深入理解Java虚拟机----(九)程序编译和代码优化
早期优化

优化技术
javac
把.java文件编译为class文件的这个编译过程,几乎没做什么优化,几乎将优化都放到了后端的即时编译器中,这样是为了其他非javac编译的程序也能享受到优化的待遇。但javac给我们提供了很多便于编程的语法糖,大大的方便了我们。可以说后端优化提高了运行效率,前端优化对于编码更加密切。
javac编译过程可大致分3步:
- 解析与填充符号表
- 插入式注解处理器的注解处理
- 分析与字节码生成:语义分析,保证代码符合逻辑。解语法糖是在这一步。
语法糖
- 泛型、类型擦除:本质是参数化类型的应用,也就是操作的数据类型被指定为一个参数。可以应用到类、接口、方法上。泛型其实是javac提供给我们的一颗语法糖,因为它在编译阶段采用类型擦除,将泛型还原为裸类型。r然后在适当的位置加入类型转换操作。例如:ArrayList
list在编译后,我们再反编译class文件,可以看到代码变成了ArrayList list。这是一种伪泛型。在c#中,List 和List 是完全不同的两个类型,是真实泛型,而在java中由于类型擦除,他们是相同的类型。所以,一个类中如果声明了两个方法void fun(List ) 和 void fun(List )是不能通过编译的,很显然,他们被类型擦出后,变成了相同参数类型。如果改成void fun(List ) 和 int fun(List ),就可以编译过了(JDK1.6以后)!返回值类型不是不参与重载么?价值观被颠覆了?其实返回值类型并没有参与重载,但是在Class文件格式中,只要描述符不是完全相同的方法就可以共存。后来为了获取参数化类型,虚拟机规范做了修改(JDK1.5),引入了Signature等解决泛型带来的参数类型识别问题。Signature就保存了参数化类型的信息。 - 自动拆装箱、遍历循环:
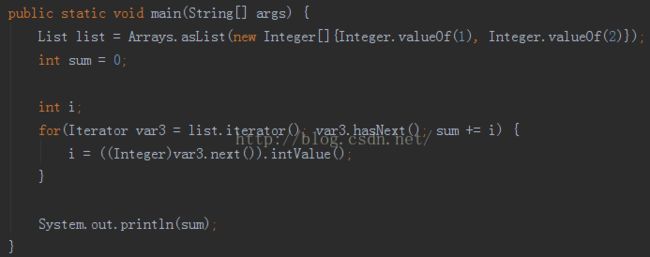
public static void main(String[] args) {这段代码用到了5各语法糖:可变长参数、拆箱、装箱、遍历循环、泛型。我们看一下,编译后再反编译的代码:
Listlist = Arrays.asList(1,2,3,4);
int sum = 0;
for(int i : list) {
sum += i;
}
System.out.println(sum);
}
List类型擦除了;可变长变成数组了;遍历循环改为iterator了;数字也拆装箱了。
一些不建议实际开发中的写法,作为思考很有趣,请看下面代码,说出运行结果:
public static void main(String[] args)throws InterruptedException {答案:
Integer a = 1;
Integer b = 2;
Integer c = 3;
Integer d = 3;
Integer e = 128;
Integer f = 128;
Long g = 3L;
System.out.println(c == d);
System.out.println(e == f);
System.out.println(c == (a+b));
System.out.println(c.equals(a+b));
System.out.println(g==(a+b));
System.out.println(g.equals(a+b));
}
truefalsetruetruetruefalse
我才一定有些答案出乎你的意料。因为我们很多内部的实现细节不是完全了解,所以会导致有些语句的结果和我们想想的不一样。所以,在没有十足的把握时,不建议这样写。说一下答案的解释,首先看这个方法反编译后的样子:
public static void main(String[] args) throws InterruptedException {
Integer a = Integer.valueOf(1);
Integer b = Integer.valueOf(2);
Integer c = Integer.valueOf(3);
Integer d = Integer.valueOf(3);
Integer e = Integer.valueOf(128);
Integer f = Integer.valueOf(128);
Long g = Long.valueOf(3L);
System.out.println(c == d);
System.out.println(e == f);
System.out.println(c.intValue() == a.intValue() + b.intValue());
System.out.println(c.equals(Integer.valueOf(a.intValue() + b.intValue())));
