计算机网络协议汇总-前人都说烂了
计算机网络协议汇总
- 前言
- 应用层
- http
- http请求报文
- http响应报文
- http cookie
- web缓存机制
- ftp
- DNS
- 域名四层结构
- DNS服务器解析流程
- DNS查询方式
- ddos了解一下
- DHCP
- P2P
- 种子文件
- socket套接字编程
- https是啥
- 传输层
- 传输层与下面的网络层关系
- 多路复用与多路分解
- 端口号
- UDP套接字
- TCP套接字
- UDP
- TCP
- 建立连接-三次握手
- 什么是半连接队列
- ISN是固定的么
- 三次握手过程中可以携带数据吗
- SYN攻击是什么
- 断开连接-四次握手
- 网络层
- 路由器
- 路由表
- 路由表分类
- 常见路由算法
- 分片重装
- 分片插入
- 分片重组
- IPV4与IPV6
- 防火墙
- 网关
- ICMP与ping
- 数据链路层
- 交换机
- arp协议
- arp攻击
- arp防御
- 代理arp
- 免费arp
- rarp与iarp
- 物理层
前言
这都烂大街的问题了,之前做项目的时候有做过有关tcp和udp的东西,但是都是直接用的人家封装好的协议栈(lwip),现在有时间了,我得回过头来认认真真学一遍。冲冲冲
应用层
应用层做了哪些事情呢?我们知道,网络通信的简单描述就是,进程将要传输的数据放到socket套接字中,然后接收方解析套接字中的数据。应用层所作的,就是规定什么时候用socket传输、如何解析socket、socket里承载的报文的类型啊、格式啊、各个字段的语义啊类似这种。
http
Web是一个应用,而Http是Web使用的一种应用层传输协议,可以理解吧?一个完整的HTTP协议包含两个部分,即客户端部分和服务端部分,而咱们用的web就是实现了HTTP客户端,咱们访问的就是实现了HTTP客户端的web服务器。(应该没那么绕对吧)下面是web与HTTP以及客户端服务端的关系图: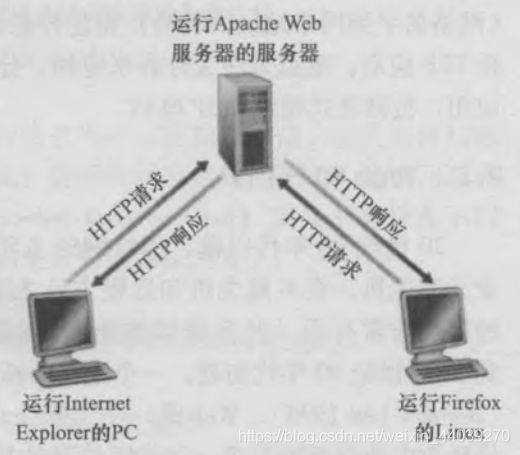
HTTP是web的核心协议,那么HTTP底层的传输层用的是什么协议呢?答案是面向可靠传输的TCP!!!
什么是持续连接?什么是非持续连接?也很简单,当你想通过HTTP请求多个数据时,一种方式是每次请求都申请建立连接,然后传输,然后断开连接;另一种则只建立一次连接,当数据全部请求完成后再断开连接。
http报文格式是啥呢?
