从入门到入土 Hadoop新手搭建(2) 分布式集群搭建
个人学习笔记,仅供参考
从入门到入土 Hadoop新手搭建(2) 分布式集群搭建
(1)JDK安装
Hadoop基于JAVA,要运行JAVA必然要先安装java。按照我上一篇的指南这样做的话,现在就可以打开xshell进行连接。在xshell中,我们运行java -version查看java版本,如果我没记错的话,java要1.6以上,按照我的流程走的话,现在是没有安装java的,如图
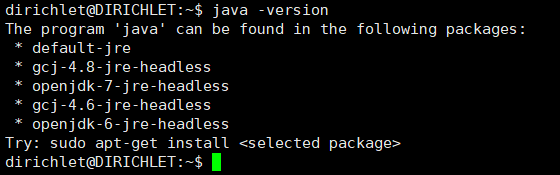
然后,我们在上一篇已经完成换源了,所以我们现在安装java会很快,运行后来在使用pyspark时,实测报错,需要用java1.8,所以此处运行sudo apt-get install default-jdk 安装就可以了。sudo apt-get install openjdk-8-jdk ,安装之后再次输入java -version,可以看到java版本
 然后设置JAVAHOME等系统环境,查看java路径在哪
然后设置JAVAHOME等系统环境,查看java路径在哪

不想钻研的话,只要操作和我一样那么路径也是和我一样的,可以看到java路径是/usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
(2)相关环境准备
将要构建一个分布式的集群,设计是这样的,一个master虚拟机,作为NameNode和ResourceManager,相当于管理员的身份,一个或是多个虚拟机,作为DataNode和NodeManager。
然后集群中应当有各种功能,为了避免重复下载和配置,我们把相关环境包下载到当前虚拟机,后面通过复制虚拟机来达到避免节点重复配置的目的。这里要有的包有Hadoop,Hive,Hbase,Zookeeper,spark。到里面会细讲。
1.Hadoop
进入Hadoop官网,查找最新的hadoop版本,这里直接给出下载页面,可以看到有源码和二进制版本,我们就不自己编译了,所以选择二进制版本的最新版本,(此处可以选择hadoop3+,按道理确实是版本越新越好,但我手头的资料全是2的,加上老师要求也是2,所以我这里下载了2的最新版)注意此处下载需要点下面的mirror site这样可以匹配镜像,下载会快,
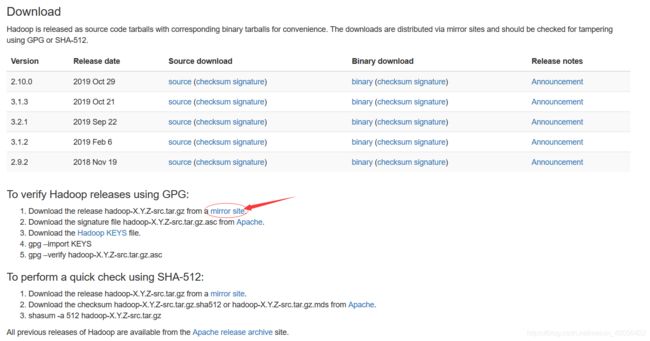
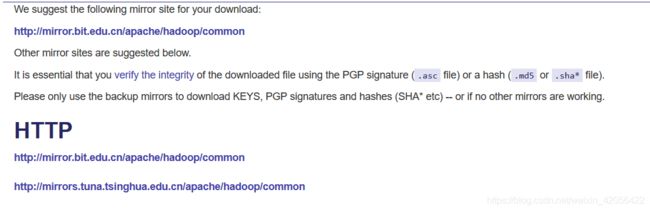
稍作等待,就会出现,其中粗体蓝字都是推荐的镜像,可以选一个,进入,当然这里也直接给出地址
北京理工源
清华源
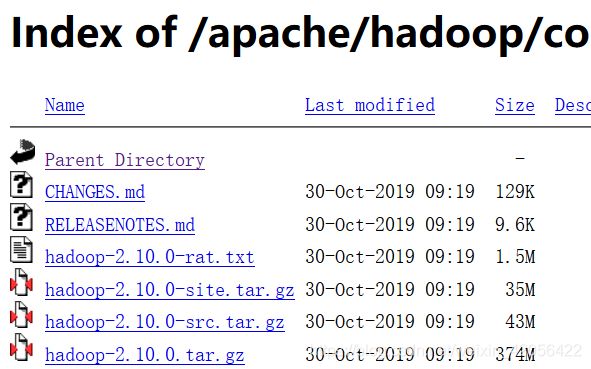
进入之后选择版本,我选择2.10,然后右键最后一行的374MB的文件,复制链接地址,得到http地址
http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.10.0/hadoop-2.10.0.tar.gz
 回到xshell ,输入
回到xshell ,输入wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.10.0/hadoop-2.10.0.tar.gz 等待下载完成即可。
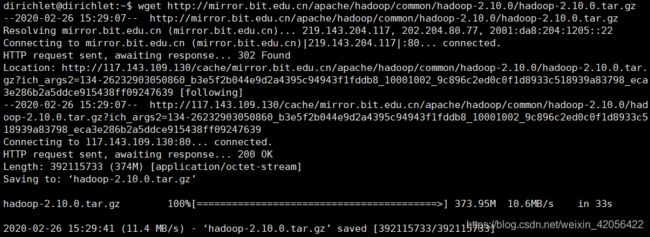 之后
之后 tar -zxvf hadoop-2.10.0.tar.gz 进行解压,并更名mv hadoop-2.10.0 hadoop。
更新
hadoop在不同情况下适应也不同,笔者在使用时需要spark上运行hive,可以选择自己编译,但是厦大林子雨老师给出了hadoop2.7和spark2.1.0的编译完成的包,所以此处还是建议用hadoop2.7.7,这样可以免去自己编译的好几个小时的时间
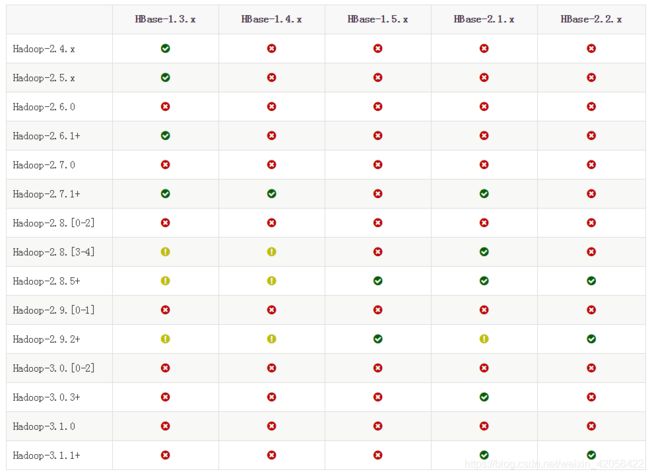
2.HBase
大同小异 找到地址下载解压 ,更名
hbase自带zookeeper,免去了下载
wget http://mirror.bit.edu.cn/apache/hbase/2.2.3/hbase-2.2.3-bin.tar.gz
tar -zxvf hbase-2.2.3-bin.tar.gz
mv hbase-2.2.3 hbase
3.Spark