System.out.println(g.longValue() == (long)(a.intValue() + b.intValue()));
System.out.println(g.equals(Integer.valueOf(a.intValue() + b.intValue())));
}
变量a到f声明语句编译后自动装箱,
再看Integer的源码:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
public boolean equals(Object obj) {
if (obj instanceof Integer) {
return value == ((Integer)obj).intValue();
}
return false;
}
原来默认情况下是对-128到127之间的数做了缓存,所以c和d的valueof都返回了同一个缓存对象。而e和f不再缓存范围内,不是同一个对象。而==运算在不遇到算术运算的情况下不会自动拆箱,所以比较的是是不是同一个对象;下面有+运算,则拆箱判断值。
而equals方法不会处理类型转换,同类型则比较值,不同类型直接false。
- 条件编译:c++中的条件编译,在java中能否实现呢?答案是可以的,但是很有限,必须是if+常量的方式,必须是if!!!这也是语法糖,编译器会将if不成立的语法块过滤掉不编译。
晚期优化
Java程序通过解释器进行解释执行,当虚拟机发现一段代码被频繁的执行,,就把它认定为
热点代码(Hot Spot Code)。为了提高热点代码的执行效率,运行时会把这些代码编译成本地平台相关的机器码,然后进行优化。完成这个任务的叫
即时编译器JIT。
理解这个过程,需要搞清楚这么几个问题:
以HotSpot虚拟机为例
解释器与编译器
这各编译器是编译成本地机器码的编译器,下不冗述。编译器并不是必须的,规范中没有要求,但一般商业虚拟机中都有。他们各有作用,当需要快速启动时,解释器可以首先发挥作用,让程序迅速启动;随着时间推移编译器让越来越多的热点代码编译成机器码再优化,充分利用内存,使程序效率更高。编译器也有失误的时候,需要将热点代码退化,这时编译器还可以接收这个退货。他们之间就是这样配合的,这叫混合模式。
HotSpot中内置两个即时编译器:Client Compiler和Server Compiler,也叫C1和C2。使用哪个,取决于运行模式,也就是-client和-server参数指定的环境模式。还可以用参数强制虚拟机只用解释器或优先用编译器(这时解释器也要做替补队员)。JDK1.6又引入了分层编译策略,JDK1.7被改良作为了server模式的默认编译策略。它分为三层:
- 第0层,解释执行。不加入性能监控。
- 第1层,也称为C1编译。编译为本地代码,简单优化。可能加入性能监控。
- 第2层,也称为C2编译。编译为本地代码,进行一些耗时的深度优化,甚至激进优化。
编译对象和触发条件
热点代码有两类:多次调用的方法 和 多次执行的循环体。这两种情况,都是整个方法作为编译对象。那这里的多次是怎么判断出来的呢?有两种判定方式:
- 基于采样:定期检查各个线程的栈顶,发现一个方法经常出现,则是热点代码。优点:简单高效,可获得调用关系。缺点:不精确,可能因为阻塞等原因误判。
- 基于计数器:为每个方法维护计数器。优点:准确。缺点:不能获得调用关系。
- 方法调用计数器 :并不是绝对值,而是一段时间的相对值。如果一段时间内,次数仍不足以触发编译,则计数减少一半,称为热度衰减。而这个时间称为半衰期。如果超过阈值,则触发编译,但还是执行解释器,等虚拟机编译完成,讲方法入口改为编译后的地址,新的本地代码才被使用。
- 回边计数器:统计方法中循环体的执行次数。没有衰减,是绝对次数。触发阈值时,会将计数器值减小一些,以便先执行。这个编译被称为OSR编译。
优化技术
- 公共子表达式消除:如果一个表达式之前已经计算过了,并且参与者期间都没有发生变化,那该表达式就是公共子表达式,不需要再次计算。
- 数组边界检查消除:java是动态安全的,访问数组前会先判断下表是否越界,但每次运行都判断,未免浪费效率。编译器在编译期间如果确定不会越界,就省略判断,运行时就可以提高效率。还有一种思路,是不判断,而是等出异常再处理,对于大多数情况正常的代码,能提升效率。
- 方法内联:不只是消除了调用的消耗,主要是为其他优化提供了基础。
- 逃逸分析:如果能证明一个对象不会逃逸到方法或者线程外,就可以做很多优化。
- 栈上分配。方法中不会被外部引用的局部对象有很多,在栈帧上分配,随方法调用一起生死,降低堆垃圾清理压力。
- 同步消除:如果不会逃逸出线程,则可以消除同步操作。
- 标量替换:不能再拆分的基本类型就是标量,对象就是聚合量。如果一个对象不会被外部访问,那将可能不创建对象,而是用组成他的一些标量的集合代替它。拆分后,不仅可以让标量在栈上,还可以为后续优化做基础。