http请求报文
一个HTTP请求报文由请求行(request line)、请求头部(header)、空行和请求数据4个部分组成
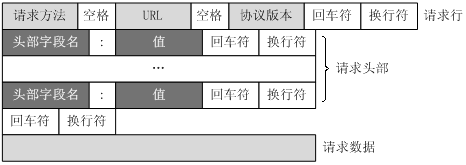
其中咱们重点介绍一下请求方法的类型(我就讲三类)
GET方法要求服务器将URL定位的资源放在响应报文的数据部分,回送给客户端。使用GET方法时,请求参数和对应的值附加在URL后面,利用一个问号(“?”)代表URL的结尾与请求参数的开始,传递参数长度受限制。例如,/index.jsp?id=100&op=bind 而且我们很明显可以看到,这样的GET传参是很没有隐私安全保障的,对吧。
为什么GET的url参数数量有限制呢?是http的一个规定么?其实和协议没关系,纯粹是浏览器或者是web服务器的锅。其中的一个原因是,为了性能和安全(防止恶意构造长 URL 来攻击)考虑,会给 URL 长度加限制。
HEAD就像GET,只不过服务端接受到HEAD请求后只返回响应头,而不会发送响应内容。当我们只需要查看某个页面的状态的时候,使用HEAD是非常高效的,因为在传输的过程中省去了页面内容。
POST本意是向指定的资源提交要被处理的数据,但是在使用上其实和GET的很多功能都是重复的。当然了,POST不像GET,它没有参数的限制,因为POST的参数是放在body里的。另外,POST在http协议里并没有规定将header和body分开发送,从而产生两个TCP数据包。这种事情是部分浏览器干的。
所以咱们总结一下,POST和GET在本质上是没什么区别的,不过在传参细节上有区别,一个是不安全且有限制的,另一个是安全且没限制的。(其实吧,这俩从传输的角度讲,都是不安全的,因为 HTTP 在网络上是明文传输的,只要在网络节点上捉包,就能完整地获取数据报文。要想安全传输,就只有加密,也就是 HTTPS。)
http响应报文
再说说http的回答报文。其实格式也很简单,与请求的格式很相似:
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行、响应正文。其中状态行里有一个Status-Code表示服务器发回的响应状态代码,它是个三位数,其中最高位1~5表示响应类型,咱们简单看看:
1xx:指示信息–表示请求已接收,继续处理。
2xx:成功–表示请求已被成功接收、理解、接受。
3xx:重定向–要完成请求必须进行更进一步的操作。
4xx:客户端错误–请求有语法错误或请求无法实现。
5xx:服务器端错误–服务器未能实现合法的请求
咱们的404 not found现在能理解了吧?再补充一个常见的:200 OK:客户端请求成功。
http cookie
看到cookie是不是觉得很熟悉?这个词你肯定不陌生,不过没想到这东西是http协议的一部分吧?嘿嘿嘿,咱们开始讲讲。
首先http请求是无状态的。啥意思呢?就是说,你哪怕连续发出两次http请求,对不起,第二次的时候服务器该不认识你就依旧还不认识你。cookie是做啥的呢?它就是存在于用户本地浏览器中的一小段文本,里面标记了用户的身份。每次咱们发起http请求的时候,连带着会把这段cookie也发送给服务器,这样一来不就每次访问就很方便了嘛!
那么cookie是如何从无到有产生的呢?其实也很简单,首先用户发起http请求,服务端收到以后,会生成这样的cookie记录,同时放在响应信息中发给客户端。等下次客户端再次发起http请求时,这个cookie就会附带进请求信息中。
如何看待cookie呢?这东西确实简化了很多http请求操作,但是它也将用户的关键信息暴露给web了,这就可能造成隐私泄露!!!
web缓存机制
Web缓存是指一个Web资源(如html页面,图片,js,数据等)存在于Web服务器和客户端(浏览器)之间的副本。缓存会根据进来的请求保存输出内容的副本;当下一个请求来到的时候,如果是相同的URL,缓存会根据缓存机制决定是直接使用副本响应访问请求,还是向源服务器再次发送请求。比较常见的就是浏览器会缓存访问过网站的网页,当再次访问这个URL地址的时候,如果网页没有更新,就不会再次下载网页,而是直接使用本地缓存的网页。只有当网站明确标识资源已经更新,浏览器才会再次下载网页。
ftp
ftp也是应用层协议之一,它就简单多了。首先它也是基于TCP这种可靠连接,只不过某个ftp客户端想和ftp服务端搞点事情的话,首先要通过21端口申请建立tcp连接,当连接通过以后呢,这个端口就成为了客户端向服务端传输控制指令的通道了,而数据传输通道是另外建立的,由ftp服务端申请向ftp客户端建立数据通道,实质上就是发送文件。具体的结构如下图所示:

所以咱们总结一下:ftp的连接与http一致在于,都是基于TCP,但是不同之处在于,ftp是双tcp通道(或者叫双端口),且还有一点不同在于,ftp建立连接是有状态的!也就是说,当ftp客户端想请求两次文件,它不需要每次都重新建立与服务端的连接,那个端口20的tcp连接是一直有效的!!!
DNS
域名四层结构
这东西我也常听到过,这次咱们深究一下。(引用自阮一峰的博客,侵删)
DNS是基于UDP哦!!!!!!