同理 但是此处需要注意spark有许多版本,有自带hadoop的版本,我也没试过,但是我们已经安装了hadoop,所以选择下载Pre-built with user-provided Apache Hadoop,这个版本的spark自带scala,免去了下载
wget https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.5/spark-2.4.5-bin-without-hadoop.tgz
tar -zxvf spark-2.4.5-bin-without-hadoop.tgz
mv spark-2.4.5-bin-without-hadoop spark
更新
hadoop在不同情况下适应也不同,笔者在使用时需要spark上运行hive,可以选择自己编译,但是厦大林子雨老师给出了hadoop2.7和spark2.1.0的编译完成的包,所以此处还是建议用已经编译完成的包,这样可以免去自己编译的好几个小时的时间,链接
4.Hive
hive这里改用MySQL数据库保存Hive的元数据,还需安装mysql
先sudo apt-get install mysql-server
然后sudo cat /etc/mysql/debian.cnf查看密码
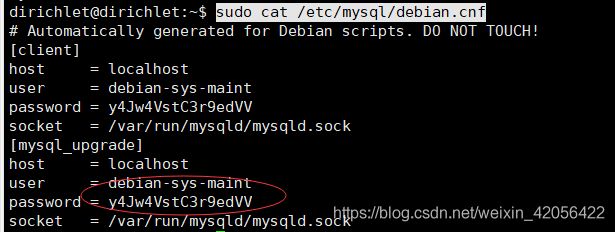 复制密码 之后
复制密码 之后mysql -u debian-sys-maint -p,输入刚刚的密码,进入shell,
修改成自己想要的密码,之后就可以使用自己想要的密码了
use mysql;
update mysql.user set authentication_string=password('root') where user='root' and Host ='localhost';
update user set plugin="mysql_native_password";
flush privileges;
quit;
下载hive 解压改名,
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-2.3.6/apache-hive-2.3.6-bin.tar.gz
tar -zxvf apache-hive-2.3.6-bin.tar.gz
mv apache-hive-2.3.6-bin hive
(3)环境构建+安装
先分析master和普通机器的区别,以便复制的时候进行最少操作
- IP设置,静态ip设置显然要不同
- host设置,host设置相同,但是增加节点则需要修改
- 主机名,方便辨认主机名应当不同
- ssh无密码访问。
理论上来说,应当对于每一个独立的服务器生成私钥和公钥,公钥传给master,这样master可以访问所有普通节点。
当然也可以做成所有节点互通,master集成所有公钥之后,将公钥复制给所有的普通节点。
也有更取巧的方法,master生成公钥密钥后,以master为蓝本复制虚拟机,即可完成互相访问。 - 环境变量,master和普通节点的环境变量设置应当是一样的。
- 除了Hive只需安装在master以外,其他组件可以完全复制。
现在要建立一个源节点,之后所有的节点都从这个源节点复制而来
源节点任务清单(按组件分的):
- 与组件无关的任务,如host,ssh
- hadoop
修改core-site.xml 、hdfs-site.xml、mapred-site.xml 、yarn-site.xml、hadoop-env.sh、配置slaves、配置环境变量 - HBase
修改hbase-site.xml、regionservers,配置环境变量 - Spark
修改spark-env.sh、slaves,配置环境变量。
注意到每一个都要配置环境变量,那么我们优先把环境变量都配置掉。
组件无关的构建
ip和主机名因为每一个复制都需要更改,所以不用改动。
host
sudo vi /etc/hosts
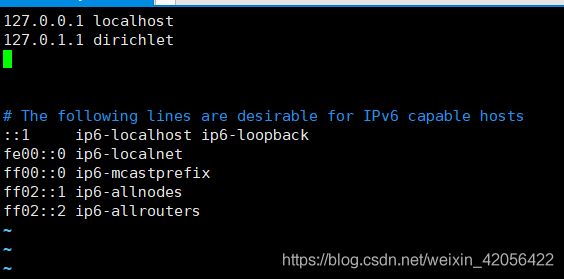 改成
改成
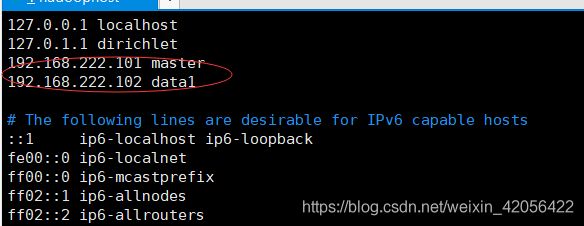 分别写上自己将要构建的主机的ip,我只构建两个,所以只多写两行。
分别写上自己将要构建的主机的ip,我只构建两个,所以只多写两行。
ssh无密码访问
bashssh-keygen -t rsa
