mysql 聚簇索引与非聚簇索引
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。具体的细节依赖于其实现方式,但InnoDB的聚簇索引实际上在同一个结构中保存了B-Tree索引和数据行。
当表有聚族索引时,它的数据行实际上存放在索引的叶子页( leaf page)中。术语 "聚簇" 表示数据行和相邻的键值紧凑地存储在一起。因为无法同时把数据行存放在两个不同
的地方,所以一个表只能有一个聚族索引。
与之相对的是,非聚簇索引。mysql 中InnoDB的索引结构是聚簇索引,myisam 是非聚簇索引。
下图展示了InnoDB 聚簇索引中的记录是如何存放的(但并不是很准确,水平有限 [手动滑稽] ,只求说明白聚簇索引结构)

在InnoDB 上节点叶只包含索引列(这里指主键),叶子页包含了行的全部数据 。
如果没有定义主键,InnoDB 会选择一个唯一的非空索引代替。如果没有这样的索引,InnoDB会隐式定义一个主键来作为聚簇索引。 InnoDB 只聚集在同一个页面中的记录。包含相邻键值的页面可能会相距甚远。
聚集的数据有一些重要的优点:
可以把相关数据保存在一起。例如实现电子邮箱时,可以根据用户ID来聚集数据,这样只需要从磁盘读取少数的数据页就能获取某个用户的全部邮件。如果没有使用聚簇索引,则毎封邮件都可能导致一次磁盘I0。
数据访问更快。聚簇索引将索引和数据保存在同一个 B- Tree中,因此从聚簇索引中获取数据通常比在非聚簇索引中查找要快。
使用覆盖索引扫描的查询可以直接使用页节点中的主键值。
如果在设计表和查询时能充分利用上面的优点,那就能极大地提升性能。同时,聚簇索引也有一些缺点:
聚簇数据最大限度地提高了I/O密集型应用的性能,但如果数据全部都放在内存中,则访问的顺序就没那么重要了,聚簇索引也就没什么优勢了。
插入速度严重依赖于插入顺序。按照主键的顺序插入是加载数据到 InnoDB表中速度最快的方式。但如果不是按照主键顺序加载数据,那么在加载完成后最好使用
0PTIMIZE TABLE命令重新组织一下表。
更新聚簇索引列的代价很高,因为会强制InnoDB将毎个被更新的行移动到新的位置。
基于聚簇索引的表在插入新行,或者主键被更新导致需要移动行的时候,可能面临"页分裂( page split)" 的问题。当行的主键值要求必须将这一行插入到某个已满的页中时,存储引擎会将该页分裂成两个页面来容纳该行,这就是一次页分裂操作(这种情况更多的发生在更新,举个栗子,有个字段是varchar型,只存了不足255个字节的内容,在当前页面中,但如果后续更新中存储了更多的数据,发现当前页已经满足不了存储要求,就会发生页分裂)。页分裂会导致表占用更多的磁盘空间。
聚簇索引可能导致全表扫描变慢,尤其是行比较稀疏,或者由于页分裂导致数据存储不连续的时侯。
非聚簇索引结构:
相比聚簇索引,非聚簇索结构可能是这样的(请注意这里用词,是可能,也就是说不一定是这样的,这里只求说明问题即可,水平有限,还请见谅)。
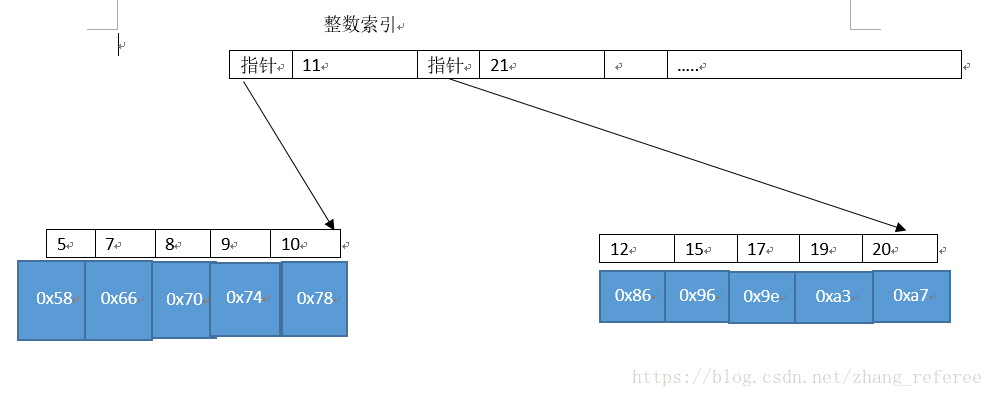
在上面中,我假设索引是自增主键索引,但如果是其他非唯一索引,结构是不一样的(主要体现在叶子页节点上)。
InnoDB索引和MyISAM索引结构的区别:
一 InnoDB的数据文件本身就是索引文件。而MyISAM的索引和数据是分开的。
二 InnoDB的非主键索引存储的是主键的值而不是地址,主键存储的是数据,而MyISAM的辅助索引和主索引没有多大区别。
嗯嗯,想了半天,查了些资料,发现有位老哥写的很不错,这里直接上博客地址,看了他的文章,感觉现在所写的很多都是多余的。
博客地址:https://www.cnblogs.com/gym333/p/6877023.html
是从数据结构来讲的,讲的很详细,很容易理解。