【Mybatis源码探索】 --- Mybatis查询过程核心源码解读 --- 先聊聊selectOne方法
文章目录
- 1 源码入口
- 2 sqlSessionFactory.openSession()源码分析
- 2.1 openSession方法 --- 获取SqlSession对象的骨架
- 2.2 Executor对象的创建 --- 真正与数据库打交道的其实是Executor
- 2.2.1 Executor对象创建源码解析
- 2.2.2 Executor介绍
- 3 Mybatis查询过程核心源码解读
- 3.1 selectOne方法 --- 组装查询条件并调用Executor查询数据
- 3.2 executor.query(...)方法 --- 2级缓存处理逻辑
- 3.3 delegate.query(...)方法 --- 1级缓存处理逻辑
- 3.4 queryFromDatabase(...)方法 --- 查询数据库,并将结果放到一级缓存
- 3.5 doQuery(...)方法 --- 获取真正与数据库交互的对象StatementHandler
- 3.5.1 StatementHandler介绍
- 3.5.2 将sql、请求参数设置到Statement对象 --- PreparedStatementHandler的情况
- 3.6 query(...)方法 --- 真正的与数据库进行交互
- 3.7 handleResultSets(...)方法---ORM的真谛 --- 将数据库获取结果解析为Java对象的底层原理
- 4 不做总结了
1 源码入口
本篇文章的源码入口如下(可参考上篇文章《【Mybatis源码探索】 — 开篇 • 搭建一个最简单的Mybatis框架》):
/***
* 快速入门1 --- ibatis的方式,其实Mybatis底层也用的这种方式
*/
@Test
public void quickStart1() {
// 2.获取sqlSession
SqlSession sqlSession = sqlSessionFactory.openSession();
// 3.执行查询语句并返回结果 -- 第二次查询会走缓存
TUser user = sqlSession.selectOne("com.nrsc.mybatis.mapper.TUserMapper.selectByPrimaryKey", 1);
TUser user2 = sqlSession.selectOne("com.nrsc.mybatis.mapper.TUserMapper.selectByPrimaryKey", 1);
// 4.关闭session
sqlSession.close();
log.info("user111:" + user);
log.info("user111:" + user2);
}
2 sqlSessionFactory.openSession()源码分析
这里要注意,上篇文章《【Mybatis源码探索】 — Mybatis配置文件解析核心源码解读》已经讲过Configuration对象是单例的,DefaultSqlSessionFactory也是单例的,而且创建DefaultSqlSessionFactory对象时其实将Configuration对象传了进去,也就是说DefaultSqlSessionFactory里是有Configuration对象的。
2.1 openSession方法 — 获取SqlSession对象的骨架
所在类:DefaultSqlSessionFactory
@Override
public SqlSession openSession() {
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
}
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
//从Configuration对象里拿出来Environment对象
final Environment environment = configuration.getEnvironment();
//获取事务工厂并新建一个事务管理器
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
//创建Executor对象 --- Executor对象是真正进行与数据库交互的执行器
final Executor executor = configuration.newExecutor(tx, execType);
//利用Configuration、Executor和autoCommit构建SqlSession对象
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
这里一定要记得,获取到的SqlSession对象封装了Configuration、Executor和autoCommit三个属性。
2.2 Executor对象的创建 — 真正与数据库打交道的其实是Executor
2.2.1 Executor对象创建源码解析
Executor的创建源码如下:
所在类:Configuration
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
//获取指定的Executor的类型,如果没指定,默认使用SimpleExecutor
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
//如果指定Executor的类型为BATCH,则使用BatchExecutor
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
//如果指定Executor的类型为REUSE ,则使用ExecutorType
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
//默认情况下使用SimpleExecutor
} else {