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
之后尝试ssh localhost,如果配置成功则不需要输入密码,只需输入y加回车即可连上。
环境变量
输入sudo vi /etc/profile,在文件底部增加
此处JAVAHOME就是前面的java的路径去掉bin
后面的几个组件路径就是组件更名之后的路径,看你解压在什么地方
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/home/dirichlet/hadoop
export PATH=$PATH:/home/dirichlet/hadoop/bin:/home/dirichlet/hadoop/sbin
export HBASE_HOME=/home/dirichlet/hbase
export PATH=$HBASE_HOME/bin:$PATH
export HBASE_MANAGES_ZK=true
export SPARK_HOME=/home/dirichlet/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export HIVE_HOME=/home/dirichlet/hive
export PATH=$PATH:$HIVE_HOME/bin
保存之后source /etc/profile,令其生效,然后依次打入以下代码进行hadoop和hbase的环境变量测验
hadoop version
hbase version
Hadoop配置
cd ~
vi hadoop/etc/hadoop/core-site.xml
把原来的
变成
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/dirichlet/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
hadoop.tmp.dir指临时文件夹,如果不修改则可能会被系统清理。
接着vi hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/dirichlet/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/dirichlet/hadoop/tmp/dfs/data</value>
</property>
</configuration>
dfs.replication是副本数量,dfs.namenode.name.dir是namenode存放数据的地址,datanode同理。注意此处写了两个,事实上在本次实验,无论是datanode还是namenode都只需一个,在复制虚拟机之后进行修改。
vi hadoop/etc/hadoop/mapred-site.xml
mapred-site.xml 用于设置监控Map与Reduce程序的JobTracker任务分配情况。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
vi hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>10240</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
vi hadoop/etc/hadoop/hadoop-env.sh
文件开始处加上
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre
export HADOOP_HOME=/home/dirichlet/hadoop
export PATH=$PATH:/home/dirichlet/hadoop/bin
vi hadoop/etc/hadoop/slaves
去掉localhost,在里面添加普通节点,我这里的话写上data1
HBase配置
vi hbase/conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,data1</value>
</property>
<property>
<name>hbase.temp.dir</name>