DNS (Domain Name System 的缩写)的作用非常简单,就是根据域名查出IP地址。你可以把它想象成一本巨大的电话本。举例来说,如果你要访问域名math.stackexchange.com,首先要通过DNS查出它的IP地址是151.101.129.69
OK在开始前先介绍一下查询dns的工具or指令:Linux下使用dig指令,Windows下使用nslookup指令,简单用的话直接机上待解析的域名即可。OK咱们用nslookup简单看看:
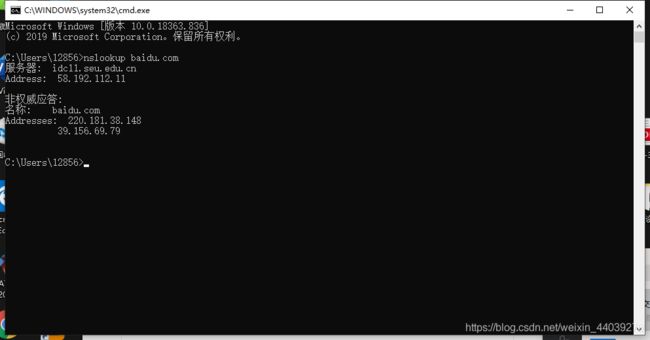
可以看到dns服务器是idc11.seu.edu.cn,也列出了dns服务器的ip地址。
那么究竟是如何一步步的将域名解析成ip地址呢?
DNS服务器解析流程
以这个www.baidu.com来说,其实完整的domain域名是www.baidu.com.root,对没错就是这样的四层结构,只是一般最高层的root大家都一样,所以就不写了。(这个叫根域名)。OK继续往下走,遇到了.com这个东西是顶级域名,当然还有诸如.net这种。再往下走是二级域名,也是用户可以注册的域名,再往下走就是主机名称,也叫三级域名,就是www啦。
OK咱们可以换Linux下dig +trace www.baidu.com一步步看看,DNS服务器究竟做了啥。
第一步,先列出root根域名服务器的信息包括其ip地址。(世界上一共13个根域名服务器,代称A~M),然后DNS服务器向这些所有的根域名服务器发送顶级域名.com,然后谁先给回复,就听谁的,这样根域名服务器就将顶级域名的服务器信息包含ip地址传给DNS服务器了。一层一层,最后找到目的ip地址。(DNS服务器咋晓得找到根服务器呢?其实这东西是在DNS服务器里定死的,本来就不怎么会发生变化)
当然啦,并不是每次DNS都要访问一下根域名服务器,因为DNS服务器会记录这样的一次访问结果,然后保存很长很长时间的。(有个蚕食叫TTL了解一下?)
DNS查询方式
DNS查询方式主要介绍两种:递归和迭代。
简单来说,执行递归查询的DNS会替发起请求的用户客户端完成一系列的DNS查询,直到获取了最终结果后,返回给查询客户端。而迭代查询过程中,各级DNS都把自己知道的信息反馈给客户端,所有的查询过程都由发起请求的客户端自己完成。
DNS也有缓存机制,没错就是你想的那样。
ddos了解一下
ddos攻击想必各位一定都听说过,这次咱们深究一下。其实就是向根域名服务器或者是顶级服务器发送一些虚假的DNS报文,让正常的DNS请求得不到正确响应。不过DNS缓存机制、根域名服务器和顶级域名服务器的过滤机制可以有效缓解这种压力。
DHCP
DHCP是Dynamic Host Configuration Protocol的缩写,即动态主机配置协议。DHCP是一个很重要的局域网的网络协议,使用UDP协议工作,为内部网络或网络服务供应商自动分配IP地址。大部分路由器可以转发DHCP配置请求,因此,互联网的每个子网并不都需要DHCP服务器。
这里额外说一句,当时我做实验的时候发现,如果DHCP分配失败了,那么windows会将ip地址设置到169.254.0.0这个段。
P2P
看到这个东西,有些司机朋友要笑了。没错,它也是应用层的协议之一!P2P 就是 peer-to-peer。这种方式的特点是,资源一开始并不集中存储在某些设备上,而是分散地存储在多台设备上,这些设备我们称为 peer。 在下载一个文件时,只要得到那些已经存在了文件的 peer 地址,并和这些 peer 建立点对点的连接,就可以就近下载文件,而不需要到中心服务器上。一旦下载了文件,你的设备也就称为这个网络的一个 peer,你旁边的那些机器也可能会选择从你这里下载文件。
种子文件(.torent)各位司机一定很熟悉对吧,咱们就是靠着这种种子文件传给如电驴或者bit-Torrent这种p2p下载软件,然后就能接受资源了。那么这个种子文件究竟做了什么呢?
