJava来用不仅解决了线程安全问题而且特别简单),一份是OKHTTP原始的代码
项目是MVVM的,为下载的Activity创建一个ViewModel来执行下载的耗时操作,并在Activity中用Dagger2来注入该ViewModel对象
public class ElectronicImageSynthesisViewModel {
private IServiceApi mServiceApi;
@Inject
public ElectronicImageSynthesisViewModel(IServiceApi serviceApi){
mServiceApi = serviceApi;
}
//下载PDF文件
public Observable retrofitDownloadFile(String fileUrl) {
return mServiceApi.retrofitDownloadFile(fileUrl).subscribeOn(Schedulers.io()).observeOn(AndroidSchedulers.mainThread());
}
}
上面代码中注意一点(RXJava的内容)
要指定下载的线程与数据返回的线程:
subscribeOn(Schedulers.io()):在io线程中下载文件
observeOn(AndroidSchedulers.mainThread()):在UI线程中处理返回结果
public class ElectronicImageSynthesisActivity extends BaseActivity {
...
@Inject
ElectronicImageSynthesisViewModel mElectronicImageSynthesisViewModel;
/**
* pdf下载
*/
private void pdfDownLoad() {
mElectronicImageSynthesisViewModel.retrofitDownloadFile(mPDFDownloadUrl)
.map(new Function() {
@Override
public Boolean apply(ResponseBody responseBody) throws Exception {
return DownLoadManager.writeResponseBodyToDisk(mPDFSavedFile, responseBody);
}
}).subscribe(new Consumer() {
@Override
public void accept(Boolean aBoolean) throws Exception {
if (aBoolean) {
//这一步就是对你下载下来的文件进行你想要的操作了,我这里是展示PDF
displayFromFile(mPDFSavedFile);
}
}
}, new Consumer() {
@Override
public void accept(Throwable throwable) throws Exception {
//onError
showToast(throwable.getMessage());
}
});
}
...
}
上面代码是Retrofit和RXJava结合来使用的,代码看起来没多少行,很简洁。最让我喜欢的是它的链式结构,逻辑一目了然,而不是以往那种层层递进。
pdfDownLoad()的代码有很多东西需要讲,因为它涉及到RXJava了,我们这里重点是Retrofit下载,只挑一些重点来说明一下:
①.首先它调用了ViewModel里面的mElectronicImageSynthesisViewModel(),并给它传递了一个PDF的下载链接mPDFDownloadUrl
②.mElectronicImageSynthesisViewModel()方法返回的就是携带下载数据的Observable
③.这个Observable在RXJava中叫做被观察者,它的泛型就是下载的数据:ResponseBody,现在我们通过retrofitDownloadFile()返回了它,那么我们需要做的就是把它写入到手机本地
④.writeResponseBodyToDisk()就上场了,把我们定义的想要存储到手机哪里的文件File给它传递进去。我们只需要做的就是根据writeResponseBodyToDisk()返回的boolean值来判断文件到底写没写入成功:true-写入成功,false-写入失败。
⑤.这里就涉及到一个类型转换了,我们拿到的是ResponseBody,想要的却是写入成功与否的标记,RXJava就给提供了一个操作符:map
⑥.使用map操作符,实现里面的apply方法,在apply里面调用我们的writeResponseBodyToDisk(),把拿到的boolean值返回,ok,转换完成~
⑦.接下来就是accept中对下载好的文件进行操作了,判断下boolean,如果true怎么怎么样,false怎么怎么样。
⑧.最后一定要写new Consumer
以上简单了解~~
如果使用源生的OKHTTP,那就简单的多,直接调用下载:
OkHttpClient okHttpClient = new OkHttpClient.Builder().build();
Retrofit retrofit = new Retrofit.Builder()
.client(okHttpClient)
.baseUrl(baseUrl)
.build();
IServiceApi apiService = retrofit.create(IServiceApi.class);
Call call = apiService.retrofitDownloadFile(mPDFDownloadUrl);
call.enqueue(new Callback() {
@Override
public void onResponse(Call call, Response response) {
if (response.isSuccessful()) {
//下载成功,写入文件
boolean bl = DownLoadManager.writeResponseBodyToDisk(mPDFSavedFile, response.body());
if (bl) {
//这一步就是对你下载下来的文件进行你想要的操作了,我这里是展示PDF
displayFromFile(mPDFSavedFile);
}
} else {
//下载失败
}
}
@Override
public void onFailure(Call call, Throwable t) {
//下载失败
}
});
上面的代码只涉及到Retrofit下载,就没啥干货可以讲,用法也很简单。不过大家可以看到两种写法的区别,先不说链接逻辑和层层递进逻辑上的区别,光这个代码量和排版就不讨人喜欢。所以还是推荐大家学习一下RXJava,虽然入门挺难,但是用熟了你会发现有很多惊喜,太棒了~
误区
在这里记录我遇到的坑或者使用错误的地方:
①:一开始我理解的是GET请求一定要用@Path注解,POST请求一定要用@Query注解,但这是错误的。@Path、@Query具体怎么用要看具体的Url形式。
特别感谢以下作者,让我从一个不会Retrofit的小白成长到会使用这个网络框架的程序猿,这篇文章也是在这几篇博文基础上总结了下自己的理解:
Retrofit分析-漂亮的解耦套路
Android retrofit 注解@QueryMap和@Body的区别
这是一份很详细的 Retrofit 2.0 使用教程(含实例讲解)
Retrofit 2.0 超能实践(四),完成大文件断点下载