executor = new SimpleExecutor(this, transaction);
}
//判断一级缓存是否打开,默认情况下是打开的 ---> 可以通过Configuration对象的源码进行验证
if (cacheEnabled) {
//对获取的Executor进行包装 --- 使其具有一级缓存的能力,这里用到了装饰器模式
executor = new CachingExecutor(executor);
}
executor = (Executor) interceptorChain.pluginAll(executor);//与插件有关,不细究了
return executor; //返回创建好的Executor对象
}
2.2.2 Executor介绍
Executor的继承关系图如下:
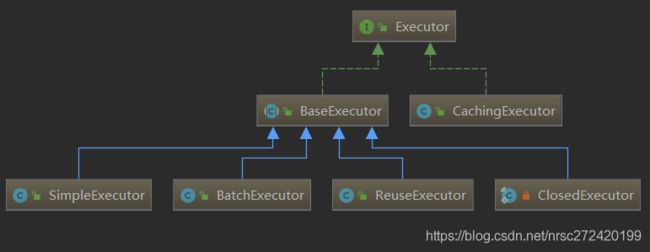
这里要说明的有三点
(1)由2.2.1中的源码可知,
真正与数据库打交道的三个Executor是BatchExecutor、ReuseExecutor和SimpleExecutor,而CachingExecutor的作用主要就是装饰这三个与数据库真正打交道的Executor,使其具有一级缓存的能力。
(2)BatchExecutor和ReuseExecutor与SimpleExecutor相比又有啥区别呢???其实很简单:
- BatchExecutor封装了JDBC批量执行sql的具体实现 —
即Statement的executeBatch方式- ReuseExecutor可以复用Statement对象
(3)其实一眼就可以看出来BaseExecutor和BatchExecutor、ReuseExecutor和SimpleExecutor使用到了策略+模版模式。还有通过源码可知:Executor的属性大多都在BaseExecutor里。
3 Mybatis查询过程核心源码解读
3.1 selectOne方法 — 组装查询条件并调用Executor查询数据
所在类:DefaultSqlSession
@Override
public <T> T selectOne(String statement, Object parameter) {
// Popular vote was to return null on 0 results and throw exception on too many.
List<T> list = this.selectList(statement, parameter);//真正去查询数据
if (list.size() == 1) {
return list.get(0); //因为调用的是selectOne,所以查询结果为1个时才正常返回
} else if (list.size() > 1) {
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}
@Override
public <E> List<E> selectList(String statement, Object parameter) {
//真正去查询数据 --- 注意这里多了一个参数RowBounds.DEFAULT
return this.selectList(statement, parameter, RowBounds.DEFAULT);
}
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
//从Configuration对象里获取到MappedStatement,
//上篇文章讲过MappedStatement就是解析select、 insert、update、delete标签封装的对象
MappedStatement ms = configuration.getMappedStatement(statement);
//调用Executor进行与查询 --- 注意这里的最后一个参数为Executor.NO_RESULT_HANDLER即null
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
3.2 executor.query(…)方法 — 2级缓存处理逻辑
因为我没有强制不使用一级缓存,所以调用的Executor肯定是包装了SimpleExecutor的CachingExecutor,其源码如下:
所在类:CachingExecutor
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
//获取与sql绑定相关的对象
BoundSql boundSql = ms.getBoundSql(parameterObject);
//创建一级缓存的key --- 这里我会再写一篇文章,因为项目里在这遇到过坑
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
//真正去查询数据
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
//真正去查询数据的方法
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
//从MappedStatement对象里获取二级缓存
//由于每一个MappedStatement都存在Configuration对象里,
//所以可以说二级缓存也存在于Configuration对象里
Cache cache = ms.getCache();
//如果二级缓存里有,从缓存里拿值
// 第一次肯定拿不到,假如不开启二级缓存,这里肯定就一直拿不到
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key); //获取到二级缓存的对象
if (list == null) { //如果拿不到二级缓存中缓存的对象,查询数据库,并把查询结果放到二级缓存
//带着获取的一级缓存的key去查询数据---delegate是具体与数据库打交道的Executor