种子文件
.torrent 文件由Announce(Tracker URL)和文件信息两部分组成。其中Tracker咱们得介绍一下是干嘛的。Tracker服务器其实相当于p2p的核心服务器(卧槽不是说好了p2p是去中心化的传输方式么???),这里其实不矛盾,传输这件事情确实是去中心化实现的,但是管理这些分散的资源以及对应主机ip地址是由tracker服务器干的。
下载时,BT 客户端首先解析 .torrent 文件,得到 Tracker 地址,然后连接 Tracker 服务器。Tracker 服务器回应下载者的请求,将其他下载者(包括发布者)的 IP 提供给下载者。下载者再连接其他下载者进行下载。peers之间一般用TCP进行通信。
从这个过程也可以看出,这种方式特别依赖 Tracker。Tracker 需要收集所有 peer 的信息,并将从信息提供给下载者,使下载者相互连接,传输数据。虽然下载的过程是非中心化的,但是加入这个 P2P 网络时,需要借助 Tracker 中心服务器,这个服务器用来登记有哪些用户在请求哪些资源。所以,这种工作方式有一个弊端,一旦 Tracker 服务器出现故障或者线路被屏蔽,BT 工具就无法正常工作了。
那么有没有解决方法呢?DHT了解一下。
这东西是一种去中心化网络,distributed-hash-table。当一个客户端启动 BitTorrent 准备下载资源时,这个客户端就充当了两个角色:
peer 角色:监听一个 TCP 端口,用来上传和下载文件。对外表明我这里有某个文件;
DHT Node 角色:监听一个 UDP 端口,通过这个角色,表明这个节点加入了一个 DHT 网络。
在 DHT 网络里面,每一个 DHT Node 都有一个 ID。这个 ID 是一个长字符串。每个 DHT Node 都有责任掌握一些“知识”,也就是文件索引。也就是说,每个节点要知道哪些文件是保存哪些节点上的。注意,这里它只需要有这些“知识”就可以了,而它本身不一定就是保存这个文件的节点。当然,每个 DHT Node 不会有全局的“知识”,也就是说它不知道所有的文件保存位置,只需要知道一部分。这里的一部分,就是通过哈希算法计算出来的。
OK说了这么多,我会在算法栏目重点介绍DHT的一个很强的算法实现:Kademlia
OK应用层还差一个SMTP没讲,这个留给朋友们自己搞定,加油!
socket套接字编程
这也是前几天面试官问到我的一个问题,说实话很简单的东西。
你也许听很多高手说过,UNIX/Linux 中的一切都是文件!那个家伙说的没错。请注意,网络连接也是一个文件!我们可以通过 socket() 函数来创建一个网络连接,或者说打开一个网络文件,socket() 的返回值就是文件描述符。有了文件描述符,我们就可以使用普通的文件操作函数来传输数据了,例如:
用 read() 读取从远程计算机传来的数据;
用 write() 向远程计算机写入数据。
你看,只要用 socket() 创建了连接,剩下的就是文件操作了,看来Linux下的socket编程还是挺直观的。
Windows 会区分 socket 和文件,Windows 就把 socket 当做一个网络连接来对待,因此需要调用专门针对 socket 而设计的数据传输函数。具体的咱们去传输层了解一下。
https是啥
其实就比http多个s,即security。用的端口号也不再是80,而是443.至于哪里安全了,我这边就不做展开。
传输层
传输层里需要考虑哪几个问题呢?其实就是:
1.传输的可靠性
问题来了:为什么传输会不可靠呢?这里有物理层传输的原因(比如物理上的干扰),也有传输协议上的不可靠(比如分组信息过多导致router(路由器)缓存溢出)。
2.吞吐量/吞吐率
什么是带宽?在计算机行业,带宽表示理论上最大的数据传输速率。经常出现多个进程共用一条网络路径传输数据,因而分到每个进程的可用带宽不仅变小了,而且还会随之波动。
