从入门到入土 大数据学习(4) 最简单windows下idea运行调试spark程序
从入门到入土 大数据学习(4)windows下idea运行spark程序
继环境搭建和windows环境搭建之后,不可避免的需要在windows上进行开发,但是这种跨平台的开发本身就给开发者带来一定的难度。如果条件允许(指电脑内存足够大,且今后开发服务器上也会有LINUX图形化界面的情况),个人还是建议使用图形化界面,在windows上开发,笔者真的捣鼓了很久。
网上常见的windows上连接spark开发是使用idea本身自带远程,打开5005端口进行调试,还是比较复杂的,有兴趣的可以百度。
这里介绍一种自己捣鼓的方法,前提要求:
- 主机和虚拟机已经能互相访问(笔者使用了NAT,将主机映射到一个ip)
- spark环境已经完成搭建,且能正常运行
导入类库
因为windows上没有相关类库,所以要导入相关类库,笔者将之前下载在linux上还未解压的hadoop、spark压缩包都复制到了主机上,并且解压。
- 打开idea,File-Project Structure
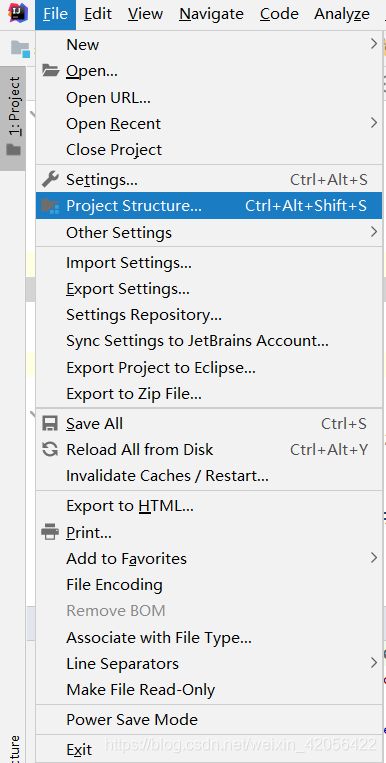
- 选择libraries,并选择加号,JAVA
- 选择相关类库
其中hadoop的库,在hadoop解压目录下share-hadoop下的所有文件夹和share-hadoop-common-lib
spark的类库在spark目录下jars目录下
只要选择以上的目录添加即可。
设置输出级别
在此后的实验里面会看到一大堆INFO,从而找不到输出,这不是我们希望的,所以将spark/conf目录下log4j.properties.template复制到src-main-scala-temp-resources目录下,并更名为log4j.properties,打开修改第19行
log4j.rootCategory=INFO, console
为
log4j.rootCategory=WARN, console
本地运行
很令人惊奇,spark居然能在windows上运行,不过想想也正常,spark开发语言是scala,里面调用了大量的java库 运行在jvm上,想来也有很好的跨平台性。
到这一步已经能够在windows上进行单机调试了,不涉及虚拟机里面的集群,笔者在src-main-scala-temp下建立了hello.scala
package temp
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object hello {
def main(args:Array[String]): Unit ={
val conf = new SparkConf().setAppName("app")
.setMaster("local")
val sc = new SparkContext(conf)
sc.parallelize(Array(1,2,3,4)).foreach(println)
}
}
其中setMaster可以设置为local[N],N为线程数,默认为1
那么本地的spark单机就已经能运行了
如果只做到这一步,这样可以在windows上先调试好再打包成jar放到虚拟机里面运行。适合单机测试。
集群运行
本质上还是使用jar进行打包上传,所以要先设置导出jar的设置
打开File-Project Structure,选择Artifacts,加号jar,
From modules with dependencies……
选择项目,选择主类,选择copy to the output directory and link via manifest
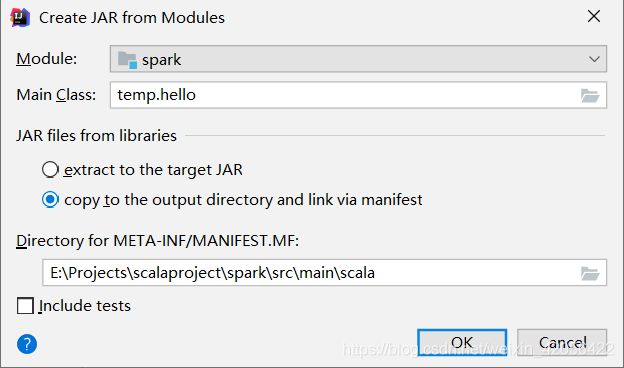 确认后 界面上会出现
确认后 界面上会出现
经过测试,还需要再列表中找到你导出的jar包
 点开后还会有一个别的东西,我这里是叫httpd,移除。如果不移除,输出的jar包里面会有一个Tomcat,凭空占好几十M,所以这里选择移除,我的图上已经移除了,所以看不到。
点开后还会有一个别的东西,我这里是叫httpd,移除。如果不移除,输出的jar包里面会有一个Tomcat,凭空占好几十M,所以这里选择移除,我的图上已经移除了,所以看不到。
在调整你需要的路径,就可以保存了。
这样每一次编译都会更新你输出目录下的jar包。
之后输入代码
package temp
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object hello {
def main(args:Array[String]): Unit ={
val conf = new SparkConf().setAppName("app")
.setMaster("spark://master:7077")
.set("spark.driver.host","192.168.222.3")
.setJars(Array("out/artifacts/spark_jar/spark.jar"))
val sc = new SparkContext(conf)
sc.parallelize(Array(1,2,3,4)).foreach(println)
}
}
此处 setMaster变为spark集群的地址,一般默认都是7077,具体要看之前的配置。
spark.driver.host是主机名的意思,如果不设置,会默认使用主机的主机名,但是主机的主机名一般是没有配置在集群之中的,所以直接用主机映射的ip地址。不设置会报无法连接到XXX,找不到主机名
setJars 设置运行的jar地址,也就是刚刚导出jar包的地址。
如果不设置,在某些运算上没有问题,如果只用到了一个服务器,运行起来没有问题,如果涉及并行,使用多个服务器,就会出现找不到class的错误,原因是,不设置,除了提交的节点,其他节点都找不到这个包,也就是没有分发到各个节点,从而导致报错。
设置之后
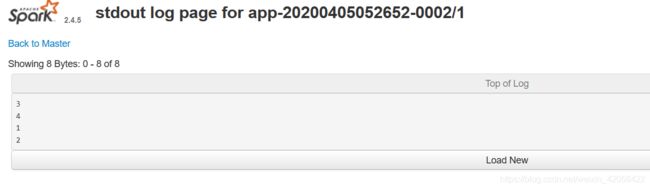
运行该程序后,会看到没有输出,打开spark的web界面,笔者配置的是http://master:8079,进入之后可以看到很多任务
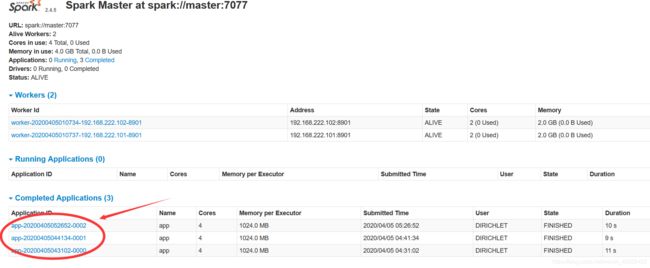 点击最新的任务,可以看到集群状态 和输入输出
点击最新的任务,可以看到集群状态 和输入输出
 依次点击stdout,会在其中一个里面看到想要的输出
依次点击stdout,会在其中一个里面看到想要的输出