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list; //返回查到的数据
}
}
//带着获取的一级缓存的key去查询数据---delegate是具体与数据库打交道的Executor
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
从这段代码中至少可以得到如下两个结论:
(1)如果二级缓存和一级缓存都开启了,会先去二级缓存里拿数据
(2)二级缓存存在于Configuration对象里
3.3 delegate.query(…)方法 — 1级缓存处理逻辑
所在类:BaseExecutor
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
//根据一级缓存key去一级缓存里拿一级缓存的数据
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) { //如果拿到了 --> 处理本地缓存的输出参数 -->不细究了
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else { //如果没拿到缓存数据,则去查库
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear(); //如果指定缓存为STATEMENT级别的,则清空缓存
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
从这段代码中至少可以得到如下两个结论:
(1)一级缓存存在于BaseExecutor对象里, 或者更直接点说一级缓存是SqlSession级别的(这里结合一下2.1肯定就明白我说的是什么意思了)。
(2)在一次SqlSession里查询完数据不会清空一级缓存,除非指定一级缓存级别为STATEMENT级别。
3.4 queryFromDatabase(…)方法 — 查询数据库,并将结果放到一级缓存
所在类:BaseExecutor
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//真正去查询数据库
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
localCache.putObject(key, list); //将查询的结果放入到一级缓存
//存储过程相关,不细究了
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list; //返回从数据库查询到的数据
}
3.5 doQuery(…)方法 — 获取真正与数据库交互的对象StatementHandler
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration(); //获取Configuration对象
//将wrapper(即Executor)、ms、parameter等属性都封装到StatementHandler对象里
//注意这里也用到了装饰器模式,获取的handler也是经过包装的
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
//获取Statement对象
stmt = prepareStatement(handler, ms.getStatementLog());
//去具体的handler里进行真正的查询
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt); //销毁掉Statement对象
}
}
3.5.1 StatementHandler介绍
实际上真正与数据库打交道的类是StatementHandler对象,它的继承关系图如下:
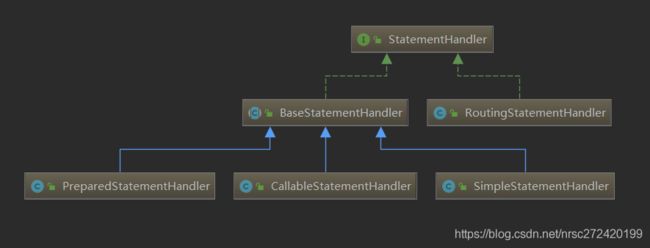
可以看到跟Executor如出一辙。需要注意的有以下几点
(1)默认情况下使用PreparedStatementHandler —> 使用的Statement为PreparedStatement —> 可防止sql注入
(2)在mapper.xml里配置了当前语句的statementType="STATEMENT"时,使用SimpleStatementHandler —> 会有sql注入的风险
(3)在mapper.xml里配置了当前语句的statementType="CALLABLE"时使用CallableStatementHandler —> 不细究
(4)RoutingStatementHandler是一个装饰器,里面封装了一些方法
(5)由3.5中的源码可以看出StatementHandler应该包含wrapper, ms, parameter, rowBounds等参数对应的属性 —> 这些属性其实都封装在了模版类BaseStatementHandler里,这些属性以及通过handler.query(stmt, resultHandler);方法传入StatementHandler对象的两个参数是真正与数据库打交道的关键。
3.5.2 将sql、请求参数设置到Statement对象 — PreparedStatementHandler的情况
stmt = prepareStatement(handler, ms.getStatementLog());语句对应的源码:
所在类:SimpleExecutor
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
//获取Connection对象 --- 数据库连接对象
Connection connection = getConnection(statementLog);
//创建Statement对象,默认情况下使用PrepareStatementHandler,此时还会将sql放到Statement对象里
//且此时的Statement对象实际上是PrepareStatement