吞吐量,是指在一次性能测试过程中网络上传输的数据量的总和。咱们不能用这个参数来衡量一个网络系统的输出能力,咱们还得除以所用时间,得到一个吞吐率,用它来衡量会更合适。
传输层没能保证这一点。
3.定时
发送端通过socket套接字注入数据时的时间,到接收端接收到数据,这一段时间的长短影响了很多应用程序,如微信电话,打游戏等等。
传输层其实没能保证这一点。
4.安全性
即数据进入传输层时是否可以加密用户数据,而将从传输层离开时能否解密数据。
传输层真的有这种加密解密的东西么?其实并没有。那其他层没有么?这还真有。应用层有一种强化的socket,称为secure socket layer。
传输层与下面的网络层关系
就几句话就能说清楚:网络层是提供了主机和主机之间的逻辑通信,而传输层则是提供了主机上的不同的进程和进程之间的逻辑通信。
多路复用与多路分解
端口号
就是个16bit的数字,其中前面的1024个是well-known即周知端口号,是留给特定的应用层协议使用的。
UDP套接字
一个UDP套接字是由一个包含目的lP地址和目的端口号的二元组来标识的。
假定主机A中的一个进程具有的UDP端口号为9157,它要发送一个应用程序数据块给主机B中的另一进程,该进程具有的UDP端口号为6428。主机A中的传输层创建一个传输层报文段,其中包括应用程序数据、源端口号9157、目的端口号6428和两个其他字段。然后,传输层将生成的报文段传递到网络层。
网络层将该报文段封装到一个IP数据报中,并尽力而为地将报文段交付给接收主机。如果该报文段到达接收主机B,接收主机传输层就检查该报文段中的目的端口号6428,并将该报文段传递给端口号6428所标识的套接字。注意到主机B能够运行多个进程,每个进程有自己的UDP套接字及对应的端口号。当从网络接收到达的UDP报文段时,主机B通过检查该报文段中的目的端口号,将报文段定向(多路分解)到相应的套接字。
如果两个UDP报文段有不同的源IP地址或源端口号,但具有相同的目的IP地址和目的端口号,那么这两个报文段将通过相同的目的套接字定向到相同的目的进程。
TCP套接字
TCP套接字是由一个四元组(源IP地址,源端口号,目的IP地址,目的端口号)来标识的。
UDP
其实udp只是做了传输层协议能做的最少的工作,仅仅只是包括了实现分解和复用,然后是少量的差错检测,就没给下面的网络层的IP数据报增加太多的头部尾部信息,且还是无连接的,生死有命,富贵看IP(IP是尽自己所能传输,稳不稳也不好说,反正不可靠)。
那么UDP有什么优点呢?
1.无需建立连接;
2.分组的首部开销很小,只有8byte(看看tcp,有20byte!!!)
3.传输流量大;
UDP报文格式简单:

单播多播广播了解一下?
udp的广播就是局域网范围内进行的,它指明的目的IP地址是255/255/255/255,当然广播信息是无法被路由器路由出去的,不然会造成网络风暴。不过即使是广播,也需要指定好特定的接收方端口号。
多播我没有使用过,我也不是很了解,兄弟要不你自己去查查。
TCP
tcp是全双工的服务,是面向连接的,是可靠的传输层协议。
建立连接-三次握手
这才是老生常谈的问题了,我吐了。
咱们首先搞清楚TCP报文的格式中,有一个叫标志位的东西,里面包括SYN(请求建立连接)、ACK(确认)等等标志。

反正得让两方都明白一件事情:对方有通信的能力
第一次握手:客户端发送一个连接请求,测试服务端是否可以正常通信(SYN位置为1)
第二次握手:服务端确认客户端的连接请求,并且同时发送一个请求,测试客户端是否可以正常通信(SYN位置为1, ACK位置为1)
第三次握手:客户端接受到服务端的确认(了解到服务器可以正常通信),之后发送一个ACK,告诉服务器我可以正常通信(ACK位置为1)
