本来这篇文章该在去年11月底写出来的,被各种繁杂的事情所烦扰,再者网络上也有非常多比较完善的配置的文章,但是依旧是表述不太清晰。依旧写个Step By Step的教程,留待己用。
Hadoop的部署环境是经过虚拟化之后的四台主机,OS是Ubuntu Server10.04。(XenServer5.6兼容的OS并不包括Ubuntu,将Ubuntu转成PV也是一个折腾的过程,另文介绍)。Hadoop的版本号依旧是:0.20.2.安装Java环境如上一讲所示。
主机名及其IP地址对应如下:
Slave&TaskTracker:dm1,IP:192.168.0.17;(datanode)
Slave&TaskTracker:dm2,IP:192.168.0.18;(datanode)
Slave&TaskTracker:dm3,IP:192.168.0.9;(datanode)
Master&JobTracker:dm4,IP:192.168.0.10;(namenode)
Master是Hadoop集群的管理节点,重要的配置工作都在它上面,至于它的功能和作用请参考HadoopAPI。
具体配置步骤如下:
一.修改各个节点(dm1-dm4)的HostName,命令如下:
Vi /etc/hostname
如下图所示例:

二.在host中添加机器的hostname和IP,用以通讯。Master需要知道所有的slave的信息。对应的slave只需要知道Master和自身的信息即可。
命令如下:
vi /etc/hosts
Master(dm4)的hosts配置应该如下图所示:
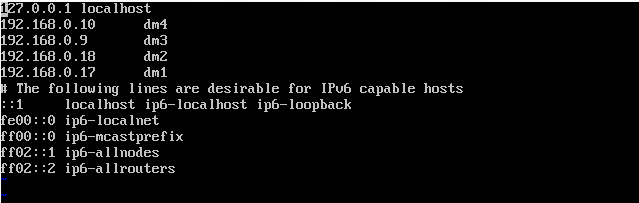
其它的slave(dm3……)的hosts配置应该如下图所示:

三.Hadoop核心代码需要配置conf文件夹里面的core-site.xml,hdfs-site.xml,mapread-site.xml,mapred-site.xml,hadoop-env.sh这几个文件。具体各个配置的含义请参考Hadoop帮助文档。
1.首先编辑各个机器节点(包括master和slave)的core-site.xml文件,命令如下:(Hadoop 文件夹放在home下)
vi /home/hadoop/conf/core-site.xml
core-site.xml文件配置,应如下面代码所示:
fs.default.name
hdfs://dm4:9000
2.其次编辑各个机器节点(包括master和slave)的hdfs-site.xml,命令如下:
vi /home/hadoop/conf/hdfs-site.xml
hdfs-site.xml文件配置,应如下面代码所示:
dfs.name.dir
/home/hadoop/NameData
dfs.permissions
false
dfs.replication
1
3.再次,编辑各个机器节点(包括master和slave)mapred-site.xml文件,命令如下:
vi /home/hadoop/conf/mapred-site.xmlmapred-site.xml文件配置,应如下面代码所示:
mapred.job.tracker
192.168.0.10:9001
4.最后,编辑各个机器节点(包括master和slave) hadoop-env.sh文件,命令如下:
vi /home/hadoop/conf/hadoop-env.sh向该文件加入几行代码,如下所示:
export HADOOP_HOME=/home/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/conf
export PATH=$PATH:$HADOOP_HOME/bin
四.配置集群的主从关系。在所有机器节点上,Hadoop的conf文件夹中,都有slaves和masters两个文件。往masters中添加Master(dm4)的IP地址或者hostname。往slaves文件中添加Slave(dm1-dm3)的IP或hostname。所有节点都需要修改。
Masters如下图所示:
![]()
slaves如下图所示:

行文至此,Hadoop的整体安装和配置已经完成。Hadoop集群的启动从Master(Namenode)机器开始,它和slave(DataNode)之间通讯使用ssh,我们接下来需要设置ssh无密码公钥认证登入。
五.SSH非对称密钥的原理请参见此文和彼文。首先要在所有节点生成密钥对,具体实现步骤如下:
1.所有节点生成RSA密钥对,命令如下:
ssh-keygen -t rsa
出现如下图所示:
![]()
直接回车,密钥对存放为/root/.ssh/id_rsa。在该文的演示中生成/root/viki.pub然后会要求你输入密码,选择空
![]()
最后生成如下图:

2.将Master(Namenode)生成的公钥viki.pub的内容复制到本机的 /root/.ssh/ 的authorized_keys 文件 里。命令如下:
cp viki.pub authorized_keys然后,将authorized_keys 文件复制到各个slave(DataNode)机器的 /root/.ssh/ 文件夹,命令如下:
scp /root/.ssh/authorized_keys dm3:/root/.ssh/
最后,在所有机器执行用户权限命令chmod,命令如下:
chmod 644 authorized_keys
经过以上步骤,ssh配置也已完成。通过以下命令验证:
ssh dm3
exit
ssh dm2
exit
ssh dm1
exit
第一次连接需要密码,输入yes和机器密码就可以。以后即不用再输入。
六.启动并验证Hadoop集群,如同上讲所述。输入:http://192.168.0.10:50030/jobtracker.jsp
在下所搭建的Hadoop集群截图:

七.参考文献
1.Hadoop快速入门 http://hadoop.apache.org/common/docs/r0.18.2/cn/quickstart.html
2.通用线程: OpenSSH 密钥管理
http://www.ibm.com/developerworks/cn/linux/security/openssh/part1/index.html