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt); //如果使用PrepareStatementHandler时会将请求参数设置到Statement对象里
return stmt;
}
注意: 我上面的注释,对于当使用的是StatementHandler时,其实不会将sql放到Statement对象里,且也不会在这里向Statement里设置参数 —>其实这就体现出来PrepareStatement所谓的预编译了....—> 具体逻辑有兴趣的自己看吧。
3.6 query(…)方法 — 真正的与数据库进行交互
由于我没指定statementType的类型,所以这里会经RoutingStatementHandler代理,真正调用PreparedStatementHandler中的query()方法,其源码如下:
这里省去了RoutingStatementHandler转发的过程
所在类:PreparedStatementHandler
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
//第一步就是将Statement 对象转为PreparedStatement
PreparedStatement ps = (PreparedStatement) statement;
ps.execute(); //前面已经将sql,请求参数设置到Statement对象里了,这里可以直接执行查库操作了
return resultSetHandler.handleResultSets(ps); //解析查询结果
}
3.7 handleResultSets(…)方法—ORM的真谛 — 将数据库获取结果解析为Java对象的底层原理
所在类:DefaultResultSetHandler
@Override
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
final List<Object> multipleResults = new ArrayList<>();
int resultSetCount = 0;
//具体讲解看文末的图片
ResultSetWrapper rsw = getFirstResultSet(stmt);
//-------------将从数据库获取的数据封装为具体的对象(这里也不往下细跟了)---------------------
//获取要返回对象的类型集合
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
ResultMap resultMap = resultMaps.get(resultSetCount);
//正常情况下这句话就已经活得到了返回结果
handleResultSet(rsw, resultMap, multipleResults, null);
//执行下一个Statement语句,这个应该与BatchExecutor有关
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
//-------------将从数据库获取的数据封装为具体的对象(这里也不往下细跟了)--------------------
//---------------------------(好像一直没走下面的if语句)不细究了--------------------------
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
//---------------------------不细究了-----------------------------------------------
return collapseSingleResultList(multipleResults);
}
ResultSetWrapper rsw = getFirstResultSet(stmt);这句话获取到的结果如下图所示:
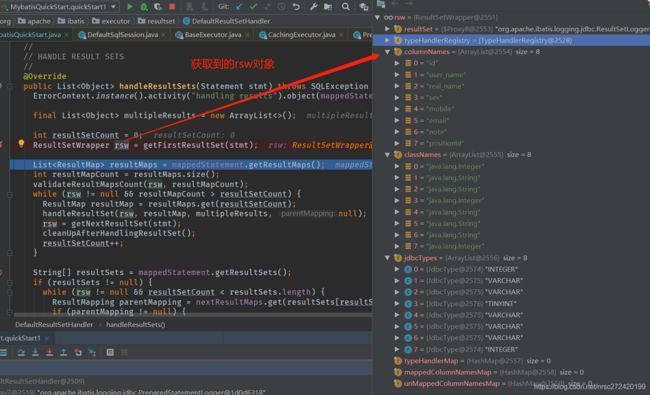
也就是说这句话拿到了从数据库里查询到的数据在数据库里的类型,以及要映射的对象的字段和字段的类型。接下来就可以创建要映射的对象,并将查询到的数据一个个的set到该对象里进行返回了 — 我想这应该就是ORM的真谛了。。。
这里看一下handleResultSet(rsw, resultMap, multipleResults, null);这句话执行后的效果:
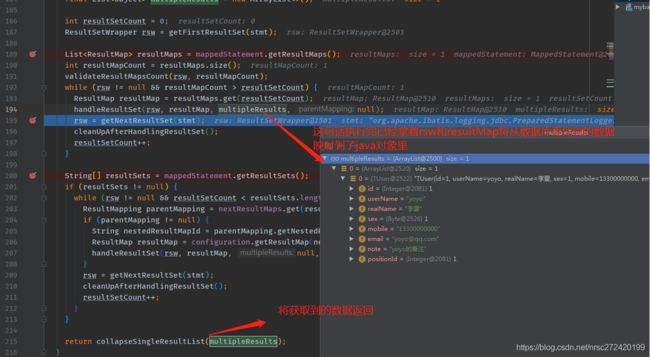
4 不做总结了
本篇文章探索了selectOne方法执行的核心源代码,其实Mybatis的mapper调用方式底层原理也是如此。据说Google的工程师看到ibatis的调用方式竟然是这样的:
TUser user = sqlSession.selectOne("com.nrsc.mybatis.mapper.TUserMapper.selectByPrimaryKey", 1);
然后一看太不优雅了,所以对ibatis进行了再次封装,然后就可以按照如下的方式进行开发了:
/***
* mybatis的方式
*/
@Test
public void quickStart2() {
// 2.获取sqlSession
SqlSession sqlSession = sqlSessionFactory.openSession();
// 3.获取对应mapper
TUserMapper mapper = sqlSession.getMapper(TUserMapper.class);
// 4.执行查询语句并返回结果
TUser user = mapper.selectByPrimaryKey(1);
//5.关闭session
sqlSession.close();
log.info("user222:" + user);
}
这肯定相比于ibatis的方式优雅多了。。。
之后的文章会对这种方式的源码进行探索!!!