考虑两次握手:客户端发送一个连接请求,服务端接受到连接请求,发送一个确认,此时服务端已经确认自己有接受报文的能力,认为连接已经建立,所以开始为已建立的连接分配资源,如果服务端发送的确认丢失,客户端就无从知道连接已经建立。如果存在大量这种情况,就有可能会造成服务器崩溃。
什么是半连接队列
服务器第一次收到客户端的 SYN 之后,就会处于 SYN_RCVD 状态,此时双方还没有完全建立其连接,服务器会把此种状态下请求连接放在一个队列里,我们把这种队列称之为半连接队列。
当然还有一个全连接队列,就是已经完成三次握手,建立起连接的就会放在全连接队列中。如果队列满了就有可能会出现丢包现象。
这里在补充一点关于SYN-ACK 重传次数的问题:
服务器发送完SYN-ACK包,如果未收到客户确认包,服务器进行首次重传,等待一段时间仍未收到客户确认包,进行第二次重传。如果重传次数超过系统规定的最大重传次数,系统将该连接信息从半连接队列中删除。
注意,每次重传等待的时间不一定相同,一般会是指数增长,例如间隔时间为 1s,2s,4s,8s…
ISN是固定的么
首先isn是啥?就是咱们在申请建立tcp连接的时候,放进去的initial sequence number,希望等服务器将其+1并放在ack里返回回来。ISN随时间而变化,因此每个连接都将具有不同的ISN。ISN可以看作是一个32比特的计数器,每4ms加1 。如果 ISN 是固定的,攻击者很容易猜出后续的确认号,因此 ISN 是动态生成的。
三次握手过程中可以携带数据吗
第一次和第二次是不可以的,第三次可以。为什么呢?是这样的,对于第一次而言,如果客户端的这个请求可以携带大量的数据,那么就会有别有用心的人制造大量的首次握手数据并发给服务器,这会让服务器花费很多时间、内存空间来接收这些报文。而对于第三次的话,此时客户端已经处于 ESTABLISHED 状态。对于客户端来说,他已经建立起连接了,并且也已经知道服务器的接收、发送能力是正常的了,所以能携带数据也没啥毛病。
SYN攻击是什么
服务器端的资源分配是在二次握手时分配的,而客户端的资源是在完成三次握手时分配的,所以服务器容易受到SYN洪泛攻击。SYN攻击就是Client在短时间内伪造大量不存在的IP地址,并向Server不断地发送SYN包,Server则回复确认包,并等待Client确认,由于源地址不存在,因此Server需要不断重发直至超时,这些伪造的SYN包将长时间占用未连接队列,导致正常的SYN请求因为队列满而被丢弃,从而引起网络拥塞甚至系统瘫痪。SYN 攻击是一种典型的 DoS/DDoS 攻击。
检测 SYN 攻击非常的方便,当你在服务器上看到大量的半连接状态时,特别是源IP地址是随机的,基本上可以断定这是一次SYN攻击。在 Linux上可以使用系统自带的 netstats 命令来检测 SYN 攻击。
netstat -n -p TCP | grep SYN_RECV
防护手段:
1.缩短超时(SYN Timeout)时间
2.增加最大半连接数
3.过滤网关防护
4.SYN cookies技术
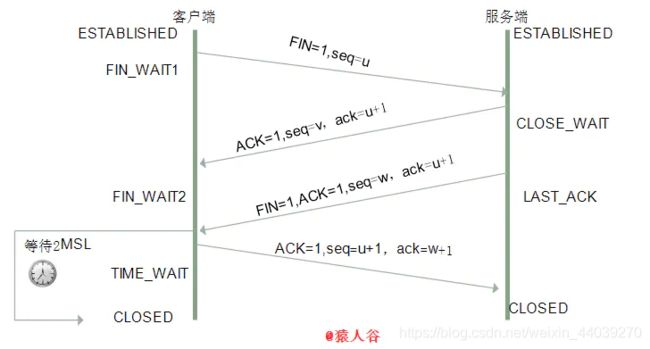
断开连接-四次握手
再继续看看TCP报文的标志位,里面还包括这些:FIN(结束)
网络层
网络层需要被了解的主要是IP协议。它是一种尽力而为的交付方式,不能保证在一定时间内传输完成报文、也不能保证传输的报文到达顺序,更无法保证报文能顺利传送到目的地址。
路由器
路由器是工作在网络层的网络器件,作用是转发分组。
路由器使用队列来维护输入端口中接收到的分组,因此会产生一定的时延。路由器同样使用队列来维护输出端口中等待发出的分组。
若路由器处理分组的速率赶不上分组进入队列的速率,则队列的存储空间很快就会耗尽,后面再进入队列的分组由于没有存储空间而只能被丢弃。路由器中的输入或输出队列产生溢出是造成分组丢失的重要原因。
路由表
路由表的主要作用是供路由器查找目标网络,进而确定转发接口和下一跳路由,完成数据包的转发功能。那么路由表长啥样子呢?