<value>/home/dirichlet/hbase/tmp</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/dirichlet/hbase/tmp/zookeeper</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
</configuration>
vi hbase/conf/regionservers
删除localhost,填上master和data1
vi hbase/conf/hbase-env.sh
也是在开头加上
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre
export HBASE_HOME=/home/dirichlet/hbase
export PATH=$PATH:/home/dirichlet/hbase/bin
export HBASE_MANAGES_ZK=true
Spark配置
vi /home/dirichlet/spark/conf/spark-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre
export SCALA_HOME=/usr/local/scala
export HADOOP_CONF_DIR=/home/dirichlet/hadoop/etc/hadoop
export HADOOP_HDFS_HOME=/home/dirichlet/hadoop
export SPARK_HOME=/home/dirichlet/spark
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_HOST=master
export SPARK_WORKER_CORES=2
export SPARK_WORKER_PORT=8901
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=2g
export SPARK_DIST_CLASSPATH=$(/home/dirichlet/hadoop/bin/hadoop classpath)
export SPARK_MASTER_WEBUI_PORT=8079
执行
source spark-env.sh
vi /home/dirichlet/spark/conf/slaves
写上
master
data1
至此源虚拟机搭建完毕,
master构建
源虚拟机关机,完整克隆一个取名master,并开机。
IP
此时要先设置ip,因为ip即将变动,所以先不用xshell
主机名
sudo hostname master
sudo vi /etc/hostname
hadoop配置
因为之前有说hdfs-site.xml配置其实多了,现在在datanode里面删去namenode的配置,在namenode里面删去datanode配置。
data1构建
同上,可以在xshell里面用master的shell,执行ssh data1来转到data1的shell,想要回到master的shell,只要执行logout即可。
集群正式搭建
在master执行hdfs namenode -format,如果出现以下输出则为配置成功。
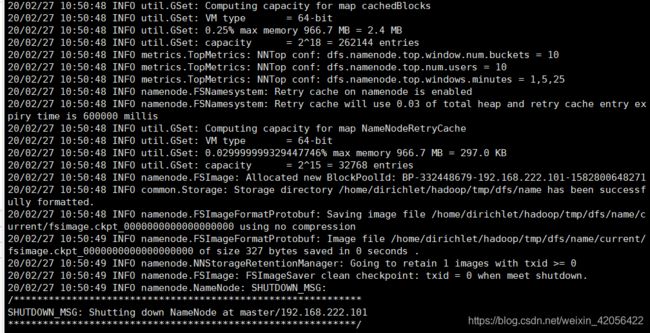 在master执行
在master执行start-all.sh,图片如下
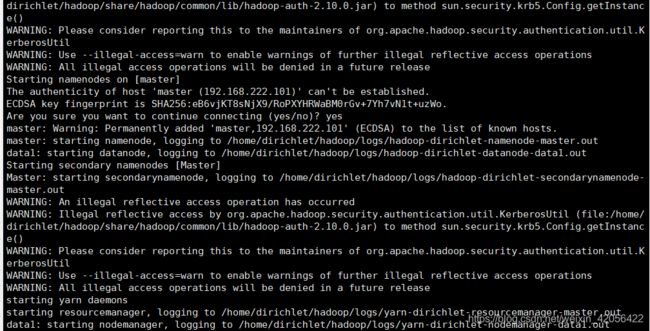 在master上执行
在master上执行jps会得到
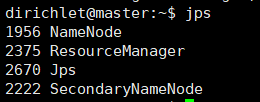
在data1上执行jps会得到
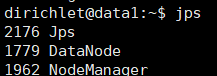
如果都启动了,则为启动成功,当然web界面也可以看到,在自己主机上用浏览器打开http://192.168.222.101:50070也可以看到启动的data节点。
现在hadoop中的hdfs已经启动完成
之后再检测spark安装是否成功。
cd spark/sbin
./start-all.sh
如果启动成功则可以在自己的主机浏览器上输入192.168.222.101:8079查看sparkWEB,
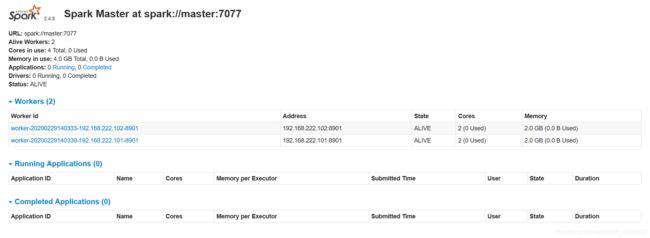 如图所示,则spark也启动成功
如图所示,则spark也启动成功