| 表项 | 含义 |
|---|---|
| destination mask pre costdestination | 目的地址,用来标识IP包的目的地址或者目的网络。 |
| mask | 网络掩码,与目的地址一起标识目的主机或者路由器所在的网段的地址。 |
| pre | 标识路由加入IP路由表的优先级。可能到达一个目的地有多条路由,但是优先级的存在让他们先选择优先级高的路由进行利用。 |
| cost | 路由开销,当到达一个目的地的多个路由优先级相同时,路由开销最小的将成为最优路由。 |
| interface | 输出接口,说明IP包将从该路由器哪个接口转发。 |
| nexthop | 下一跳IP地址,说明IP包所经过的下一个路由器。 |
路由表分类
1.静态路由表项
静态路由是由管理员在路由器中手动配置的固定路由,路由明确地指定了包到达目的地必须经过的路径,除非网络管理员干预,否则静态路由不会发生变化。静态路由不能对网络的改变作出反应,所以一般说静态路由用于网络规模不大、拓扑结构相对固定的网络。
2.动态路由表项
动态路由表是根据网络运行情况自动调整的路由表,路由器根据路由选择协议(如RIP)提供的功能,自动学习和记录网络运行情况,在需要时自动计算数据传输的最佳路径。
常见路由算法
这个我暂时不放在这里讲述,单独写一篇。
分片重装
发送方会在IP层将要发送的数据分成多个数据包分批发送,而接收方则将数据按照顺序再从新组织起来,等接收到一个完整的数据报之后,然后再提交给上一层传输层。
注意,TCP协议为可靠的传输协议,它避免了IP分片的发生,它会在TCP层对数据进行处理,对数据进行分段(不在详述),IP分片用的多的在UDP协议。
在Linux下存储IP分片数据是采用的hash结构,首先搞了1024个hash bucket,然后根据IP报文头部的四个字段,计算得到哈希值,放在相应的bucket中(bucket结构有点意思,是一个链表,链表中串联的是一个个队列)。
分片插入
这就很简单了,先找到bucket,然后看看这个链子上有没有和自己的IP报文前面几个字段一样的(就是拿来哈希的那几个字段),有的话就进入到这个chain,然后根据报文的偏移量插入即可,当然要注意一下bucket不能溢出。
分片重组
做一些条件判断即可,其实还是非常简单的,遍历一遍即可发现是否已经收完了。
当然很不幸,有的分片总是缺点。那咋办?很简单,Linux内核采用了超时机制处理这些分片,在接收到第一个数据包分片,创建分片队列后,内核随即启动超时计时器。默认30s,超过的话则全部丢弃。当然咱不能直接给人家丢了,如果人家就是想传递给咱们这台主机,那么咱们有义务用ICMP告诉人家,分片重组超时了。。。。。。
IPV4与IPV6
咱们就简单的说说这俩的区别。
1.IPV4的地址空间不大,因为用的是32bit表示ip地址,听说好像前段时间地址全部用光了。IPV6就大很多了,用的是128bit表示ip地址,8个0~65535之间的数字。
2.安全性上,IPV4就算了吧,没啥安全性可言,透明传输;IPV6对网络层的数据进行了加密;
3.分片重装这件事情上,IPV6不允许路由器做重装操作,这件事情很费时费资源,如果路由器发现了这样的超过了大小上限的IPV6数据后就会将其丢弃掉并返回一个ICMP错误报文。
那么如何从IPV4过渡到IPV6呢?
双栈技术是为网络、业务系统同时部署IPv4和IPv6,分别对IPv4用户和IPv6用户提供服务。
翻译技术是通过特定的地址映射方式,将IPv4地址和IPv6地址互相翻译。
隧道技术主要是用于两块独立的IPv6网络穿越IPv4网络进行互联,或两块独立的IPv4网络穿越IPv6网络进行互联。
防火墙
目前我也不是很了解,只知道作用有二:过滤和状态监控。
网关
如果网络A中的主机发现数据包的目的主机不在本地网络中,就把数据包转发给它自己的网关,再由网关转发给网络B的网关,网络B的网关再转发给网络B的某个主机。
ICMP与ping
其实这个ICMP就是帮助IP做一些“错误消息通知”的,比如刚刚咱们说到的分片重装失败的时候会有ICMP消息发送给源主机。
ping 程序是用来探测主机到主机之间是否可通信,如果不能ping到某台主机,表明不能和这台主机建立连接。ping 使用的是ICMP协议,它发送icmp回送请求消息给目的主机。ICMP协议规定:目的主机必须返回ICMP回送应答消息给源主机。如果源主机在一定时间内收到应答,则认为主机可达。
数据链路层
交换机
看着熟悉吧?交换机就工作在这一层(不能这么说,应该说,工作到这一层)。交换机中有一张MAC地址转发表,记录了MAC地址和交换机端口的对应关系,一个端口可以对应多个MAC地址。每个交换机在转发报文的时候只需要知道这个目的MAC可以从我的哪一个端口到达就行了,然后就把帧往这个端口发,至于后面的设备怎么处理他并不关心。就这样一级一级转发,知道电脑的网卡实际连接的交换机把帧发到网卡以后,网卡一看目的MAC就是自己,然后就解封装,交由三层协议栈进行处理。
如何建立这张表呢?
部分是根据主动发起请求的报文,把源MAC和从哪一个端口收到的建立对应,另一部分在收到报文的时候如果MAC表里还没有这个目的MAC,那么就在除了收到这个报文的端口以外的其他端口进行一次洪泛,等待目的MAC的终端响应。
arp协议
ARP(Address Resolution Protocol)即地址解析协议, 用于实现从 IP 地址到 MAC 地址的映射,即询问目标IP对应的MAC地址。
一般情况下,上层应用程序更多关心IP地址而不关心MAC地址,所以需要通过ARP协议来获知目的主机的MAC地址,完成数据封装。
ARP的功能和实现过程是如此的简单:它在发送方需要目标MAC地址的时及时出手,通过"一问一答"的方式获取到特定IP对应的MAC地址,然后存储到本地【ARP缓存表】,后续需要的话,就到这里查找。当然这个缓存表有时效性,只要重启电脑就会消失掉。将请求包以广播的形式发送。
PC1发送的请求广播包同时被其他主机收到,然后PC3和PC4收到之后(发现不是问自己)则丢弃。而PC2收到之后,根据请求包里面的信息(有自己的IP地址),判断是给自己的,所以不会做丢弃动作,而是返回ARP回应包。
ARP请求包的完整信息是:我的IP地址是IP1,MAC地址是MAC1,请问谁是PC2,你的IP2对应的MAC地址是多少?(先自我介绍,再询问)
就这样,通过一问一答的方式完成了arp交互。(俩人都美滋滋的把对方的信息写入缓存表中了)
arp攻击
其实非常好理解,假设一个局域网内有三台设备,分别是PC1、2、3.某天PC1和2进行arp通信,于是被PC3被动监听到了。等下次他俩再想arp通信的时候,PC3就假装自己是PC2,发一些虚假的arp回复信息。PC1会根据“谁新鲜就相信谁”的策略选择与PC3通信。。。。。。
按照这个思路,如果PC2是个路由器,PC1想借着它去上网,那完了,别上网了,断网了呀。
可以说,除了基于https的数据意外的所有其他数据,都可以被窃取。
arp防御
其实防御的方法就俩:要么黑客发的虚假arp不能被交换机转发,要么就是用户收到假的arp后不去相信。
对于第一种方法,就靠咱们的交换机了。交换机记录每个接口对应的IP地址和MAC,即port<->mac<->ip,生成DAI检测表;交换机检测每个接口发送过来的ARP回应包,根据DAI表判断是否违规,若违规则丢弃此数据包并对接口进行惩罚。当然目前的家用交换机应该是没有这样的牛逼功能的。
代理arp
咱们想访问互联网上的服务器,肯定没法用arp协议广播穿透整个互联网最后发给目的服务器,请求它的mac地址对吧?那咋办?
当ARP请求目标跨网段时,网关设备收到此ARP请求,会用自己的MAC地址返回给请求者,这便是代理ARP。
代理ARP本质是一个"善意的欺骗",是一个"错位"的映射。从图中我们看到服务器地址的正常映射是<8.8.8.8-MAC2>,而路由器返回给电脑的,却是 <8.8.8.8-MAC254>。不管是不是"欺骗",至少最终电脑可以与外网的服务器实现通信。
第一,代理ARP仅仅是正常ARP的一个拓展使用,是可选项而不是必要项;
第二:代理ARP有特定的应用场景,与网关/路由的设置有直接关系:当电脑没有默认网关/路由功能时,并且需要跨网站通信时,则会触发代理ARP。换句话说,如果有网关/路由功能,则不需要代理ARP;
第三:正常环境下,当用户接入网络时,都会通过DHCP协议或手工配置的方式得到IP和网关信息(所以不需要代理ARP)
免费arp
如何在IP地址冲突的时候及时检测,并且做出解决方案呢?
它们会相互发送免费ARP(“互怼”),用来提醒对方:你的IP地址跟我的冲突啦! 这里要注意一点:免费ARP是以ARP Request或Reply广播形式发送,将IP和MAC地址信息绑定,并宣告到整个局域网。如果在宣告的过程中,其他电脑监听到,并且地址跟自己一样,也会直接参与这个"互怼"过程。
那么,这个混乱的争抢过程,会不会停下来呢?
可能会持续一段时间,也可能一直持续下去(后面有实验验证)。冲突方之间可能会一直发送,直到有一边做出让步并修改IP地址。
rarp与iarp
RARP是一种逝去的地址分配技术,是Bootp和DHCP的鼻祖,目前我们的电脑基本不会用到这个协议,只有部分无盘工作站等情况需要用到。根据MAC获取IP地址,更确切的说,用于主机在启动的时候获得自己的IP地址。功能跟DHCP是一样的。
为啥rarp被淘汰了呢?因为它有很多局限性,比如,如果rarp服务器和客户不在一个网段的话,由于rarp请求报文无法跨越路由器,GG。另外,RARPserver上的MAC地址和IP地址是必须事先静态配置好的。但DHCP却可以实现除静态分配外的动态IP地址分配以及IP地址租期管理等等相对复杂的功能。
iarp我不是很了解,就不说了。
物理层
pass!